虚拟容器架构在Ceph中应用
2020-05-18荆文军

摘 要:近年来,Ceph越来越受到各大企业和高校的青睐。它的可靠性,可扩展性,使得Ceph在众多存储开源产品中脱颖而出,Ceph的对象存储是其应用场景较为广泛的功能。随着直播等自媒体的兴起,人们对于对象存储的要求不只局限于功能上的使用,当把Ceph对象存储进行商业化时候,对其性能的要求也是越来越高。该文引入“虚拟容器”的概念,通过增加一层容器以及对应算法,解决原有的索引瓶颈,使得在数据遍历,搜索等方面发挥更好的效果。
关键词:对象存储;虚拟容器;索引
中图分类号:TP393.09 文献标识码:A 文章编号:2096-4706(2020)20-0128-03
Application of Virtual Container Architecture in Ceph
JING Wenjun
(China Mobile(Suzhou)Software Technology Co.,Ltd.,Suzhou 215153,China)
Abstract:Recently,Ceph has been increasingly attracted by enterprises and universities. Its reliability and extensibility make Ceph stand out among the store open source products. Cephs object storage is a more extensive function of its application scenarios. With the rise of self-media such as live broadcasts,peoples requirements for object storage are not limited to functional use. When Ceph object storage is commercialized,its performance requirements are getting higher and higher. The artical introduces the concept of “virtual container”,by adding a layer of container and the algorithm,to solve the original index bottleneck,so as to play a better effect in data traversal,search and other aspects.
Keywords:object storage;virtual container;index
0 引 言
Ceph对象存储单个容器的性能指标备受各大企业应用的关注,当容器对象到达一定數量级(千万级)时,容器遍历性能会大受影响。目前,在容器遍历性能的改进方面鲜有研究,大部分的做法是通过增加底层磁盘性能进行提升,比如使用磁盘缓存设备,或者直接使用高性能磁盘。
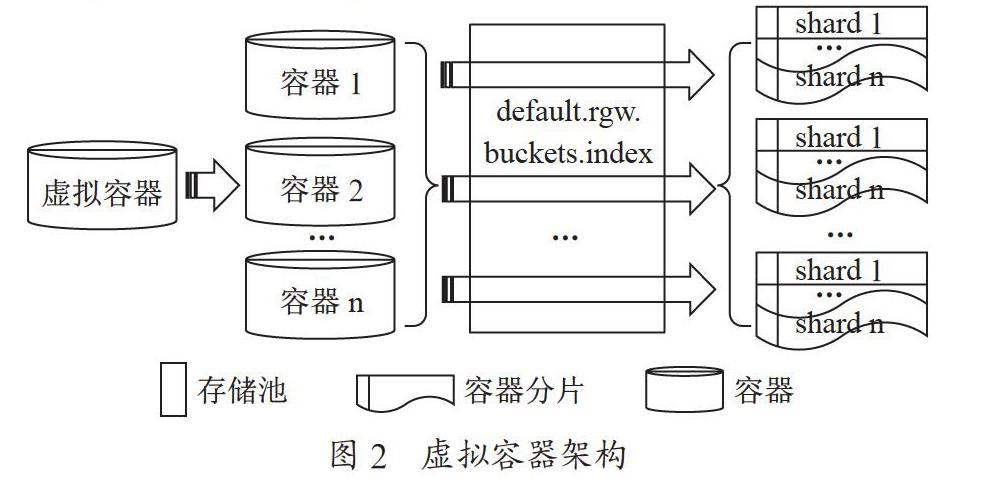
作者在从事的日常集群维护工作中也遇到上述容器遍历的性能问题,随着用户容器数量的增加,对象频繁遍历会使得上层应用等待时间过久而超时。因此作者以此背景进行研究,本文提出虚拟容器概念和子容器分配算法,在原容器上增加虚拟容器层,在用户层面该虚拟容器所有功能与原容器一致。虚拟容器和子容器之间通过一致性算法进行对象分配,这种伪随机分配算法可以使得各个子容器对象数量相对均匀,同时对象的子容器分配路径是“固定的”,即可以计算得出,且在动态增加或减少子容器时对象移动的开销最小。所以在一定硬件条件下,虚拟容器架构可以提高容器可支持最大遍历对象数量,文中最后给出了不同存储设备后端的容器最大容量的建议值。本文的读者对象建议为研究人员或者相关企业单位从事云计算领域专家。
1 Ceph对象存储
