一种改进的基于TransE知识图谱表示方法
2020-05-18陈文杰
陈文杰,文 奕,张 鑫,杨 宁,赵 爽
(中国科学院 成都文献情报中心,成都 610041)
0 概述
知识图谱的起源可以追溯到语义网,语义网是一种通过计算机可以理解的方式对事物进行描述的网络,其目的是实现人与计算机的无障碍沟通。知识图谱本质上是一种大规模的语义网络,主要目标是构建一张巨大的网络图来描述真实世界中存在的各种实体之间的关系。知识图谱作为一种结构化的语义知识库,通常采用三元组(h,r,t)的形式来表示知识,h和t代表头和尾2个实体,r代表关系。知识图谱的构建主要包括知识获取、知识融合、知识验证、知识推理和应用等部分。知识表示是知识图谱构建和应用的基础,但是基于三元组的知识表示形式无法充分且完全地刻画实体间的语义关系,同时存在计算复杂度高、推理效率低和数据稀疏等问题。
近年来,随着大数据和深度学习技术的发展,表示学习在自然语言处理和图像识别等领域得到广泛应用。表示学习的目的是用低维稠密的向量来表示研究对象,在低维空间中对象距离越近,对象在语义上越相似[1]。文献[2]提出一种DeepWalk算法,其较早将word2vec的思想引入到网络表示学习中。DeepWalk充分利用图中的随机游走信息,并通过实验验证了文档中的单词和随机游走序列中的节点均服从幂律定律,在此基础上,将word2vec应用在随机游走的序列上,从而得到节点的向量表示。但是,DeepWalk在游走过程中完全随机,难以针对特定目标进行有选择性地游走。
现有网络表示学习模型更侧重于节点本身信息,忽略了边上丰富的语义信息,而且边通常不具有方向。知识图谱表示学习是网络表示学习的子领域,由于图谱中的边含有特定的语义且具有方向,因此其模型的设计更为复杂。在现有的知识表示模型中,TransE模型较具代表性,该模型将尾节点看作头节点加关系的翻译结果,使用基于距离的评分函数来估计三元组的概率。TransE模型取得了较好的预测结果,但是存在3个方面的缺陷,一是使用距离作为评分度量,每一维的特征权重相同,不够灵活,知识表示的准确性会受到无关维度的影响,二是无法处理好一对多(1-N)、多对1(N-1)和多对多(N-N)等复杂关系,三是模型独立地学习每一个三元组,忽略了图谱中的网络结构和语义信息[3]。
当前多数知识图谱表示学习方法独立地学习三元组而忽略了知识图谱的结构特征。为了解决该问题,本文利用近邻结构特征作为补充,进一步增强知识图谱的表示效果,在此基础上,提出一种向量共享的交叉训练机制,以实现图谱结构信息和三元组信息的深度融合。
1 相关工作
