弱分层交互Lasso罚loGistic回归模型和改进坐标下降算法①
2020-05-14王金甲
李 静 于 辉 王金甲
(*燕山大学理学院 秦皇岛 066004) (**燕山大学信息科学与工程学院,河北省信息传输与信号处理重点实验室 秦皇岛 066004)
0 引 言
目前高维数据回归问题的稀疏性使线性方法如Lasso获得了巨大的成功[1]。Lasso是L1罚的最小二乘回归,也可以推广到广义线性模型[2],例如L1罚的loGistic回归用于分类[3]。响应变量是预测变量的线性加权和,加权系数可通过坐标下降法求解[4]。在分析高维数据时响应变量可能不能用预测变量的线性加权和来解释,那么就需要使用2次模型和高次模型。这有可能说明存在特征交互问题[5]。例如单核苷酸多态性(SNPs)间的交互被认为在癌症和其他疾病诊断中起着重要的作用[6]。线性模型可解释性好、计算简单的优点使得考虑特征交互的模型成为研究热点和难点[7]。特征交互的分层模型的方法可以分为3类:第1类是多步骤方法。一旦交互特征对应的预测变量在模型中,那么交互特征也必须在模型中[8]。或者先考虑变量选择后考虑交互[9],采用修正的最小角回归算法求解分层模型[10]。第2类是贝叶斯方法,例如改进随机搜索变量选择方法用于分层模型[11]。第3类是基于优化的方法,将稀疏交互分层模型用公式表示为非凸优化问题[12],进一步将非凸优化表达为凸优化问题如Lasso[13]和Group Lasso问题[14]。在结构稀疏文献中[15],复合绝对处罚(composite absolute penalties ,CAP)也能获得分组和交互稀疏,但是交互特征系数被罚了2次[16]。文献[17]的方法解决了在非线性交互问题上的分层稀疏性。也有文献研究特征交互但不分层的方法,如考虑二值变量高阶交互的loGistic回归方法[18],从高维数据中选择交互特征的研究[19],从高维数据中的多元数据图表示的交互特征中采用遗传算法优选特征[20]。
