面向语音识别系统的黑盒对抗攻击方法
2020-05-14陈晋音叶林辉郑海斌杨奕涛俞山青
陈晋音,叶林辉,郑海斌,杨奕涛,俞山青
(浙江工业大学 信息工程学院,杭州 310023)
E-mail:chenjinyin@zjut.edu.cn
1 引 言
随着深度学习模型在语音识别应用中取得的成功,语音识别控制系统如Amazon Alexa,谷歌语音助手,苹果siri,微软Cortana和科大讯飞等商业产品在人机交互中获得广泛应用,并在移动设备、智能家居等多个领域取得成功,尤其在自动驾驶、声纹身份认证等安全级别较高的应用场景中实现了关键应用.
传统语音识别模型多数采用隐马尔科夫高斯混合模型(HMM-GMM)[1],建立在似然概率基础上,利用区分度训练在一定程度上拟合了模式类之间的差异性.深度学习的引入使语音识别系统原有的技术框架得到彻底改变[2-5].深度神经网络可以充分利用特征之间的关联性,将连续帧的语音特征合并后进行训练,使语音识别系统的识别率大幅度提高.
由于深度神经网络的优异性能,已有较多基于深度神经网络模型的语音识别系统.然而,Goodfellow[6]和Szegedy[7]发现深度神经网络容易受到对输入数据添加细微扰动形式的对抗攻击.例如在自动驾驶领域,车载语音识别系统在输入时被外加的细微扰动所攻击,语音识别系统将错误地识别乘客的指令,这给自动驾驶系统带来了极大的安全隐患.
随着图像领域对抗攻击的研究深入,音频领域的对抗攻击也逐步提出.两种攻击存在差异,首先,语音识别系统需要处理时间域上的信息变化,这比图像分类系统更复杂;其次,音频的采样率通常都非常高.例如:采样率为16kHz的音频,每秒采样16000个数据点,相比于图像分类,这意味着要处理更大的数据量.因此,语音识别领域对抗样本的生成过程更加复杂.
Carlini[8],Cisse[9]和Iter[10]提出了语音识别对抗攻击生成方法,在已知识别模型结构的前提下基于梯度信息生成对抗样本,属于白盒攻击方法,Carlini指定了攻击的目标短语,属于目标攻击,而Cisse和Iter的攻击方法未指定特定攻击目标短语,属于无目标攻击(逃逸攻击).而在实际应用中,通常攻击者很难获得识别模型的结构信息,且攻击是为了达到特定目标(例如,使得某一段语音识别成特定的指令),因此黑盒的目标攻击在实际应用中更具有攻击性与隐蔽性.
为实现面向语音识别系统的黑盒目标攻击,本文提出了一种面向语音识别系统的黑盒攻击方法,主要工作包括:
1)提出了一种基于布谷鸟搜索优化算法的黑盒对抗攻击方法,实现对语音识别系统的黑盒攻击;
2)通过设定攻击目标指令,可将任意正常样本通过布谷鸟搜索算法自动生成对抗样本,实现了黑盒设置下的目标对抗攻击,验证了提出方法具有较强的目标攻击能力与样本生成能力;
3)将本文提出的方法在多个实际数据集展开验证,包括:公共语音数据集、谷歌语音命令数据集、GTZAN数据集和LibriSpeech数据集,验证提出方法的有效性.并分析了生成对抗样本的攻击迁移性,验证其对其他语音识别模型具有迁移性攻击,并对对抗样本进行了主观评测,探究了其隐蔽性.
2 相关工作
2.1 语音识别深度模型
基于隐马尔可夫模型(HMM)的语音识别模型是常用方法之一,Baum[11]率先使用最大似然原则对HMM模型进行训练.Macherey[12]把比最大似然原则更优的判别训练应用在HMM上,采用了最小分类误差优化模型的参数并取得较好结果.Zheng[13]提出了一种新的判别训练标准,使用最小通话帧误差加速了模型的训练,并且使得模型的准确率有所提高.Wu[14]提出了基于最小代误差的HMM训练方法,提高了模型的识别精度.
在基于HMM的语音识别模型基础上,利用高斯混合模型(GMM)状态观测概率进行建模.Yu[15,16]用上下文相关的深度神经网络模型(DNN)来替代高斯混合模型,并取得了良好的效果.Mohamed[17]使用深度置信网络代替高斯混合模型来提高模型的识别率.Yao[18]将自适应的方法引入DNN-HMM的模型中,使词错误率进一步降低.
近几年,提出了较多基于深度学习模型的语音识别方法,端到端的语音识别方法直接将输入的声学特征序列映射到输出的词序列.Graves[19]利用连接主义时间分类(CTC)来建立端到端的语音识别模型.随后,百度拓展了这项工作,利用大量的数据训练得到能成功商用于英语和普通话的语音识别模型[3].Zhang[20]将深度卷积网络引入端到端模型,进一步增强了模型的表达和泛化能力.谷歌的DeepMind团队推出了可以生成音频的深度神经网络WaveNet模型[5],WaveNet不仅能作为一种生成模型,而且可以完成语音识别的任务.Chan[21]提出了一种端到端的语音识别注意力模型,进一步提高识别准确率.
2.2 对抗攻击与防御方法
受到图像领域对抗攻击研究的启发,音频领域的对抗攻击正在受到越来越多的关注.Gong[22]使用2%大小的扰动使得基于深度神经网络的语音识别系统误识别,实现了无目标攻击.Carlini[23]提出了一种通过MFC层传递梯度的方法,并将其应用到DeepSpeech模型[2]中,通过从一个梯度连接到原始输入,其攻击绝大多数情况下能够成功.Wang[24]利用快速梯度符号法(FGSM),对基于注意力机制的深度关键词识别模型生成了对抗样本.Schönherr[25]利用心理声学原理,基于梯度信息构建了隐蔽性良好的对抗样本,实现了目标攻击.Qin[26]同样利用了心理声学原理和梯度信息实现了目标攻击,与Schönherr[25]不同的是,Qin[26]构建的对抗样本具有更好的隐蔽性和更强的鲁棒性.Yakura[27]在对抗样本生成过程中引入了脉冲响应和高斯白噪声,提高了生成的对抗样本对回声和环境噪声的鲁棒性.而这些攻击的方法均在已知模型结构前提下展开攻击,属于白盒攻击.
在黑盒攻击方面,Alzantot[28]已经证明,实现针对自动语音识别系统的黑盒目标攻击是可行的.Zhang[29]通过调制超声波载波的命令并利用麦克风的漏洞提出了海豚攻击.Du[30]提出了SirenAttack,利用粒子群优化算法,分别在白盒和黑盒设置下成功生成了对抗样本,他们在多种语音识别模型上进行了实验,并取得了较好结果.Khare[31]在黑盒设置下使用多目标进化优化的方法对DeepSpeech[2]和Kaldi-ASR(Automatic Speech Recognition)[4]模型进行目标攻击,成功实现黑盒攻击.Gong[32]在黑盒设置下,利用强化学习实现了实时对抗攻击,但是只攻击了指令识别模型,实现的是无目标攻击,且存在计算资源消耗大的问题.Abdullah[33]使用在语音信号处理阶段加噪声的方法,通过将目标指令隐藏在噪声中实现了黑盒攻击,该方法生成的对抗样能够使模型识别,而人听起来就像噪声,无法获取对抗样本中隐藏的内容.但现实中,当人听到扬声器传来噪声时,很有可能会引起警觉发现异样,也就是说该方法生成的对抗样本隐蔽性不够高.
