基于改进SSD模型的高铁扣件定位算法
2020-05-18李兆洋李柏林罗建桥
李兆洋,李柏林,罗建桥,欧 阳
(西南交通大学机械工程学院,成都 610031)
铁路扣件是保障铁路沿线正常运营的重要部件。受多种因素的影响,扣件会出现断裂、丢失等异常状态,这将会对列车的运行带来严重的安全隐患[1-12]。随着我国高速铁路的发展,实现自动化的扣件检测将成为必然。扣件定位作为扣件检测的重要一环,引起了研究者们越来越多的关注。
近年来,国内外提出了多种扣件定位方法,包括传统的视觉方法和深度学习方法。文献[13]采用改进的Rank变换窗口以突出图像中的垫板与轨枕接触的边界信息,完成扣件区域的定位。文献[14]利用canny算子提取图像的边缘特征,然后通过LSD直线提取钢轨边缘坐标并结合先验信息实现扣件定位。因该算法中的阈值选择过于敏感,对不同光照下的扣件定位适应性很差。龙炎等[15]采用Faster R-CNN深度卷积神经网络搭建了一套高铁扣件检测系统,因其网络结构的计算量巨大,导致检测速度较慢。扣件的定位仍存以下两个方面的难点:(1)扣件的目标较小。道岔处扣件图像中的背景极其复杂,准确区分扣件和背景需要较强的特征提取能力。(2)图像质量变化大。户外天气变化引起的图像光照不均、车辆振动造成图像模糊等,都严重影响图像的质量,对扣件的定位带来巨大的影响。
基于上述分析,提出一种膨胀残差网络结合SSD[16]深度学习的扣件定位算法。通过采用ResNet增加网络的深度,提高扣件特征的提取能力。利用膨胀卷积和非极大加权抑制,提高扣件定位的稳定性和输出框的准确性,实现快速定位的同时提高了定位的精确度。
1 经典SSD检测模型框架
SSD是由Liu等人提出的一种快速高效的目标检测方法,由Faster R-CNN和YOLO[17]的检测模型衍生而来,其检测框架如图1所示。SSD的检测框架主要由两部分构成:第一部分是位于前端的卷积神经网络,经典模型中为VGG16,用于目标初步的特征提取;第二部分是位于后端的多尺度特征检测网络,对前端网络产生的特征层进行不同尺度条件下的特征提取。图1中的SSD在Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2特征层的每一个单元中按照不同长宽比分别提取4~6个默认框。
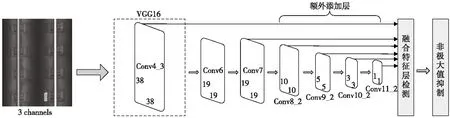
图1 SSD检测框架
模型训练时,检测框架的总体目标损失函数用位置损失(Lloc)和置信损失(Lconf)的加权和表示,如式(1)所示:

(1)
式中,N表示匹配到真实目标的先验框(prior box)的数量;l表示先验框;g表示真实的框;c是Softmax函数对每类别的置信度;α参数用于调整位置损失和置信损失之间的比例,默认α为1。
置信损失如式(2)所示

(2)
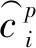
置信损失如式(3)所示

(3)

(4)