Bien等人[13]提出了将交互分层Lasso方法用于回归,基于卡罗需库恩塔克(Karush-Kuhn-Tucker, KKT)条件和拉格朗日乘子法给出了系数解,并给出了参数稀疏和实际稀疏的概念。但是没有采用坐标下降法。本论文在已有交互特征研究基础上,提出了几何代数变量交互的概念,给出了弱分层交互Lasso方法用于loGistic回归模型,并通过改进的坐标下降法求解加权系数。本论文创新在于:第1,用几何代数解释了变量交互;第2,将文献[13]的弱分层交互Lasso推广到loGistic回归;第3,推导了改进的坐标下降算法用于模型求解。实验数据采用了UCI机器学习数据库的4种数据集和1个真实的日常生活活动识别数据集,并与多种方法进行了比较,实验结果表明分层交互Lasso的分类性能优于Lasso、交互Lasso和传统方法。分层交互Lasso方法在处理数据时兼具Lasso和交互Lasso的优点。
1 几何代数的变量交互理论
定义1如果函数f(x,y)不能被表示为独立的f1(x)+f2(y),则x,y在函数f上存在交互。
定义2通俗的解释如下,如果响应变量不能用预测变量的线性加权和来表示,这很可能说明变量间存在交互。
变量间交互可以很容易用几何代数理论加以解释。图1是几何代数各级子空间示意图,其中1阶向量可以表示原始数据的p维坐标子空间,即原始数据的p维变量是在1阶向量上的投影值。2阶向量表示2种变量间的交互,最简单的2阶向量系数可以是2个1阶向量间的交互变量,文献[13]的变量交互采用的是面积特征,文献[20]的变量交互采用的是重心特征。依次类推,k阶向量表示高阶交互。本文只研究了1阶主变量与2阶面积交互变量。本文方法也可以推广非线性复杂函数形式或高阶交互。
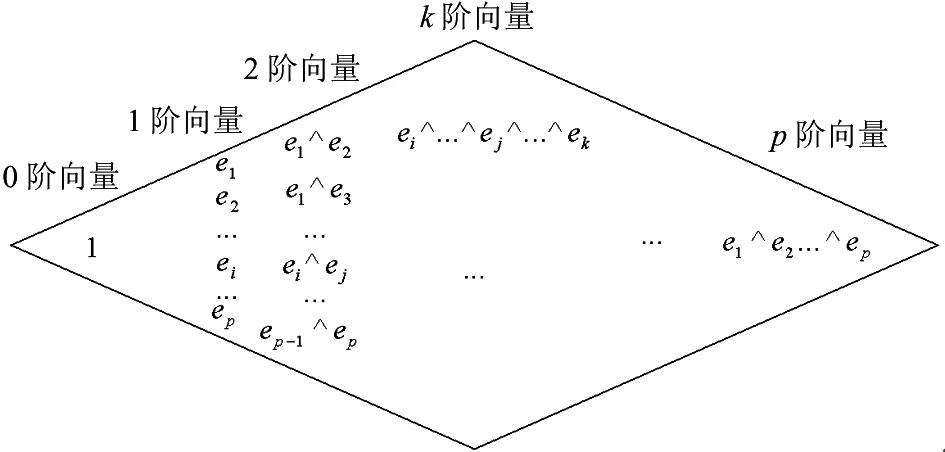
