应用CNN-Seq2seq的PM2.5未来一小时浓度预测模型
2020-05-14刘旭林赵文芳
刘旭林,赵文芳,唐 伟
1(北京市气象探测中心,北京 100176)
2(北京城市气象研究院,北京 100089)
3(北京市气象信息中心,北京 100089)
4(中国气象局发展研究中心,北京 100081)
E-mail:yoyozwf@sina.cn
1 引 言
PM2.5(fine particulate matter)是指一种悬浮于大气中的空气动力学直径小于等于2.5μm的细颗粒物[1-3],它是构成霾的主要成分,其浓度越高,意味着雾霾污染越严重.雾霾天气容易引起交通事故,引发多种呼吸道疾病,危害人类健康[4-7].近几年,我国多地出现雾霾天气,受到各级政府、部门及社会的广泛关注.衡量雾霾污染程度的首要因子是PM2.5浓度,因此准确预测PM2.5浓度对大气污染防御、空气质量的监测和政府决策都具有重要意义.
目前PM2.5的预测主要有数值模式法和统计学预报法.数值模式法广泛应用于气象预报领域,主要基于空气动力学理论和物理化学过程,使用数学方法建立大气污染浓度的稀释和扩散模型动态预测空气质量和主要污染物的浓度变化.国内外常用的空气质量数值模式包括美国环保局研发的多尺度空气质量模式(The Community Multi-scale Air Quality,简称CMAQ)[8-11],美国NOAA预报系统实验室研发的WRF-Chem(Weather Research Forecast-Chemical)[12,13],中国气象局和中国气象科学研究院研发的大气化学模式(Chinese Unified Atmospheric Chemistry Environment,简称CUACE)[14]以及北京市气象局研发的区域环境气象数值预报系统(Beijing Regional Environmental Meteorology Pre-diction System,简称BREMPS)[15]等.这些模式通常依赖大量的计算,很多参数都是根据经验估计的,很多条件也是假定为理想状态,因此存在一定的局限性和不确定性.此外,由于这些模式对空气质量数据和气象数据的要求较高,相关数据往往很难获取,所以数值模式方法在国内大多城市并不成熟[16].
统计学预报法是利用统计学方法建立模型开展天气预报,常用的方法有多元线性回归、随机森林、贝叶斯、支持向量机(Support Vector Machine,简称SVM)、神经网络等.基于这些算法建立的模型通常使用遗传算法、粒子群算法和蚁群算法等优化算法获取最优参数.已有大量学者利用空气质量数据、气象观测数据和数值模式预报数据,应用一种或多种统计学方法建立预测模型,对PM2.5浓度和其他污染物浓度进行预报[17-23].刘杰等提出应用SVM和模糊粒化时间序列相结合预测PM2.5的方法;李龙等选择综合气象指数、二氧化硫浓度、一氧化硫浓度、二氧化氮浓度和PM10浓度构成特征向量,利用特征向量和PM2.5浓度数据应用最小二乘支持向量机(Least Squares Support Vector Machine,简称LS-SVM)预测模型;戴李杰等联合应用支持向量机(SVM)和粒子群优化(Particle Swarm Optimization,简称PSO)算法建立滚动预报模型,对PM2.5未来24小时浓度进行预报,同时对未来一天的昼、夜均值及日均值浓度进行预报;张恒德等将时间学列和卡尔曼滤波结合起来用在雾霾预报技术中.然而,除了气象条件,污染物浓度还受排放量、交通条件、人口密度等因素的共同影响,使用单一统计方法很难建立准确度高的预报模型.