针对语音识别系统的攻击,也提出了一些防御方法用于消除攻击带来的影响.这些方法的一个共同特点就是检测收到的信号是否来自于一个正在说话的人.Lei[34]提出了一种利用无线信号来检测人体运动的虚拟按钮,只有在检测到人体运动时才能接受语音命令.Feng[35]提出了VAuth(Vee-Auth),这是第一个为语音助手提供连续和可用身份验证的系统.通过可穿戴设备采集用户的体表振动,并将其与语音助手的麦克风接收到的语音信号相匹配,以此来验证语音命令是用户发出的.然而,这些方法都是有限的,因为语音命令不一定伴随可检测的运动,可穿戴设备(例如眼镜)也不方便.Zhang[29]提出了利用超声波和麦克风漏洞攻击的方法,同时也提出了相应的防御方法,利用一种能抑制超声载体信号的增强型麦克风来防御.在对抗性声学系统的防御方面,Szegedy[7]提出了对抗训练,Wang[24]利用生成的对抗样本和原样本对关键词识别模型进行重训练,提高了模型的鲁棒性,但对抗训练的局限性在于,经过重训练的模型可实现相应攻击的防御,在实际中,攻击者可以更改参数来绕过防御.Du[30]提出了滑动平均滤波的防御方法,即把某个采样点的前K-1个和后K-1个采样点作为参考点,用参考点的平均值代替这个采样点的方式进行防御,具有一定的防御效果.针对语音识别系统的防御研究,本文提出了两种防御对抗攻击的策略,尝试实现语音识别模型的防御.
2.3 群优化搜索算法
智能优化算法如遗传算法[36]、蚁群算法[37]、粒子群算法[38]、布谷鸟搜索算法[39]等,通过模拟生物的行为或自然界的现象求解目标优化问题.
布谷鸟搜索算法是Yang[39]提出的一种模仿自然界中布谷鸟育雏行为的启发式算法.布谷鸟本身不筑巢、不孵卵、不育雏,而是通过将卵产在其他鸟(宿主)的鸟巢中,由宿主代为孵化和育雏的方式进行繁衍.布谷鸟趁宿主外出时将自己的卵产入宿主的鸟巢中.为了不被宿主察觉,布谷鸟在产卵之前会把宿主鸟巢中的一枚或多枚卵移走,来保持鸟巢中原有的卵数量.一旦布谷鸟的寄生卵被发现,这个卵便会被宿主移走或者宿主丢弃这个鸟巢去建立新的鸟巢,布谷鸟寄生繁殖失败.
布谷鸟通过莱维飞行搜寻鸟巢.莱维飞行属于随机行走的一种,行走的步长满足一个重尾的稳定分布,在这种形式的行走中,高频率的短距离飞行和低频率的长距离飞行相间.
由于布谷鸟搜索算法的操作简单、收敛速度快、具有较强的空间搜索能力,因而本文选用布谷鸟搜索算法优化扰动,生成对抗样本.在实际寻优过程中,鸟巢就是解,鸟巢的数量作为种群大小,根据具体优化问题而设定,通过莱维飞行更新鸟巢位置.宿主以一定的概率Pa发现异常卵,在实际问题中则以概率Pa剔除适应度低的解.
3 基于布谷鸟搜索算法的黑盒对抗攻击方法
本文提出基于布谷鸟搜索算法的对抗攻击方法,输入原始音频样本,通过布谷鸟搜索算法寻找近似最优对抗扰动,并生成相应的对抗样本,样本的攻击效果通过输入目标模型(DeepSpeech)判定其输出结果作出评价,最终将搜索得到的最优解输出,即为有效对抗样本,其系统框架如图1所示.
本文利用布谷鸟搜索算法优化扰动生成对抗样本.首先,原始音频复制至设定鸟巢数量后通过添加随机噪声扩大鸟巢之间的差异形成初步解;其次,通过莱维飞行产生新解,通过适应度函数,比较新旧解的优劣,更新鸟巢.在优化过程中,发现当适应度函数值低于一定值时,布谷鸟算法不再高效,因此设定阈值ψ.当适应度函数值小于阈值ψ时,在布谷鸟算法的基础上添加变异操作,扩大搜索范围.最后,判断对抗样本是否识别为目标短语或达到最大迭代次数,若未产生对抗样本并未达到最大迭代次数,继续迭代优化对抗样本.
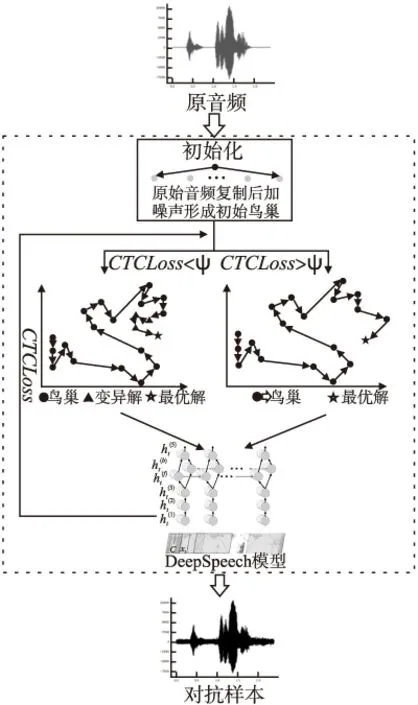
图1 系统框架
3.1 鸟巢初始化
将原始音频复制至设定鸟巢数量,由于复制后的各个解之间不存在差异,无法确定最优解,因此不能直接通过布谷鸟搜索算法优化.通过添加随机噪声的方法扩大各个鸟巢之间的差异性,完成初始化.例如:DeepSpeech模型的输入为采样率为16kHz的音频文件,恢复为模拟信号后的音频文件的最高频率为8kHz.根据Reichenbach[40]的研究表明,人耳对低频比高频更敏感,因此对噪声使用截止频率fcutoff=7kHz的高通滤波器,将噪声限制在高频范围内,使人耳更难察觉.初始化后的鸟巢通过适应度函数进行评分,确定初始种群的最优解,并记录最优适应度值.
3.2 适应度函数
连结主义时间分类(CTC)是Graves[41]提出的一种端到端的循环神经网络(RNN)训练方法.传统的语音识别模型中,对语音模型进行训练之前,需将文本与语音进行严格对齐,即需要将每一帧对应到标签,而CTC不需要对齐语音和文本.CTC的损失函数CTCLoss可以解释为给定样本后输出正确label的概率之和.本文使用CTCLoss作为适应度函数FCTCLoss(x),一方面得益于CTC不要求对齐,另一方面是CTCLoss可较好衡量对抗样本与目标短语之间的接近程度.
假定x为DeepSpeech的输入,其输出序列π为可能解码为对应文本T的序列,定义集合Z=(a,z)∪(_)∪(-),其中“_”表示空格,“-”为CTC引入的特殊字符,这个字符可以避免CTC解码器在解码过程中删除序列π中可以解码为对应文本的字符,其中π∈Z.
