基于马尔科夫链的起源过滤效用评估模型
2020-05-13孙连山徐艳艳张永斌
孙连山, 徐艳艳, 张永斌, 侯 涛
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
0 引言
大数据时代,海量数据在网络上产生和传输,被不同组织存储、转化和利用.数据的可信性对相关组织制定各种业务决策至关重要.数据起源(Data Provenance)记录数据从产生到消亡的整个生命周期内涉及的数据实体、处理过程以及相关的人员和组织[1,2],通常呈现为由实体、活动、代理节点以及它们之间的依赖关系组成的有向无环图[3-5],称为起源图(Provenance Graph).数据的使用者可以根据起源图,追溯数据产生的历史信息,满足数据鉴真、错误数据归因和追责,关键数据重建等不同类型的数据溯源需求.
起源图记录数据的演变历史,往往可能含有敏感信息,如用户的身份、住址、金融、偏好以及病史等.为保证信息安全,在发布或者共享起源图之前,往往需隐藏其中的敏感信息[6].起源过滤是通过隐藏或改变起源图中的部分信息,得到安全或简化的起源过滤视图的新型技术[7-10].理想情况下,过滤视图也应满足原始起源图所满足的所有溯源需求,但由于过滤技术隐藏、抽象或改变了原始起源图中的部分信息,导致过滤视图通常无法完全满足所有的溯源需求.本文采用“溯源效用”刻画过滤视图满足溯源需求的程度.应用不同过滤技术得到的过滤视图通常具有不同的溯源效用.选择或设计适当的过滤技术,生成具有给定溯源效用的过滤视图,是起源过滤研究面临的关键现实挑战之一.
Blaustein等[11]和Nagy等[12]使用保留节点和边在原始起源图中的占比来度量过滤视图的溯源效用.所谓保留节点和保留边就是原始起源图和过滤视图的公共节点和边.该方法并未考虑路径对溯源效用的影响,实际上路径中包含节点和边的所有信息,并且可以通过路径来对某个节点溯源,因此路径是计算过滤视图的溯源效用的关键.
王艺星等[13]发现过滤视图的部分溯源路径中可能含有不确定边,指出溯源效用不但与保留节点和边的占比相关,还与过滤视图中的溯源路径与原始起源图中的溯源路径的差异相关.但王艺星等仅采用不确定边的数量以及不确定边所替代的原始起源图中路径的长度来衡量这种差异,并没有科学地体现溯源路径的结构对证实作用的影响.例如,学生C从班长A处得知“明天不上课”的消息,班长A声称其从老师T处得到该消息,则学生C通常可以确信该消息为真;而假若学生C从学生B处得到该消息,即使学生B声称该消息来源于老师T,学生C仍可能认为该消息存疑.
总之,溯源效用的内涵较为模糊,难以准确评估,而且现有研究对溯源效用尚无一致定义,效用评估结果不可靠,不能作为研究和选用过滤技术的依据.具体来讲,现有效用评估模型存在两方面的不足.第一,现有效用评估模型针对一个过滤视图仅给出一个溯源效用评估结果,无法体现同一过滤视图满足不同溯源需求的能力不同的实际情况;第二,现有评估模型并未体现溯源路径的结构对溯源效用的影响,仅通过过滤视图与原始起源图在节点、边和路径上的数量差异评估溯源效用.
为此,本文分析数据溯源的内涵,建立了一个基于马尔科夫链的溯源效用评估模型.一方面,该模型针对具体溯源需求评估过滤视图的溯源效用,评估粒度更细,评估结果更可靠;另一方面,该模型结合起源图的溯源路径结构,评估结果更符合起源图的客观实际.
1 数据溯源及溯源效用
结合实例介绍数据起源的概念,分析数据溯源的内涵,形式地定义溯源结果和溯源效用.
1.1 数据起源
数据起源(Data Provenance)记录数据的演变历史,通常呈现为如图1所示的有向无环图,称为起源图(Provenance Graph).起源图通常服从一定的语法有效性约束,如连通性、无环[8]、无假依赖[9]等.

图1 部分邮件转发起源图
图1记录了用户user_C所接收到的一封电子邮件email_B的部分起源信息.起源图中矩形表示数据产生的处理过程,如转发过程send1、send2、增加内容过程addContent;椭圆形表示数据实体,如邮件email_A、email_A′和email_B;五边形表示影响数据产生过程的相关人员和组织,如用户user_A、user_B和user_C.
起源图中有向边表示起点在一定程度上直接依赖于终点,即终点是起点产生的部分原因.例如,图1中边
为论述方便,形式地定义起源图如下:
定义1 起源图G=(V,E,P)
节点集V={v1,v2,…,vn}表示图G有n个节点;边E={ei|ei=
1.2 数据溯源
数据溯源是起源图的基本用途.数据溯源是根据已知起源图,对可能影响特定数据节点当前状态的历史信息进行追溯分析的过程.本文将相关起源受关注的特定数据节点称为溯源起点.数据溯源往往从溯源起点出发,沿着起源依赖关系,查找可能影响溯源起点状态的所有历史节点,并分析每个历史节点对溯源起点产生的作用或贡献.