深度学习是人工智能领域中一种新颖的机器学习方法,可以对大量输入数据的特征表示进行有效学习,为气象时间序列的预测提供了新的研究思路和方法.深度学习的主要神经网络模型主要有卷积神经网络(Convolutional Neural Networks,CNN)、递归神经网络(Recurrent Neural Network,RNN)、长短时记忆(Long Short Term Memory,LSTM)、对抗神经网络等,已有一些学者利用这些模型开展气象预测的研究.Vidushi Chaudhary 等提出了一个多层的LSTM模型预测未来空气污染物的浓度[24];ZHAO等构建了LSTM-FC预测模型,使用历史空气质量数据、气象数据和天气预报数据预测未来48小时的PM2.5浓度[25].此外,还有一些学者将LSTM模型与特征空间相关性相结合应用于PM2.5浓度预报,如:Congcong Wen等提出了一种新的时空卷积长短期记忆神经网络,将当前站和近邻站点PM2.5浓度数据经过1维卷积运算后输入到模型中[26];SOH等提出LSTM预测模型,使用当前站点和近邻站的PM2.5浓度数据、气象数据和地形数据,其中地形数据用以提取地形对空气质量的影响[27].这些模型各有自的特点和适用场景,但都是根据输入数据对未来某个时间的PM2.5浓度进行预测,而气象预测和服务都需要根据输入的历史序列数据预测未来多个时间的PM2.5浓度.Seq2Seq是一种根据输入序列生成输出序列的模型,输入序列的长度和输出序列的长度可以不同,主要应用于机器翻译和文本生成等应用.已有文献利用Seq2Seq模型应用在语音识别、文本摘要、对话系统、图像标题生成中,但是将Seq2Seq模型应用至PM2.5浓度预测的研究相对甚少.因此,本文选择Seq2Seq进行建模,实现对未来多个时间段的PM2.5浓度预测.
综上所述,基于PM2.5浓度预测的重要性和难度,考虑PM2.5浓度与气象要素的时空相关性,本文将采用Seq2Seq建立PM2.5浓度预测模型,以历史的空气质量观测数据、气象观测数据和PM2.5浓度数据作为输入,先进行卷积操作提取出空间特征,再将结果输入Seq2Seq模型,进而得到最终的预测结果.
2 数据分析
2.1 北京地区雾霾天气的季节变化趋势
为了研究北京地区雾霾天气的季节变化特征,收集了北京地区2008年-2018年所有国家级气象站的观测数据,计算每个站逐年雾霾天气出现的总次数,统计每个季节所有站的季平均雾霾天气出现次数,结果如图1所示.可以看出,近10年在北京地区雾霾天气出现的平均次数从春节到冬季呈现先下降后上升的趋势,冬季发生雾霾天气次数最高,夏季最低.从2008年到2014年,冬季出现雾霾天气现象的次数逐年递增,2014年之后则逐年下降,从侧面反映了近几年空气污染治理取得了良好效果.春季和秋季出现雾霾天气的次数比较接近,逐年变化也不大.
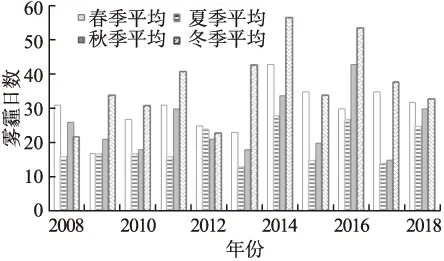
图1 20个国家级气象站逐年霾日数的季节变化趋势
2.2 不同季节PM2.5浓度日内逐小时变化特征
对所有气象站的PM2.5浓度数据按春、夏、秋、冬季分类,然后在每个季节内再按照观测时间0到23点进行分类排序,计算所有站点各季节0点到23点逐小时PM2.5浓度均值,结果如图2所示.可以看出,春季和冬季,PM2.5浓度从凌晨到半夜呈现先下降再上升趋势,波峰集中出现在0点和23点,波谷出现在上午9时左右.冬季PM2.5浓度均值在各时间段都保持在65μg/m3,最高突破90μg/m3,春季PM2.5浓度均值在各时间起伏较大,傍晚最低值不到60μg/m3,而0点峰值达到86μg/m3.夏秋两季,PM2.5浓度随时间的变化均不大,夏季峰值出现在上午9时左右,秋季峰值出现在0点和22点,浓度先下降,在上午8时左右达到一个峰值,随后下降傍晚最低,再呈现上升趋势到22时到达最大.

图2 不同季节的PM2.5浓度日内逐小时变化趋势
2.3 PM2.5浓度的相关性分析
对所有气象站选出与之最临近的12个站点,按距离由近及远排序,逐一计算每个站点和最临近12个站点之间的PM2.5浓度相关性,结果如图3(a)所示,其中,横坐标为最临近的12个站点,纵坐标为PM2.5浓度相关性.可以看出,所有站点的PM2.5浓度相关性随距离增加呈下降趋势,大部分的站点与最临近6个站点的PM2.5浓度相关性大于0.5,也有的站点与距离最近站点的PM2.5浓度相关性小于0.5.计算站点PM2.5浓度与不同气象要素的相关性,结果如图3(b)所示.可以看出,温度、最高温度、平均相对湿度、能见度与PM2.5浓度呈现正相关;2米风、10米风、极大风速、小时降水量与PM2.5浓度呈负相关;PM10的浓度与PM2.5浓度相关性较强,而O3,SO2浓度与PM2.5浓度几乎不相关.