近年来,随着Linking Open Data、Freebase和OpenKG等开放数据集的广泛应用,互联网从文档万维网向数据万维网方向快速发展。谷歌在2012年提出了知识图谱的概念,用于改善搜索结果[4]。随后,多家互联网公司开始构建知识图谱,如苹果的“Wolfram Alpha”、百度的“知心”和搜狗的“知立方”。知识图谱被广泛应用于语义搜索、智能问答和辅助决策等任务,在人工智能领域也具有良好的应用前景。
知识表示学习是将知识图谱中的实体和关系映射到连续稠密的低维向量空间,同时保留图中的结构和语义关系[5]。知识表示学习可以降低知识图谱的高维和异构性,高效实现语义相似度计算等任务,并显著提升计算效率,此外,其将每个实体映射为一个稠密的向量,有效地解决了数据稀疏问题。知识表示学习能够实现异构知识的融合,将不同来源的实体和关系映射到同一语义空间中,还可以广泛地应用于知识图谱补全、关系抽取和智能问答等各类下游学习任务中[6]。知识表示学习的模型主要分为基于距离的翻译模型、基于语义的匹配模型、矩阵分解模型和神经网络模型等[2]。
目前,知识表示学习的研究热点主要集中在基于距离的翻译模型上,以Trans系列模型为代表。这类模型将尾节点看作头节点加关系的翻译结果,使用基于距离的评分函数来估计三元组的概率。文献[7]于2013年提出TransE模型,该模型基于欧氏距离上的偏移量来衡量计算实体之间的语义相似度。TransE模型相对简单,且具有良好的性能。TransE被提出之后,出现了一系列对其进行改进和补充的模型,如TransH、TransG、TransR和CTransR等。其中,为了有效处理1-N、N-1和N-N间的复杂关系,TransH模型令每一个实体在不同的关系下拥有不同的表示,将关系映射到另一个空间[8]。TransAH在TransH的基础上引入一种自适应的度量方法,通过对角权重矩阵将目标函数中的欧式距离转换为加权欧式距离[3]。TransA同样提出一种自适应的度量方法,为每个关系定义一个非负的对称矩阵,从而为表示向量中的每一个维度添加权重,有效地提升了模型的表示能力[9]。TransG模型使用高斯混合来刻画实体间的多种语义关系,利用最大相似度原理训练数据,该模型能够有效解决多语义问题[10]。TransE和TransH假设实体和关系全都在一个空间内,在一定程度上限制了模型的表示能力。TransR则假设不同的关系具有不同的语义空间,将每个实体投影到对应的关系空间中[11]。为了解决TransR参数过多的问题,TransD将映射矩阵转换为2个向量的乘积,TranSparse则引入自适应稀疏矩阵[12-13]。文献[11]提出的CTransR模型是对TransR的扩展,该模型首先对关系对应的头尾实体作差值,然后根据差值聚类将关系细分为多个子类[11]。但是,在CTransR模型的学习过程中,参数过多,计算量很大,不适用于大规模知识图谱。除了将实体在不同关系下表示为不同向量,TransE方法进行另一类改进,其放宽翻译模型的约束条件[6]。TransM为每一个三元组(h,r,t)分配一个与关系r相关的权重,其中,当r属于1-N、N-1和N-N等复杂关系时权重值较低[14]。TransF模型不严格限定V(h)+V(r)≈V(t),要求向量V(h)+V(r)与向量V(t)在方向上保持一致即可[15]。
