稀疏混合字典学习的人脸鉴别算法
2020-05-14矫慧文梁久祯
矫慧文,狄 岚,梁久祯
1(江南大学 人工智能与计算机学院,无锡 214122)
2(常州大学 信息科学与工程学院,常州 213164)
E-mail :18861824997@163.com
1 引 言
随着计算机硬件技术革新以及软件技术的发展,人脸鉴别逐渐应用在经济工程、社会安全等不同领域.基于深度学习的人脸鉴别算法[1-3]虽然识别率高,但它依赖于需要大量的数据样本、高昂的硬件设备以及长达数天的训练时间.与其相比,基于稀疏表示的人脸鉴别训练简单、对于噪声有较强鲁棒性,近年来引起国内外学者广泛关注.
2009年,J.Wrigh等人[4]提出基于稀疏表示的分类(Sparse Representation Based Classification,SRC).该算法基于光照模型,假设任一测试样本都可由该类训练样本集重构表示,通过选取最小重构误差进行分类,第一次将稀疏表示算法引入到人脸鉴别领域.而后,众多学者在SRC基础上提出改进算法.Zhang等人[5]将SRC算法中l1-norm约束项改为l2-norm,提出CRC算法,在保证识别率的同时降低了求解稀疏编码的复杂度,使算法运行速度明显提升.Aharon等人[6]依据误差最小原则,泛化 K-means 聚类,提出 K-SVD 算法,对误差项进行 SVD 分解.
以上几种算法中的字典均由训练数据直接构成,具有字典辨别性不足且对噪声较为敏感的缺点.针对字典辨别性,Sprechmann等人[7]提出鉴别子字典思想,利用稀疏编码为每类数据构造对应的子字典.Jiang 等人[8]将标签一致性约束添加到 K-SVD 算法中,提升字典的辨别力.
针对编码辨别性,Yang等人[9]以Fisher准则为模型,提出FDDL算法,增强字典原子与训练标签之间的关联性,约束稀疏编码类间方差大、类内方差小.2014年,Cai等人[10]提出SVGDL算法,自适应地确定每个编码向量对的权重,在训练样本不充分时可以取得较好的分类效果.2018年,Zhou等人[11]提出新样本扩充方法,Li等人[12]将核方法引入协同近邻算法,增强稀疏编码的分类能力.
鉴别子字典虽然能有效提取类别之间的特殊性和差异性,但未考虑到不同类别之间的共性.2018年,Wang等人[13]提出显著特征提取并构造共享字典,Li等人[14]提出CSICVDL算法,利用辅助数据构造类内字典,捕捉不同类别间的相同特征.
考虑到少样本训练情况,本文借鉴子字典思想和共享字典思想,提出一种新的混合字典学习模型,提取类别差异特征和类内共性特征.算法共分为两部分:
1)提出基于拉普拉斯矩阵与费舍尔判别准则的类别字典学习算法,保留稀疏编码数据相似性的同时减小类内编码离散度,增大类间编码离散度,扩大不同类别的信息差异,提高字典和稀疏编码的辨别性.
2)提出类内差异字典算法,捕捉不同类别的相同特征,在保留数据共性特征的基础上增强算法对测试样本存在光照、遮挡变化等情况时的鉴别能力.最后,为验证模型各部分的有效性,将本文模型分为4个方案,分别在AR、CMU-PIE、LFW等人脸库上进行实验.
2 相关工作
给定训练样本集A:
A={A1,A2,…,AK}∈Rm×N
测试样本集Y:
Y={Y1,Y2,…,YK}∈Rm×N1
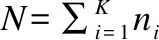
2.1 基于稀疏表示的人脸识别SRC
对于测试集Y,稀疏表示的目的是通过一个合适的字典D寻找能表达Y的稀疏编码X,算法模型如下:
模型分为重构误差项与正则项两部分,优化正则项可参照LASSO[15]问题.正则化参数λ>0平衡两项之间关系.大量研究人员针对求解稀疏编码X提出许多快速求解算法,主要分为贪婪算法(如正交匹配追踪[16]、子空间追踪[17])和凸松弛算法(如梯度投影稀疏重构法[18])两类.