图3 PM2.5浓度相关性分析
从以上的数据分析可以看出,北京雾霾天气多发生在冬季和春季,PM2.5浓度小时峰值最容易出现在这两个季节的凌晨和上午时间段.由于观测站点分布的不均匀,PM2.5浓度不仅与站点之间距离存在相关性,还与不同气象要素之间存在相关性,因此在建立预测模型时候必须充分考虑PM2.5浓度的时间相关性和空间相关性.
3 PM2.5预测模型
3.1 问题的描述
3.2 PM2.5浓度预测模型
Seq2Seq属于encoder-decoder结构的一种,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder,实现从一个序列到另外一个序列的转换.encoder负责将输入序列压缩成指定长度的向量,这个过程称为编码,decoder负责将encoder生成的固定向量再转化成输出序列,这个过程称为解码.
PM2.5浓度预测模型包含获取空间特征的CNN与Seq2Seq模型,使用的数据包括北京市气象局10个观测站逐小时的空气污染物浓度观测资料、逐小时气象要素观测资料和北京地区网格化三维气象要素客观分析资料.本文选择常用于序列模型的一维卷积来获取与站点高度相关的短期空间特征.以站点为中心,从整个三维气象要素客观分析网格中取出10*10的子网格作为输入,使用一维CNN分别获取温度、相对湿度、风要素的空间特征.Seq2Seq模型包含两个RNN,一个RNN作为encoder,另一个RNN作为decoder.站点在某个时刻的观测数据、最临近6个站的PM2.5浓度数据经过预处理后与该站在这个时刻的空间特征作为当前时刻的特征向量输入到Encoder结构,经过运算得到输出和隐含状态;Encoder的输出和隐含状态与站点的目标预测值作为当前时刻的Decoder的输入,经过RNN运算得到预测结果.整个模型的结构如图4所示.
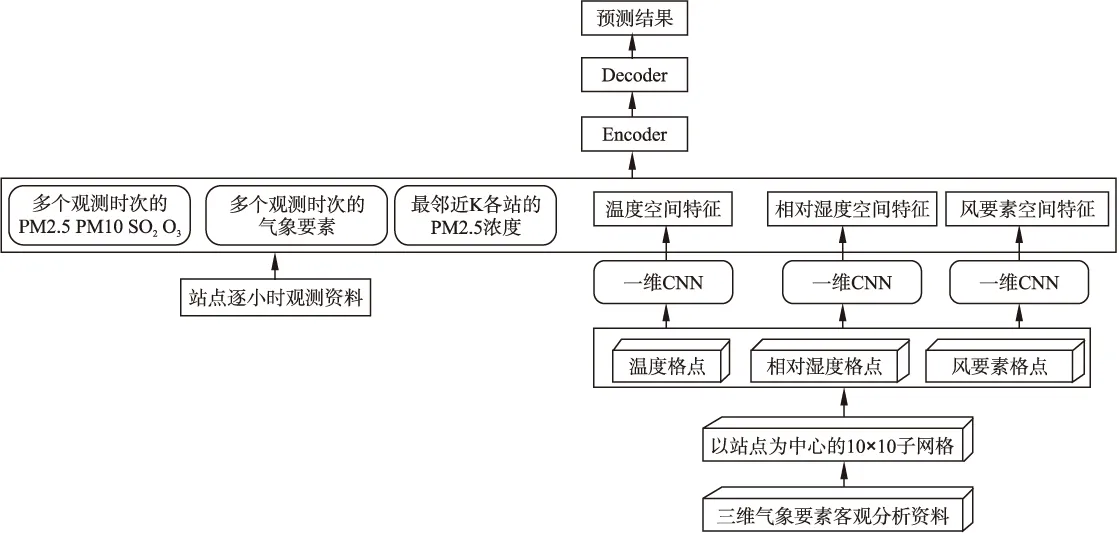
图4 PM2.5浓度预测模型架构
Chung等的研究成果指出,门控循环单元(Gated Recurrent Neural,简称GRU)在较小的数据集上比LSTM表现更突出,能更好解决RNN在长序列训练中爆炸或消失梯度的问题[28],因此,本文选择GRU作为Seq2Seq模型的RNN.另外,根据Geman等的研究,改变隐藏节点的数量可能会减少过度拟合和增加模型泛化.一个可能的经验法则是采取隐藏节点的数量为输入层和输出层维度总和的2/3[29,30].按照这个法则,如果使用过去72小时数据预测未来24小时PM2.5浓度,隐藏节点数量应该设置为(72+24)*2/3=64,这个值也是大量文献和研究中推荐使用的.与单层GRU相比,堆叠GRU可以增加模型的学习能力,但是网络参数也会随之增加,这对模型泛化能力和训练时间都有直接影响.考虑到样本数总量,本文使用2层GRU结构,每层有64个隐含节点.此外,为了防止过拟合,在Decoder结构中使用比例为0.15的Dropout.