实体间的关键路径通常也能反映实体间的语义关系。Path Ranking算法将2个实体的关键路径作为特征,以预测实体之间的关系[16]。TransE等模型存在一定的局限性,往往独立地学习每一个三元组。PTransE以TransE为基础,提出一种考虑关键路径的表示学习方法,并取得了显著的效果[17]。基于语义的匹配模型[18-19]为了寻找实体间的语义关系,定义了多个投影矩阵来描述实体间的内在联系,将实体和关系投影到隐语义空间以进行相似度计算。以RESACL[20-21]为代表的模型,采用矩阵分解来进行知识图谱表示学习,利用三元组构建一个大矩阵,然后将矩阵分解为实体和关系的向量表示。为了精确刻画实体和关系间的语义联系,文献[22]提出了单层神经网络模型,该模型能够使用非线性变换为实体和关系提供微弱的关联,但其计算复杂度大幅提高。张量神经网络模型使用双线性张量取代传统的线性变换层,能够更精确地刻画实体和关系的语义联系,但其训练需要大量数据,不适用于稀疏知识图谱。文献[23]基于卷积神经网络构建一种融合实体文本属性的学习模型,该模型使用低秩矩阵对头实体和尾实体进行映射,从而更好地表征复杂关系。
2 TransGraph知识表示方法
TransE模型简单,参数较少,计算效率较高,但其独立地学习单个三元组,忽略了三元组形成的复杂网络关系,因此,TransE难以处理三元组中1-N、N-1和N-N等问题。为此,本文基于TransE提出一种TransGraph模型,以在学习三元组的同时有效融合知识图谱的网络结构特征。
为了更好地描述知识图谱和相应的算法模型,本文给出相关的定义和符号表示。将知识图谱记作G=(E,R,S),其中,E是实体集,R是关系集,S⊆E×R×E表示三元组的集合,集合中的每一个元素用(h,r,t)表示,h、r和t分别表示头实体、关系和尾实体。知识表示学习的目的是将实体和关系映射为低维稠密的向量V(h)、V(r)和V(t)。TransE采用最大间隔法来增强知识表示的区分能力,其目标函数定义如下:
d(h,r,t)=|V(h)+V(r)-V(t)|L1/L2
其中,[x]+表示x的正值函数,l是间隔距离参数,S′是三元组集S的负采样集,d(h,r,t)是向量V(h)+V(r)和V(t)之间的L1或L2距离。
2.1 网络结构特征学习