溯源起点由溯源需求确定.溯源需求通常是用户对溯源起点的性质或状态的查询.如判断节点v是否可信,则节点v就是溯源起点.在起源图G中由溯源起点v出发,可以溯源得到v的所有历史节点.如图1中溯源起点email_A的历史节点包括send1和user_A.
溯源结果是历史节点对溯源起点的影响.历史节点对溯源起点的影响与二者之间的连通路径有关.一般地,历史节点与溯源起点之间的连通路径越长,表示历史节点的时间戳与溯源起点的时间戳的差越大,该节点对溯源起点的影响力通常越小.总之,溯源所得的各历史节点对溯源起点的影响力不同,与到溯源起点连通路径的长度相关.
定义2 溯源结果ΔG(v)
G为起源图,v为溯源起点,则ΔG(v)为G中以v为起点进行溯源得到的结果,如式 (1) 所示:
ΔG(v)={ti=KG,v(vi) |vi∈HG(v),i=1,2,…,m}
(1)
式(1)中:HG(v)表示溯源所得到的历史节点集,KG,v(vi)表示HG(v)中每个历史节点vi影响溯源起点v的因果信度,KG,v表示在图G中以v为起点溯源得到的因果信度分布.显然,若能科学地评估因果信度分布KG,v,就能利用衡量不同分布相似度的工具,更准确地评估过滤视图的溯源效用.
1.3 溯源效用
通常假设原始起源图能完全满足用户的溯源需求,即溯源效用最大.而过滤视图是采用不同过滤技术改造原始起源图后的结果,相对于原始起源图有不同程度的信息损失.如匿名技术[12]将敏感节点的信息置空;抽象技术[9]用一个抽象节点替换一组敏感节点;删除+修复技术[13]在删除敏感节点以及与其相关联的所有边的基础上增加不确定边,修复被破坏的非敏感的边或路径.在原始起源图和过滤视图中,根据同一起点溯源得到的两个不同溯源结果之间的相似度越大,说明过滤视图满足用户溯源需求的程度越大,相反则越小.
为定量衡量过滤视图满足用户溯源需求的程度,从而评价不同过滤技术的优劣,本节提出溯源效用的概念.溯源效用就是过滤视图相对于原始起源图所能满足用户溯源需求的程度,可通过基于过滤视图和原始起源图所得溯源结果的相似度来表征.溯源效用的形式化定义如式 (2) 所示:
定义3 溯源效用U(G,S,v)
U(G,S,v)=f(ΔG(v),ΔS(v))
(2)
式(2)中:ΔG(v),ΔS(v)分别表示起点v在原始起源图G和过滤视图S中的溯源结果,f为衡量这两个溯源结果相似度的度量函数.
由式 (2) 可知,科学评价过滤视图溯源效用的关键在于科学地定义评价函数Δ和f,分别计算溯源结果和不同溯源结果之间的相似度.下文首先采用马尔科夫链[14]描述历史节点对溯源起点的影响方式,将形如式 (1) 的溯源结果表征为一个因果信度分布,科学地定义评价函数Δ.其次计算过滤视图S和原始起源图G的两个溯源因果信度分布之间的相对熵,可用于科学地定义评价函数f.
2 基于马尔科夫链的溯源效用评估模型
首先定义历史节点到溯源起点的连通路径证实溯源起点的置信度,结合实例介绍马尔科夫链的原理,其次定义作为溯源结果的因果信度分布.最后利用相对熵来计算两个因果信度分布之间的相似性,表征过滤视图的溯源效用.
2.1 置信度
不同历史节点到溯源起点的连通路径不同,证实溯源起点的方式也不同.一般地,连通路径越长,历史节点与溯源起点的时间间隔越大,二者之间的关联性就越弱,历史节点证实溯源起点的方式的可信度就越小.因此本文引入置信度刻画不同历史节点间接证实溯源起点的可信度[15,16].