模型优化算法选用Adam算法.为了评估模型的性能,使用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和和平均绝对百分比错误(MAPE)作为评价指标.RMSE和MAE用于评估绝对误差,而MAPE用于测量相对误差.RMSE和MAE反映了预测的极值效应和误差范围值,MAPE反映了平均值的特异性预测值.
3.3 模型算法流程
PM2.5预测模型算法的具体步骤如下:
1)提取站点的空间特征.以站点为中心,将原始的气象要素客观分析资料处理为10×10的子网格,按温度、相对湿度、风要素网格分别存储.使用一维卷积操作这些子网格作提取不同要素的空间特征,作为站点在该观测时刻的空间特征.
2)对站点的空气污染物浓度和气象要素观测数据进行预处理.首先,计算每类数据的均值和方差,将均值在缩小而偏差在增大的数据从样本集中剔除.其次,缺测值使用均值替代,再进行归一化处理.最后,将它们与同一观测时刻的空间特征进行组合,作为站点在该观测时刻的特征向量.
3)数据融合与格式化,设置滑动时间窗口,生成用于训练和测试模型的时间序列数据,完成原始数据到张量的转变.
4)训练CNN-Seq2Seq模型,得到最优超参数和训练步长.
5)依据RMSE、MAE和MAPE指标评估Seq2Seq模型的预测效果.
4 实验及分析
4.1 实验环境及数据
本文使用的实验数据来源于北京市气象局,分为3类,如表1所示.
表1 输入LSTM模型的站点特征向量
Table 1 Input feature vectors of LSTM

字段名称描述ID站号PM2.5PM2.5浓度PM10PM10浓度vis能见度tem平均气温tem_max最高气温tem_min最低气温win_2m2米风速win_10m10米风速win_max极大风速pre小时降水rh相对湿度rh_max最大相对湿度prs平均气压
1)10个站点的逐小时观测资料,包括PM2.5 浓度、 PM10浓度、能见度和气象要素,数据每小时更新一次,具体见表1;
2)北京地区的网格化三维气象要素客观分析资料,空间分辨率为1公里,每小时更新一次;主要包括温度、风和相对湿度要素;
3)与每个站点最临近K个站点的PM2.5浓度数据,每小时更新一次.
原始数据经过预处理后生成序列数据集,其中每个时间序列数据由45个特征向量组成,每个样本则包含96个时间序列(输入72,输出24)数据,批量训练一次输入64个样本.数据集的时间跨度为2016年-2018年,其中80%的数据用来训练模型,20%的数据用来验证模型,测试集的时间跨度为2018年10月-12月.
4.2 Seq2Seq模型关键参数调优
在参考大量文献的基础上,本文中对模型中的部分关键参数做出了合理的设定:隐藏层为2层,每层隐藏神经元个数为64,学习率为10-3,衰减率为0.995,参数初始化范围设置为[-0.08,0.08],模型优化算法选用Adam算法.过大的训练步长会引起模型对训练数据过度拟合,也会消耗更多的时间,而过小的步长容易引起局部最优,因此,训练步长参数需要通过测试找到最优值.图5显示了训练集和验证集数据的MAPE随训练步长的变化.训练集和验证集上,MAPE误差都随迭代次数增加逐步减少.迭代次数超过3000左右时,该模型似乎过度适应,不仅泛化能力没有改善,而且还出现微弱波动.因此,设置迭代步长为3000.