DeepSpeech模型定义为y=F(x),其中x∈X,为输入音频X的某一帧,其输出y为字符的概率分布,由此概率分布可以确定输出序列为π的概率.对于输入X,CTC解码器在解码时,对序列π进行移除相邻重复字母和移除特殊字符“-”的操作.例如对输入为10帧的音频X,若其对应文本T为“apple”,则对序列π1-“-aappp-ple”与序列π2-“ap-p-l-eee”进行移除相邻重复字母和特殊字符的操作,则序列π1和π2均可解码为“apple”.因此对于一个输入音频X,其输出预测序列π是不唯一的.因此在输入X下,其输出为序列π的概率为:
(1)
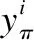
(2)
而CTCLoss定义如下:
CTCLoss(f(x),T)=-logP(T|f(x))
(3)
可以发现,在模型训练时,当解码为T的概率P(T|f(x))越大,CTCLoss越小,由此本文定义适应度函数FCTCLoss(x)如下:
FCTCLoss(x)=-CTCLoss(f(x),t)
(4)
其中,t为设置的目标短语,可见,当对抗样本解码为目标短语t的概率越大,FCTCLoss(x)越大,则评分越高.
3.3 布谷鸟搜索算法实现
布谷鸟搜索算法通过莱维飞行机制和随机游走寻找鸟巢,莱维飞行是一种由小步长的短距离飞行和偶尔大步长的长距离飞行组成的随机游走过程,因此布谷鸟搜索的寻窝路径容易在不同的搜索区域间跳跃,导致布谷鸟搜索算法的局部精细搜索能力较差,在算法迭代后期容易在全局最优解附近的区域出现震荡现象,造成算法效率偏低.因此本文在达到一定条件后,在布谷鸟搜索算法中加入变异操作,提高算法寻找最优解的效率.
3.3.1 莱维飞行
在自然界中,布谷鸟搜索以随机或者类似随机的飞行方式来寻找适合自己产卵的鸟巢位置,为了便于模拟布谷鸟搜索的繁殖策略,Yang等[39]将布谷鸟搜索算法假设为以下三个理想状态:
1)每只布谷鸟搜索一次只产一个卵,并随机选择一个位置的鸟巢进行孵化.
2)在随机选择的一组鸟巢中,优质的鸟巢将会被保留到下一代.
3)可利用的鸟巢数量固定,宿主鸟发现外来鸟蛋的概率为Pa∈[0,1].当宿主鸟发现外来的布谷鸟蛋的时候,它会将布谷鸟蛋丢弃或者重新建立新的鸟巢.
基于以上三个理想状态,使用Mentegna算法[42]实现莱维飞行.莱维飞行更新如下:
(5)
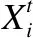
(6)
其中,u,v是两个服从高斯分布的变量,β是常数,其值由具体问题决定,σ2由公式(7)计算:
(7)
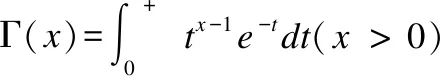
利用莱维飞行,对除最优鸟巢以外的鸟巢的位置和状态进行更新,产生新鸟巢.比较每个新鸟巢与旧鸟巢的适应度,将旧鸟巢中适应度差的解替换为新鸟巢中适应度优的解,并找出当前种群中适应度最优的鸟巢,保存至下一代.
3.3.2 局部随机游走
局部随机游走定义为宿主鸟以一定的概率Pa发现外来鸟后重新建窝的路径.产生的鸟窝的位置采用偏好随机游动的方式,即利用了其它鸟窝的相似性.新建的鸟窝的位置公式定义如下:
Xt+1=Xt+γ*Heaviside(Pa-ε)*(Xi-Xj)
(8)
其中,γ和ε是服从均匀分布的随机数,相互独立,Heaviside(x)是跳跃函数,Xi,Xj是其它任意的两个鸟巢.局部随机游走产生的新鸟巢同样需要与旧鸟巢比较,将旧鸟巢中适应度低的解替换为新鸟巢中适应度高的解,并记录当前种群中适应度函数最优的鸟巢,保存至下一代.
3.4 变异
当CTCLoss减小到一定范围时,对抗样本接近目标扰动,此时的莱维飞行由于种群个体太过相似而容易陷入局部最优,无法产生更优解.因此,本文设计了变异操作拓展搜索空间,提高搜索效率.通过对所有解添加随机噪声的方式进行变异,同时,这个噪声会通过一个截止频率为fcutoff=7kHz的高通滤波器,将噪音限制在高频范围内.若变异操作产生比原来解中更优的解,通过替换旧解更新鸟巢,最优解将会被保留到下一代.变异算法在增加种群的多样性的同时,用变异概率限制或扩大变异的程度.若变异概率太低,可能产生不了新的更好的最优解,而变异概率过大,可能会错过最优解.因此设置了动量更新公式更新突变概率:
(9)
其中,pold表示种群原来的突变率,pnew表示种群新的突变率,currScore表示当前种群的得分,preScore表示上一代种群的得分.μ和γ是相关系数,μ值越大,新的突变率pnew越接近pold;γ越大,pnew变化的范围越大.μ的取值应比较大,γ应较小,这是为了控制pnew的变化幅度,若变化幅度太大,可能会使原有解的较好形态的消失.动量更新增加了突变概率的加速度,当种群优化停滞时,通过保持高的突变概率,使得突变的部位累积并随迭代次数而相加.变异操作将增加种群的多样性,与莱维飞行结合,将更加高效的获得最优解.