图1 几何代数各级子空间示意图
2 考虑交互和分层的二值loGistic回归模型
假设模型样本输出为Y,输入X为p维变量(x1,…xj,…,xp),样本在每维输入变量间都存在几何代数面积交互项xjxk。则含有2次交互项的loGistic回归模型具有以下形式:
(1)
其中,x0为1,xj表示1阶主变量,xjxk表示几何代数2阶面积交互变量, 1阶主变量系数β∈Rp+1,2阶面积交互变量系数Θ∈Rp×p是对称变量系数矩阵,Θjj=0,ε~N(0,σ2)。
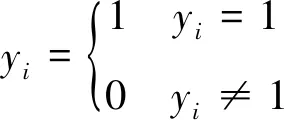
P(yi=1|xi)
(2)
P (yi=0|xi)
(3)
通过极大似然估计拟合模型式(1),使N次独立观测的似然函数L(β,Θ)最大:
(4)
对L(β,Θ)求取对数可得到对数似然函数:
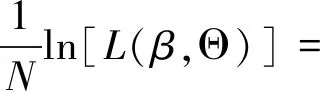
+ln(1-p(xi)]
(5)
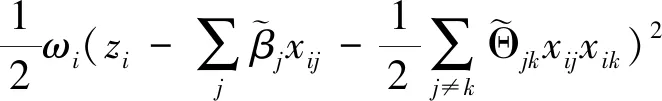
(6)
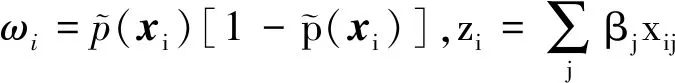
为达到收缩模型系数的目的,得到1阶主变量系数与2阶交互变量系数的稀疏解,提高模型稳定性,本文为目标函数l(β,Θ)添加系数的Lasso罚函数,λ1、λ2为超参数,则:
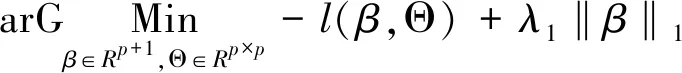
+λ2‖Θ‖1
(7)
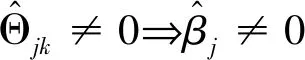
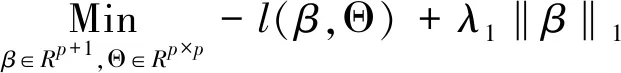
+λ2‖Θ‖1
s.t.‖Θj‖1≤|βj|j=1,…,p(8)
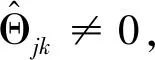
