一种结合LSTM和集成算法的文本校对模型
2020-05-14陶永才吴文乐海朝阳
陶永才,吴文乐,海朝阳,石 磊,卫 琳
1(郑州大学 信息工程学院,郑州 450001)
2(郑州大学 软件技术学院,郑州 450002)
E-mail:ieyctao@zzu.edu.cn
1 引 言
随着互联网信息技术的快速发展,出版行业和电子书刊的全面普及为中文文本校对的准确定性提出了更高的要求,如何提高校对的准确性是目前文本校对工作的难题.国外文本校对工作最早开始于1960年,IBM Thomas J.Watson实验室提出一个TYPO英文拼写检查器[1],经过几十年的发展,英文文本校对技术取得了巨大进步.中文文本校对工作起步较晚,上世纪九十年代才有学者正式研究该方向.
受中文自身特点的影响,中文校对方法同英文校对方法存在着极大的差异.中文句子中的词语之间搭配关系复杂,所表达的含义不仅和句子上下文相关,还和用词以及语法有关,因此,中文文本校对可分为字词级、语法级和语义级三个方面.目前中文文本校对的研究工作多是在字词级和语法级层面,且研究成果丰硕,但语义层面的研究较少,没有行之有效的方法解决中文文本中存在的语义层面的错误.这些错误大多是词语搭配错误,比如动宾搭配不当、主谓搭配不当、量词搭配不当等.这些搭配错误从常理上理解不存在问题,但不符合语义规范,比如:“他今天穿了一件紫色外套和黑色眼镜”.句子结构完整,但句中谓语动词“穿”和“黑色眼镜”的搭配与中文语义搭配规范相悖.
针对目前现状,本文在语义级研究一种中文文本特征检测和校对方法,使用长短时记忆网络获取上下文语义信息,并将长短时记忆网络作为集成算法的子模型预测义原序列,采用K邻近算法对预测义原进行模糊匹配,最后对候选义原集合投票并排序,筛选出排名靠前的结果作为校对建议,提高了文本校对的准确性.
2 相关工作
文本特征检测和校对方法由于涉及到语义问题,一直是中文文本校对的研究重点. 然而个体的思维习惯、认知习惯和不同地区的风俗习惯等多种因素都会对词语搭配结果造成影响[2],这为研究工作带来了极大的挑战.目前常见的语义级检错校对方法有:
1)基于规则的方法[3].该方法通过观察和统计大量语料数据,总结语法规范和语义规范,构建知识图谱,使用知识图谱进行查错.文献[4]结合逻辑和规则的方法,提出一种基于矩阵的语义级文本查错方法,通过句法分析得到文本语句成分,计算语料库和成分相似度进行查错,并以词义的N元邻接矩阵对语义建模,提高查错率.该方法对长距离语义搭配错误予以校对,为语义级文本查错工作提供了新的思路.
2)基于统计学理论[5].通过建立统计模型,如贝叶斯模型、N-gram[6]等构造上下文特征进行查错.文献[7]提出一种基于规则和统计的文本查错方法,该方法分析正确文本分词后词语的排列规则,总结出文本错误规则,结合字的二元、 三元统计模型和词的二元、三元统计模型,建立并实现文本自动查错模型,并取得了较为满意的结果.文献[3]采取统计学理论和基于规则的方法相结合的策略,生成词语-义原和义原-义原这两种搭配知识库,使用语义搭配的互信息量MI和聚合度PD作为证据,用统计方法建立证据信任分配函数,结合分配函数和D-S规则判断词语搭配的正确性.
3)基于深度学习的方法[8].该方法通过建立模型学习文本特征,文献[9]提出了一种基于特征的自动错误检测和纠正方法,该方法集查错和纠错为一体,首先构造字或词的混淆集,接着构造目标串的二元接续关系、词性类的三元接续关系、上下文语义类、词性类等4种特征集,然后采用Winnow方法学习以上特征集特征,依据上下文特征选择目标混淆集中的词.
3 语义特征检测及校对方法
本文结合长短时记忆网络和集成学习方法,设计一个基于长短时记忆网络的集成模型,用于提高文本语义特征检测和校对的准确性.整体框架如图1所示.
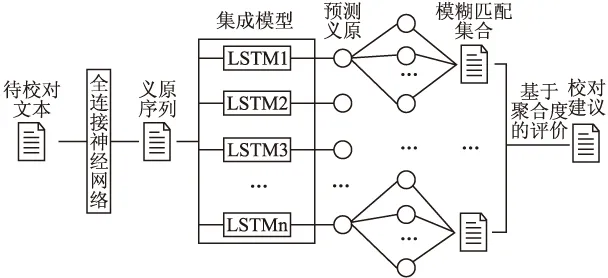
图1 文本语义特征检测及校对的整体框架
3.1 词语-语义映射
经过对大量中文文本数据进行统计和分析发现,中文句子中词语之间存在一定的联系,这些关系中蕴含了丰富的语义特征,词语之间的关联性随着语句上下文的变化而改变,因此如何合适地提取并将词语之间的关联性表达出来是表达语义特征的关键问题.