在知识图谱网络中,有2种拓扑结构能够描述目标实体,一种是目标实体和相邻实体组成的邻接结构,如图1所示,另一种是从一个实体到目标实体的关系路径[11],如图2所示。如果采用TransE从图1的三元组中学习知识表示,将会使得“奥巴马”“布什”和“特朗普”的向量相同,造成实体表示的区分度低,原因是TransE模型独立学习三元组,在处理复杂关系时存在不足。邻接结构反映了实体间的1-N和N-1等多重关系,因此,在表示学习过程中结合网络结构特征能够捕获到网络中隐含的复杂关系,从而有效改善TransE的不足。
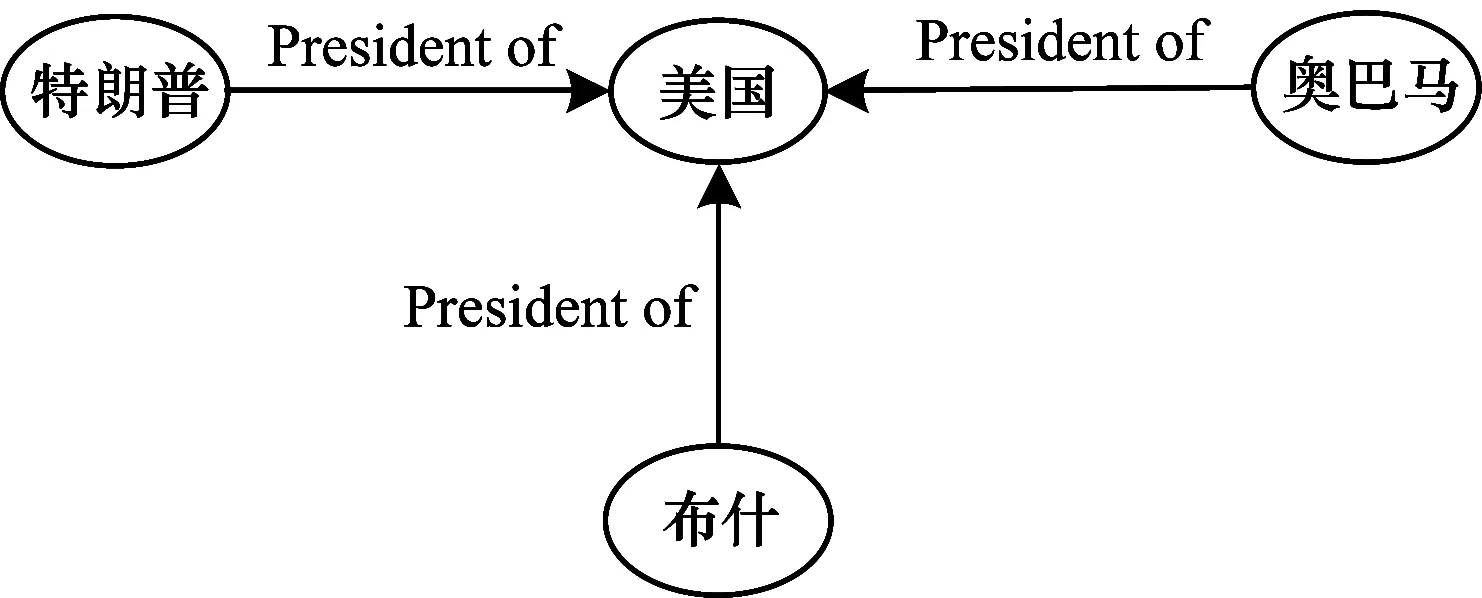
图1 邻接结构
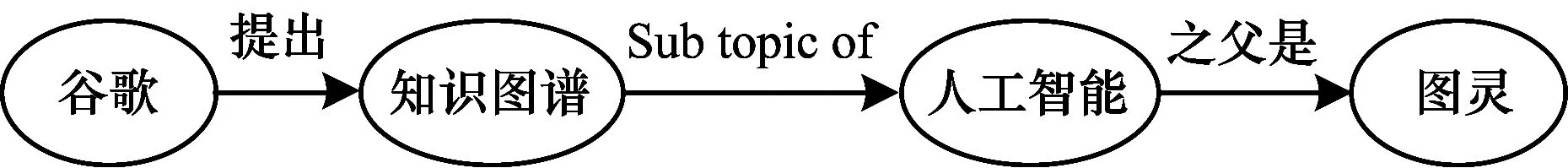
图2 关系路径
Fig.2 Relationship path
从直觉上来看,在知识图谱中,拓扑结构相似的实体应该具有相近的向量表示。局部线性表示假设节点在较小的局部区域内是线性的,即一个节点的表示可以由多个邻居节点的表示线性组合近似得到。文献[24]研究表明,网络中节点的邻居节点集合对于表征节点间的结构相似性具有重要意义,邻接结构相似的实体往往具有相近的语义。
根据目标节点到邻居节点的距离,将目标节点的邻接结构分为一阶近邻结构和多阶近邻结构,一阶近邻结构特征的学习过程如下:类似于CBOW模型利用上下文预测目标单词,本文将邻居实体和关系集视作一种特殊的“上下文”,在已知实体邻接结构的情况下预测实体的概率,即通过最大化目标实体的预测概率来学习知识图谱中的一阶近邻结构。例如,在图1中用(奥巴马,President of)、(布什,President of)和(特朗普,President of)来预测“美国”的概率值。将邻居实体和关系作为输入,目标实体作为输出,构建3层神经网络如图3所示。

图3 一阶近邻神经网络模型
以预测概率为学习目标,定义一阶近邻结构学习目标函数如下:
其中,Nr_1(t)表示尾实体t的一阶近邻,Nr_1(t)={(h1,r1),(h2,r2),…,(hn,rn)}。投影层的中间向量作为一阶近邻结构的表示向量,采用累加求和的方式计算:

p(t|Nr_1(t))概率值的计算是典型的分类问题,本文使用softmax函数进行计算:
其中,E表示实体集,yt是实体t未归一化的概率,计算如下:
yt=b+UXt
其中,b、U是softmax函数的参数。
在知识图谱中,一阶近邻是十分稀疏的,因此,本文考虑使用多阶近邻实体和关系的向量来表示目标实体向量。假设目标实体t存在一个n阶近邻的实体h,则从h到t构成了一条n步的关系路径。在知识图谱中,多步的关系路径往往能够表征实体间的语义关系,文献[16]基于关系路径预测实体间的关系。为了构建关系路径向量,PTransE对路径上的所有关系进行语义组合,如图4所示。
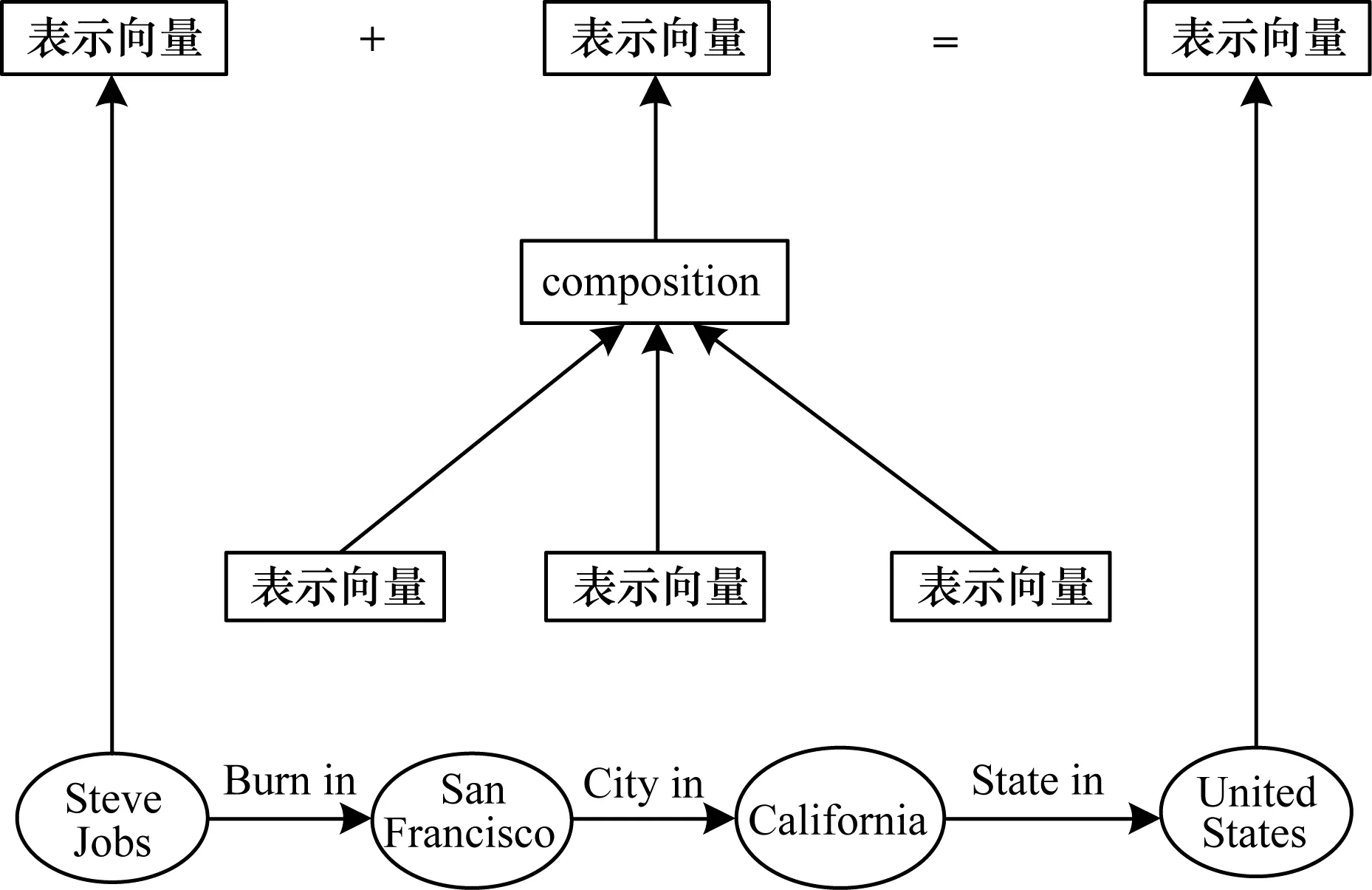