事实上,起源图中的直接依赖关系记录了历史节点对溯源起点的直接影响.如图2中直接依赖关系
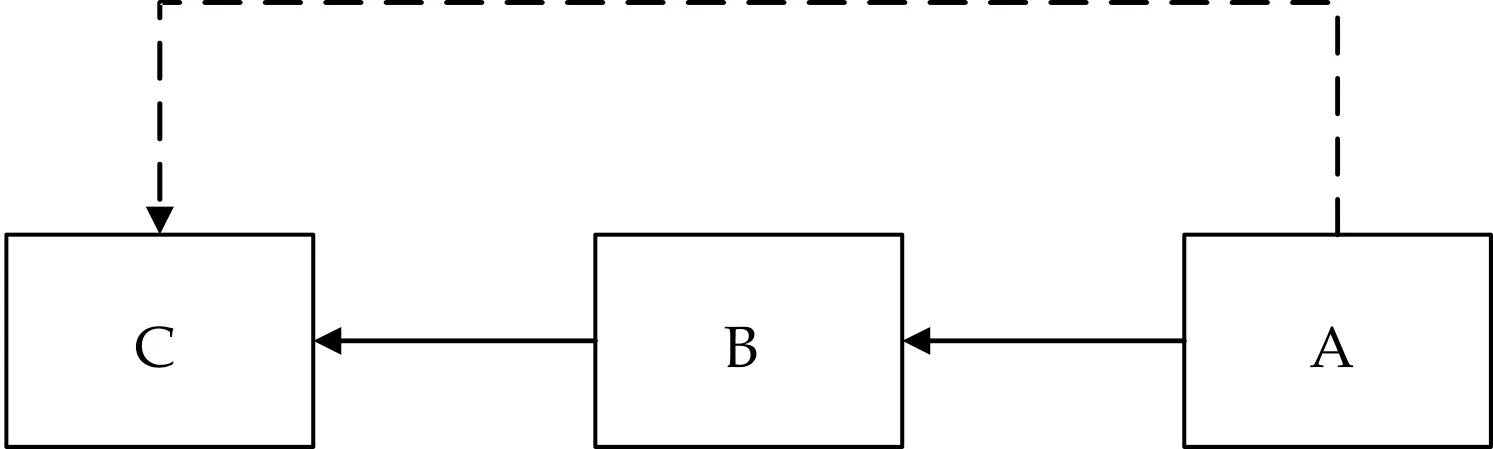
图2 简单溯源图
马尔科夫链[14]是具有马尔科夫性质的随机变量X1、X2、X3…的一个数列,描述了一种状态序列,其每个状态值取决于前面有限个状态.而且T+1时刻的状态只与T时刻的状态有关,与T时刻以前的状态无关.在起源图中同样具有这一特性,如图2中溯源起点A仅与节点B直接相关,而节点B也仅与节点C直接相关,通过状态逐层传递的影响关系,C对A的影响可以认为是通过C对B的影响及B对A的影响间接实现的,因此本节采用马尔科夫链建模各历史节点影响溯源起点的方式.
事实上,起源图的产生方式多种多样,其中的依赖关系并不完全可信[18].一方面,原始起源图中的直接依赖关系所表征的历史节点与溯源起点之间的因果关系并不完全可信.根据直接依赖关系追溯得到的历史节点很可能并不是溯源起点呈现为其当前状态的真正原因.为此,本文引入参数α(0<α<1)表征直接依赖关系所蕴含因果关系的可信度.另一方面,过滤视图中往往包含原始起源图中并不存在的直接依赖关系,例如端节点为匿名或抽象节点的直接依赖关系.显然,这种直接依赖关系所表征的历史节点与溯源起点之间的因果关系也不完全可信.通常,这些直接依赖关系所蕴含因果关系的可信度低于原始起源图中直接依赖关系所蕴含因果关系的可信度,因此,在本文引入参数β(0<β<α)来表征.
起源图G中,不同历史节点vi通过路径证实溯源起点v的置信度不同,节点v的所有历史节点通过路径影响v的置信度,构成节点v的置信度向量.本文将节点v的置信度向量形式化定义如式 (3) 所示:
(3)
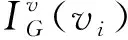
如图3所示,溯源起点为email_B且email_A为匿名节点时,历史节点user_A到email_B的路径中共有2条保留直接依赖关系
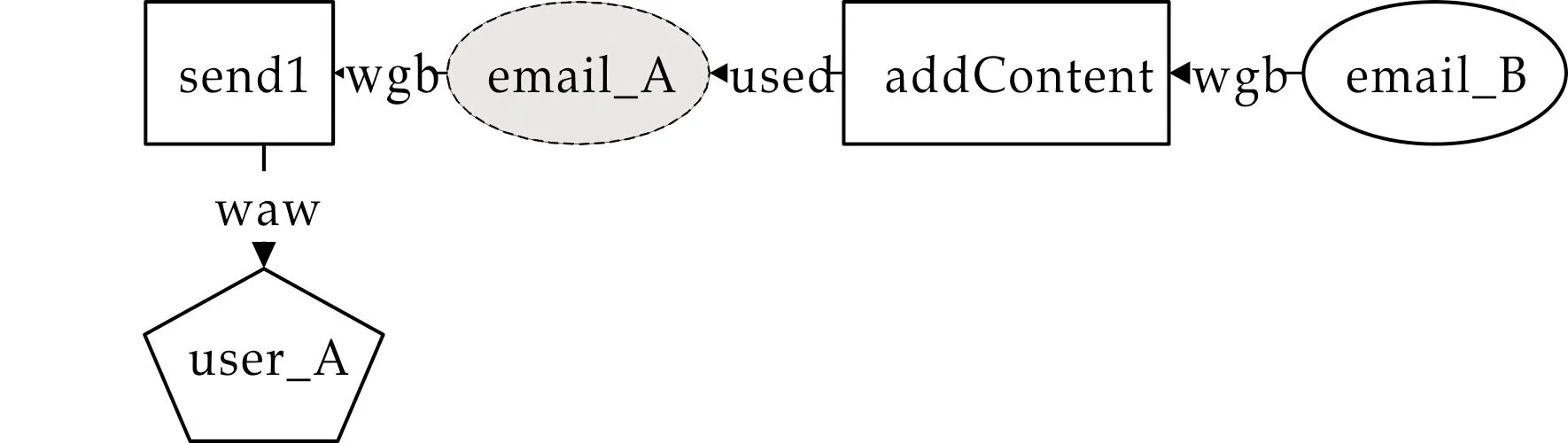
图3 单路径起源图
当历史节点与溯源起点之间存在多条路径时,表明该节点对溯源起点的影响方式多样.这时,该节点证实溯源起点的置信度应为该节点通过不同路径证实溯源起点的最大置信度,与路径的数量无关.
