应用MSER与DLBP的证件文本定位方法
2020-05-13贾小云潘德燃
贾小云, 潘德燃, 赵 晓
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
0 引言
传统的版面分析与手工校准等方法难以对具有复杂排版或是自然场景中的文本进行定位.如今针对复杂场景进行文本定位的方法,可以分为两类[1]:一类是基于特征的文本定位方法[2,3],该类方法结合滑动窗口与多种特征,利用机器学习等相关方法将窗口分为文本窗口与非文本窗口;二类是基于连通域分析的方法,以基于MSER[4,5]和SWT[6]为代表的方法.基于连通域分析的方法依赖于所采用的连通域提取算法,该算法需要能够对字符连通域的提取拥有高召回率,此外设计一个合理的连通域分析器也是该方法的关键.而基于机器学习的方法则需要手工设计多种特征.单一的特征难以应对复杂的场景,而组合多种特征又会增加特征描述的复杂度,同时所准备正负样本的完备性对结果也有着明显的影响.另外使用深度学习的方法则是通过隐藏层组合多种底层特征形成更加抽象的高层特征来检测文本区域.虽然检测结果优于连通域分析以及手工特征,但是其难以利用文本的上下文信息以及其他知识,同时训练模型也依赖于大量的正确样本标注.
基于此,本文提出一种综合 MSER 连通域分析与单一DLBP[7]纹理特征的证件文本定位方法.该方法针对特定的复杂场景充分利用文本的上下文信息并新设计了一种连通域分析器,对不同倾斜方向的文本行均可以准确定位,结合DLBP纹理特征也可以明显提高定位的准确率.另外该方法结合了连通域分析以及基于特征的方法并使得两部分的设计难度都得以降低.该方法主要包含四个步骤:
首先,是图像预处理,对于输入的图像进行等宽高比缩放,使其像素总量达到某一预设数量.其次,使用MSER算法对其蓝、绿、红通道以及灰度图像提取候选区域并利用简单区域特征进行筛选,用筛选后的候选区域为前景初始化一幅二值图像使得重叠区域得以合并.第三,对该二值图像进行多种形态学处理,填补区域的间断、裂痕以及空洞并使得边界变得更加光滑.最后,提取该二值图像中所有的连通域,并利用本文所提出的文本行合并算法进行连通域合并.最后,利用DLBP 特征结合SVM分类对合并后的连通域进行纹理检测从而得到最终的文本定位结果.
实验结果表明:本文所设计的文本行合并算法具有较高的召回率,而DLBP结合SVM进行纹理分类也有着良好的准确率,同时该方法对其他不同类型的证件进行文本定位也有着一定的兼容能力.
1 多通道MSER候选区域提取
1.1 图像预处理
由于输入图像的尺寸不定,字符的像素尺寸也会有较大差异.过大或者过小的文本可能无法被检测到.同时较大尺寸的图像也会显著影响检测的速度.因此预处理需要将输入的图像缩放到一个合适的大小,本文中将输入图像的像素总量控制在400 000像素左右.以身份证图像为例并对多张证件图像进行测量可得到目标字符大小集中在16×16到33×33像素之间.对缩放好的图像分别提取其R、G、B通道以及灰度图像中的最大极值稳定区域.
1.2 MSER提取候选区域
MSER算法用于检测图像中的最大极值稳定区域.最大极值稳定区域是在一组Q1,Q2,…,Qi,…连续嵌套的极值区域中,如果qi=(|Qi+ΔQi-Δ|)/(|Qi|) 取得最小值,那么Qi即为最大极值稳定区域.其中极值区域Qi是在以i为阈值的二值图像中的一个连通域.由于文本的颜色通常为单一色且与背景色有较大差异,因此是理想的最大极值稳定区域.并且MSER对旋转、缩放以及仿射变换都有很好的鲁棒性,故能够检测出大部分的文本区域.但也存在提取候选区域过多、区域重叠以及由于灰度化彩色字体后对比度下降导致部分文本区域提取不到等问题.这些问题都会对文本区域检测造成一定的影响.