图4 关系路径向量
对于多阶近邻结构,本文考虑使用近邻实体到目标实体的多条关系路径来表示目标实体。类似于一阶近邻结构学习,本文将多个关系路径向量作为输入,目标实体作为输出,构建3层神经网络模型,如图5所示。
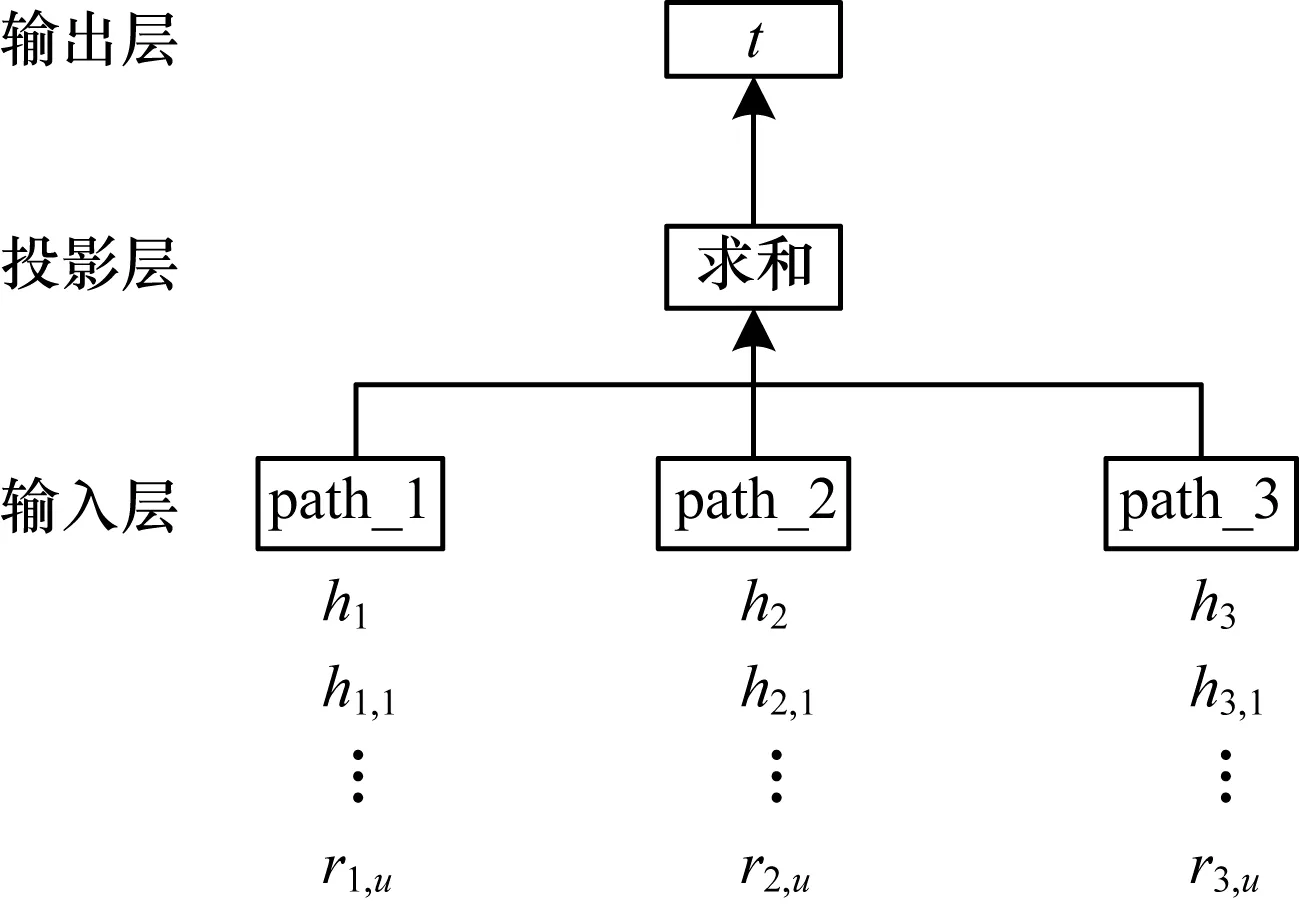
图5 多阶近邻神经网络模型
定义n阶近邻结构学习目标函数如下:
其中,Nr_n(t)表示所有小于等于n阶的近邻实体到尾实体t的关系路径,Nr_n(t)={path1,path2,…,paths},pathi=(hi,r1,r2,…,ru),hi表示近邻的实体,r是路径上的关系,1≤u≤n。投影层的中间向量采用累加求和的方式计算:

同样采用softmax函数计算p(t|Nr_n(t))概率值,此处不再赘述。
2.2 混合特征学习
当前多数方法独立地学习三元组而忽略了知识图谱的结构特征,为了解决这一问题,本文利用近邻结构特征作为补充,进一步增强知识图谱的表示效果。模型的目标优化函数如下:
L=ηLn+LTransE
其中,η是平衡结构特征和三元组特征的学习参数,通过不断调整权重能更好地将模型应用于不同数据场景。一方面,目标函数L利用n阶近邻向量预测目标实体,使得表示向量包含图谱的结构特征;另一方面,表示向量又参与了TransE模型中的三元组表示学习训练。为了实现图谱结构信息和三元组信息的深度融合,本文提出一种向量共享的交叉训练机制,如图6所示,其中,左右两部分模型交替训练,实体和关系向量在2个模型中共享,通过不断地迭代训练来更新向量,最终得到融合后的向量表示。
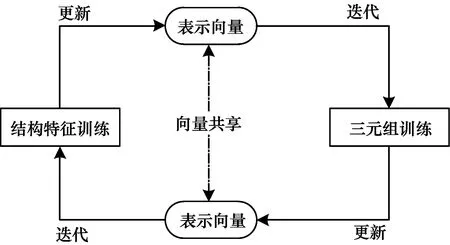
图6 交叉训练机制
为了提高模型的训练速度,研究人员通常使用hierarchical softmax替代softmax。当计算p(t|Nr_n(t))时,hierarchical softmax以实体和关系作为叶子节点,将实体和关系在三元组集S中出现的频率作为节点的权,构造一颗哈夫曼树。对于每一个实体或关系v,哈夫曼树中必然存在一条从根节点到v对应节点的路径pv,v出现的频率越高,则路径的长度越短。在路径pv上存在lv个分支,每个分支都视作一次二分类并产生一个概率,将分支产生的概率相乘便得到p(t|Nr_n(t))的值。因此,得到:
其中,有:

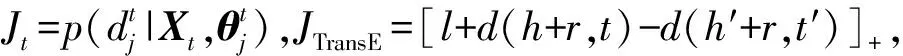
算法1TransGraph训练算法
输入triple setS,vector sized,marginl,learn rateα,balance rateη

1.Build Huffman Tree from S
2.Initialization V