HowNet知识库将义原定义为比词语、词义更小的语义单元表达,并认为义原是最基本的、不能再分割的单位,并使用义原表达所有的概念.义原的提出,使得语义特征检测的工作突破了词语的限制,可在一定程度上反映词语语义信息,更抽象地表达语义特征.
神经网络拥有很强的泛化能力和抽象表达能力,使用神经网络可从数据中提取高维数据特征.本文将训练语料库和HowNet构建的语义搭配知识库结合,使用训练语料中的词语构建词向量空间,对HowNet义原集合构造HowNet义原向量空间.在HowNet义原向量空间中的义原向量和对应的词语之间建立映射关系,得到词语-义原映射集合.
本文采用7层全连接神经网络,将词语和该词语对应的义原分别作为网络的输入和标签并训练网络.计算输出义原向量与HowNet义原向量之间的欧氏距离,采用均方误差作为目标函数,使用反向传播来优化该网络.在给定新词序列时,将词语转化为词向量后,该网络可将词向量快速转化为对应的义原向量,进而完成从词语序列到义原序列的映射.
3.2 长短时记忆网络
文本的语义和上下文存在着紧密联系,语义级中文文本的检错工作需要分析和学习语义之间存在的搭配规律,根据学习到的上下文语义搭配规律判断输入的语义序列是否存在错误.分析语义搭配信息时需要检测完整的语义序列,而该序列长度是不固定的,故使用长短时记忆网络模型提取语义序列的上下文语义特征.
长短时记忆网络(Long Short Term Memory Network,LSTM)的思路是引入三个门来保持单元状态c,分别是决定上一时刻单元状态ct-1保留多少到当前时刻的遗忘门、决定当前时刻网络输入xt有多少保存到单元状态ct的输入门和用来控制单元状态ct输出多少到LSTM输出值ht的输出门.LSTM模型结构如图2所示.
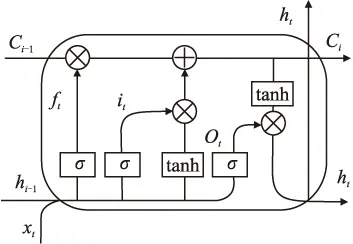
图2 LSTM模型结构
遗忘门的计算公式如式(1)所示.
ft=σ(Wf·[ht-1,xt]+bf)
(1)
其中,Wf是遗忘门的权重矩阵,[ht-1,xt]表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ是sigmoid函数.
输入门的计算公式如式(2)-式(4)所示.
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
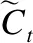
输出门决定输出什么值,ht是LSTM的最终输出,它由输入门和单元状态共同决定,其计算公式如式(5)-式(6)所示.
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot*tanh(ct)
(6)
3.3 义原预测集成模型
集成算法是一种监督式学习方法,它采取集成策略将多个子模型整合为集成模型,集成模型的预测结果优于每个子模型.Boostrap Aggregating是常见的一种集成算法,也被称作Bagging[10].Bagging算法的核心思想是通过对数据集进行多次有放回的随机采样,构造多个训练集,使每个子模型的训练集均不相同,进而得到差异化的分类结果,将结果按特定策略整合后输出.
本文结合长短时记忆网络模型(LSTM)和集成学习方法,设计一种基于长短时记忆网络和集成算法的模型,该模型将多个长短时记忆网络作为子模型,采用Bagging算法集成,弥补了单模型预测的不足,减少了训练过程中生成的冗余信息,提高文本校对准确性.集成框架如图 3所示.
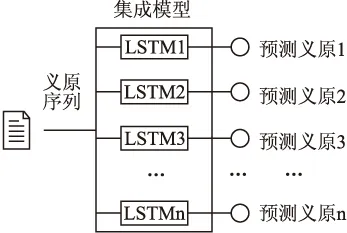
图3 集成模型框架
每个LSTM子模型均采用时序优化(BPTT)方法进行优化,集成模型将输入的义原序列输入到每个LSTM子模型后,每个子模型根据自己学习到的经验预测输入义原下一时刻的搭配义原.