2.2 拉普拉斯矩阵
拉普拉斯矩阵[19]是基于图论的矩阵,为了更好的把稀疏表示转换为图论问题,假定无向图G={V,E},顶点集V表示各个样本,带权的边表示样本编码之间的相似度.
wqr表示顶点q、r之间的权值,根据相互k近邻原则[20],权值公式如下:
其中,xq∈Nk(xr)表示xq是xr的k近邻,σ是内核的带宽参数.
定义邻接矩阵W=(wqr),与某顶点邻接的所有边的权值和uq表示为:
多个u形成度矩阵:
U=diag(∑q≠rwqr)
最终拉普拉斯矩阵Δ定义如下:Δ=U-W
2.3 费舍尔判别准则
费舍尔判别准则的思想是将样本投影到合适的投影轴,使同类样本投影点的距离尽可能小,异类样本投影点的距离尽可能大.
对于稀疏编码X,定义u0表示所有稀疏系数的中心.ui表示各类稀疏编码均值向量:
类内散度矩阵Sw(X)、类间散度矩阵SB(X)可定义为:
3 稀疏混合字典学习的人脸鉴别方法
本文提出一种新的稀疏混合字典学习分类方法,利用训练数据构造类别特色字典,利用辅助数据构造类内差异字典,采用分步优化方法求解.
3.1 类别特色字典
3.1.1 类别特色字典模型
对于训练集A和测试集Y,习得由K个子字典组成的字典D:D={D1,D2,…,DK}.
根据拉普拉斯矩阵与费舍尔判别准则,提出类别特色字典模型如下:
(1)
模型分为重构误差项、稀疏保证项和判别系数项三部分.下面依次论述模型每一项原理.
g(A,D,X)表示重构误差项,该项保证字典的识别力.本文以SRC重构误差项为基础,借鉴子字典思想,加入子字典重构项,最终公式如下:
其中Xi是Ai被D重构的稀疏编码,Xii是Ai被Di重构的稀疏编码.
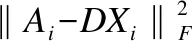
‖X‖21表示稀疏保证项,该项确保编码的稀疏性,‖.‖21表示l1/2-norm.
f(X,D)表示判别系数项,该项确保编码的识别力.
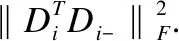
以拉普拉斯矩阵和费舍尔准则为思想基础,在为稀疏编码添加两项约束,使稀疏编码在保留数据相似度信息的同时,扩大类间离散度,缩小类内离散度,增强稀疏编码的辨别性.
f(X,D)最终公式如下:

方案1,单添加字典约束项扩大子空间多样性,作为基础对照项:
方案2,添加费舍尔准则约束与字典约束项.将稀疏编码映射到到子空间,使稀疏编码在此空间的投影类间离散度尽可能大,类内离散度尽可能小:
方案3,添加拉普拉斯矩阵约束与字典约束项.结合图论思想,将稀疏编码构造成图G,每一个节点对应一个编码数据点,将各个点连接起来,利用边的权重表示稀疏编码之间的相似性.将图以邻接矩阵W的形式表示,构造度矩阵U,拉普拉斯矩阵Δ=U-W,为稀疏编码添加拉普拉斯约束项,保留数据相似度信息:
方案4,结合方案2和方案3,添加费舍尔准则约束、拉普拉斯矩阵约束与字典约束项:
优化时默认采用方案4,目标函数(1)的完整形式为:
(2)
3.1.2 类别特色字典优化
公式(2)为非凸函数,优化步骤如下:
第1步,初始化字典D;
将训练数据A={A1,A2,…,AK}的特征向量初始化为字典的原子,对字典D的每一类归一化,使其l2范数为1.
第2步,固定字典D,更新稀疏系数X;
目标函数转化为:
(3)
其中Xi∈RN×ni的求解通过文献[21]中的方法,γ=λ1/2.
第3步,固定稀疏系数X,更新字典D;
本文采用逐个更新的方法更新字典D,即当更新第j个子字典时,默认其他子字典Dj(i≠j)已更新完毕.
目标函数可转化为:
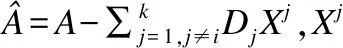
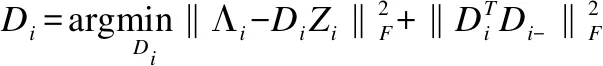
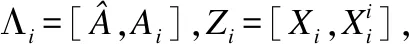
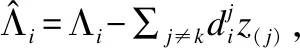
(4)
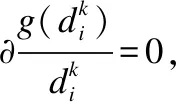
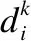
第4步,重复步骤2和步骤3,直到前后两次的函数Q的值达到阈值或者达到最大迭代次数为止.