新增的约束条件强制分层,导致式(8)并不是凸函数,将式(8)进行凸松弛变换,得:
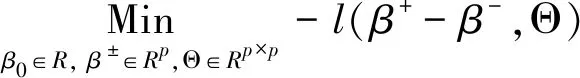
这里用β+、β-∈Rp+1代替向量β=β+-β-,β±=max{±β,0},则‖β‖1=β++β-。
3 坐标下降算法以及KKT条件
坐标下降算法的思想是首先给出初始系数解;然后每次更新一个坐标的系数值,重复坐标更新过程,就可以得到所有坐标的一次更新值;重复系数更新过程就可以得到系数向量最终解。如果坐标满足独立条件,整个迭代过程将很快完成。
因此根据坐标下降法对式(9)求解。式(9)的拉格朗日函数为
L(β+,β-,Θ)=-l(β+-β-,Θ)
(10)
其中
是分层约束的对偶变量,γ±是非负约束的对偶变量。上式可以分解为p个子问题进行求解:
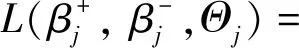
+<(λ2+α)Uj,Θj>
(11)
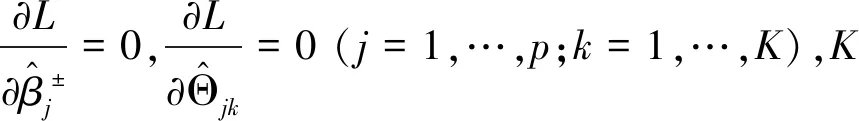
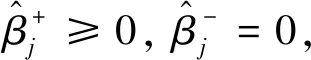
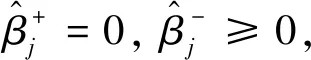
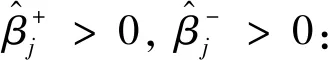
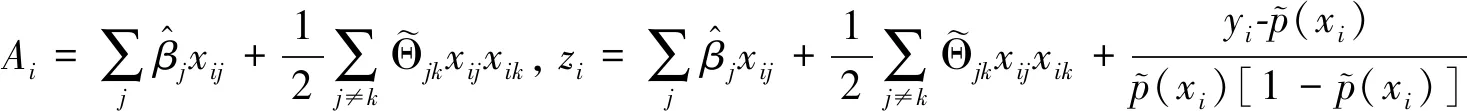
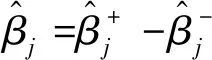
(12)
其中,S为软阈值S(c,λ)=siGn(c)(|c|-λ)+。
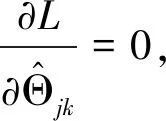
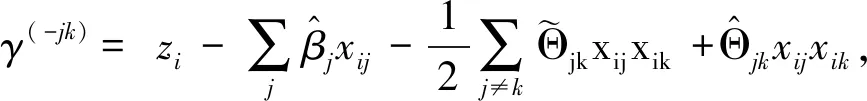
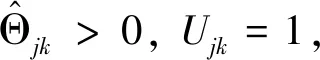