3.5 算法基本流程
布谷鸟搜索算法
输入:原始音频X,目标短语t,迭代次数itr,最大迭代次数Max
输出:对抗样本Xadv
初始化鸟巢:产生n个寄主鸟巢,添加噪声扩大差异,形成初始解Xn
计算初始鸟巢最优适应度值Fbest,确定最优解Xbest
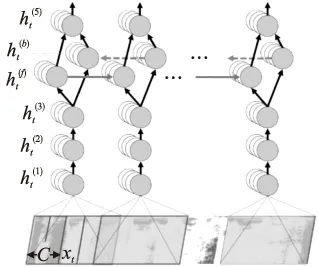
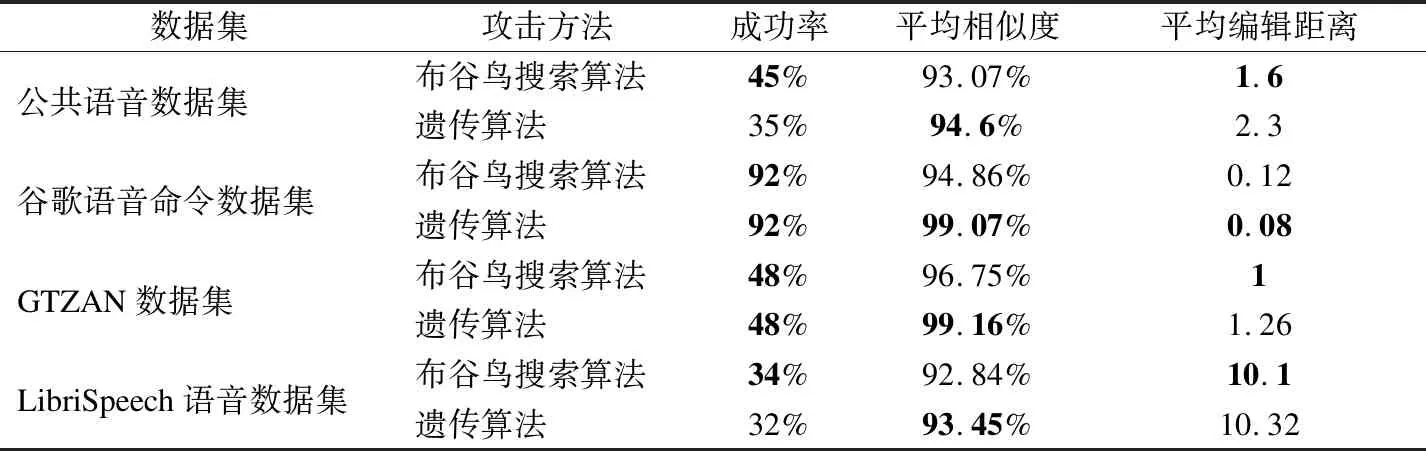
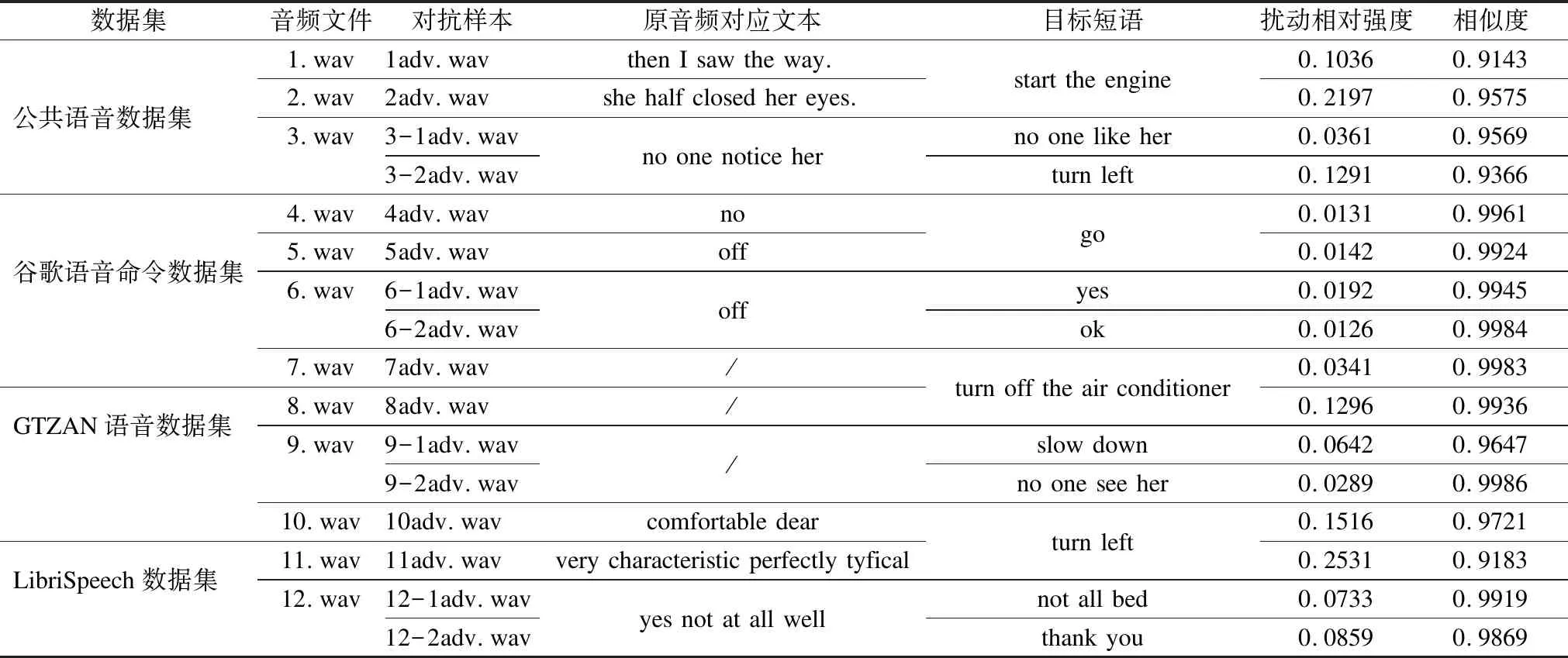
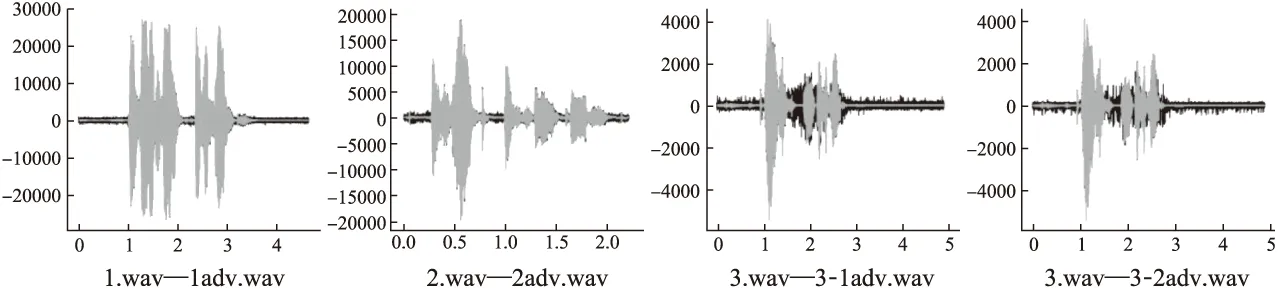
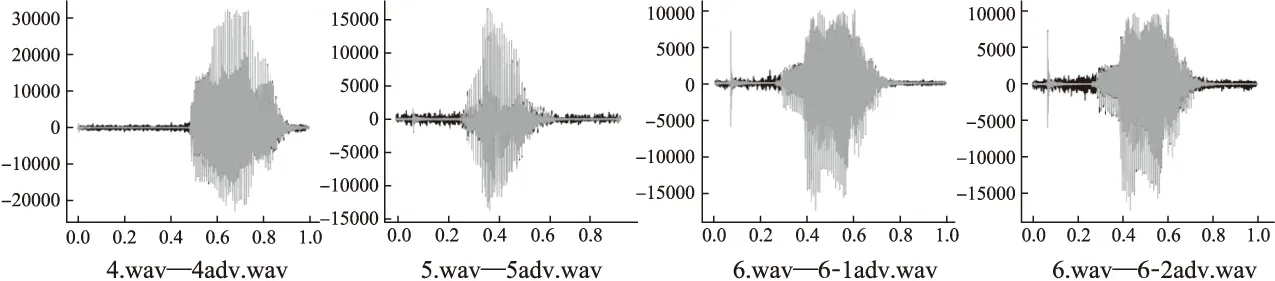
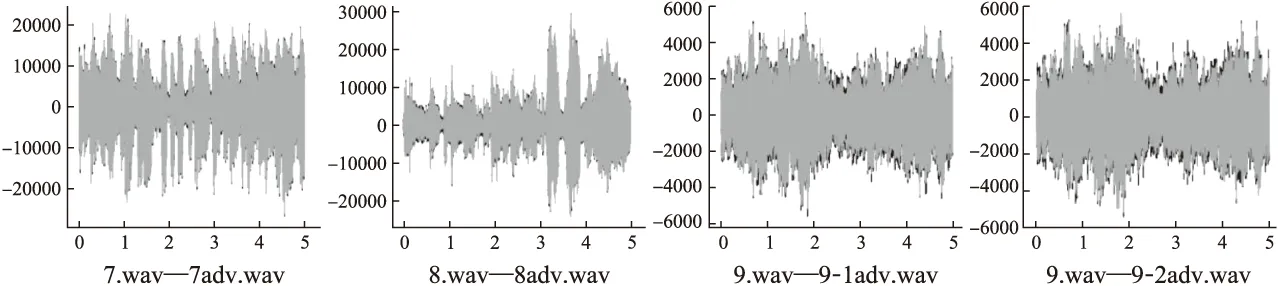
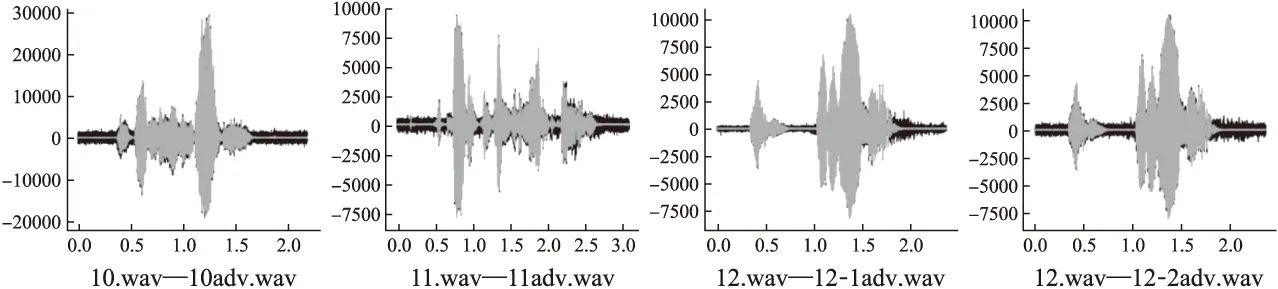
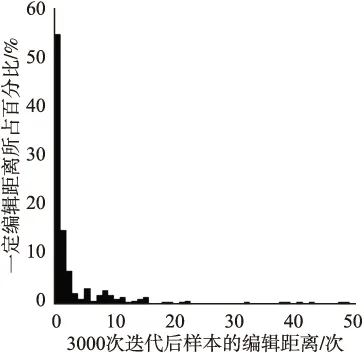
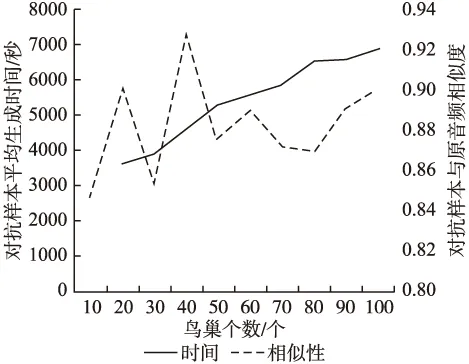
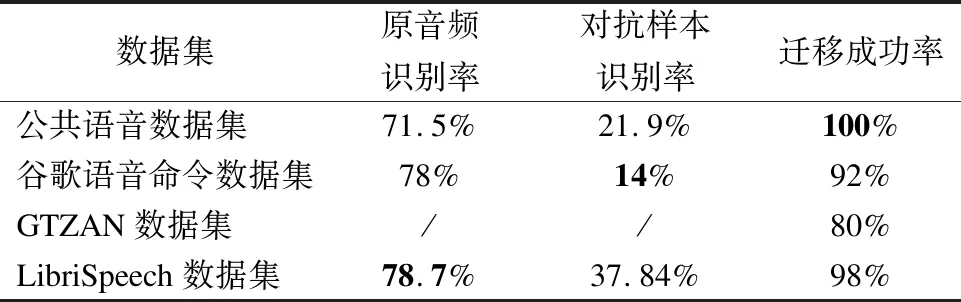
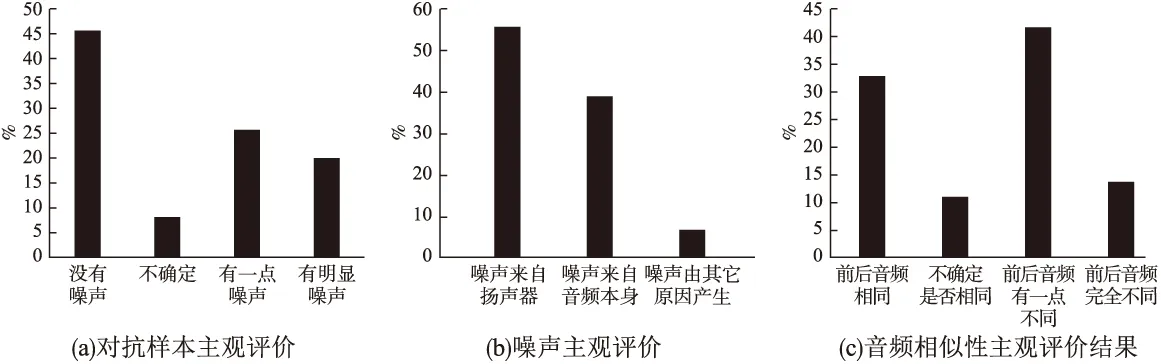
while (itr 莱维飞行产生新解X′n 比较新旧解适应度值F′n,Fn ifF′i>Fi(i=1…n) Xi=X′i IfF′best>Fbest Xbest=X′best ifF″i>Fi(i=1…n) Xi=X″i ifF″best>Fbest Xbest=X″best ifCTCLoss<ψ 加入变异操作 end while returnXadv=Xbest 为验证本文方法的有效性,在四个数据集上展开实验,包括:公共语音数据集(1)https://voice.mozilla.org/zh-CN/datasets,谷歌语音命令数据集(2)http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz,GTZAN音乐数据集(3)http://marsyas.info/downloads/datasets.html和LibriSpeech数据集(4)http://www.openslr.org/12/.其中,公共语音数据集是Mozilla开源的大型语音数据集,它由用户朗读来自于博客,书籍,电影等多个公共信息源的文本收集而成.它拥有超过500小时的样本,大约有20000名志愿者提供了40000多份样本.谷歌语音命令数据集是由谷歌的TensorFlow团队创建的语音数据集.该数据集包含30种短单词的命令,总共有65000个时长为1秒的,只包含一个单词的命令语音.GTZAN音乐数据集包含了10种音乐风格的总量为1000个的30秒长的音乐片段.LibriSpeech语音数据集包含了1000小时采样率为16kHz的有声录音,并且经过切割和整理成每条10秒左右的、经过文本标注的音频文件. 为了确定对抗样本和原始样本之间的扰动大小,引入了分贝(dB).用分贝来衡量单个音频样本的相对强度: dB(X)=max(20log10X) (10) 其中,X表示输入音频.在本次实验中,在dB级别上,将生成的对抗样本Xadv和原始音频X比较,以此确定相对扰动的强度: dBX(Xadv)=|dB(Xadv)-dB(X)| (11) 为了比较生成的对抗样本和原音频的相似度,引入了皮尔逊相关系数来衡量对抗样本和原音频的相似度,皮尔逊相关系数公式如下: (12) 其中cov(X,Y)是矩阵X,Y的协方差,δX,δY分别表示矩阵X,Y的标准差. 为了比较生成样本的解码结果与目标短语的差距,引入了编辑距离.编辑距离是用来度量两个序列相似程度的指标,指的是在两个序列 本文设计攻击的目标模型为百度的DeepSpeech模型[2].DeepSpeech是一个开源的基于CTC的端到端深度语音识别模型(5)https://github.com/carlini/audio_adversarial_examples,其核心是一个循环神经网络(RNN),由五层隐藏单元组成.如图2所示,网络的前三层不是循环神经元,第一层的输出取决于每个时间的输入xt以及xt左右相邻的C帧音频,第二、三层的输入为前一层的输出,对于每一时间步,前3层可以计算为: (13) 第四层是双向递归层,这一层有两类神经元,一类是前向递归h(f),另一类是后向递归h(b): (14) (15) 若输入音频的总帧数为T,则h(f)必须从t=1到t=T依次计算,同时h(b)神经元从t=T到t=1反向依次计算. 第五层将第四层中的前向和后向单元的输出作为输入: (16) (17) 模型通过CTCLoss计算预测误差.DeepSpeech使用Switchboard(SWB)数据集和Fisher(FSH)数据集进行训练,数据集总时长为2300小时.