类别特色字典算法总体实现步骤如下:
算法1.类别特色字典优化算法
输入:训练样本N,规范化参数γ
输出:字典D和稀疏系数X及相应的标签
Step1.初始化字典D
Step2.固定字典D,更新稀疏系数X
初始化字典后,利用公式(3)依次求解
Step3.固定稀疏系数,更新字典:
利用公式(4)依次更新
Step4.重复Step2和Step3,直到前后两次的函数的值达到阈值或者达到最大迭代次数为止.
3.2 类内差异字典
3.2.1 类内差异字典模型
在人脸鉴别中,传统方法往往致力于在提取特征时扩大类别之间的差异,摒弃类别之间相同的特征.但在同一表情变化或同一遮挡、光照等情况下,不同类别之间往往存在相似的变化特征.如表情识别中的表情特征,提取此类变化特征隐含的相关性信息,有助于提高复杂环境下的鉴别精度.换句话说,类内差异字典模型基于不同类别间的特征变化存在相关性这一假设,构建类内字典以捕获训练和测试数据之间的可能变化.

图1 类内差异字典训练数据
如图1所示,假设共有k类数据训练类内差异字典,标准数据为:
N={N1,N2,…,Nk},Ni∈Rm×li
变化数据为:
X={X1,X2,…,Xk},Xi[xi1,xi2,…,xini]
标准数据与变化数据共称为辅助数据C.定义目标函数如下:
(5)
其中DS∈Rm×r为类内差异字典,αi∈Rni×1为标准无变化数据的稀疏系数,βi∈Rr×1为被DS重构的稀疏系数.
3.2.2 类内差异字典优化
公式(5)为非凸函数,优化步骤如下:
第1步,初始化字典DS
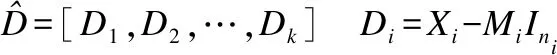
其中,Mi为第i类标准数据的中心,本文取该类数据的平均向量,Ini=[1,1,…,1]∈R1×ni.
第2步,固定字典DS,更新稀疏系数αi,βi
目标函数转换为:
(6)
其中Di=[Ni,DS],ri=[αi,βi],本文采用文献[22]方法求解上述公式.
第3步,固定稀疏系数αi,βi,字典DS
目标函数转换为:
假设:
目标函数转换为:
当更新字典原子dj时,假设其余的原子已更新完毕,因此有:
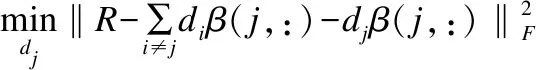
设Y=R-∑i≠jdiβ(i,:),采用拉格朗日乘子法,目标函数转换为:

di=Yβ(j,:)T(β(j,:)β(j,:)T-γ)-1
(7)
将得到的dj规范化:
dj=Yβ(j,:)T/‖Yβ(j,:)T‖2
第4步,重复步骤2和步骤3,直到前后两次的函数Q的值达到阈值或者达到最大迭代次数为止.
类内差异字典算法总体实现步骤如下:
算法2.类别特征字典优化算法
输入:标准数据N,变化数据X,规范化参数γ
输出:字典DS
Step1.初始化字典DS
Step2.固定字典DS,更新稀疏系数αi,βi:
初始化字典DS后,利用公式(6)依次求解αi,βi,i=1,2,…,N
Step3.固定稀疏系数αi,βi,更新字典DS:
利用公式(7)依次更新dj,j=1,2,…,r
Step4.重复Step2和Step3,直到前后两次的函数Q的值达到阈值或者达到最大迭代次数为止.
3.3 分类策略
本文提出全局分类策略如下:
y由第i类字典Di重构的误差为:
(8)
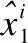
于是y的标签为:
identify(y)=argmini{ei}
(9)
3.4 算法步骤及流程图
算法3.稀疏混合字典学习的分类
输入:训练数据A,辅助数据C,测试数据Y,参数λ1,λ2,w
输出:分类标签
Step1.利用训练数据A及算法1习得类别特色字典D、稀疏编码X
Step2.利用辅助数据C及算法2习得类内差异字典DS
Step3.利用公式(8)、公式(9)得到样本标签
本文算法流程图如图2所示,利用训练数据构造类别特色字典,获得类别特色字典D、稀疏编码X;利用辅助数据构造类内差异字典,获得类内差异字典DS.对于测试样本y,将字典D、编码X、字典DS送入分类器,得出样本标签.