因此,本文首先在输入图像的红、绿、蓝通道以及灰度图像中分别提取最大极值稳定区域.然后利用简单区域特征排除明显非文本候选区域.接着以所得候选区域为前景构建二值图像以此合并重叠的区域.最后通过形态学处理使得区域的形态更加有利于后续处理.其详细流程叙述如下:
第一步:利用 MSER算法分别对R、G、B通道以及灰度图像进行提取得到一组候选区域.并对每一个候选区域进行简单特征筛选,其特征包括区域面积、边界长度、宽高比、占空比以及紧密度[8]这五个简单特征.相关参数如表 1所示.用所得候选区域为前景构建一幅二值图像,将重叠、相交的候选区域合并为较大的选区.
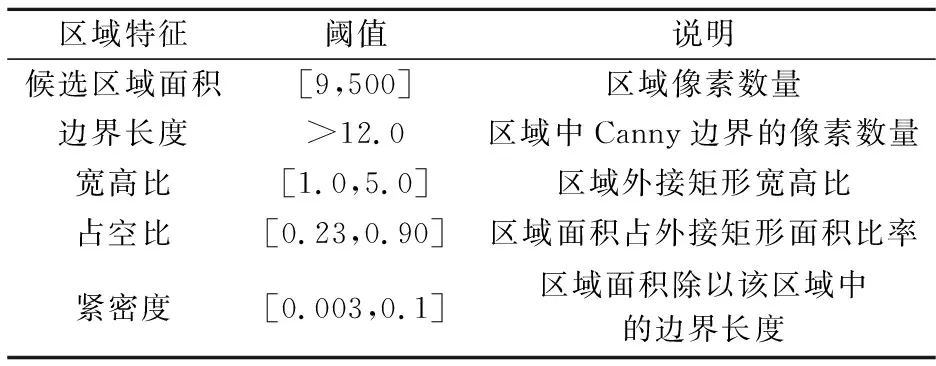
表1 区域简单特征阈值表
第二步:对所得二值图像中的每一个候选区域用3×3的结构元素进行腐蚀,消除区域边缘细小的突刺.但跳过腐蚀后消失或面积小于原面积1/9的区域,因为对这些区域腐蚀会显著改变区域的轮廓.
第三步:由于目标字符大小为16×16至33×33像素之间,因此用6×6大小的矩形结构元素对该二值图像中的每一个面积小于100像素的区域进行膨胀,增大面积过小的区域;第四步对二值图像以3×3的结构元素进行闭运算,填补区域中的间断、裂痕、以及空洞,并使得边界变得更加光滑.对一张居民身份证进行候选区域提取的结果如图 1所示.可在图 1(b)中看到文字区域基本上被全部召回.