3.4 模糊匹配
前文的工作中采用全连接神经网络完成对词语-义原转换,会损失一部分精度,使得在预测搭配义原时出现精度不高的情况.为解决这一问题,需要对预测结果进行模糊匹配,得到模糊匹配集合.常见的模糊匹配是借助相似度来完成的,对于两个义原向量,它们之间的距离越近或相似度越高,义原向量对应句子的语义就越接近.在计算两个向量相似度时,还需要考虑两个向量之间对应元素的差异,对应元素的值越相近,相似度也就越高[11].传统欧氏距离忽略这一差异,本文将加权欧氏距离作为相似度的度量指标,计算预测义原向量与HowNet义原向量之间加权欧氏距离,并选取K邻近算法进行模糊匹配,对每个预测义原得到对应的模糊匹配集合.
加权欧氏距离是对欧氏距离的一种改进方法,假设n维义原向量A(x1,x2,x3,...,xn),集成模型预测得到的义原向量B(y1,y2,y3,...,yn),则两个向量之间的加权欧氏距离如式(7)所示.
(7)
其中ωi为权值,ωi=e-|xi-yi|/σ;σ是调节因子,这里取σ=1;W是归一化因子,W=∑ωi[12].
3.5 基于聚合度的评价方法
聚合度是化工领域用于衡量聚合物大小的指标,在这里本文使用聚合度PD作为衡量义原搭配准确性的指标.
设中心词为x,中心词的搭配词为y,与x具有相同义原的义原集合为X,则集合X和y的搭配程度称作PD(聚合度),以PD表示,PD的计算公式如式(8)所示.
(8)
N为义原集合中义原个数,Cωi,y的定义如式(9)所示.
(9)
通过以上公式可以看出,PD越趋近于1,x和y构成正确搭配的可能性就越大;PD越趋近于0,x和y构成正确搭配的可能性就越小.
以义原序列最后一个义原对应的词作为中心词x,其搭配词为y,计算聚合度.设α为PD的阈值,当PD≥α时,认为x和y构成正确搭配;否则视为语义搭配错误,计算x与预测搭配义原集合中每个义原的聚合度,依据聚合度投票并排序,截取排名靠前的义原对应的词语作为校对建议.
4 实 验
4.1 实验环境
本文的实验环境及其配置如表1所示.
表1 实验环境配置
4.2 实验数据集
实验选取的训练语料是《人民日报》,该语料库来自北大计算语言研究所(1998年公布),约2600万字,是新闻类的语料,语句标准且用词规范,已经完成了校对、分词以及词性标注等工作,是中文自然语言领域公开的大规模数标注据集.语料的文本没有处理停用词,每一行都是一个完整的句子,满足本实验对训练语料的要求.
4.3 相关参数的确认
需要确定的相关参数包括:模糊匹配过程中使用到的K邻近算法的K值、聚合度阈值.
对比不同阈值对准确率的影响,如图4所示,阈值选取0.6时,准确较高,故阈值α取值为0.6.
实验中的K邻近算法用于得到预测义原的模糊匹配集合,故在确定K值时应考虑义原搭配的分布情况,选取可代表大多数义原搭配数量的值作为K值. 统计语料库中所有义原搭配数目,得到义原搭配数量分布图,如图5所示.
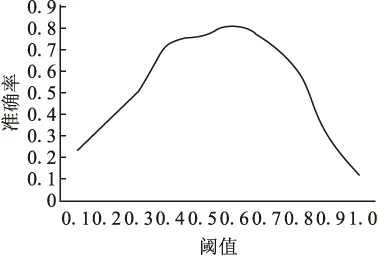
图4 阈值对准确率的影响
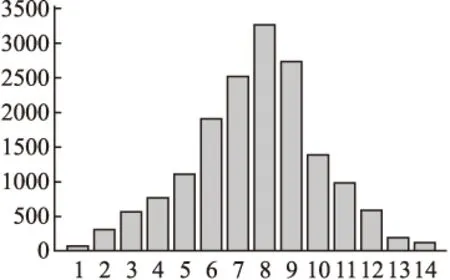
图5 义原搭配数量分布图
横坐标代表每个义原的搭配义原的个数,纵坐标代表有i个搭配义原的义原数量.通过实验对比了不同的K值对文本检错准确率、召回率和F值的影响,如图6所示.
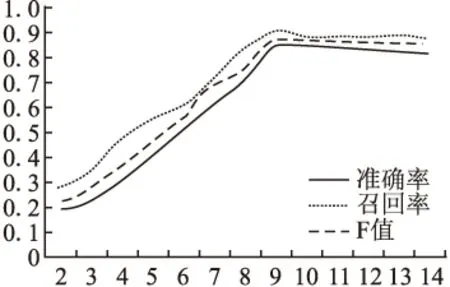
图6 K值对准确率、召回率和F值的影响
通过观察可以发现义原搭配数量基本符合正态分布,且数量大都集中在[4,12]的区间上.结合图5和图6中的趋势可以发现当K值取9时,F取最大值,故可将K取值为9.