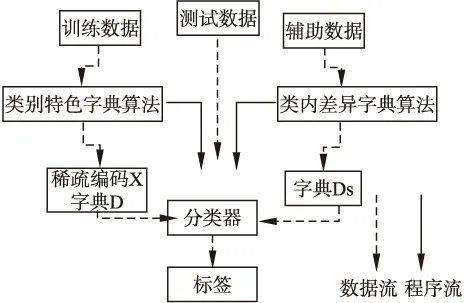
图2 算法流程图
4 实验结果及分析
4.1 实验平台和参数设置
本文实验环境为64位Window 10操作系统,内存32GB,Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz,并用MatlabR2016b软件编程实现.
实验图像都经过标准化处理,共选取CMU-PIE[23]人脸数据库、AR人脸数据库[24]、LFW人脸数据库进行实验,比较算法包括:SRC ,FDDL,CRC,SVGDL和CSICVDL.
4.2 AR数据库实验
本文随机选取AR人脸数据库100人进行实验,每人图片分为5个集合,如图3所示,将其中没有光照表情变化的两张人脸作为训练图片,其余的分为4个集合分别作为测试图片.

图3 AR人脸数据库样本
集合S1为包含表情变化的测试数据;集合S2为包含光照变化的测试数据;集合S3眼镜遮挡的测试数据;集合S4为围巾遮挡的测试数据.
实验选取80个人作为训练集和测试集,其余20个人用于训练类内差异字典,每张图片下采样为60×80,并采用PCA[18]将样本数据降为160维.各算法在AR数据库的识别率如表1所示.
表1 算法在AR库上的实验结果(%)
Table 1 Accuracy(%) of different methods on Experiment1 of AR database
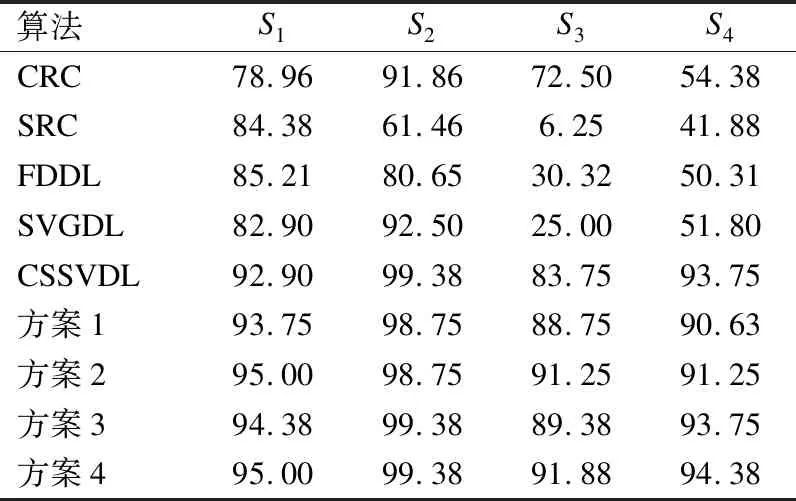
算法S1S2S3S4CRC78.9691.8672.5054.38SRC84.3861.466.2541.88FDDL85.2180.6530.3250.31SVGDL82.9092.5025.0051.80CSSVDL92.9099.3883.7593.75方案193.7598.7588.7590.63方案295.0098.7591.2591.25方案394.3899.3889.3893.75方案495.0099.3891.8894.38
从表1可知,在不同集合下方案4取得最好的分类结果.方案3适宜测试样本存在光照变化、墨镜遮挡的情况,方案2性能较稳定,且在测试样本存在表情变化、围巾遮挡时表现良好.CSICVDL、本文算法识别率高于FDDL,说明了学习类内差异字典的必要性.
4.3 CMU-PIE数据库实验
实验选取CMU-PIE数据库68个人,每人70张图片共4760张图片进行实验.将每人的70张图片分为4个集合,训练样本为2张姿态正面、光照正常图片,测试样本分为4个集合.