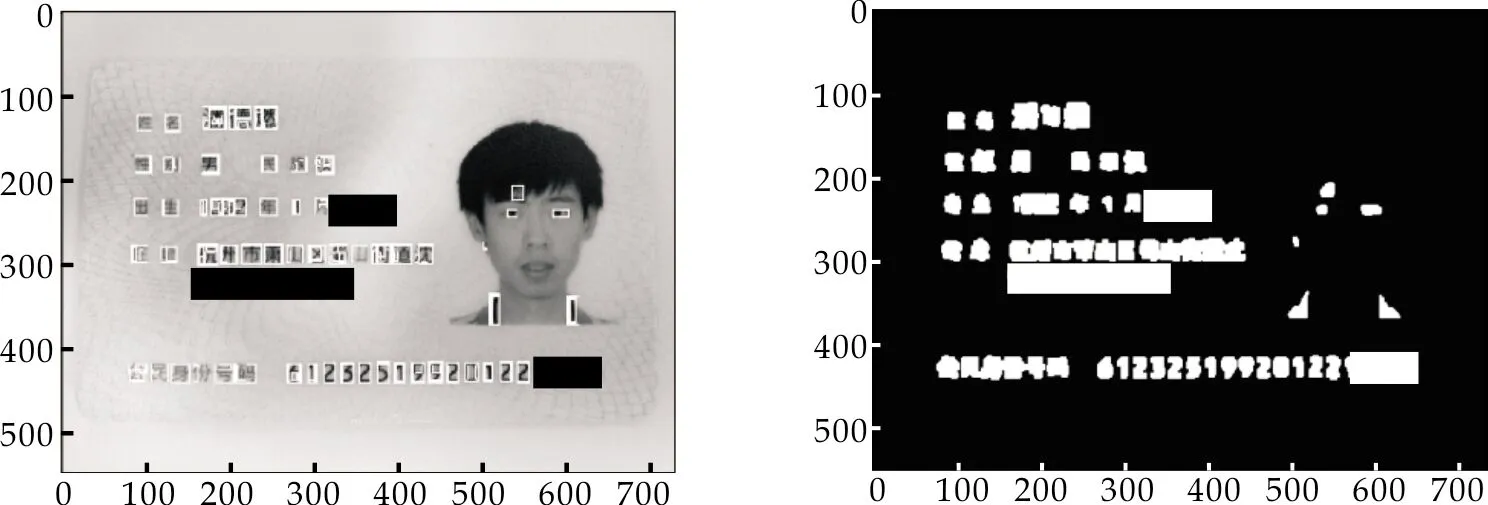
(a)原图 (b)MSER提取图1 MSER候选区域提取图示
2 基于MSER的文本行合并
在上文得到的二值图像中,通过观察可知字符区域的形状大多呈矩形且排列成行,而非字符区域多是不规则形状且分布零散.因此本文设计了如下的方法可以将字符区域合并成文本行.该方法需要对每一个候选区域计算面积、方向以及宽高比三个属性,相关说明如表2所示.
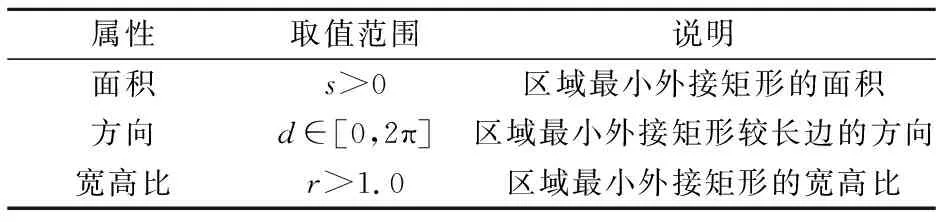
表2 文本行合并所需计算参数
在进行候选字符区域合并时,判断两个候选区域是否可以合并需要依赖两个区域的重叠率、位置比率、方向、距离的判断以及策略的选择,现分别叙述如下:
(1)重叠率α.如果两个区域a、b的重叠率大于1/4,那么这两个区域可以直接合并.α的值为区域a、b交集部分的面积除以a、b中面积较小的面积.
(2)位置比率β.位置比率用于评估两个区域a、b间的相似性和邻近度.β的值为区域a、b的面积和除以包含a、b最小外接矩形的面积.如图 2所示,图2(a)的β值的大小明显大于图 2 (b).β阈值的取值依据区域a、b的情况而定,通过实验得到如下1个定义,2个规则,并以此动态计算阈值.