随着云计算生态环境的日渐成熟,软件定义产品呼声高涨,越来越多的企业和用户选择上云。Ceph作为软件定义存储的优秀开源代表之一,有着成熟社区的支撑,开源峰会的推广和优秀企业的打磨,使得Ceph由开源界的“网红”逐步成长为“元老”,打造开源存储届的“Linux”。对象存储是Ceph应用广泛的功能之一,网盘的对接、直播数据的存储、监控视频的存储都离不开它,只要有一台能访问公网的计算机随时随地可以使用对象存储。
2 数据存储方式
Ceph的对象存储网关(Rados Gateway,RGW)提供了REST API,除了提供了原始的接口层,还兼容了AWS的S3接口和OpenStack的Swift接口,用户可以根据需求进行使用和定制。一般来说对象存储由用户(user),桶或容器(bucket),对象(object)资源组成。桶归属于用户,每个桶可以存放多个对象,该对象一般是非结构化的数据。
3 现有数据存储流程
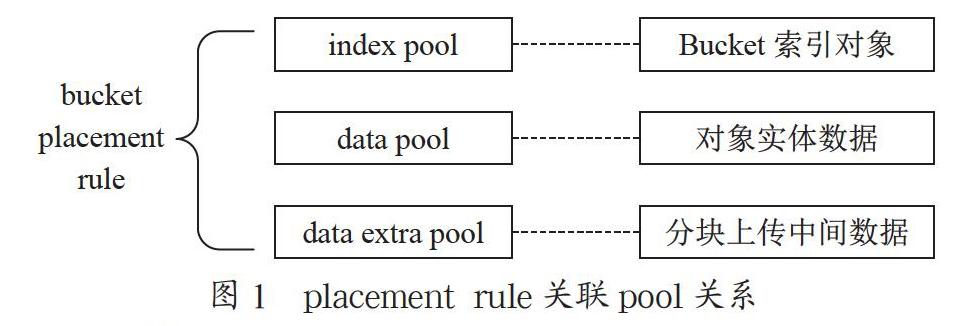
存储桶是用来存放对象的容器,含基础信息和扩展信息。基础信息主要是一些桶的标准元数据信息,比如桶的配额,placement rule,bucket的使用容量和bucket对象数目等。扩展信息主要是bucket的一些用户自定义元数据信息。
在bucket的palcement rule里面记录了数据的存放位置,如图1所示。
存储池default.rgw.buckets.index是图1中index pool,用来存放bucket的索引对象。当容器容量到达一定规模,处理客户端遍历容器内对象(list)请求后Ceph会出现请求等待的性能瓶颈,即队列繁忙导致其他请求阻塞(blocked)。为了提高索引效率,容器支持调整分片数,该分片用于关联容器的索引对象,对象元数据可关联在容器不同的分片上,在处理遍历请求时,所有分片可以异步进行遍历,一定程度上能够提升性能。在此基础上性能要突破需要依赖于硬件。
步骤2:当1 步骤3:创建N个子容器; 步骤4:根据子容器id通过一致性Hash算法得到子容器对应的Hash环位置; 步骤5:处理对象的相关请求时,解析请求中对象名称(key),根据key通过一致性Hash算法得到Hash环位置,并在Hash环上按照顺时针方向找到最近的目标子容器; 步骤6:最后该对象根据步骤5获取的目标子容器进行存放。 6 实际应用 我们对上述方法进行了模拟对比。集群配置如下: 操作系统:CentOS 7.3;集群数量:20台;磁盘数量:200个,表2测试场景中采用HDD(机械盘)和Bcache(缓存盘)进行对比。每台物理机2张网,带宽均为万兆,网卡绑定模式为mode1,物理机内存64 GB。mon数量:3个;osd数量200个;对象存储网关数量:3个;rgw_override_bucket_index_max_shards配置为128。 通过实验可得出单容器可支持的对象最大遍历数如表2所示。 从上述对比可知虚拟容器架构的性能要优于原架构性能。 7 结 论 本文指出了Ceph对象存储在现有的元数据池分片架构中,单容器存储大量对象的遍历性能问题。通过增加“虚拟容器”算法的方式对单容器存储架构进行优化。使得对象存放到虚拟容器时,通过一致性算法能够与“子容器”形成“固定的”对应关系,即这种对应关系是伪随机的,相同对象的存储路径不随不同的时间段的操作而改变,能够大大地提高容器遍历和查询对象的性能。 参考文献: [1] WEIL S A. Ceph:Reliable, scalable, and high-performance distributed storage [D]. SANTA CRUZ:University of California,Santa Cruz,2007. [2] 謝型果.Ceph设计原理与实现 [M].北京:机械工业出版社,2017. [3] 叶毓睿,雷迎春,李炫辉,等.软件定义存储:原理、实践与生态 [M].北京:机械工业出版社,2016. [4] 张冬.大话存储:存储系统底层架构原理极限剖析(终极版) [M].北京:清华大学出版社,2015. [5] SINGH K.Ceph Cookbook [M].Ceph中国社区,KVM云技术社区,译.北京:电子工业出版社,2016. 作者简介:荆文军(1990.09—),男,汉族,江苏丹阳人,中级工程师,硕士研究生,主要研究方向:云计算。