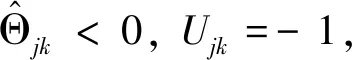
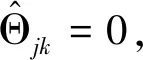
(13)
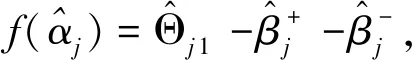
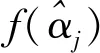
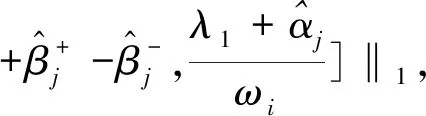
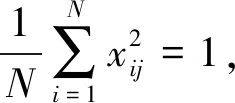
4 实验结果与分析
4.1 UCI数据的实验结果与分析
本文选用UCI学习数据库中4个数据集,即Breast-cancer-wisconsin 数据集、Ionosphere数据集、Liver-disorders数据集和Sonar数据集,如表1所示。
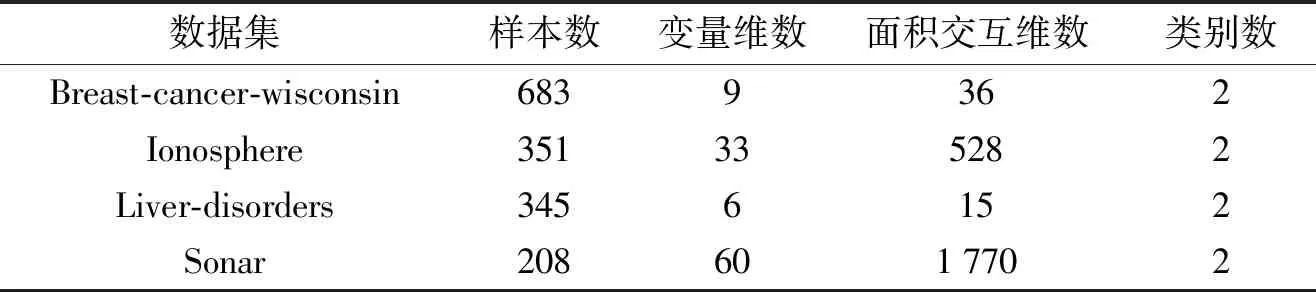
表1 UCI数据集信息
本文对4个数据集进行20次10倍交叉验证,实验中选择λ1=2λ2=λ。完成了loGistic回归的分层交互Lasso方法的实验,采用R编程,结果包括非0变量系数个数、平均错误率、标准差、CPU时间以及所选取的λ值估计值Lamhat,见表2所示。图2~图5分别是本文所提出方法在4种数据集上10倍交叉验证的实验结果,下横坐标表示λ的对数值,上横坐标表示非零变量数,纵坐标是错误率。
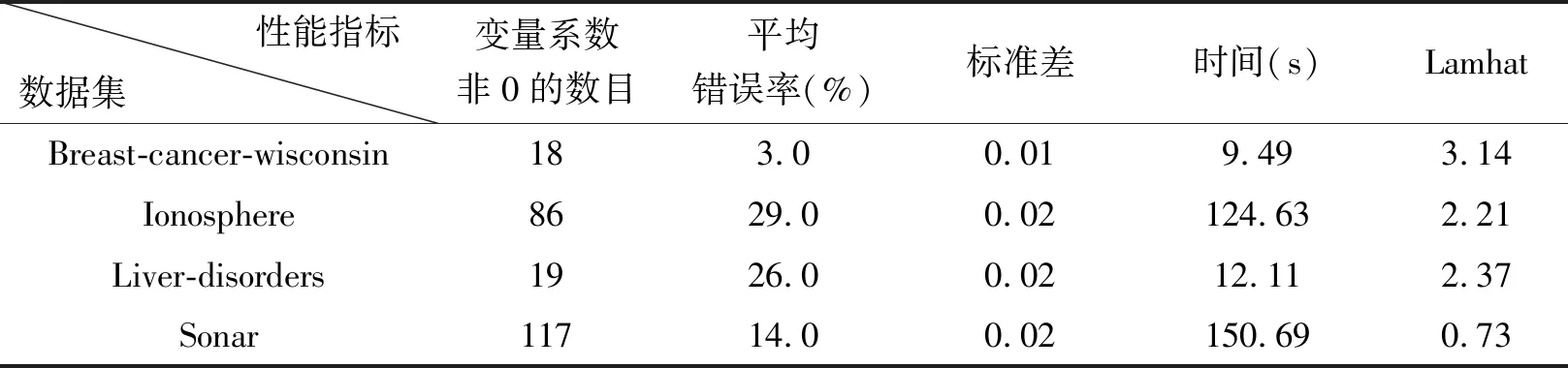
表2 LoGistic回归的分层交互Lasso方法10倍交叉验证的实验结果
图2所示为Breast-cancer-wisconsin数据实验结果,当所选择变量超过11个时,错误率开始平稳,最低为3.0%。从图中可以看出标准差较小,说明了本文选用方法的高效性和稳定性。图3所示为Ionosphere数据实验结果,当所选择变量为86个时,错误率最低为29.0%,标准差较小。