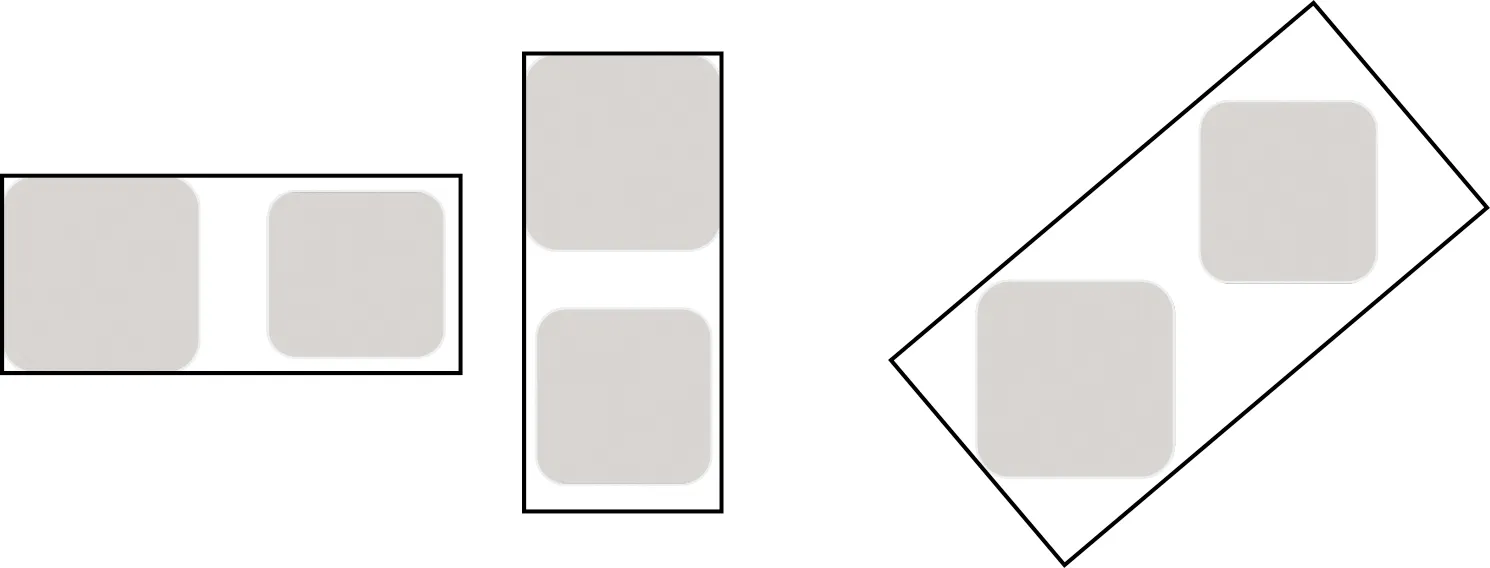
(a)大小相似,位置相近 (b)大小相似,位置相错图2 位置比率图示
定义1:面积小于1 500像素并且长和宽都要小于60像素的区域为单字符区域.
规则1:在区域a、b中如果有一个区域为单字符区域,那么该区域的面积通常较小,位置的轻微改变可能会引起明显的位置比率变动.此时应给予较低的阈值,本文设置为0.6.若单字符区域宽高比大于2.0,表明其更有可能只是偏旁部首应当给予更低的阈值0.55.
规则2:区域a、b的位置比率会随着其宽高比的增加而增加.若区域a、b都不是单个字符区域,且其中存在较高宽高比的区域时,即使两个区域相距很远也能够得到较高的位置比率.所以应当提高此种情况的阈值,默认值为0.7,当a或b的宽高比大于3.0时,阈值提高为0.72;大于5.0时为0.76;大于8.0时为0.8.
(3)方向判断.当两个区域满足位置比率后还需要进行方向判断,以此区别是否是同行文本,从而在合并同行文本的同时,能够有效防止非同行文本的合并.如图 3(a)、(c)所示为可合并的同行文本,而如图 3 (b)、(d)所示为不可合并的非同行文本.

(a)同行文本行 (c)文本行与同行单字符

(b)非同行文本行 (d)文本行与行外单字符
图3 方向判断图示
在图 3中,实线箭头表示区域的方向,即一个区域最小外接矩形的较长边的方向,而虚线表示两个区域中心点连线的方向.通过对这两种方向进行比较,计算其是否满足平行或垂直条件来判断是否是同行文本.当两个方向的最小夹角(≤90 °)小于阈值时满足平行条件,大于90 °减去阈值时满足垂直条件.比较的具体规则如下:
规则1:如果区域a、b都不是单字符区域,那么a、b的方向需要满足平行条件并且a、b中心点连线的方向也要与a、b的方向满足平行条件.
规则2:如果在区域a、b中只有一个是单字符区域,由于单字符区域的方向具有很大的任意性,所以该情况只需要区域a、b中心点连线方向与非单字符区域的方向满足平行条件.
规则3:如果区域a、b都是单个字符区域,那么忽略方向判断.
由于区域的宽高比越小区域的方向便越不稳定,因此阈值也应随之宽松.在本文实验中,当区域a或b的宽高比小于2.0时阈值为35 °,当a和b的宽高比都大于2.0时阈值为30 °.