平滑L1损失如式(5)所示

(5)
模型测试时,每个默认框都和标注框进行重叠率匹配,并按照匹配分数从高到低排序,利用非极大值抑制[18]的方法,将检测结果最优化。
2 改进的SSD模型
2.1 残差网络提取深度特征
在分辨率为900×1 100的轨道图像中,单个扣件的分辨率仅为50×70,因此扣件在轨道图像中占的尺寸很小。原始SSD中,首先采用VGG16模型提取特征,然后使用Conv4_3层的特征层来检测小目标,因此,小目标的特征提取不丰富,检测的精度不高。文献[19]的相关研究表明,通过增加网络层数可以丰富特征,目标检测的精度也会随着网络层数深度的增加而提高。然而,随着神经网络深度的不断加深,模型的学习能力会在某个深度达到稳定,继续增加模型的层数时,模型前面一个细小改变都会在模型后面引起很大的变化,即出现“梯度消失”或“网格退化”现象,但退化问题并不是由过拟合引起的,而是过多的层数及参数导致网络难以找到最优解。因此,He等[20]提出了残差网络(Residual Network),该网络结构使得更深的网络更容易训练,因而可通过增加网络层数提高识别准确率。具体而言,即两个或两个以上连续的神经网络层形成一堆叠层,在这个堆叠层上添加一个快捷连接(Shortcut Connection),实现快捷连接的过程叫恒等映射(Identity Mapping),即输入跳过堆叠层直接连接到堆叠层的输出位置,如图2所示。
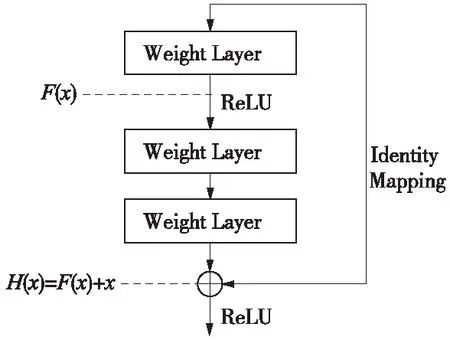
图2 残差模块
残差网络通过自动拟合获得残差函数F(x)并与输入的特征图x相加,从而生成输出特征图函数H(x),如式(6)所示
H(x)=F(x)+x
(6)
2.2 膨胀卷积提高鲁棒性
扣件在定位过程中存在较多的干扰因素,如天气、光照、扣件损坏、道岔背景复杂等,不同的干扰因素均会引起定位不准、定位稳定性不高的问题。准确的定位扣件需要考虑目标附近的邻域信息,以增强判断的依据。原始SSD网络中,对于扣件的定位鲁棒性较差,主要是因为基础模型采用VGG16的低层特征层检测小目标,低层卷积层虽然分辨率高,但感受野较小,语义信息也很低,对于扣件信息的提取不充分,边缘结构也会有一定的丢失,不能满足扣件定位的鲁棒性。
因此,本文采用膨胀卷积的方式,通过在原始卷积的基础上增加了膨胀参数d,将卷积核扩张到膨胀系数所约束的尺度中,并将原卷积核中未被占用的区域填充0,在不减小图像大小的同时获得比较大的感受野。传统卷积运算和膨胀卷积运算公式分别如式(7)和(8)

(7)

(8)
图3显示了不同膨胀系数下的感受野。其中,图3(a)表示d=1的膨胀卷积核,与普通的卷积操作相同,感受野为3×3;图3(b)表示d=2的膨胀卷积核,感受野为7×7;图3(c)表示d=4的膨胀卷积核,感受野为15×15。
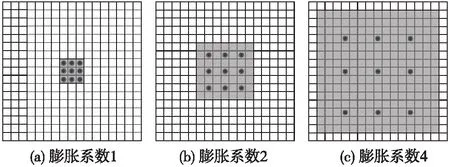
图3 膨胀卷积
将ResNet101与膨胀卷积结合。ResNet101具有101层网络结构,总体上分为5个区块,每个区块包含若干的残差模块单元。假定残差网络输入的图像尺寸为300×300,原来第五层卷积层的输出特征图为10×10,特征图的分辨率缩小为原来的1/30,特征图分辨率的降低会造成影像大量局部细节信息的丢失,严重影响目标识别结果对边缘结构信息的保留能力。在原始残差网络的前三层中,对原始的输入进行近8倍的降采样,特征图的尺寸为38×38;在最后两层的输出相对于输入分别降低了2倍和4倍,38×38的分辨率足够识别图像场景的结构,并且保存了图像的大多数信息。因此,为了解决信息丢失的问题,对原始残差网络区域块中第4层和第5层进行膨胀系数为2和膨胀系数为4的膨胀卷积,这样能够使信息最大程度的保留,使感受野和第三层输出的相同,而不增加新的参数。
采用膨胀卷积残差网络的优点如下:(1)在保持卷积核参数大小不变的同时,增大卷积的视野。无需通过下采样处理降低特征图的分辨率,也可以学习到高层的语义特征,解决边缘结构信息丢失的问题;(2)未引入额外参数,能够保证一定的计算速度。由于使用了不同的膨胀系数,能够获得不同的感受野,在进行特征下采样也可以改善对于扣件这种小目标检测精度不高的问题,增加了鲁棒性。
2.3 非极大加权抑制
在后续的扣件状态检测过程中,需要判断扣件的状态,如丢失、断裂、异位等,而扣件定位的精度可以提高在扣件状态检测过程中的准确率和效率,因此扣件定位的精度显得至关重要。原始SSD通过非极大值抑制(Non-Maximum Suppression,NMS)的方式来产生最后的定位结果,当IoU(Intersection over Union)的值高于设定的阈值时,找到的一组边框被认为是同一类目标,通过选择最高置信度的框为最后的输出框。但通过选择最高置信度的框会存在遗漏一些包含最大特征但置信度并非最高的预测框。因此,提出一种通过加权的方法来获取最终输出框的算法,即非极大加权抑制(Non-Maximum weighted Suppression,NWS)。
当扣件作为目标确定时,会产生一系列预测框,通过加权来确定最终的输出框
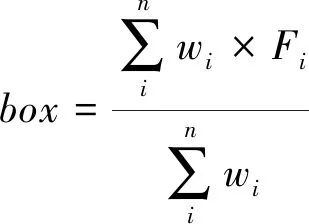
(9)
wi=Ci×iou(Fi,Farg maxCi)
(10)
式中,box为最后的输出框;w为每一个预测框的权重;Fi为扣件预测框的集合;Ci为第i个预测框的置信度;iou(Fi,Farg maxCi)为第i个预测框和最大置信度预测框的交互比;n为预测框的数量。
2.4 算法整体流程
改进的SSD深层网络模型流程如图4所示。输入的图像为300×300的RGB图像,通过一系列的卷积运算后,在Res3b3_ReLu层达到分辨率为38×38,从res3b3_relu层至res5c_relu层的过程中,采用膨胀卷积残差模块;在区块4中采用如图3(b)所示的膨胀系数为2的膨胀卷积;在区块5中采用如图3(c)所示的膨胀系数为4的膨胀卷积,通过膨胀卷积增大了感受野,同时不增加新的参数。因此可以不通过下采样处理来降低特征图的分辨率,也可学习到比较高层的语义特征,提高对扣件特征的表征能力,保留更多的扣件细节。