模型通过数据并行和模型并行的方式训练,能在数小时内完成2300小时的音频数据的训练,并在300小时的Switchboard的数据集上进行了评价,在Hub500S数据集上进行了测试.实验结果表明在使用可比较的数据量进行训练时,DeepSpeech与现有最佳ASR系统相比具有竞争力[2].另外DeepSpeech向Wall Street Journal(WSJ)数据集,Switchboard(SWB)数据集,Fisher(FSH)数据集和Baidu数据集加入噪声,将加入噪声后的数据集对模型进行训练,并将所有数据重新采样到16khz,数据集总时长超过10万小时.DeepSpeech的测试结果表明,其在噪音环境下的识别率优于Bing,Apple等语音识别系统[2]. 为了验证本文提出的基于布谷鸟搜索算法的黑盒攻击的有效性,在上述数据集上进行了语音的黑盒攻击.初始化40个鸟巢,最大迭代次数设为3000,参数β设为2.当CTCLoss大于55时,采用布谷鸟算搜索法优化扰动.当CTCLoss小于55时,在布谷鸟算法的基础上加入变异操作,变异率设为0.005.对于公共语音数据集和LibriSpeech数据集,分别从中随机挑选50个训练样本生成对抗样本.对于谷歌语音命令数据集,随机挑选5个指令,在每个指令中随机挑选10条作为训练样本.对于GTZAN数据集,随机从5种风格的音乐样本中随机挑选10条,截取为5秒后作为训练样本.由于DeepSpeech模型的输入为采样率为16kHz的wav文件,因此将所选音频样转化为采样率为16kHz的wav格式的音频文件.对于从每个数据集中随机选出的50条样本,随机以10个音频文件为1组,分成5组,共20组,分别设置不同的目标短语.为了模拟自动驾驶时的场景,对于从公共语音数据集,GTZAN音乐数据集和LibriSpeech语音数据集选出的15组样本,将目标短语设置为“turn left”,“turn right”,“speed up”等自动驾驶时常用的短语.若在自动驾驶时,语音识别系统将“stop”识别为“go”,这很有可能带来巨大风险,考虑到这个场景,将谷歌语音命令数据集的目标短语设置为与其相反的短语,如音频的对应文本为“on”,则目标短语设置为“off”.另外,分别从4个数据集中,随机挑选2个音频文件作为样本,每个样本随机设置10条不同的目标短语,分析攻击效果.根据上述4个语音数据集的实验结果分析本文攻击方法的有效性. 图2 DeepSpeech模型结构 定义攻击成功,当生成的对抗样本被识别为目标短语,则视为攻击成功,否则失败.表1列出了在各个数据集上的攻击成功率,扰动的相对强度的平均值和对抗样本与原音频相似度的平均值.对比公共语音数据集,谷歌语音命令数据集和LibriSpeech数据集的结果可以发现,样本词长度越长,攻击的成功率越低,所添加的扰动越大,对抗样本与原音频的相似度越小.而对谷歌语音命令数据集的高攻击成功率可以反映出在自动驾驶领域,使简单的指令误识别为目标指令是相对容易的,对自动驾驶领域的语音控制系统的攻击是存在较大可能性的.从扰动相对强度和平均相似度上可以发现,所添加扰动的相对强度小,对抗样本与原音频有着较高的相似度.对于GTZAN音乐数据集的成功攻击反映出可以将目标短语嵌入到音乐中,而由于音乐能够使人放松等特性,所加的噪声将更难被发现. 表1 基于布谷鸟算法的黑盒攻击方法在不同数据集上的攻击情况 Table 1 Black-box attack based on cuckoo algorithm on different data sets 数据集样本平均词长目标短语平均词长攻击效果成功率相对扰动强度(dB)平均相似度公共语音数据集5.482.851.43%0.18493.07%谷歌语音命令数据集1.00188.57%0.10895.07%GTZAN数据集/3.645.71%0.25496.16%LibriSpeech数据集8.06235.71%0.24594.12% 本文比较了布谷鸟搜索算法与Taori[43]提出的遗传算法的攻击成功率,平均编辑距离和平均相似度.从上述4个数据集中,每个数据集随机挑选50条音频作为样本,将目标短语设置为1000个最常用英语短语中词长度为2的短语,每个样本迭代3000代,分别用遗传算法和布谷鸟搜索算法生成对抗样本.如表2所示,本文提出的布谷鸟搜索算法的攻击成功率和平均编辑距离要优于遗传算法,但布谷鸟搜索算法生成的对抗样本在平均相似度上低于遗传算法.布谷鸟搜索算法的核心是莱维飞行和局部随机游走,而遗传算法的核心是种群间的交叉变异.相比于布谷鸟搜索算法,遗传算法的种群间的交叉变异可以把添加的扰动限制在更小的范围内.但通过莱维飞行和局部随机游走,布谷鸟搜索算法可以搜索更大的空间,因此布谷鸟搜索算法的攻击成功率要高于遗传算法,但由于添加的扰动比遗传算法大,因此平均相似度要略低于遗传算法. 为进一步分析对抗样本与原样本之间的相似性,本文在每个数据集上,成功生成的对抗样本中,随机选取4条样本进行比较,并将原始波形和对抗样本波形叠加以可视化扰动.