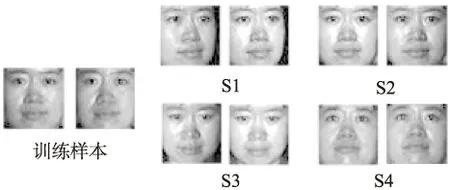
图4 CMU-PIE人脸数据库样本
如图4所示,S1为10张转向图片,S2为38张正面包含部分光照和遮挡变化图片,S3为10张低头图片,S4为10张抬头图片.实验选取18个人作为辅助数据,剩余的50人用于训练和测试,图片采用PCA降维,实验结果如表2所示.
表2 算法在CMU-PIE库上的实验结果(%)
Table 2 Accuracy(%) of different methods on experiment1 of CMU-PIE database
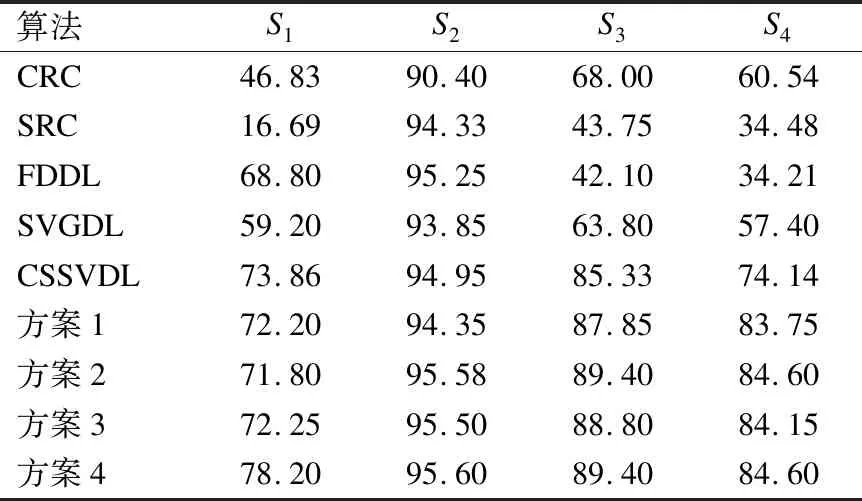
算法S1S2S3S4CRC46.8390.4068.0060.54SRC16.6994.3343.7534.48FDDL68.8095.2542.1034.21SVGDL59.2093.8563.8057.40CSSVDL73.8694.9585.3374.14方案172.2094.3587.8583.75方案271.8095.5889.4084.60方案372.2595.5088.8084.15方案478.2095.6089.4084.60
从表2可知,在各集合下方案四皆取得最优分类效果.对集合S2~S4,本文算法分类准确率较高,对于集合S1,各算法分类准确率较低,初步推测是由于转向图片丢失重要信息导致.
4.4 LFW数据库实验
本文选取非受限人脸数据库LFW进行实验,利用3d校正补齐因转向、遮挡而缺失的特征信息.选取单人图片数量大于10张的139人作为实验数据.每人10张图片进行实验,5张图片作为训练样本,其余为测试样本.
图5表示其中一人的训练样本和测试样本.为验证类内差异字典对算法影响,实验随机挑选19、39、59、79个人作为辅助数据,分别作为S1、S2、S3、S4四种集合,其余用于训练和测试,与基础FDDL算法、包含辅助字典的CSSVDL算法进行对比,各算法在各集合上的识别率如表3所示.
表3 算法在LFW库上的实验结果(%)
Table 3 Accuracy(%) of different methods on Experiment1 of LFW database
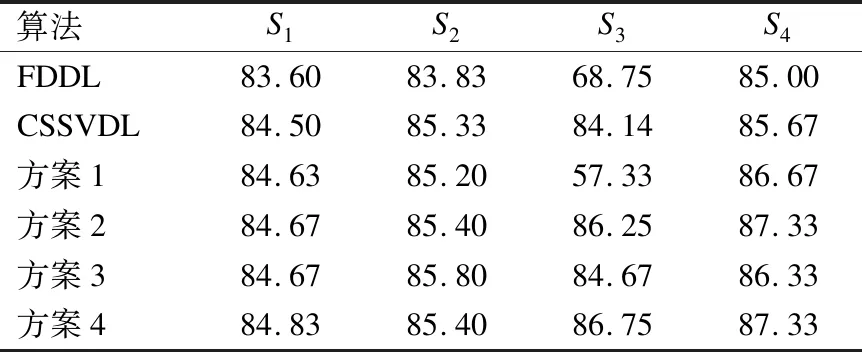
算法S1S2S3S4FDDL83.6083.8368.7585.00CSSVDL84.5085.3384.1485.67方案184.6385.2057.3386.67方案284.6785.4086.2587.33方案384.6785.8084.6786.33方案484.8385.4086.7587.33
从表3可知,随着构筑类内差异字典的辅助数据增加,算法的识别率增加.在非受限人脸数据库上,方案四分类效果最优,而方案1对数据依赖性强,性能不稳定.