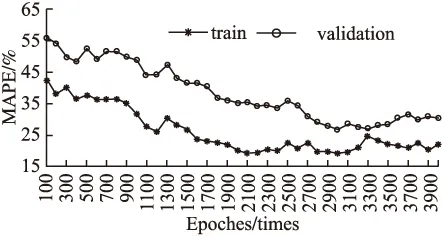
图5 MAPE随步长变化趋势
4.3 实验中使用的几种模型
为了方便模型之间的对比,除了CNN-Seq2Seq,本文还设计了以下几种模型:基于机器学习的SVR模型、Just-Seq2Seq模型和Local-Seq2Seq模型.SVR广泛用于分类或者回归目的,在小样本、非线性、高维模式识别等问题的解决上表现出许多特有优势,具有较好的泛化能.本文使用的SVR模型参考文献[31]调整参数,以获得最佳性能.Just-Seq2Seq和Local-Seq2Seq结构与CNN-Seq2Seq的Seq2Seq部分完全相同,使用同样的超参数,输入序列长度也都相同,只是序列数据中包含的特征向量不同.Just-Seq2Seq模型的输入仅包含用于生成时间特征的特征向量,而local-Seq2Seq模型的输入仅包含站点自身的观测数据,和最临近K个站的数据,这里K取值为6.
4.4 实验结果与分析
4.4.1 几种模型预测的误差分析
基于验证集,选择RMSE、MAE和MAPE对SVR、Just-Seq2Seq、local-Seq2Seq和CNN-Seq2Seq这4个模型的预测结果进行评价.表2列出了4个模型对10个站点预测得到的整体精度.可以看出,尽管三个深度学习模型各项指标较接近,CNN-Seq2Seq模型预测效果仍最佳,在两个指标中均优于所有其他模型.相比仅使用本站观测数据的Local-Seq2Seq模型,对于PM2.5浓度,CNN-Seq2Seq对MAPE和RMSE的改进分别至少提高15.38%和26.48%.图6(a)~图6(b)显示了四个模型在10个站上的RMSE和MAE误差分布情况.CNN-Seq2Seq在十个站上的RMSE在[15,24]范围区间,MAE在[11,16]范围区间;Just-Seq2Seq在十个站上的RMSE在[20,38]区间,MAE在[11,25]范围区间,仅有1个站的RMSE小于25;而Local-Seq2Seq模型的RMSE和MAE分布与Just-Seq2Seq类似,峰值比Just-Seq2Seq略高;SVR模型的预测误差明显高于其他三个深度学习的模型.参考前人基于深度学习的PM2.5小时浓度预测研究,当RMSE≤25、MAE≤15时,可以认为模型的预测效果较为理想,由此可见,CNN-Seq2Seq模型的预测效果是4个模型中最好的.