如图4所示,溯源起点为email_B时,其历史节点user_A到email_B有两条不同的路径,对应两个不同的置信度值α2和α4,则历史节点user_A对溯源起点email_B的置信度为最大值α2.
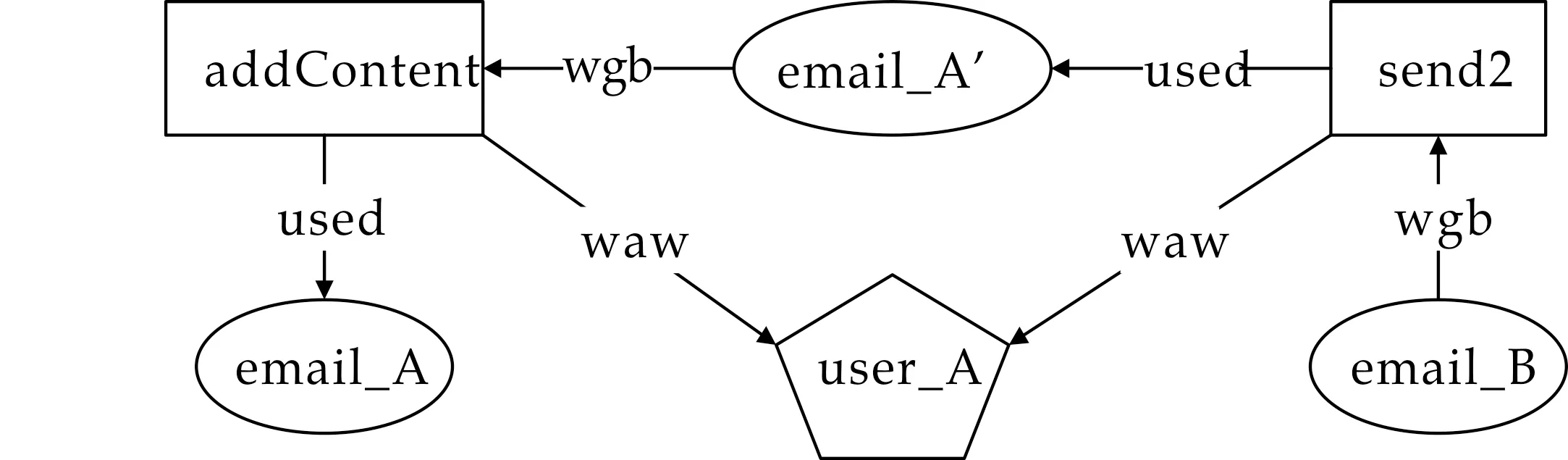
图4 多路径起源图
2.2 因果信度
将某个历史节点对证实溯源起点的贡献归一化可得到所谓的因果信度.溯源历史集中所有节点的因果信度组成因果信度分布,表征溯源结果.
定义5 因果信度分布KG,v
起源图G中节点v的所有历史节点对证实节点v的贡献作用,构成因果信度分布KG,v.本文将节点v的因果信度分布形式化定义如式(4)所示:
i=1,2,…,m
(4)
式(4)中:vi表示图G中以v为溯源起点,溯源得到的历史节点集HG(v)中的任一元素,KG,v(vi)表示历史节点vi对溯源起点v的因果信度.
2.3 溯源效用评估
根据式 (1)和(4),溯源结果最终呈现为一个因果信度分布.显然,根据相同的溯源起点v,在原始起源图和过滤视图中将得到不同的因果信度分布KG,v(vi)和KS,v(vi).则过滤视图溯源效用的评估问题就转化为评估不同因果信度分布之间相似度的问题.
相对熵也称为KL散度,是度量两个概率分布相似度的常用工具[19].相对熵越小,表示两个概率分布之间越相似;反之,相差越大,当两个分布完全相同时,相对熵为零.
用式(5)计算两个因果信度分布KG,v和KS,v之间的相对熵.
(5)
式(5)中:vi∈HG(v),i=1,2,…,m.