表3列出了所选的样本的对应文本,目标短语,扰动相对强度等结果,为了比较所加的噪声对原音频的影响,将表3的结果用波形图的形式呈现,如图3~图6所示.其中,表3中的音频文件的命名只是为了与图3~图6中的波形图对应,与样本的选择无关.如图3~图6所示,其中浅色波形表示原音频,深色波形表示对抗样本,将原音频与对抗样本叠加后进行比较.首先,从图3~图6可以发现所有扰动几乎都加在原音频波形幅值较小的位置,而这个部分通常被视为环境噪声,这使所加扰动不易被发现.其次,从图中可以发现,在音频的语音部分,所加的扰动很小,因此此攻击方法对音频的语音部分的影响小,隐蔽性高.从图5可以发现,对于GTZAN音乐数据集,所添加的扰动在各个位置的幅值都很小,这说明该攻击方法对GTZAN音乐数据集的改动小,把指令嵌入到音乐中有极高的隐蔽性. 表2 布谷鸟搜索算法与遗传算法比较 Table 2 Comparison of cuckoo search algorithms and genetic algorithms 数据集攻击方法成功率平均相似度平均编辑距离公共语音数据集布谷鸟搜索算法45%93.07%1.6遗传算法35%94.6%2.3谷歌语音命令数据集布谷鸟搜索算法92%94.86%0.12遗传算法92%99.07%0.08GTZAN数据集布谷鸟搜索算法48%96.75%1遗传算法48%99.16%1.26LibriSpeech语音数据集布谷鸟搜索算法34%92.84%10.1遗传算法32%93.45%10.32 表3 原始音频与对抗样本相似度比较 Table 3 Similarity comparison between original audio and adversarial examples 数据集音频文件对抗样本原音频对应文本目标短语扰动相对强度相似度1.wav1adv.wavthen I saw the way.start the engine0.10360.9143公共语音数据集2.wav2adv.wavshe half closed her eyes.0.21970.95753.wav3-1adv.wavno one notice herno one like her0.03610.95693-2adv.wavturn left0.12910.93664.wav4adv.wavnogo0.01310.9961谷歌语音命令数据集5.wav5adv.wavoff 0.01420.99246.wav6-1adv.wavoffyes0.01920.99456-2adv.wavok0.01260.99847.wav7adv.wav/turn off the air conditioner0.03410.9983GTZAN语音数据集8.wav8adv.wav/0.12960.99369.wav9-1adv.wav/slow down0.06420.96479-2adv.wavno one see her0.02890.998610.wav10adv.wavcomfortable dearturn left0.15160.9721LibriSpeech数据集11.wav11adv.wavvery characteristic perfectly tyfical0.25310.918312.wav12-1adv.wavyes not at all wellnot all bed0.07330.991912-2adv.wavthank you0.08590.9869 图3 公共语音数据集的音频文件与相应的对抗样本的波形比较 图4 谷歌语音命令数据集的音频文件与相应的对抗样本的波形比较 图5 GTZAN音数据集的音频文件与相应的对抗样本的波形比较 图6 LibriSpeech语音数据集的音频文件与相应的对抗样本的波形比较 进一步把在4个数据集上生成的对抗样本的识别结果与目标短语进行比较,用编辑距离衡量对抗样本与目标短语间的差距.如图7所示,可以发现大部分样本分布在编辑距离较小的这一侧,说明即使攻击失败,但对抗样本已经十分接近目标短语,只有少部分对抗样本与目标短语相差很远,若增加迭代次数,攻击的成功率将会更高. 图7 3000次迭代后样本的编辑距离所占的比例 本文进一步在谷歌语音命令数据集上的命令做相互转换.随机选出10种指令,在每种指令中都随机挑选10条作为原始音频,将原始音频的目标短语依次设置为其他9种指令.图8比较的是在谷歌语音命令数据集上做命令相互转换后的结果.由于语音命令是单个单词,目标短语的长度也是单个单词,与在另外三个语音数据集上的攻击相比,攻击的难度降低.可以发现不同的语音指令之间进行对抗攻击的成功率很高.从现实角度看,在自动驾驶领域,这也说明语音识别控制系统是存在漏洞的.如简单的“Stop”在加入扰动后就能被识别为“Go”,这将导致汽车识别错误的指令,造成危险. 