表2 不同模型预测结果的误差比较
Table 2 Error comparison among different prediction models
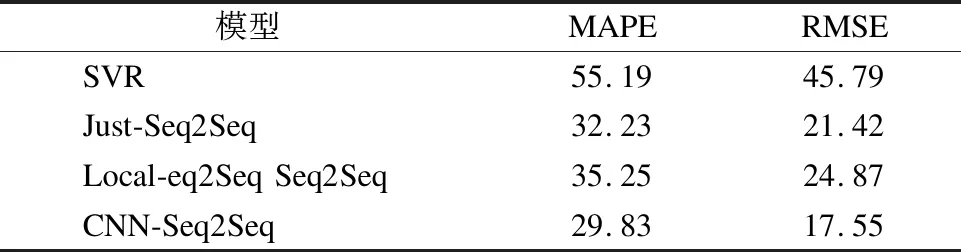
模型MAPERMSESVR55.1945.79Just-Seq2Seq32.2321.42Local-eq2Seq Seq2Seq35.2524.87CNN-Seq2Seq29.8317.55
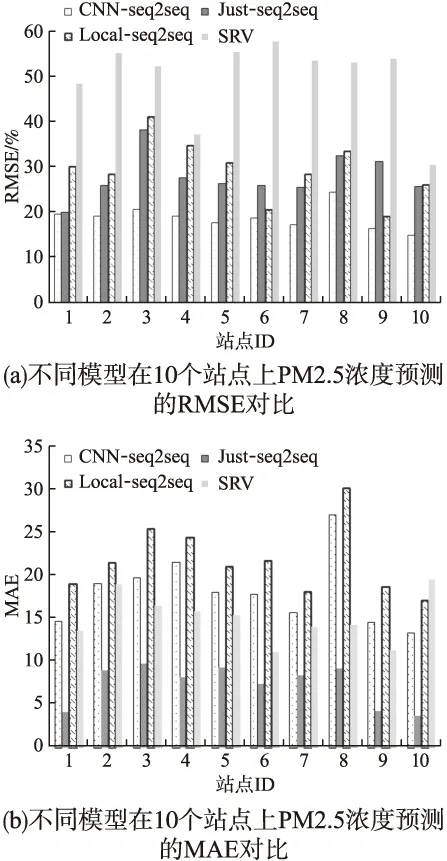
图6 不同模型在10个站点上的PM2.5浓度预测误差对比
4.4.2 不同深度学习模型的预测结果比较分析
从SVR、Just-Seq2Seq、local-Seq2Seq和CNN-Seq2Seq4个模型在验证数据集上的预测的误差分布可看出,三个深度学习模型的误差均比SVR模型小,因此,在测试集上,仅对三个深度模型的预测准确性进行对比.选择2018年11月30日-12月3日雾霾天气过程为例,CNN-Seq2Seq模型、Just-Seq2Seq和Local-Seq2Seq模型下的ID为10的站点PM2.5逐小时浓度预测曲线随时间的变化如图7所示.由图7可知,三种模型的预测曲线与实际观测曲线的趋势都基本保持一致.CNN-Seq2Seq模型的预测曲线与实际观测曲线最为接近,尤其是在浓度波峰附近,表明该模型能较好的对PM2.5小时浓度峰值进行预测,这对PM2.5浓度的短时预测有着十分积极的作用.Just-Seq2Seq模型的预报曲线在PM2.5浓度波谷部分拟合有波动,对未来48小时后PM2.5浓度的预测偏离较大,预测效果不理想.local-Seq2Seq模型的预报曲线起伏最大,对PM2.5浓度峰值的预测值比实际观测值偏大较多,和实际观测曲线偏离较大.相比之下,CNN-Seq2Seq模型预测效果最好.
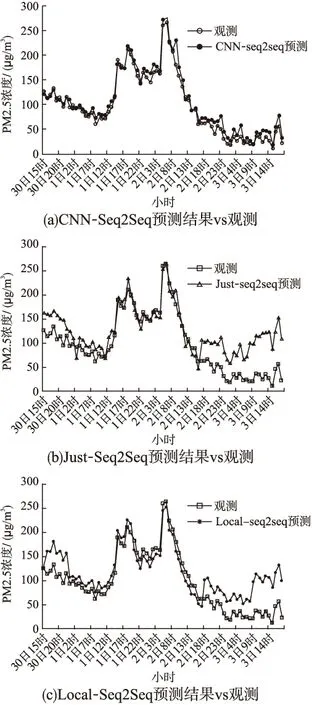
图7 不同模型预测逐小时PM2.5浓度的误差对比
由此可见,对于PM2.5未来24小时内的逐时浓度预测而言,考虑时空特征模型的准确度最高,包含周边邻近站点数据的时间序列模型的准确度高于仅考虑站点自身的时序模型,这说明空间相关性对PM2.5浓度预测很重要.
5 结束语
本文在分析北京地区PM2.5浓度随季节变化规律、逐日变化趋势以及气象要素与PM2.5浓度相关性基础上,提出了一种使用深度学习模型进行预测的方法,利用PM2.5观测实况数据和多种气象实况资料,建立CNN-Seq2Seq预测模型对PM2.5未来24小时的逐时浓度进行预测.通过几个模型预测结果和误差的对比表明,CNN-Seq2Seq预测模型能有效的获取时空特征,适合解决时空序列数据的短时预测问题.在后续的研究中,将接入气象数值模式预报产品和气象格点预报产品,通过多种模型的对比分析,进一步提高模型的效率和精度.
