基于YOLO_v3的车辆和行人检测方法
2020-05-13洪松高定国三排才让
洪松 高定国 三排才让

摘要:在新时代背景下,智慧交通的概念已经出现在人们的生活中。检测车辆和行人已经成为目标检测领域比较热门的应用研究方向。该文将YOLO_v3目标检测算法应用于车辆和行人的检测。针对行人和车辆检测问题,将分类器的输出张量维度设置为21维。实验结果表明,训练出的模型在测试集上的平均检测精度约为89%。其中,车輛的检测精度约为95.64%.行人的检测精度约为82.55%。
关键词:智慧交通;目标检测;车辆;行人
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)08-0192-02
开放科学(资源服务)标识码(OSID):
1 概述
随着城市的发展,城市交通流和人流密度成为城市道路交通拥挤的重要原因。针对这一问题,智慧交通的概念出现在人们的认知中,也因此提出了新时代智慧交通的发展应强化前沿科技应用与研发的观点[1]。在此背景下,车辆和行人检测成为当下的研究热门。近年来计算机视觉领域发展迅猛,基于深度学习的目标检测技术层出不穷。当前的目标检测技术主要分为两大类,一是以Fast R-CNN和Faster R-CNN为代表的基于区域生成的两阶段检测算法;二是以YOLO和SSD为代表的基于回归的单阶段检测算法[2]。两阶段的检测算法通常具有较高的检测精度,但检测速度较慢,而单阶段检测算法在牺牲了一定检测精度的基础上提高了检测速度。
目前YOLO系列检测算法已经在工程中的各个领域中都有广泛的应用。其中,在航空航天领域,钮赛赛[3]等人将YOLO智能网络算法用于红外弱小多目标的检测,将其与传统的模板匹配方法相比,在检测概率和检测精度上YOLO具有明显的优势。在交通领域,周慧娟[4]等人提出了基于改进Tiny YOL02的地铁进站客流人脸检测方法,测试结果表明基于改进的TinyYOL02的人脸检测算法相比于原始的检测算法在召回率和检测速度上都有提升且有较好的泛化性。在农业领域,燕红文[5]等人提出了基于改进Tiny-YOLO模型的群养生猪脸部姿态检测算法,实验表明该模型可以有效地对群养生猪不同类别脸部姿态进行检测。在教育领域,黄伟铠[6]等人设计了一种基于YOLO算法的学生课堂关注度分析系统,该系统能有效检测课堂中学生的行为,为分析学生的课堂关注度提供了一种有利的手段。由此可见,YOLO系列检测算法已经应用于各行各业.并取得了不错的检测效果,具有一定的实际应用价值。
单阶段检测算法YOLO_v3因其良好的检测精度和速度,已经在工程应用中成为主流检测算法。本文在KITTI数据集的基础上,利用YOLO_v3算法对该数据集进行特征训练学习,进一步对网络模型的参数进行调整,最终得到本文的车辆和行人检测模型。
2 YOLO v3算法理论
2.1 特征提取网络Darknet-53
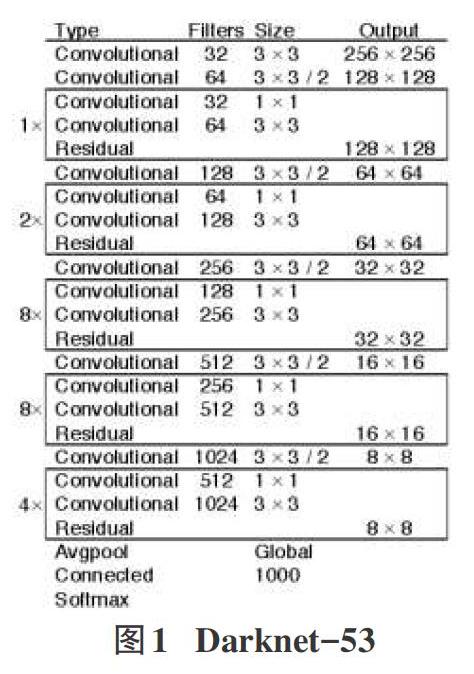