本文对布谷鸟搜索算法的关键参数鸟巢个数n和参数β进行研究,分别分析两个参数对对抗样本的影响,通过参数敏感性分析算法的稳定性. 图8 谷歌语音命令数据集实验结果 4.5.1 鸟巢个数对对抗样本生成时间与相似度的影响 为了研究鸟巢个数对对抗样本生成时间以及对抗样本与原音频相似度的影响,在不同的鸟巢个数下生成对抗样本.从上述四个数据集中,每个数据集随机挑选5条音频作为样本,在不同的鸟巢个数下生成对抗样本,统计在不同鸟巢个数下生成对抗样本的平均时间和平均相似度.实验结果如图9所示,对抗样本的平均生成时间随着鸟巢个数的增加而增加,因为鸟巢个数越大,计算机需要处理的数据越多,生成对抗样本的时间会越长.鸟巢个数与平均相似度间没有明显的关系,但是注意到鸟巢个数设定为40时,平均相似度达到最大值. 4.5.2β值对相似度的影响 为了比较β值对对抗样本相似度的影响,在不同的β值设置下,生成对抗样本.从上述4个数据集中,每个数据集随机挑选5条音频作为样本,在不同的β值设置下生成对抗样本.迭代次数设置为500,使生成的样本不能完全被解码为目标短语.迭代次数设置较大时,对抗样本可以成功生成,成功生成的对抗样本间的迭代次数可能不同,所加的扰动大小会存在较大差异.为了只比较β对对抗样本的影响,将迭代次数设为500,排除迭代次数不同而带来的差异.从图10可以发现,当β<1.8时,对抗样本与原音频间的相似度很低.β与莱维飞行的步长有关,其值越小,步长越大,对原音频加的噪声就会越大.一方面过大的噪声使对抗样本不具有隐蔽性,另一方面添加的噪声过大会造成模型无法识别音频,导致攻击失败.β=2时,步长很小,对原音频添加的扰动就小,对抗样本与原音频的相似度就高. 图9 鸟巢个数实验结果 图10 β值实验结果 本文提出的基于布谷鸟搜索算法的黑盒攻击生成的对抗样本具有攻击的迁移性.分别从公共语音数据集,LibriSpeech语音数据集,谷歌语音命令数据集和GTZAN数据集中随机挑选50条音频作为训练样本,对于GTZAN音乐数据集,对于每个样本,截取其中的5秒作为训练样本.在DeepSpeech上生成对抗样本.选取用来做攻击的迁移性的语音识别模型为2016年,主要由Google的Deepmind团队推出的一种用于生成音频的深度神经网络,WaveNet模型[5].WaveNet模型的主要成分是因果卷积,它利用卷积来学习t时刻之前的输入数据,预测t+1时刻的输出.虽然该模型是作为一种生成模型设计的,但通过在扩展后的卷积层之后添加平均池层,它可以直接适应诸如语音识别等区别于生成音频的任务.将原音频输入WaveNet模型,计算对原音频的识别率.由于对抗样本是对DeepSpeech模型进行攻击生成的,因此只在WaveNet上统计对抗样本的识别率.对于识别率,定义如下: (18) 只要WaveNet识别的对抗样本与原音频识别结果不同,就视为迁移成功.则迁移成功率: (19) 表4是本文提出的基于布谷鸟搜索算法的黑盒攻击生成的对抗样本的迁移性实验结果.从表4可以看出,WaveNet模型对对抗样本的识别率相比原音频的识别率下降了一半以上,而极高的迁移成功率说明了本文提出的黑盒攻击方法产生的对抗样本能极大的影响其他语音识别模型的识别结果. 表4 对抗样本迁移性实验结果 Table 4 Experiments on migration of adversarial examples 数据集原音频识别率对抗样本识别率迁移成功率公共语音数据集71.5%21.9%100%谷歌语音命令数据集78%14%92%GTZAN数据集//80%LibriSpeech数据集78.7%37.84%98% 为了验证本文提出的基于布谷鸟搜索算法的黑盒攻击生成的对抗样本具有一定的隐蔽性,本文对生成的对抗样本进行了主观评价.从上述4个数据集中,每个数据集中随机挑选5条音频作为样本,生成对抗样本,共20条对抗样本.在进行主观评价的实验中,一共召集了30个听众,他们都是浙江工业大学与语音识别领域、对抗攻防领域无关的在读本科生.在安静的教室使用扬声器播放音频,在听完每个音频后,每个听众将会做一些问答(如你听到的音频存在任何的噪声吗;若存在噪声你认为噪声来自哪里).为了更加接近现实环境,首先单独播放了对抗样本,因为一个攻击者对语音识别模型进行攻击时,只会通过对抗样本对模型进行攻击,不会播放原音频,对于听众来说,原音频是接触不到的,因此通过对对抗样本进行主观评价来探究对抗样本的隐蔽性.然后,将对抗样本和原始音频先后播放,打乱播放顺序,即对于对抗样本和原音频,先播放哪一个是随机的,以此探究对抗样本与原音频在听觉上的差异性.同样的,在听完每对对抗样本和原音频后,每个听众同样会做一些问答(如你听到的前后样本是否有差异;若有差异你认为差异来自哪里).图11(a)是对对抗样本进行主观评价的结果;图11(b)是在听出对抗样本中存在噪声的听众中,对噪声来自于哪里的主观评价;图11(c)是对抗样本与原音频相似性的主观评价结果.