3.for each epoch∈epochs do
4.for each(h,r,t)∈S do
5.for each(h′,r,t′)∈T′(h,r,t)
6.V(h):=V(h)+α*η*∂JTransE/∂V(h)
7.V(r):=V(r)+α*η*∂JTransE/∂V(r)
8.V(t):=V(t)+α*η*∂JTransE/∂V(t)
9.end for
11.u=0
12.for j=1:ltdo
14.u:=u+α*∂Jt/∂Xt
15.end for
16.for path∈Nr_n(t) do
17.for each e∈path
18.V(e):=V(e)+u
19.end for
20.end for
21.end for
22.end for
算法1的流程及复杂度分析如下:
2)分析算法的时间复杂度和参数复杂度。假设每次负采样K个三元组,则TransE部分的时间复杂度为O(|S|·k)。在邻接结构特征学习的梯度计算过程中,传统的softmax需要对m+n个实体和关系计算概率,采用hierarchical softmax只需计算lt次,lt数量级为lb(m+n),故此部分的时间复杂度为O(|S|·lb(m+n))。综上,算法1的整体时间复杂度为O(|S|·(k+lb(m+n))),算法的参数是共享向量和辅助向量,参数复杂度为O((m+n)d)。
3 实验结果与分析
本文采用WN11、WN18、FB13和FB15K等多个数据集验证和评估TransGraph模型的有效性。其中,WN11和WN18是WordNet的子集,FB13是Freebase的子集,FB15K是基于Freebase抽取得到的一个稠密子集。实验数据集的详细信息如表1所示。

表1 数据集统计信息
实验主要包括链路预测和三元组分类2个任务,以从不同角度评估模型的预测能力和精确度。TransGraph模型的效果受数据规模、数据类型、参数设定等因素影响,实验将针对不同因素分别进行测试。选择三类不同的模型进行比较:1)基于TransE的距离模型,以TransH、TransR、TransA和TransG为代表,这类模型采用矩阵映射和高斯混合等方式对TransE进行优化,且取得了较好效果;2)以SME为代表的语义匹配模型;3)基于矩阵分解的RESCAL模型。
3.1 链路预测
链路预测的主要过程是对于一个完整的三元组(h,r,t),实验给定(h,r)后预测t或给定(h,t)后预测r,从而验证模型预测实体的能力。本组实验采用WN18和FB15K两个数据集。
3.1.1 评价标准
本次实验采用和TransE相同的标准,以便与TransE等现有模型进行对比。首先,对于测试集中的每一个原始三元组(h,r,t),随机丢弃头实体h或尾实体r,得到(r,t)或(h,r);然后,从实体集中随机选择一个实体补全(r,t)或(h,r),得到变异三元组(e,r,t)或(h,r,e);最后,利用得分函数fr(h,e)计算原始三元组和变异三元组的得分,并对得分结果进行排序,从而得到原始三元组的排序分数。