4.5 算法分析
4.5.1 参数分析
经实验可知,在四个方案中,方案四稳定性和识别率皆优于其余方案,故以方案四作为本文算法.为进一步验证算法的鲁棒性,在此章节中分析各参数对于分类准确性的影响.
实验选取AR人脸数据库中100人作为实验数据,随机选取80个人用于训练和测试,20个人用于构筑辅助数据.如图6所示,训练样本选取每人2张正常光照和表情图片,测试样本选取每人5张包含表情、光照变化图片.

图6 参数分析样本
1)维数对准确率的影响.
为探究数据维数对准确率的影响性,我们取原始120×165图片和下采样60×80、30×40图片进行实验,分别将用降维至100、150、200、250、300、350、400、450、500.实验结果如图7所示.
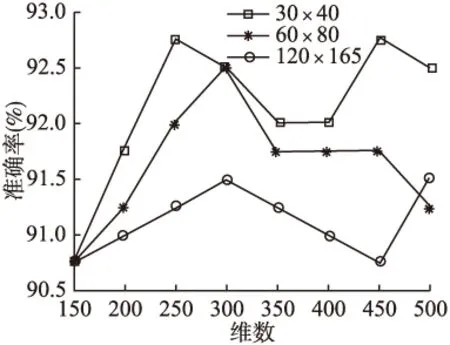
图7 维数对AR数据库的影响
从图7可以看出,随着采样分辨率的提高,本文算法对于人脸图片的整体辨别准确性增强.随着PCA降维维数的增加,各分辨率情况下算法的分类准确性先增加再减少.在30×40、60×80两种分辨率的情况下,本文算法在降维维数为300维时识别准确率最高,而在120×165的分辨率的情况下,本文算法在降维维数为250维时识别准确率最高.
2)权重对准确率的影响
对于2.3节分类策略中的公式(8),为探究权重w对准确率的影响性,取下采样30×40图片进行实验,分别使用PCA降维至100、200、300、400、500维,权重w分别取0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9,实验结果如图8所示.
从图8可以看出,随着PCA降维维数的增加,本文算法的识别准确率增强.不同维数情况下本文算法的识别率随权重变化的大体趋势相同,在权重取值为0.1~0.5时,准确率随权重的增加而增加,取值为0.5~0.9时,本文算法的准确率趋于稳定.
3)参数λ1、λ2对准确率的影响
本文提出的稀疏混合字典学习的人脸鉴别方法共需设置两个约束参数,根据文献[14]通过5倍验证评估参数λ1、λ2.根据前人经验,设定验证小集为{0.1,0.05,0.01,0.005,0.001}.
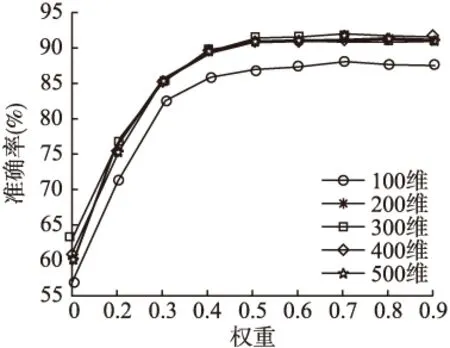
图8 权重对AR数据库的影响
为探究参数λ1、λ2对准确率的影响性,我们取下采样30×40图片进行实验,分别使用PCA降维至100、200、300、400、500维.图9和图10为λ1、λ2、取0.001、0.005、0.01、0.05、0.1时对实验准确率的影响.
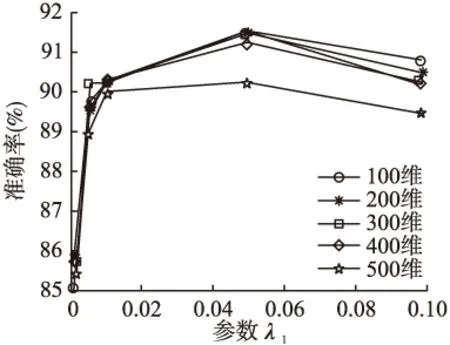
图9 λ1对AR数据库的影响
从图9和图10可以看出,不同维数情况下本文算法的识别率随λ1、λ2取值变化而变化的大体趋势相同,其中λ1、λ2取值为0.05时准确率最高.