4.4 评价指标及对比实验
本文采用文本检错准确率P、召回率R、F值以及校对准确率这四个指标对算法性能进行评价,其计算方法如公式(10)-式(13)所示.
(10)
(11)
(12)
(13)
4.5 实验及评价
文章基于Pytorch框架,采用Python语言对提出的模型进行了验证.实验分为三个部分:无错文本的语义校对、错误文本的语义校对和常规文本的语义校对.
4.5.1 无错文本的语义校对
从《人民日报》语料库中随机抽取80条数据作为测试集,用于检验模型对训练语料的错误检测能力,经实验发现在测试集上中未发现语义搭配错误,说明模型能够根据学习到的规律对语义信息错误与否作出正确的判断,但此种情况需要考虑算法是否存在过拟合的问题,为此需要在错误文本和常规文本上进行语义校对实验.
4.5.2 错误文本的语义校对
语义错误检测方面目前没有公开的测试数据集,国内外中文文本校对工作采用的测试数据集均是自行构建.本文整合300条中小学语文语病修改试题作为语义错误测试集,依据上述评价指标得出本文的实验结果.与此同时,文章也实现了相关文献中提到的方法,并在本文构建的数据集上进行了验证,发现这些方法在本测试数据集上的表现不如在原文中的效果好,故仍采用原文中的实验结果,如表2所示.
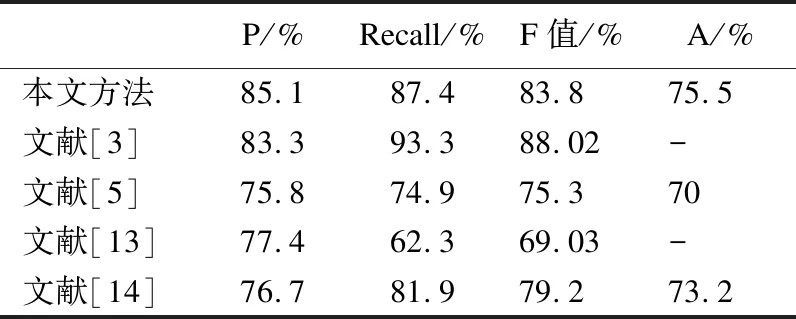
表2 实验结果对比
由表 2可以看出,本文提出的模型能够对错误文本起到较好的校对作用,不存在过拟合的现象.虽然模型在召回率和F值上没有取得最高值,但在准确度和校对正确率上与其他文献相比均取得了最高值.
4.5.3 常规文本的语义校对
为进一步验证模型对文本语义错误检测及校对的效果,文章收集并整理了实验室最近几年的硕士论文初稿12篇,通过模型检查初稿中存在的语义搭配错误,检测其中存在379处语义错误.经过精度原文,发现其中真正的语义错误为281处,准确率为74.14 %.随机选取两篇论文进行仔细阅读揣摩,发现实际存在53处错误,这些错误被模型检测出 的有38处,召回率为71.69%.为计算校对准确率,对比并分析了281处语义错误的校对建议,统计结果显示有197处校对建议是正确的,校对准确率为70.11%.实验中所得准确率、召回率以及校对准确率均略低于表2中实验结果,是由于这里选取的文本数据是计算机专业的硕士论文,论文中有着大量的专业术语,而《人民日报》是新闻题材的文本,语句以书面用语为主,这两种数据在题材和用词习惯方面均存在差异.
5 结束语
本文在前人的研究成果之上,设计一种基于集成算法和长短时记忆网络的集成模型.模型结合HowNet义原知识库和神经网络学习词语-义原之间的搭配关系,采用集成模型,利用子模型之间的差异性,扩大语义信息的提取范围,将多个长短时记忆网络集成在一起,预测语义搭配关系,结合模糊匹配方法,使用聚合度对预测结果投票并排序,将排名靠前的结果作为校对建议输出,提高了检错和校对准确率,并通过实验验证了模型的有效性.
《人民日报》基本标注语料库属于新闻题材的语料,且选词标准.本文使用该语料库作为训练数据得到的模型对口语化严重的社交网络文本数据不能达到很好的效果.目前已经有针对社交网络用语的研究[15].在今后的工作中,我们将会在语义级加强语法分析以及词语搭配关系分析的研究工作,在口语化严重的社交网络文本上,尝试设计新的模型和方法,进一步提高文本语义特征检测和校对的效果.