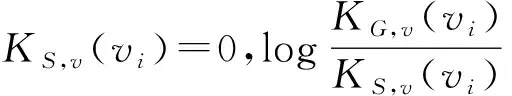
(6)
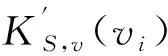
3 溯源效用评估算法
输入:G,S,v,α,β,ε
输出:U(G,S,v)
1:Evaluate(G,S,v,α,β,ε)
2:在图G中获取节点v的历史节点集HG(v)
3:for eachvi∈HG(v) do
4:P(v,vi) 为G中v到vi的溯源路径集
6: for eachpi(v,vi)∈P(v,vi) do
7:n为pi(v,vi)中保留直接依赖关系的数量
//式3计算vi对v证实作用的置信度
9: end for
10:end for
11:for eachvi∈HG(v) do
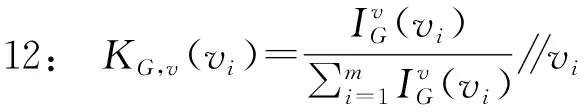
13:end for∥KG,v为G中v的因果信度分布
14:在图S中获取节点v的历史节点集HS(v)
15:for eachvi∈HS(v) do
16:P′(v,vi) 为S中v到vi的溯源路径集
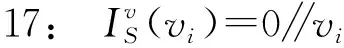
18: for eachpi′(v,vi)∈P′(v,vi) do
19:n′为pi′(v,vi)中保留直接依赖关系的数量
20:p′为pi′(v,vi)中非保留直接依赖关系数量
22: end for
23:end for
24:for eachvi∈HS(v) do
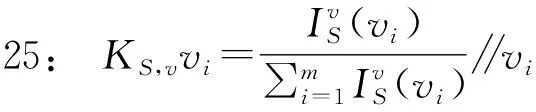
26:end for∥KS,v为过滤视图S中v的因果信度分布
27:for eachvi∈HG(v) do
28: ifvi∈HG(v)-HS(v) then
30: else ifvi∈HG(v)∩HS(v) then
32: end if
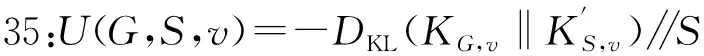
36:end Evaluate(G,S,v,α,β,ε)
上述算法需要遍历历史节点集合,并进一步遍历溯源路径,设在图G中以任意节点v为起点,溯源所得到的历史节点集HG(v)中平均有m个节点,所有溯源路径的平均长度为d,则上述算法的时间复杂度为O(d*m).
4 实验及结果分析
首先给出过滤算法所使用的实验数据、实验环境和参数设置,其次设计实验方案,用本文提出的效用评估模型与现有效用评估模型[11-13]评价四种不同过滤视图的溯源效用,最后对比分析实验结果.
4.1 实验数据、实验环境和参数设置
为验证评估模型的可靠性,本文采用如图5所示的邮件转发起源图和如图6所示的美国印第安纳大学公开发布的工作流起源数据集[20].
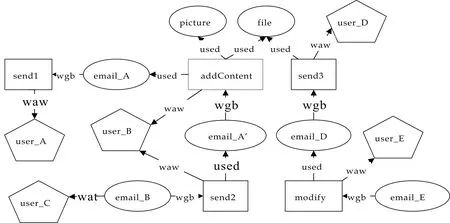
图5 邮件转发起源图G
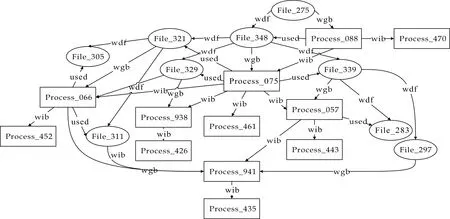
图6 Nam-wrf类型部分起源图
本文实验环境为联想Lenovo G50-70 20351笔记本电脑,Intel(R) Core(TM) i5-4210U CPU,4GB内存,64位操作系统.实验算法在开源图处理工具包JGraphT 基础上,用Java语言在Myeclipse中实现.
实验中参数设置为α=0.9,β=0.7,ε=0.001,其中α表示直接依赖关系所蕴含因果关系的可信度,是表征起源因果关系影响随时间衰减的基本假设,因此取值应为小于1的任意数字.β表示端节点为匿名或抽象节点的直接依赖关系,用以表征不确定依赖关系对起源因果影响的衰减更大,相较于原始起源图中的直接依赖关系,这种直接依赖关系的可信度更低,因此0<β<α,为达到最好的实验对比结果,本文设定参数设置为α=0.9,β=0.7.