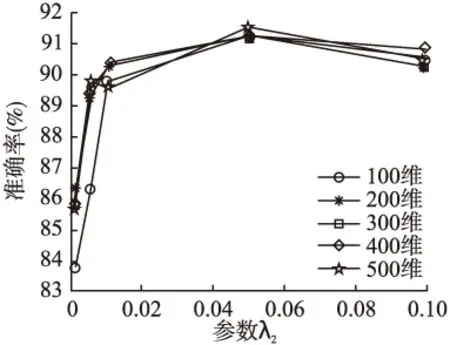
图10 λ2对AR数据库的影响
4.5.2 算法评价
1)复杂度分析
本文算法复杂度分为更新稀疏编码和更新字典两方面计算.
设训练样本个数为n,样本特征维数为q,根据文献[25],更新稀疏系数的时间复杂度为nΟ(q2nr),其中,r≥1.2为常数.
更新字典的时间复杂度为∑jnjΟ(2nq),其中,nj表示Di的原子个数.
因此,本文算法总复杂度为:
nΟ(q2nr)+∑jnjΟ(2nq)
2)多元分类评估
在实际二元分类问题中,预测值和实际值会出现四种情况:真正例(True Positive,TP)、假正例(False Positive,FP)、假负例(False Negative,FN)、真负例(True Negative,TN).除准确率(accuracy)外,常见分类评估指标还有精确率(Precision,P)、召回率(Recall,R)以及综合评价指标(F1 measure,F)等.
在多元分类评估中,宏平均(Macro-averaging)计算公式如下:
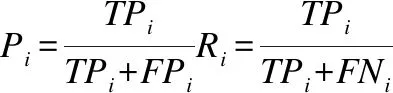
随机选取经3d校正后的LFW人脸数据库120人进行实验,每人10张图片,5张图片作为训练样本,其余为测试样本.
表4 算法在LFW库上的实验结果(%)
Table 4 Experimental results(%) of the algorithm on LFW database
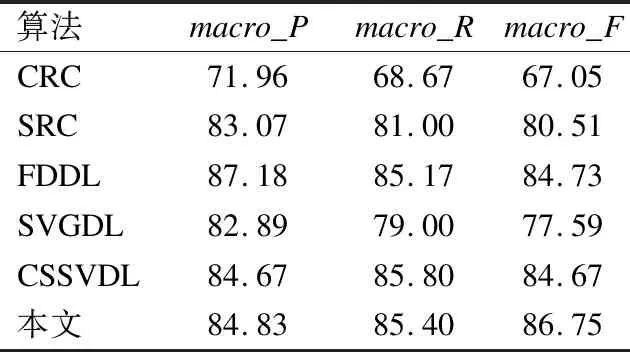
算法macro_Pmacro_Rmacro_FCRC71.9668.6767.05SRC83.0781.0080.51FDDL87.1885.1784.73SVGDL82.8979.0077.59CSSVDL84.6785.8084.67本文84.8385.4086.75
从表4、图11看出,本文算法在宏平均下精确率、F1指标优于其他算法,本文ROC曲线左凸于其他曲线,分类效果更好.
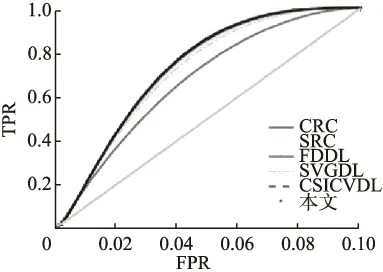
图11 ROC曲线
5 结束语
综合子字典思想和共享字典思想,本文提出稀疏混合字典模型,并综合拉普拉斯矩阵与费舍尔判别准则,提出基于拉普拉斯矩阵与费舍尔判别准则的类别字典学习算法.将公式分为四个方案分别在AR、CMU-PIE、LFW等人脸库上进行实验.实验表明,在小样本训练情境下,即使测试样本与训练样本存在较大差异如表情变化、遮挡等,本文仍能保持较好的性能.在实际应用中还需进一步探讨算法对训练样本的依赖性以及算法的稳定性.