图4 改进的SSD模型
此外,改进的模型在膨胀卷积残差网络后额外添加了8个卷积层和1个池化层,在其中的Conv1_2、Conv2_2、Conv3_2、Conv4_2上添加相应的默认检测盒,后续的特征层检测需要对检测盒进行检测,因此,图4中只画出添加检测盒的4个卷积层。新添加的卷积层Conv1_2的分辨率为19×19,Conv2_2的分辨率为10×10,Conv3_2的分辨率为5×5,Conv4_2的分辨率为3×3,最后的池化层为均值池化。不同卷积层的卷积核大小不同,其中:1×1的卷积核在不同的通道之间做线性变化,可以跨通道聚合,它的通道数为256;3×3的卷积核,则有512个通道,具体的卷积层对应的感受野与通道数如表1所示。
在最后的检测阶段,将每一个预测框与标注框进行重叠率匹配,利用非极大加权抑制的方法,对检测结果进行约简。

表1 额外添加层
3 实验分析与讨论
3.1 实验数据及设置
本文的实验数据是由国内某高铁工务段提供的真实扣件图像,其中包含普通轨道图像7 000张,道岔轨道图像3 000张。部分样本图像如图5和图6所示。为增加模型训练样本选取的随机性,采用十折交叉验证的方式验证实验结果。具体而言,将原始数据均分为10个子集,选择其中的9个子集作为训练集,余下的那个子集作为验证集,因此总共进行10次验证实验。将10次实验的平均值作为最终的结果,从而有效提高训练模型的泛化能力。

图5 普通轨道

图6 道岔轨道
数据集的标注包括目标的类别和位置信息。其中位置信息是标注框的左上角和右下角坐标,用于评测模型精确度时,根据输出框与标注框的重合率大小判定匹配分数,为网络模型提供了预定义输出。
3.2 实验平台及参数配置
本文的运行环境为Windows10,软硬件配置包括:GPU为NVIDIA GTX1080Ti,CPU为Intel Core i7-6700 3.4 GHz,内存32GB,CAFFE,Python 3.6,深度学习网络加速库为CUDA 8.0结合CUDNN 5.1。
由于融合模型的复杂程度较大,因此总迭代次数设置为60 000次。其中,前3×104次迭代的学习率设置为10-4,后3×104次迭代的学习率设置为10-5,动量设置为0.9,图像批处理大小设置为32,权重衰减设置为5×104。
3.3 模型训练与结果分析
3.3.1 评价指标
本文选用广泛使用的召回率(Recall)和精度(Precision)对算法的性能进行定量评价。其中,召回率表示图像中真实扣件被正确识别的比例,用R表示;精度表示正确预测的检测框占所有检测框的比例,用P表示。计算公式如下
(11)
式中,TP为正确识别的扣件数;FP为错误识别的扣件数;FN表示没有识别出的扣件数。此外,定位速度也是扣件定位过程中的一个重要性能指标,定义为1 s处理的图像数目,用FPS表示。
3.3.2 实验结果
为验证本文算法对扣件定位的准确性和鲁棒性,分别选用经典SSD模型和多种扣件定位算法进行对比实验,分别介绍如下。
(1)与经典SSD模型的对比
选用SSD+VGG16作为对比算法,为保障实验的公平性,其学习率、权重衰减、总迭代次数与本文算法的设置保持一致。实验结果如表2所示。