通常通过平均排序得分(MeanRank)和排序不超过10的百分比(HITS@10)2个指标来度量原始三元组的排序结果。MeanRank越低、HITS@10越高,意味着实验结果越好。需要注意的是,如果变异三元组仍然在知识图谱中存在,说明该三元组刚好由一个原始三元组变异为另一个原始三元组,在实验中这种三元组会干扰原始三元组的排序得分。为了消除上述干扰,在生成变异三元组集时需要过滤掉干扰三元组,以保证变异三元组不属于训练集、验证集和测试集等,这一过程称作Filter。未经Filter过程的实验设置称作Raw,Filter后的实验结果往往更好,拥有更低的MeanRank和更高的HITS@10。
3.1.2 实验过程
在训练TransGraph时,学习率α设为{0.01,0.1,1},间距l设为{0.25,0.5,1},向量维度d设为{20,50,100},模型间的平衡率η设为{0.01,0.1,1,10},近邻结构阶数n设为{1,2,3}。经过多次实验得到最优的参数配置如下:在FB15K数据集中,α=0.01,l=1,d=50,η=0.1,n=2;在WN18数据集中,α=0.01,l=1,d=20,η=0.1,n=2。TransGraph与TransE等现有模型的实验对比结果如表2、表3所示。
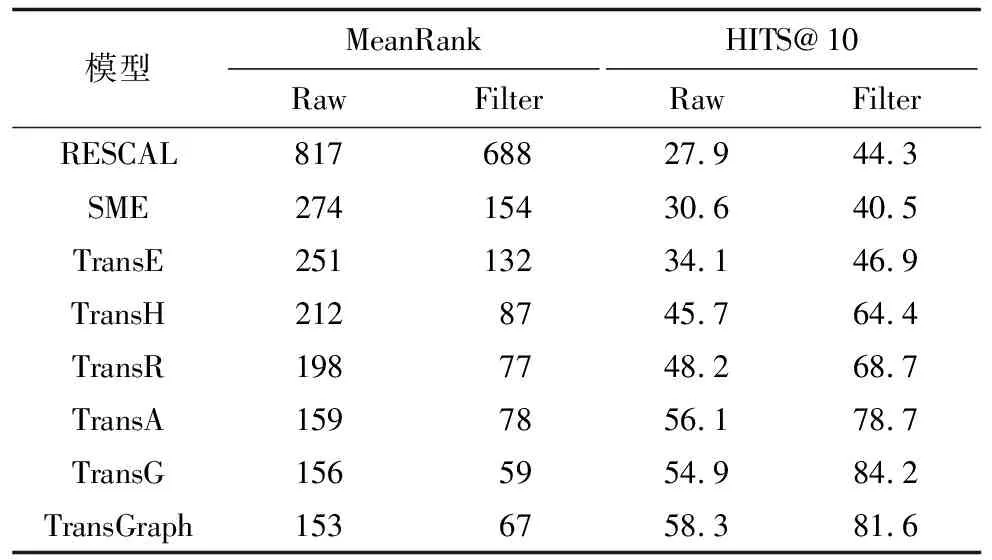
表2 FB15K数据集上的实验对比结果
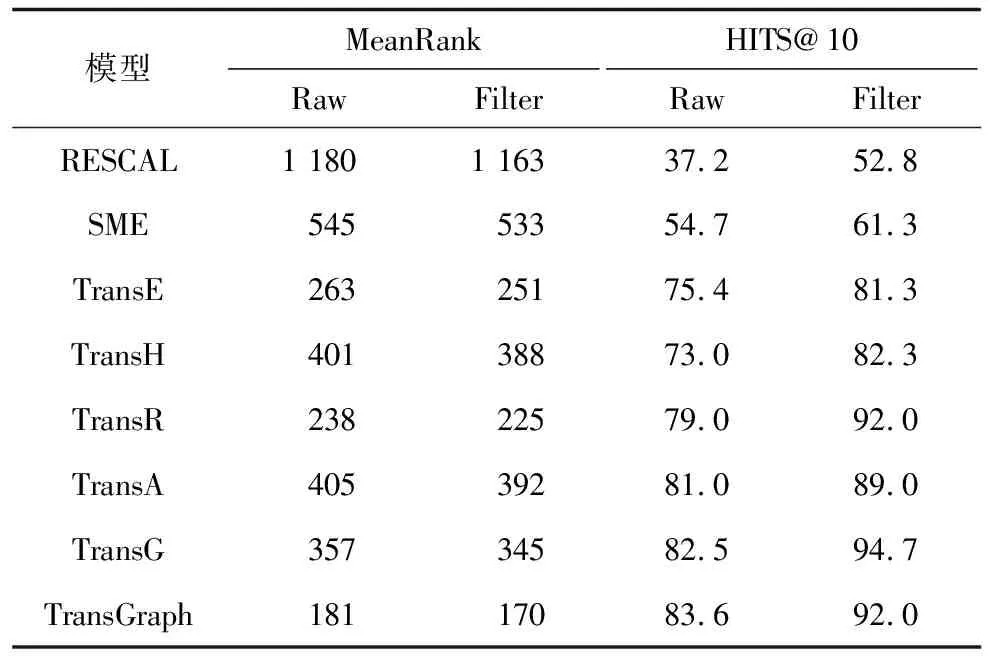
表3 WN18数据集上的实验对比结果
从表2、表3可以看出,与TransE模型相比,TransGraph的MeanRank指标更低,HITS@10指标更高,在FB15K数据集上提升39.3%,在WN18数据集上提升30.4%,该结果进一步说明了将TransE和Skip-gram相结合后在表达复杂关系的场景中拥有较大优势。需要注意的是,相较于WN18数据集,TransGraph在FB15K数据集上的MeanRank指标值更低,主要原因是FB15K是一个更加稠密的数据集,三元组组成的知识图谱拥有更复杂的网络结构,TransGraph更能发挥网络结构特征学习的优势。因此,TransGraph能够更好地处理三元组中1-N、N-1和N-N等问题,进而完成知识获取、知识融合和知识推理等。
3.2 三元组分类