错误率最低时的变量数目高于原始变量数目,故变量交互为分类提供了分类信息。图4为Liver-disorder数据实验结果,当所选择变量为19个时,错误率最低为26.0%,标准差为0.02。图5为Sonar数据实验结果,错误率变化的趋势大致与所选用变量数呈分段线性关系。当所选择的变量大于80时,错误率较低,最低为14.0%。
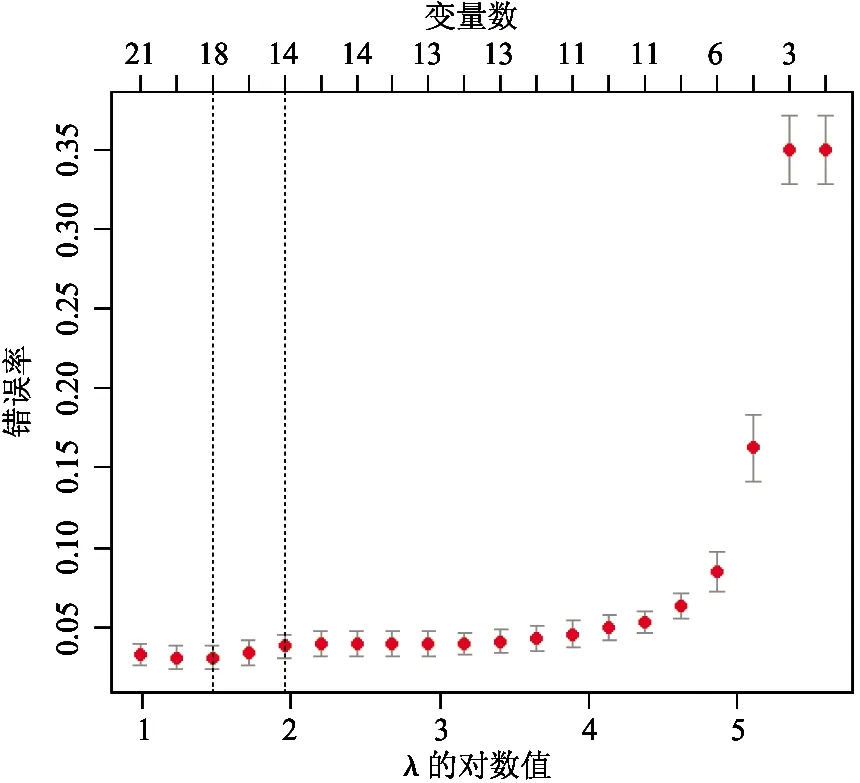
图2 Wisconsin-breast-cancer实验结果
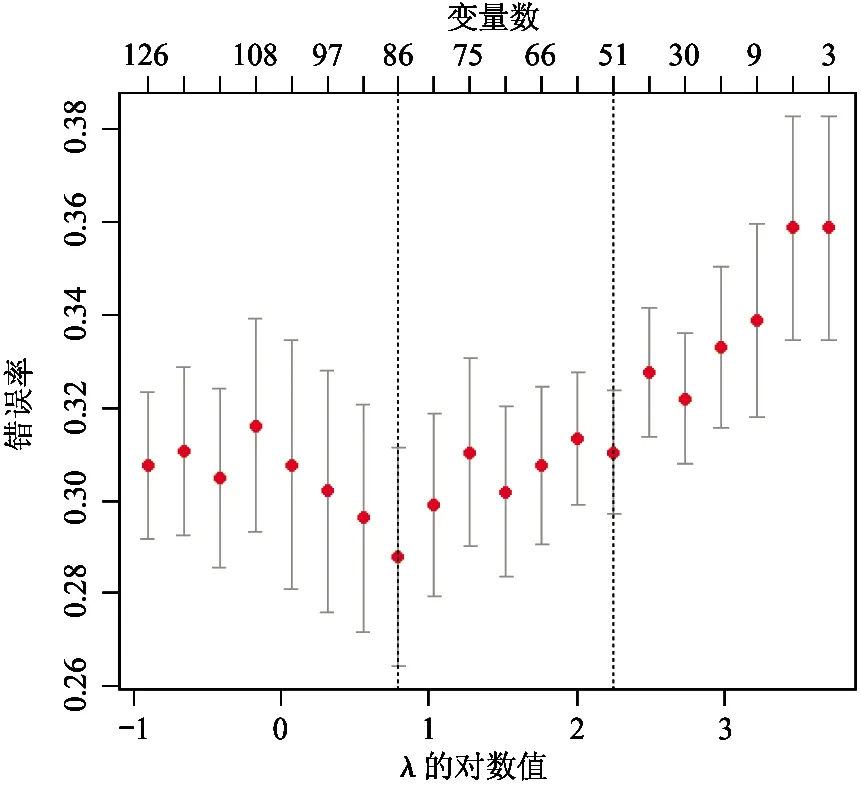
图3 Ionosphere实验结果
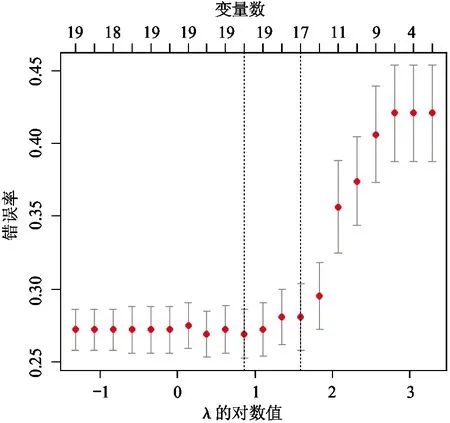
图4 Liver-disorders实验结果
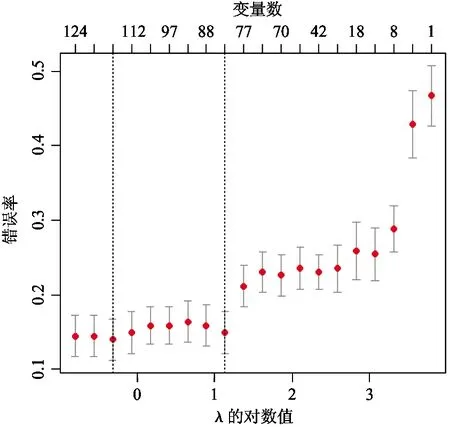
图5 Sonar实验结果
4.2 实验讨论
分层交互Lasso定义为考虑1阶变量和2阶交互变量也考虑分层。Lasso方法定义为只考虑1阶变量不考虑2阶交互变量,交互Lasso方法定义为考虑1阶变量和2阶交互变量但不考虑分层。Lasso、交互Lasso方法和传统模式识别方法在4种数据集上20次10倍交叉验证的实验结果分别为表3、表4和表5所示。实验结果说明了本文所选用分层交互loGistic回归方法分类效果好,模型稳定,突出展现了几何代数变量交互思想和弱分层思想的优势。
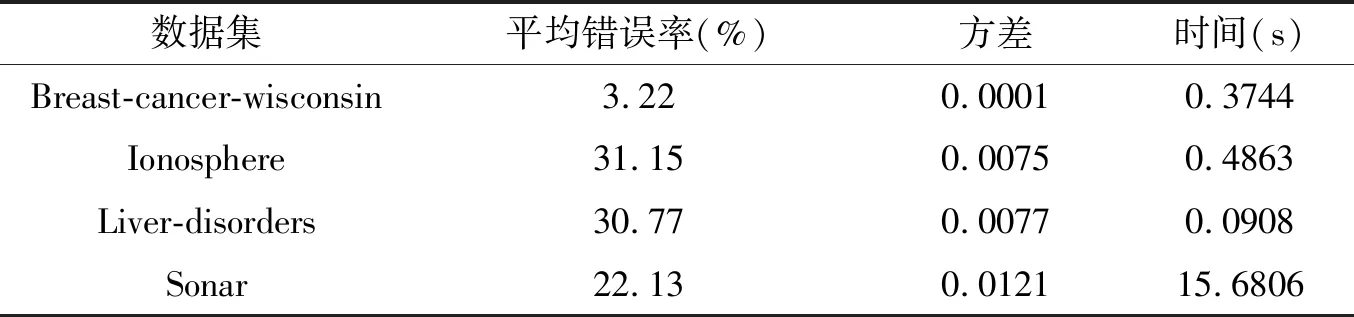
表3 Lasso方法在4种数据集上10倍交叉验证的实验结果
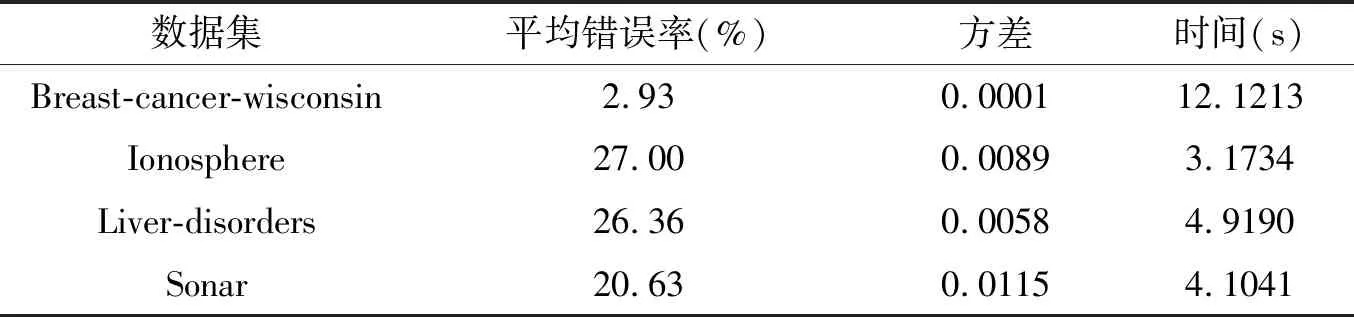
表4 交互Lasso方法在4种数据集上10倍交叉验证的实验结果