4.2 实验方案及结果分析
为对比分析本文提出的效用评估模型与王艺星等提出的高效用评估模型[13]以及Blaustein等提出的效用计算方法[11,12]之间的差异性,本文采用不同的实验数据,设计5个实验观测不同溯源起点、不同类型的过滤视图对溯源效用的影响.各个实验的基本步骤包括:(1)确定原始起源图及过滤需求,并根据溯源需求确定一个或多个溯源起点;(2)采用匿名、删除、删除+修复、抽象等经典技术实现过滤需求,分别得到4类过滤视图S1、S2、S3、S4;(3)根据过滤视图,从一个或多个溯源起点出发进行溯源,计算溯源结果;(4)使用本文模型U1、现有模型U2[13]或U3[11,12]分别评估S1、S2、S3、S4;等4类过滤视图的溯源效用.其中使用模型U1所得的溯源效用均不大于0,为0时表明过滤视图的效用与原始起源图的效用相同,达到最大值;为非0的负值时表明过滤视图的溯源效用小于原始起源图的溯源效用,而且数值越大表明过滤视图与原始起源图的相似度越大,过滤视图的溯源效用就越大;使用模型U2和U3所得的溯源效用均不大于1,为1时表明过滤视图的溯源效用与原始起源图的溯源效用相同,达到最大值,而且数值越大表明过滤视图的溯源效用就越大.最后使用U1模型重复执行以上步骤1 000次,记录运行时间,并对比分析不同实验的结果,指出本文模型U1性能可行,而且评估结果更符合客观实际.