表2 不同算法定位召回率和精度
从表2可以看出,本文算法取得了更好的召回率R和精度P。原因在于:与SSD+VGG16相比,本文方法通过使用Resnet101网络增加了神经网络的深度,提高了模型对特征的抓取能力,从而有效地区分扣件和背景,召回率R提高了3.4%,而采用膨胀卷积的方式,扩大了感受野,解决扣件边缘结构信息丢失的问题,增加了扣件定位的鲁棒性,此外,采用非极大加权抑制的方法使得输出框的位置更加精确,精度P提高了4.7%。部分样本定位结果如图7和图8所示。

图7 经典SSD定位结果

图8 改进的SSD定位结果
(2)与其他扣件定位算法对比
将本文方法与文献[13-15,17]中的算法进行对比。文献[13]中Rank+LSD中的阈值T设为0.8,文献[14]中Canny+LSD的模型参数与原文一致,文献[15]中Faster RCNN以及文献[17]中YOLO的总迭代次数均设置为60 000次,学习率和权重衰减等参数与本文算法设置一致。结果如表3所示。
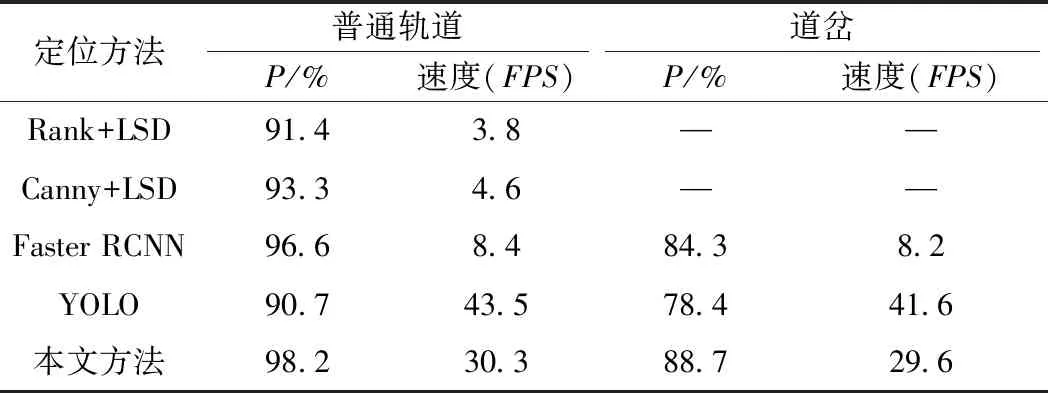
表3 不同算法定位性能
从表3可以看出,在普通轨道上,Rank+LSD对于扣件的错误定位较多,速度较慢,并且该方法只适用于特定轨道扣件,通用性较差。Canny+LSD算法由于Canny算子的阈值过于敏感,对不同光照的扣件定位效果一般,速度较慢,此外,这两种算法无法对道岔处的扣件进行定位。Faster RCNN采用滑动窗口遍历全图的方式定位扣件,因此速度较慢。YOLO采用了较少的重复候选框,虽提高了速度,但在每个单元格只预测两个边界框,导致扣件定位的精度较低。本文方法不仅增加了网络的深度,而且增大了感受野,没有引入额外的参数,保证了一定的速度,有效利用了图像的语义信息,定位精度在普通轨道区域和道岔区域明显提高,分别为98.2%和88.7%。本文算法对不同轨道不同天气的定位样本如图9所示。

图9 扣件最终定位结果
4 结语
针对传统视觉方法定位扣件时存在的速度慢、精度低,且无法定位道岔轨道处的扣件问题,提出了一种改进的SSD网络模型。改进的模型首先采用膨胀残差网络更新原有的VGG网络,然后通过非极大值加权抑制的方式来提高最终输出框位置的精度。因此,改进的算法不仅继承了经典SSD网络定位速度快的优点,而且改善了经典SSD网络对于小目标定位精度差的缺点。实验结果表明,改进的模型有更强的特征提取能力,而感受野的增加使模型的鲁棒性更强,相较于其他主流定位算法,效果更好。