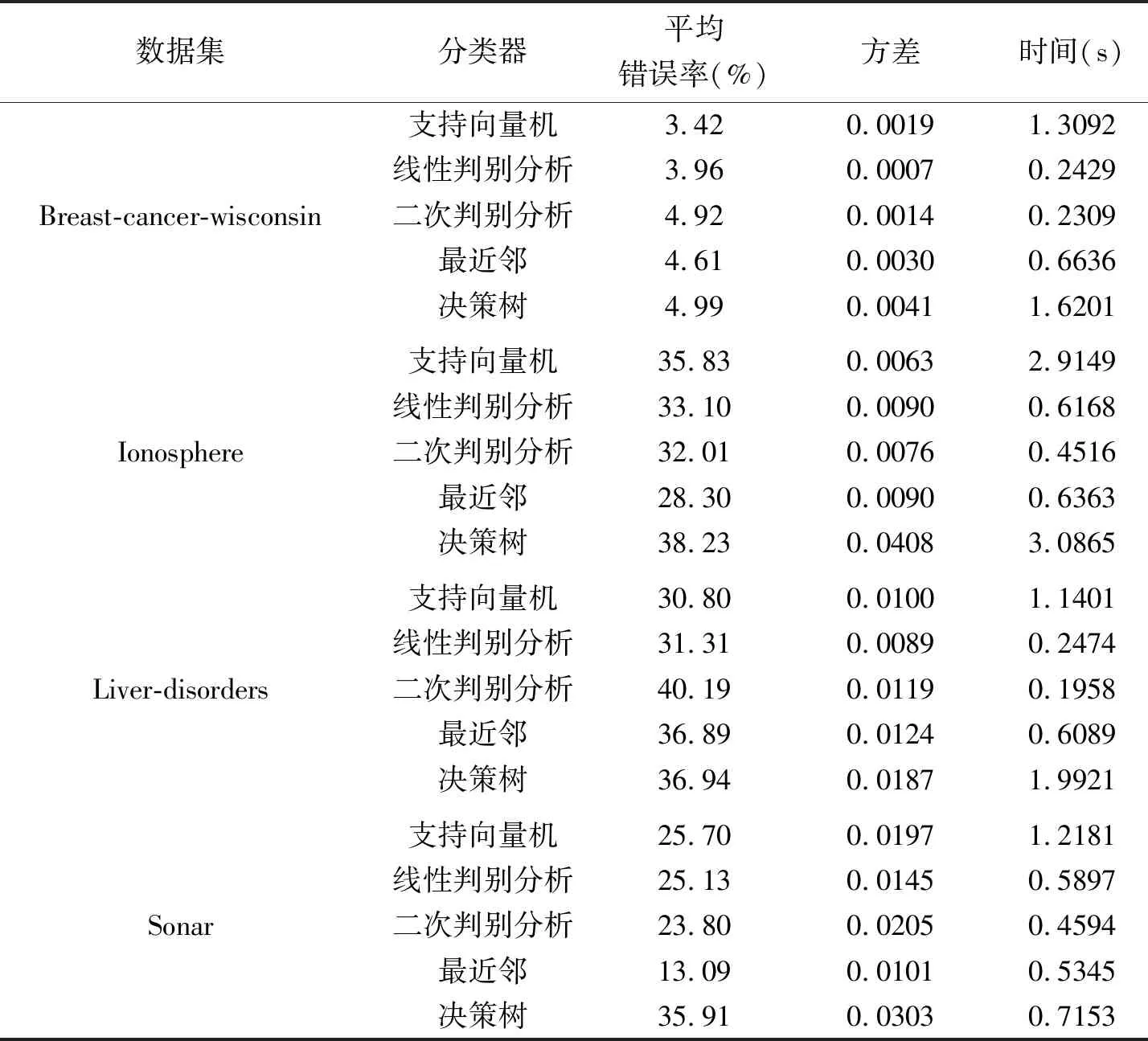
表5 传统模式识别方法在4种数据集上10倍交叉验证的实验结果
本文方法和其他文献方法区别较大,将其同文献[13]进行了对比,loGistic回归方法的平均错误率低于文献[13]回归方法,提出的坐标下降法的训练时间更少。
4.3 数值仿真实验与讨论
本文取样本n=200,p=20,考虑2阶交互变量,基于式(1)给出下面3种仿真情况:(1) 真实模型是分层Θjk≠0⟹βj≠0或βk≠0 (j,k=1,…,p),β中有10个元素是非零的,Θ中有20个元素是非零的;(2) 真实模型是仅有2阶几何代数变量交互:βj=0 (j=1,…,p),Θ中有20个元素是非零的;(3) 真实模型是仅有1阶变量:Θjk=0 (j,k=1,…,p),β中有10个元素是非零的。1阶变量信噪比为1.5, 2阶交互变量信噪比为1。100次仿真实验的结果如图6所示。当真实模型是分层时,分层交互Lasso完成最好,Lasso完成最差,如图6(a)所示。当真实模型仅有2阶交互时,交互Lasso完成最好,分层交互Lasso居中,Lasso完成最差,如图6(b)所示。这与所期待的结果有所偏差,原因可能是分层交互模型将部分交互项当做1阶变量进行模型拟合。当真实模型是仅有1阶变量时,Lasso完成最好,分层交互Lasso居中,交互Lasso完成最差,如图6(c)所示。
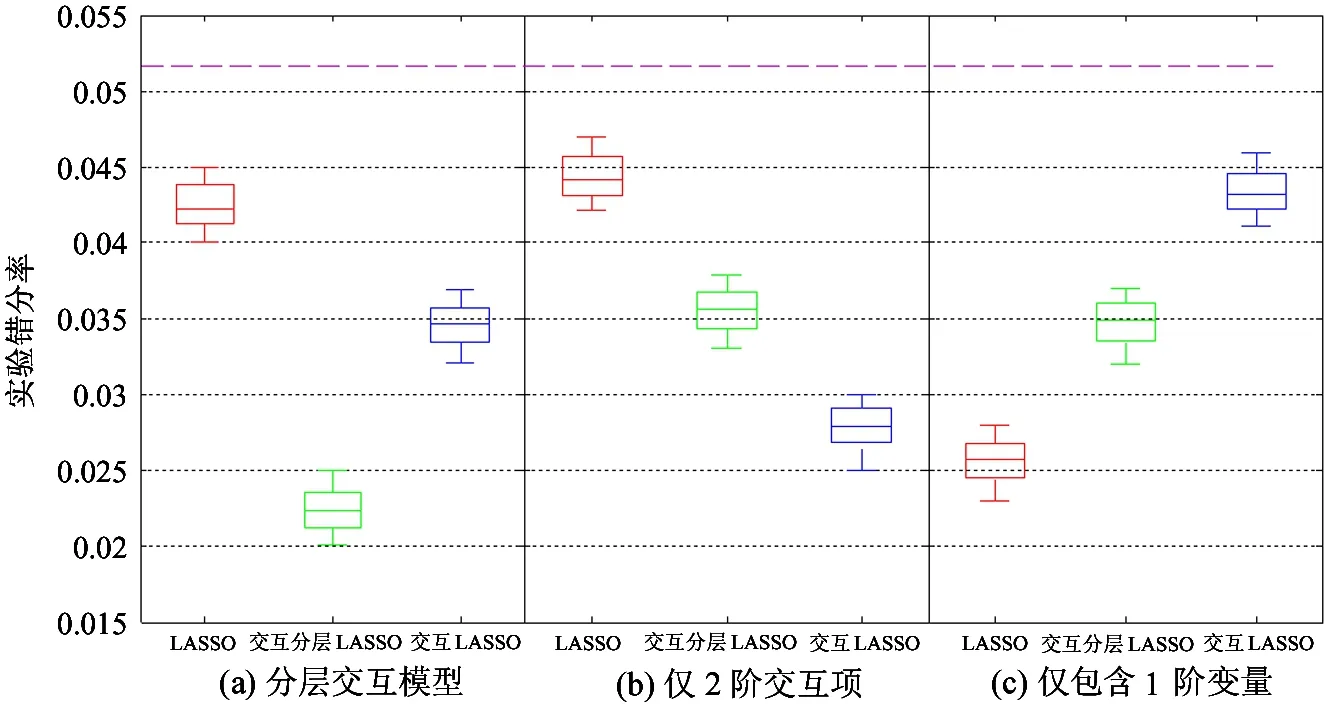
图6 3种Lasso在仿真实验中的错误率比较
实际数据真实模型可能是分层交互模型,即包含1阶变量,又包含几何代数2阶交互变量。不但如此,分层也不可忽视,因为对模型影响大的几何代数2阶交互变量预示着对应的1阶变量的贡献也重要。故分层交互Laaso方法最大限度地拟合了这种情况。
4.4 基于智能手机传感器数据的日常生活活动识别