YOLO_v3其主干特征提取网络由连续的3x3和IXI卷积层组合而成,因为一共有53个卷积层,又被称为Darknet_53[7]。YOLO_v3的特征提取网络Darknet-53如图1所示,在整个特征提取网络的结构里没有池化层和全连接层,张量的尺寸变换是通过改变卷积核的步长来实现的,在此结构中不考虑全局平均池化,张量维度的变化一共有5次。
2.2 基于车辆和行人检测的YOLO_v3算法分析
YOLO_v3网络将输入的行人和车辆图片进行预处理,然后将其送入CNN网络,CNN网络将输入的图片分割成SXS的网格,每个单元格被用于检测那些中心点落在该单元格内的目标。每个单元格会预测检测物体边界框的4个偏移坐标和置信度得分。最后YOLO_v3会在三个等级上进行预测,每个等级负责不同规模大小的物体的预测,每种规模预测三个边界框。在本实验数据集中类别为行人和车辆,共两类。所以得到的张量是SxSx[3x(4+1+2)],其中包含4个边界框的坐标、1个目标预测以及两种分类预测。
3 基于YOLO_v3的车辆和行人检测实验
3.1 实验数据
本文是在KITTI数据集的基础上训练行人和车辆检测模型,官方提供的数据集中只有训练集图片给出了标签,一共有7481张图片。将这7481张图片按照9:1的比例划分为训练集和测试集。该数据集中共有八个类别,分别是Car、Van、Truck、Tram、Pedestrian等,将这八个类合并为Car、Pedestrian这两个大类。最后通过格式转换脚本程序将KITTI数据集格式转化为YOLO网络所需要的标签格式。
3.2 实验平台
本实验平台的配置为:显卡为2080Ti,显存IIG,CPU为In-ter Core i7 9700,内存64G,操作系统为ubuntu18.04,CUDA版本为10.1,CUDNN版本为7.6.3。
3.3 实验参数设定
本实验初始学习率设置为0.001,权重衰减设置为0.0005,最大迭代次数设置为50000次,动量参数设置为0.9。在模型训练过程中,按照设定的训练节点调整学习率的大小,减少模型训练过程中的损失,该训练节点分别为最大迭代次数的80%和90%[8]。本实验数据集中的大部分车辆和行人在图片中所占比例较小,较难分辨,为了提高检测精度,将送入网络的图片分辨率设置为608x608。同时为了提高模型的鲁棒性,在训练过程中随机使用不同尺寸的图片进行训练。
4 实验分析
4.1 实验过程及分析
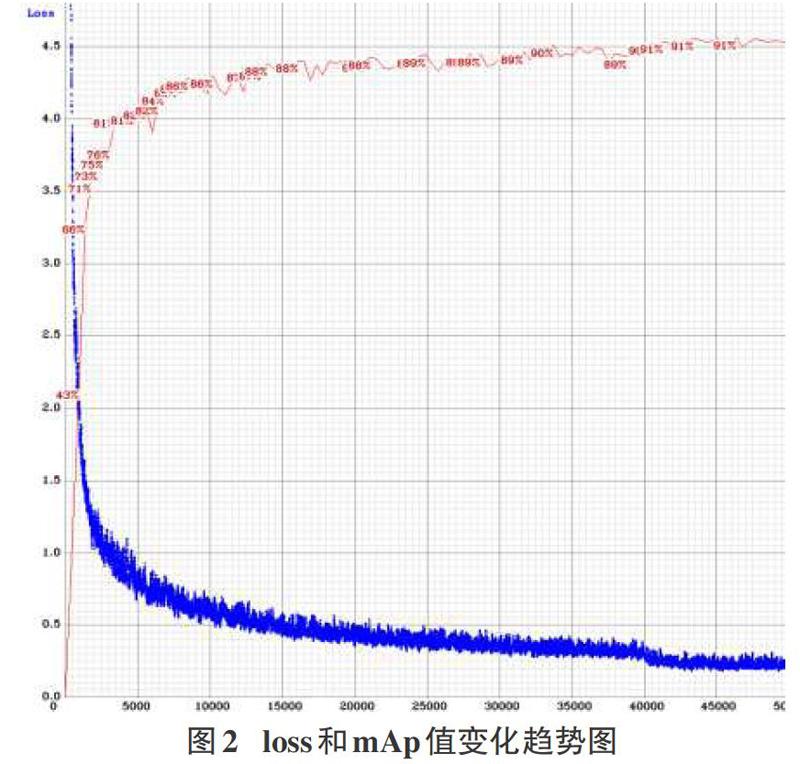
实验过程中的loss和mAp值的变化趋势如图2所示,在前5000次迭代中loss急剧下降,mAp值逐步上升。随着迭代次数的增加loss和mAp的变化趋于平缓,mAp的值在89%至91%范围内波动。在40000次迭代训练后loss值趋于稳定不再下降,当迭代训练结束时,loss的值约为0.22左右。
4.2 实验评价指标