(4)距离判断.对于宽高比值较高的区域若在其区域方向上存在其他单个字符区域.即使两区域相距很远,也会满足上述所有条件容易造成误合并.因此还需要增加对两个区域的距离判断.由于同一行的两个字符不会相距很远,因此两个区域的最近距离应当小于面积较小区域面积开方的2.6倍.
(5)合并策略.由于在合并时无法判断文本行的方向,可能会造成歧义.如图4(a)所示,用浅色方框代表的待合并区域均可与用深色方框代表的当前候选区域合并,且它们形状相似,浅色方框与深色方框的距离相同.此时,无法判断文本行是如图4(b)所示的水平文本行,还是如图4(c)所示的竖排文本行.
所以,本文设置了三种策略,分别是水平优先、垂直优先和最优策略. 当策略为水平优先时,待合并区域中心点与当前候选区域中心点的连线在x轴上的投影最长的待合并区域优先.垂直策略则是在y轴上的投影最长的优先.最优策略则是位置比率最高的优先.
因此,对于多行邻近的文本,当能够预见目标文本是水平文本行且倾斜程度不大时使用水平优先策略能够得到最优的结果.同理垂直优先策略适合于竖排文本行.但如果错误的对竖排文本行使用水平优先策略则会完全错误的合并结果如图4(d)所示.若无法预知目标文本行方向时,则采用最优策略能够在一定程度上正确合并文本行,包括倾斜的文本行,如图4(e)所示,优于文献[9]所述的方法,只能对水平文本取得较好的定位结果.

(a)字符候选区域 (b)水平文本行 (c)竖排文本行

(d)使用水平策略合并 (e)最优策略竖排文本图4 合并策略示意图
文本行合并算法如下所示:
输入:一组待合并的区域Rs={r1,r2,…,rn};
a)令i=0,j=0,令可合并集合Rcandidate为空;
b)如果i>=length(Rs),那么转至j),其中length()返回集合中元素的个数;
c)j=i+ 1;
d)如果j>=length(Rs),那么i++,然后转至i);
e)如果ri,rj满足重叠率的合并条件,那么将rj加入到Rcandidate集合中,j++,转至d);
f)如果ri,rj不满足位置比率的条件,那么j++,转至d);
g)如果ri,rj满足方向和距离的合并条件,那么将rj加入到Rcandidate集合中,j++,转至d);
h)j++,转至d);
i)如果Rcandidate不为空,那么根据文本行合并策略从Rcandidate挑选出一个最优合并区域rk,将ri,rk合并成一个新的区域rnew,并将ri,rk从Rs中删除,将rnew添加至Rs中,转至a);否则i++,转至b);
j)输出Rs;
3 基于DLBP特征文本区域检测
在进行文本行合并算法后仍然会存在非文本区域.并且这些非文本区域已经难以通过简单区域特征进行筛选.因此,本文从这些候选区域的纹理特征入手,采用DLBP特征描述区域纹理并结合SVM 进行分类检测从而得到最终的文本区域.
LBP[10]特征是基于像素编码的纹理信息.在以中心像素为圆心,半径为R的圆周上均匀分布m个采样点.若采样点的灰度值大于中心像素则为标记为0,小于中心像素则为标记为1.所有标记则构成了长度为m的LBP编码.m为8的LBP编码一共有256种组合.通过增加旋转不变性和使用uniform模式可以显著减少LBP编码的种类数量.目前有许多关于应用LBP特征进行相关目标检测的研究[11,12].
由于在uniform模式的编码中最多不超过两次1和0之间的跳变,当纹理大多是由直线或者较少曲线构成时,uniform模式可以很好的捕获其纹理特征.但是对于拥有很多曲线弯折的纹理时,uniform模式则无法很好的代表其纹理特征.DLBP则是通过获取全部的LBP编码,根据不同LBP编码出现的数量建立统计直方图.然后对统计直方图进行降序排序,将前k个编码的数量作为其特征向量.而前k个LBP编码的数量大约占据该图像全部LBP编码数量的80%左右.根据Liao S等[7]在Brodatz、Meastex、以及CUReT数据库上的测试,此时的编码的种类大约只占所有编码种类的20%.因此DLBP特征能够在较少的增加数据维数的情况下很好的捕获复杂的纹理特征.