从图11(a)中可以发现大部分的听众未从音频中发现噪声,只有20%的听众认为音频中有明显噪声;而从图11(b)中可以发现在听出噪声的听众中,超过一半的听众认为噪声来自于扬声器;从图11(c)中可以发现,认为对抗样本与原音频完全不同的听众低于15%.由此可以说明基于布谷鸟搜索算法的黑盒攻击生成的对抗样本不易引起听众的察觉,在听觉上与原音频相差不大,具有一定的隐蔽性. 图11 对对抗样本,对抗样本中的噪声以及对抗样本与原音频相似性的主观评价结果 对于本文提出的基于布谷鸟搜索算法的黑盒攻击生成的对抗样本,尝试找到防御这类对抗攻击的方法.针对扰动的分布特点,采用了两种方法:重采样和降噪. 为了更好的区分攻击是否失效,从公共语音数据集中随机挑选100个原始音频样本为大于6个词以上的句子,生成对抗样本的目标短语设为2个词.将对抗样本音频的识别结果与目标短语结果不一致定为失效,则失效率: (20) 将完全失效定义为处理后的对抗样本识别结果的词长度大于4且总字母数大于目标短语的总字母数,则完全失效率: (21) 从上图3~图6可以发现扰动几乎在音频的每个时刻都会出现.考虑到语音的识别是逐帧进行检测的,具有连续性,通过实验希望验证扰动对于模型的攻击是否是通过持续的干扰起到的作用.对此,对对抗样本进行重采样. 对抗样本的音频格式为采样率16kHz的wav文件.首先,通过下采样将其降为8kHz的音频.下采样是一个将音频的采样率降低的过程,设原始音频格式的采样率为Q,目标原始音频的采样率为P,则下采样就是对于原始音频中的采样点每隔P/Q-1个取一次点,在本次实验中,每隔一个采样点取一个点.当下采样完成时,与原对抗样本相比,少了一半的采样点. 通过插值法进行上采样,将音频重新通过两个采样点插值的方法重新扩为16kHz,这是为了符合语音识别模型的要求.重新扩充后的音频文件与原对抗样本相比,虽然每秒采样点数相同,但其中一半的采样点是通过重新插值而成,不再是原来的点.从表5中可以发现,重采样的失效率较高,经过重采样后的对抗样本几乎不能被识别为目标短语.但是重采样的完全失效率较低,这说明黑盒攻击虽然失效,但是其长度依然接近于目标短语的长度,也就是说语音识别模型依然把它识别为和目标短语相近的句子.从中可以发现由布谷鸟搜索算法得到的黑盒攻击具有较强的鲁棒性. 使用经典的谱减法[44]对包括扰动在内的所有噪声进行降噪处理.谱减法假设的情况十分简单,如果原音频中只有加性噪声时,用原始音频的频谱减去噪声的频谱,剩下的就是纯粹的语音.将一段音频的前5帧视为无语音的背景噪声部分,将这5帧的噪声进行取平均值,原音频的各个部位都减去这个平均值.这个方法可以对音频各个时间的噪声都做出相减,在整体上对攻击扰动进行干扰. 表5 不同防御方法的防御情况 Tabel 5 Defense situation of different defense methods 防御方法失效率(%)完全失效率(%)重采样94%23%降噪100%100% 表5是降噪下对抗样本的失效率和完全失效率.从结果来看,降噪法比起重采样法对于对抗样本的防御效果更强.因为相比于重采样,降噪方法在整段音频的各个位置上都做了处理,都减去了估计的噪声.但是降噪法的不足在于对噪声的估计是基于前几帧估计的,这些噪声的估计不足以表征各个位置所加噪声的准确值.在整段音频中,有些位置的噪声去除的多了,有些位置未完全去除,这会造成原音频的失真,去噪后的识别结果也变的不理想. 本文提出了面向语音识别系统的黑盒对抗攻击方法,从实验结果来看,本文提出的基于布谷鸟搜索算法的黑盒攻击方法能够攻击语音识别系统,所产生的对抗样本具有攻击的迁移性.在实际应用中,如果攻击者针对某一车载语音识别系统进行攻击,所产生的对抗样本会影响其他车载语音识别系统,这给车载语音识别系统带来了安全隐患.针对这一问题,提出了两个防御方法,并取得了一定的效果.我们希望本次设计的攻击以及防御方法可以帮助研究者改善这方面的风险,提高车载语音识别系统的安全性.但是我们的攻击方法存在着对抗样本生成时间较长,攻击的精度不够高,对于对抗样本的隐蔽性还有提高的空间等问题.所以在接下来的工作中,我们将测试更多语音识别模型,优化训练方法,提高攻击的效率和精度,进一步提高对抗样本的隐蔽性.我们也希望找到这种攻击方法的弱点,提出相应的防御方案,提高车载语音识别系统的安全性.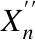
4 实验与结果分析
4.1 数据集
4.2 评价指标
4.3 目标模型
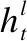
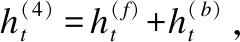
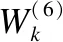
4.4 攻击的有效性实验结果分析

4.5 参数敏感性


4.6 攻击的迁移性


4.7 主观评价
5 语音攻击的鲁棒性测试


5.1 重采样
5.2 降噪

6 总 结