本实验采用目标检测领域公认的平均检测精度mAP以及Precision、Recall、Fl值来衡量模型的性能。Precision、Recall、F1值、AP及mAP定義如式(1)一(5)所示。
其中TP表示正确检测到是行人或车辆;FP表示误检测为是行人或车辆;FN表示漏检测行人或车辆;P,R分别表示精确率与召回率;C表示数据集中的类别总数,本实验取2,C.表示当前第i个类别,i的取值为0和1。
4.3 实验结果
实验结果表明,训练出的模型在748张图片的测试集上的平均检测精度约为89%。其中,车辆的检测精度约为95.64%,行人的检测精度约为82.55%。详细的实验结果如表1到3所示,在测试集上的部分检测效果如图3和4所示。
5 结束语
本文阐述了基于YOLO_v3的车辆和行人检测方法,包括修改分类器维度、模型训练及网络参数调整。实验结果表明基于YOLO_v3的车辆和行人检测方法取得了不错的检测效果,具有一定的实用价值。但是基于YOLO_v3的车辆和行人检测方法对于弱小车辆和行人目标检测效果不好,下一步可针对特定场景下的弱小车辆和行人目标进行网络改进以进一步提升网络检测精度。
参考文献:
[1]伍朝辉,武晓博,王亮.交通强国背景下智慧交通发展趋势展望[Jl.交通运输研究,2019,47(4):26-36.
[2]周晓彦,王珂,李凌燕.基于深度学习的目标检测算法综述[J].电子测量技术,2017,40(11):89-93.
[3]钮赛赛,周华伟,朱婧文,等.基于YOLO智能网络的红外弱小 多目标检测技术[Jl.上海航天,2019,36(5):28-34.
[4]周慧娟,张强,刘羽,等.基于YOLO:的地铁进站客流人脸检测方法[J].计算机与现代化,2019(10):76-82.
[5]燕红文,刘振宇,崔清亮,等,基于改进Tiny-YOLO模型的群养生猪脸部姿态检测[Jl.农业工程学报,2019,35(18):169-179.
[6]黄伟铠,张登辉.基于YOLO算法的学生课堂关注度分析系统[J].浙江树人大学学报:自然科学版,2019,19(3):1-4,17.
[7]
Redmonj, Farhadi A.YOL09000: better, faster, stronger[C]//2017lEEE Conference on Computer Vision and Pattem Recognition(CVPR),July 21-26, 2017. Honolulu, Hl. lEEE, 2017.
[8]游忍,周春燕,刘明华,等.基于TINY-YOLO的嵌入式人脸检测系统设计[Jl.工业控制计算机,2019,32(3):47-48.
【通联编辑:梁书】
收稿日期:2019-12-21
作者简介:洪松(1994-),男,硕士生,主要研究图像处理;高定国(1972-),藏族,硕士,教授,主要研究藏文信息处理、算法设计;三排才让(1994-),男,藏族,硕士生,主要研究藏文信息处理。