AnGuita等人[21]采集智能手机传感器数据,利用硬件友好的多类支持向量机方法进行日常活动识别。这对失能或老年人的日常活动监护具有重要意义。日常活动数据集可以从文献[21]下载,这里被用来评价分层交互Lasso。数据集实验结果采自30个19~48岁的志愿者,每人进行6次实验。所有人在执行活动之前都要将智能手机放在腰部。为了方便进行数据标签,实验进行了视频录制。实验采用三星Galaxy S2手机作为终端,因为内置了用于测量3维线性加速度和角速度的加速度计和陀螺仪,其采样频率为50 Hz,这对于捕捉人体运动有效。本文实验采用了上楼和下楼2个活动类,其训练集分别为986个样本和1 073个样本,测试集分别为420个样本和471个样本,变量维数都是561,由采集传感器信号的时域和频域特征组成。3种Lasso方法和常用模式识别方法的实验结果如表7。可见Lasso方法比常用模式识别方法更好考虑了变量选择和变量交互问题,而分层交互Lasso分类结果最好,训练时间和测试时间都较少。
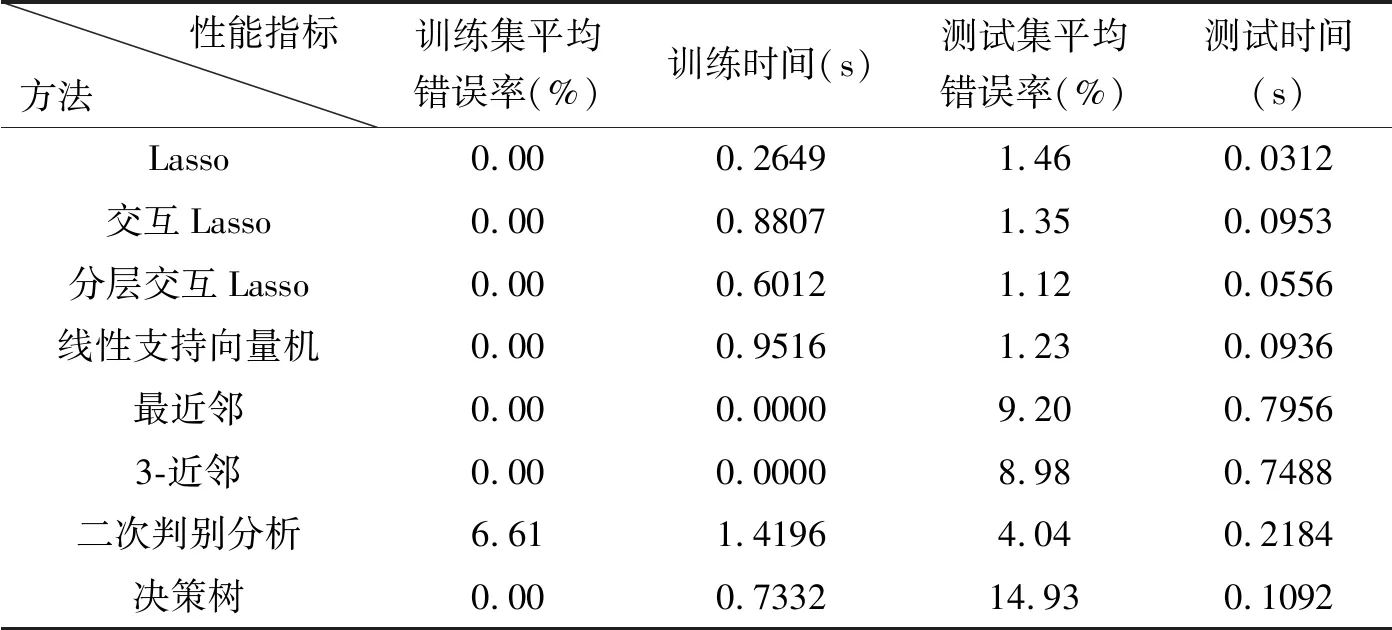
表7 活动识别数据的实验结果
5 结 论
从考虑变量间的交互性出发,基于分层Lasso思想,本文提出了loGistic回归的分层交互Lasso模型和算法,给出了模型定义、约束条件、凸松弛条件、凸优化方法和坐标下降算法的系数解。4组UCI数据集和1组真实的日常生活活动识别数据集的实验结果揭示了交互性在模型分类中广泛存在,变量交互对响应类别变量有贡献。而不考虑交互变量的Lasso方法分类性能欠佳,不考虑分层而仅考虑交互变量的交互Lasso方法分类性能也不够好。这说明变量交互和分层思想是广义线性模型能够成功应用的2个重要原因。进一步研究方向包括广义梯度下降法或交替方向乘子法等其他模型凸优化方法,多类loGistic回归方法的分层交互Lasso方法,将新方法用于活动识别问题的多传感器交互研究中。