具体来讲,为验证本文效用评估模型的合理性,首先,实验1和实验2采用图5所示的邮件转发起源图G作为实验数据,假设其中的敏感节点集为{user_B、email_A′、picture},并假设溯源需求为验证email_B和email_E的可信性,则溯源起点分别为email_B和email_E.采用4种经典过滤技术对起源图G进行过滤得到过滤视图S1、S2、S3、S4,实验1和实验2在各个过滤视图中分别以email_B、email_E为起点进行溯源,并采用溯源效用评估模型U1,U2和U3对溯源结果进行评估,最终实验1、2的结果如表1所示.
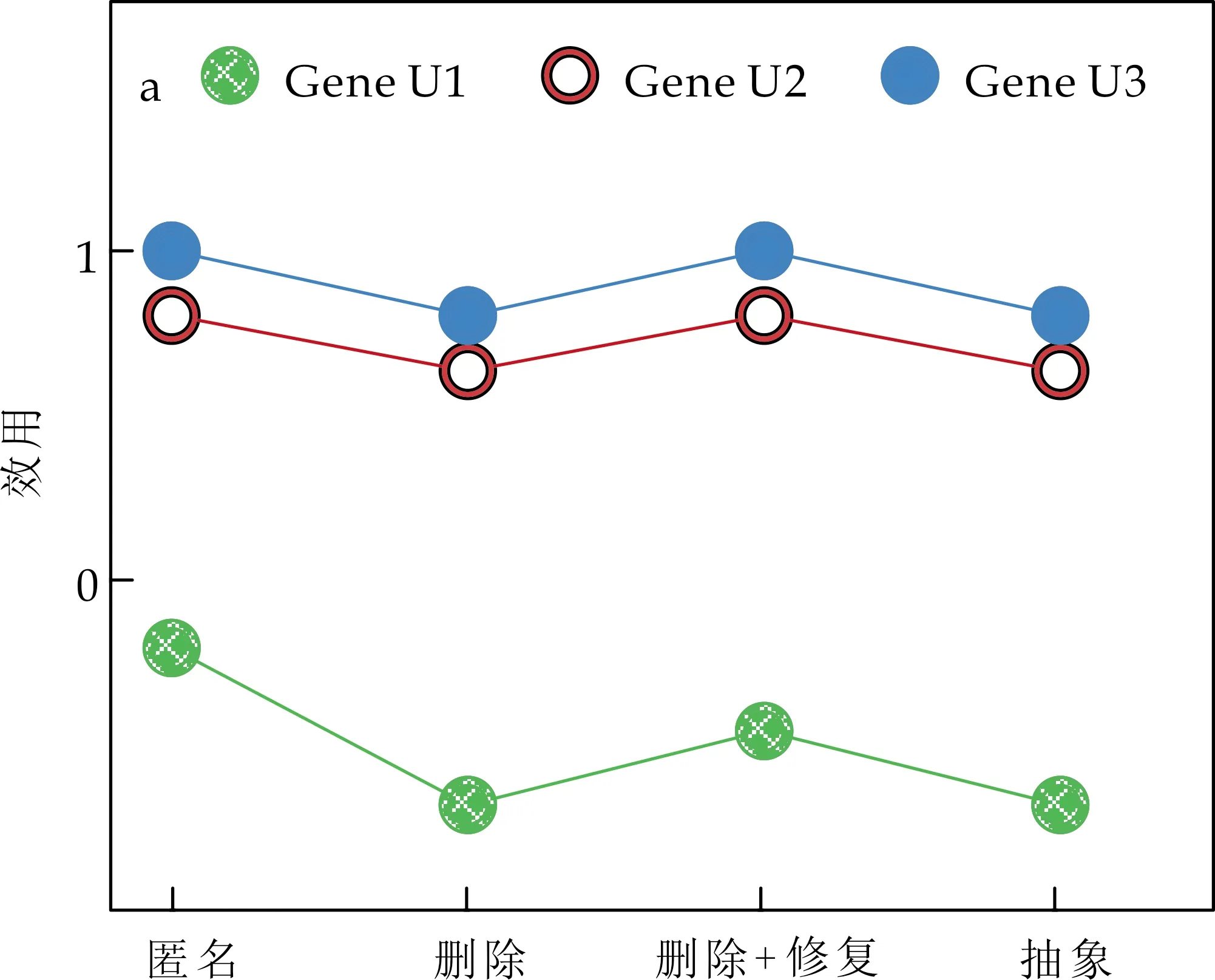
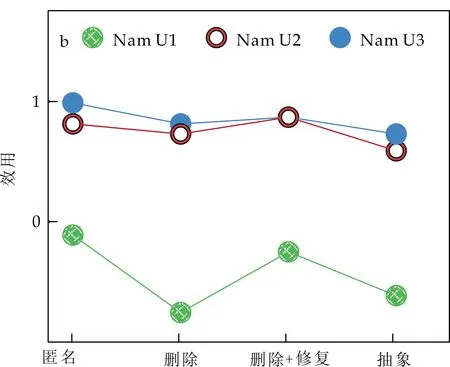
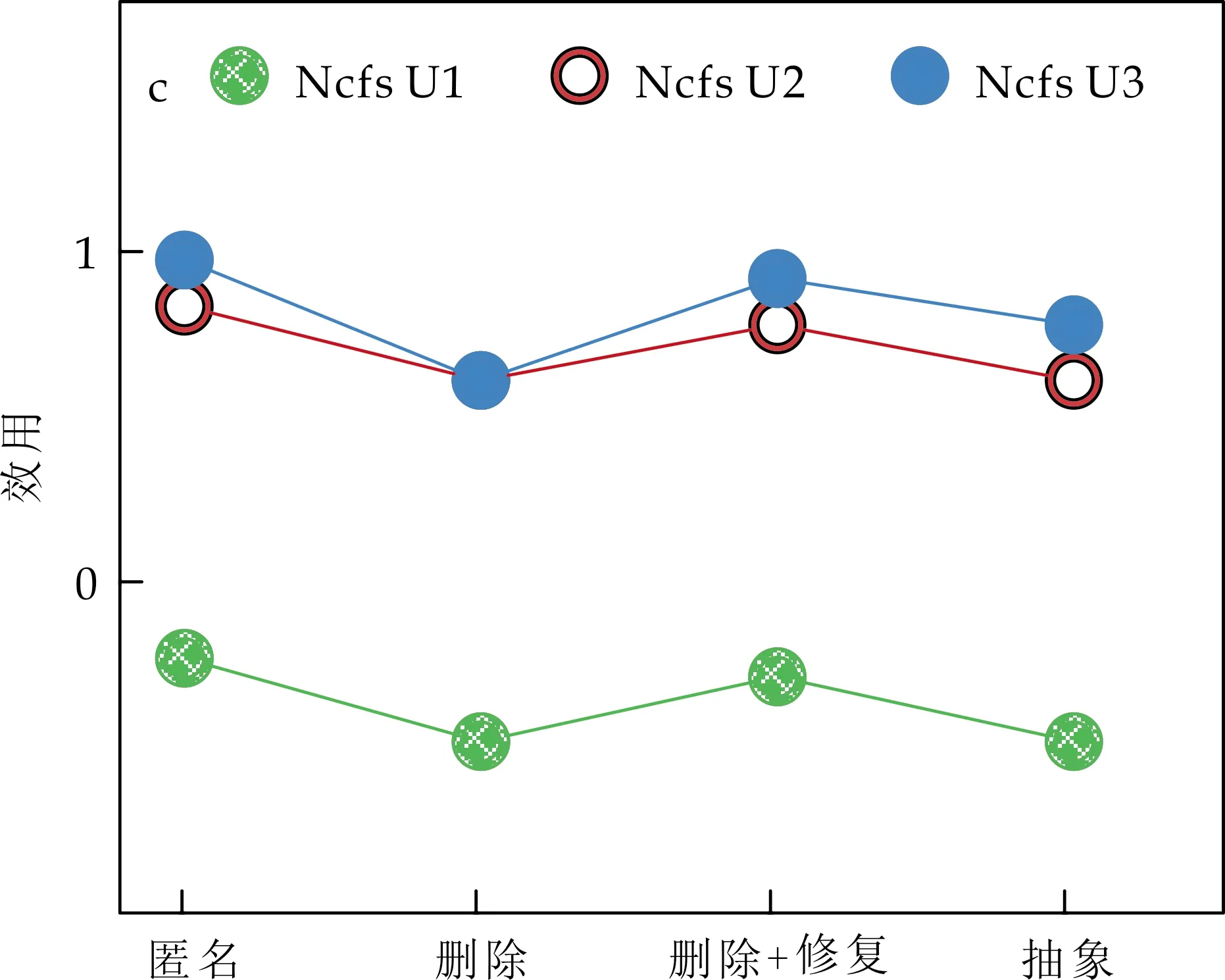
其次,实验3、实验4、实验5分别选用印第安纳大学发布的Gene、Nam、Ncfs三个不同领域的工作流起源数据集[18]为实验数据,模拟领域专家知识,确定过滤需求、溯源需求,并采用4种过滤技术生成相应的过滤视图,在同类数据集的4个过滤视图中选择相同起点进行溯源,溯源效用评估结果如图7所示,图中横坐标表示过滤技术,纵坐标表示溯源效用.评估算法性能结果如图8所示,图中横坐标表示三个不同领域的工作流起源数据集Gene、Nam、Ncfs,其中Ncfs数据集的规模较大,Gene数据集的规模较小,纵坐标表示三个不同领域工作流使用U1模型重复执行1 000次实验的耗时.