三元组分类任务用于验证模型识别原始三元组和变异三元组的能力,对于给定的三元组(h,r,t),模型需要对三元组进行二元分类。在本次实验中,使用WN11和FB13数据集,采用和链路预测同样的方式生成变异三元组。分类的标准是对于一个给定的三元组(h,r,t),计算得分函数fr(h,e),如果得分低于一个阈值σ,则将三元组分类为原始三元组;如果高于阈值,则将三元组分类为变异三元组。若三元组分类正确,则给三元组生成正标签,反之则生成负标签。
在实验过程中,设置TransGraph的学习率α={0.01,0.1,1},间距l={0.25,0.5,1},向量维度d={20,50,100},模型间的平衡率η={0.01,0.1,1,10},近邻阶数n={1,2,3}。经过多次实验得到最优的参数配置如下:在FB13数据集中,α=0.01,l=1,d=50,η=0.1,n=2;在WN11数据集中,α=0.01,l=1,d=20,η=0.1,n=2。TransGraph与TransE等现有模型的实验对比结果如表4所示。
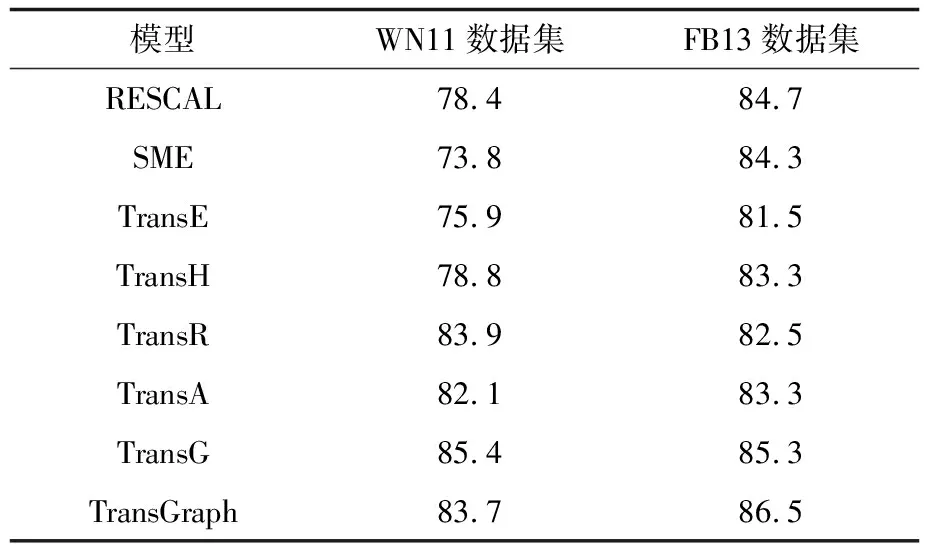
表4 三元组分类准确率对比
Table 4 Comparison of accuracy rate of triple classification %
模型WN11数据集FB13数据集RESCAL78.484.7SME73.884.3TransE75.981.5TransH78.883.3TransR83.982.5TransA82.183.3TransG85.485.3TransGraph83.786.5
从表4可以看出,相较于TransE模型,TransGraph的准确率在WN11数据集上提升10.3%,在FB13数据集上提升6.1%。因为FB13的关系数量和实体数量都大于WN11,即FB13是一个密度更大、关系更复杂的数据集,所以TransGraph模型在FB13数据集上的分类效果更好。在实验过程中,η的取值范围是{0.01,0.1,1,10},通过不同的取值能够探究网络结构特征对实验结果的影响。当η=0.1时,模型在数据集中取得最优性能;当η较小时,网络结构特征对表示向量的影响较弱,因此,模型在处理复杂关系时效果不佳;当η较大时,三元组(h,r,t)对应的表示向量不满足V(h)+V(r)≈V(t)这一约束条件,导致模型的翻译能力下降。
4 结束语
传统基于距离的翻译模型存在无法处理复杂关系和忽略知识图谱网络结构的问题,导致知识表示的效率不高。为此,本文提出一种同时学习三元组和知识图谱网络结构特征的TransGraph模型。在WN11、WN18等公开数据集上对链路预测和三元组分类2项任务进行实验,结果表明,与TransE等模型相比,TransGraph的准确率较高。但是,本文仅研究三元组及图谱结构,忽略了实体的描述文本和互联网文本等信息,因此,下一步考虑将多源信息进行融合以优化TransGraph模型。