本文通过提取各个候选文本区域的DLBP特征,并通过训练数据计算k值以及构建SVM模型.通过SVM可以有效的依据纹理特征检测出文本区域.如图5(b)所示,为正确排除在图5(a)中由于人像所产生的非文本候选区域.

(a)仅文本行合并 (b)使用DLBP特征过滤图5 DLBP特征检测结果
4 实验结果与分析
4.1 数据集及评价标准
本文测试数据为身份证图像.测试包含600张图像,其中随机选取300张图像作为训练数据,300张图像作为测试数据.评价方式采用F-measure评价标准,包含准确率(Precision)和召回率(Recall)这两个度量值.每个样本包含由本文方法检测得到文本区域E和真实标记的文本区域T.在一幅图像中,每一个检测出的文本区域e和真实标记的文本区域t都会计算出一个评估值m(e,t),该值为两个区域的交集面积除以第一个参数的区域面积.值为1代表恰好重叠,值为0代表完全不重叠.准确率P和召回率R的计算方法分别如式(1)、(2)所示:
(1)
(2)
F评价值的计算依赖于准确率和召回率.本文设置准确率和召回率的权值各位0.5,因此F的计算方法如式(3)所示:
(3)
4.2 文本定位结果
分别在仅文本行合并(水平优先策略)、合并后再使用DLBP特征检测、文献[13]以及文献[14]四种方法针对实验数据进行文本定位,其结果如表 3所示.本文所设计的方法在准确率上要明显优于文献[13]和文献[14]中的方法,同时召回率也保持在较高水平.
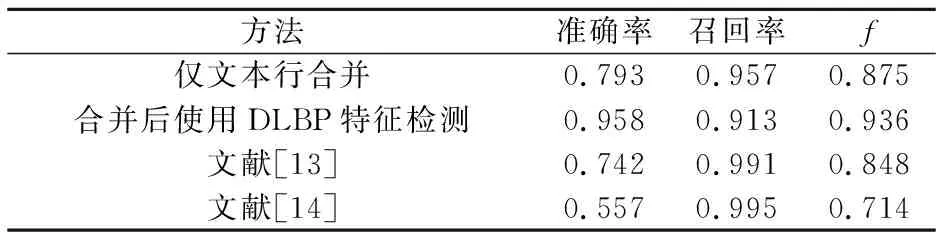
表3 实验结果数据
文献[13]采用对身份证进行版面分块后再利用字符投影的方式完成文本行定位.其所定位的每一行文本宽度均与所划分的块宽度相同.文献[14]则只对身份证左半部进行水平投影从而完成文本行定位,其所定位的文本行宽度与整个身份证宽度相当.这两种方法所定位的文本行不仅包含了文本,同时还包含大量空白或是其他区域.虽然拥有很高的召回率,但是准确率较低,且都针对身份证进行了版面划分,对其他证件不具有兼容能力.
由于不同证件字符大小存在相似性,文本方法同样可以对其他证件图像进行文本定位.对其他证件的文本定位结果如图 6所示,包含对车牌、卡号、名片等图像进行文本定位.

(a)银行卡 (b)一卡通

(c)车牌 (d)名片

(e)纯文本图6 对其他场景进行文本定位
5 结论
本文针对证件文本定位问题提出了一种基于MSER和DLBP纹理特征的定位方法,并自行设计了一种文本行合并算法.区别于大多数先分类后合并的流程,本文在使用MSER算法提取出候选区域后,首先对其进行文本行合并处理,再对合并后的候选区域进行纹理特征分类.
实验表明,本文提出的文本行合并算法具有较高的召回率,能够得到较满意的文本行.采用DLBP纹理特征结合SVM对合并后的候选区域进行分类检测也能够使得准确率得到明显的提高而召回率只有略微降低,显示了本文所述方法在证件文本定位方面具有一定的能力.
图6展示了本文所述方法在其他方面的一些潜在应用,如车牌检测、卡号提取以及文档数字化等方面.通过调整本文方法的参数可以适应于不同场景,显示了本文所述方法在其他应用场景同样具有一定的潜力.