对比分析表1、图7以及图8的结果,可得到以下二个结论.
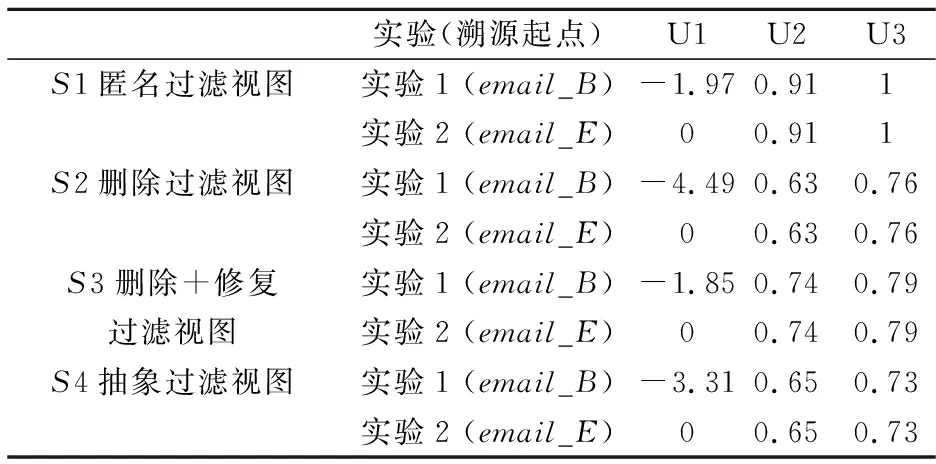
表1 实验1、2的溯源效用评估结果
(a)实验3 Gene
(b)实验4 Nam
(c)实验5 Ncfs图7 不同领域过滤视图的溯源效用
(1)本文模型U1与现有模型U2、U3均能够揭示“运用匿名过滤技术、删除+修复的过滤技术能够得到溯源效用较高的过滤视图”的规律.如表1,图7所示,匿名、删除+修复过滤视图的溯源效用结果大于删除、抽象过滤视图的溯源效用结果.
(2)只有本文模型U1能够揭示“在同一过滤视图中以不同起点进行溯源的溯源效用不同”的规律,本文评估模型更符合客观实际.如表1所示U1列S1中,从溯源起点email_B出发,S1的溯源效用为-1.97,而从email_E出发,溯源效用为0.事实上,S1中,匿名过滤技术对email_E的所有历史节点及相关溯源路径都毫无影响,则S1满足溯源需求email_E的能力最大,溯源效用为最大值0.而现有模型U2和U3,仅计算过滤视图与原始起源图在节点、边或路径上的数量差异,没有考虑溯源起点对溯源效用的影响,同一过滤视图的溯源效用均相同,评估结果不符合客观实际.此外,模型U3没有考虑匿名过滤技术对起源图语义的改变,认为S1的溯源效用达到最大值1,评估结果也不符合客观实际.
如图8所示的实验结果表明,数据集规模较大的Ncfs耗时最大,数据集规模最小的Gene耗时最小.其中影响算法时间性能的因素主要有两个,分别是以溯源起点开始溯源得到的历史节点集的数量m和每条溯源路径的平均长度d.当数据集的规模越大时,m和d的数值就较大,算法的性能就会降低,时间耗时就会越大.
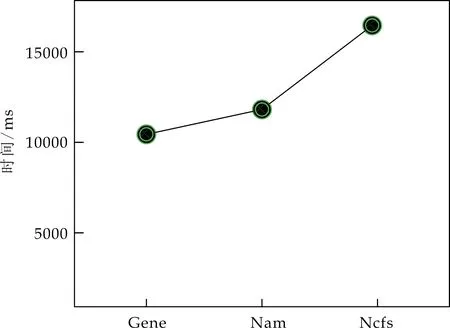
图8 U1算法性能结果图
5 结论
本文针对过滤视图溯源效用的内涵模糊,难以准确评估的问题,提出了基于马尔科夫链的起源过滤效用评估模型.与现有模型相比,本文提出的模型更具可靠性,针对具体溯源需求评估过滤视图的溯源效用,不同溯源效用评估结果表示同一过滤视图满足不同溯源需求的能力不同,更符合客观实际.未来将开展更多不同领域数据的实验验证本文效用评估模型的可靠性和性能.
