使用孪生注意力机制的生成对抗网络的研究*
2020-05-13武随烁杨金福许兵兵
武随烁,杨金福,单 义,许兵兵
1.北京工业大学 信息学部,北京 100124
2.计算智能与智能系统北京市重点实验室,北京 100124
1 引言
通过学习高维数据分布产生新样本的生成模型被广泛应用于诸如语音合成[1]、图像风格转换[2]、图像修复[3]等领域,目前最具典型的生成模型有变分自编码器[4]、自回归模型[5]以及生成对抗网络(generative adversarial network,GAN)[6],它们都有各自的优势和劣势。变分自编码器容易训练,但由于模型的限制,往往会生成模糊的结果。自回归模型通过直接模拟条件分布虽然能产生较好的结果,但没有潜在的表示,且评估速度慢,适用性不强。生成对抗网络可以生成较为清晰的图像,即使在较小的分辨率和类别变化有限的图像上,其也能将随机噪声以无监督的方式映射成图像,具有无限建模能力。综合分析上述三种方法,生成对抗网络具有最好的生成图像能力并具有无限发展空间,以最大似然估计为基础理论的变分自编码器和自回归模型则不具备无限建模的能力,生成的图像也没有生成对抗网络那样逼真。
生成对抗网络已成为生成模型中的一个研究热点,吸引了众多学者,将该模型应用在计算机视觉领域的众多方向。Ledig 等人[7]将其应用于单张图像的超分辨率,取得了良好的效果。Tang 等人[8]使用生成对抗网络模拟正常胸部X 射线的基础内容结构,进行异常胸部X 射线识别。Jo 等人[9]将生成对抗网络应用于人脸编辑,使用户根据草图修改人的面部。
2 生成对抗网络
生成对抗网络是GoodFellow 等人[6]于2014 年提出的生成模型,该框架包含两个子网络,即生成器(G)和判别器(D),它们对应的功能分别为将随机噪声映射成样本分布、鉴别真实样本与生成的样本。与其他生成模型(直接以数据分布和模型分布的差异作为损失函数)不同的是,GAN 采用对抗的方式,先通过D学习真实样本和生成样本的差异,再引导G生成更靠近真实样本分布的假样本,通过交替训练不断缩小差异。目前,GAN 主要优化以下最大最小损失函数达到纳什均衡:
(1)一种仅通过输入随机噪声训练无条件生成器的模型。
(2)一种用于不同域之间数据迁移的新技术,是域间无监督图像转换的有效方法。
(3)一种新的优化方法,并且提供有效的图像感知损失函数[12]。
虽然GAN 取得了较大的进步,有效生成了令人信服的图像,但还存在一些问题亟待解决:
(1)GAN 的训练过程极其不稳定,网络对超参数十分敏感,很难达到纳什均衡。
(2)GAN 经常出现模型崩溃,导致模型只模拟真实分布的一部分,而不是目标分布的所有分布。
(3)GAN 不能捕捉图像中某些类别中的结构和几何形状。
现有的大量工作多致力于优化GAN 的训练过程,有些专注于改变GAN 的目标函数,例如LSGAN(least squares generative adversarial networks)[13]将标准GAN 的交叉熵损失换成最小二乘损失,既提高了训练的稳定性又缩短了训练时间。有些专注于通过梯度惩罚或归一化约束D的梯度,确保D可以为G提供有效的梯度,WGAN(Wasserstein generative adversarial networks)[14]模型对D实施限制,使其满足Lipschitz约束,大大提升网络的稳定性。虽然WGAN 满足Lipschitz 约束,但其直接对参数矩阵进行限制,这种做法破坏了参数矩阵的结构,即各参数之间的关系。针对该问题,文献[15]引进一种新正则化技术,既满足Lipschitz约束,又不破坏参数矩阵结构。
此外,还有一些研究论文旨在修改GAN 的框架。
EBGAN(energy-based generative adversarial networks)[16]
是第一个将能量模型引入GAN 的框架,它把D看作一个能量模型,采用自编码器结构,真实样本赋予低能量,假的生成样本赋予高能量,通过减小生成样本的重构误差,逐渐向真实样本分布靠近。ProGAN(progressive generative adversarial networks)[17]通过逐步增强G和D来训练一个高分辨率GAN,其首先从低分辨率图像开始训练,然后通过向网络添加层来逐步提高分辨率,这种训练方法首先发现大规模的结构图像分布,然后将注意力转移到越来越精细的比例细节,而不是同时学习所有比例,但其只在单一特征图像上产生较好的结果。SAGAN(self-attention generative adversarial networks)[18]通过对加强特征图各局部位置和全局位置的联系,试图使GAN 在多类别图像上生成高质量图像,但其忽略了特征图各通道之间的联系。
本文针对GAN 不能捕捉图像中某些类别中的结构和几何形状,提出一种基于孪生注意力机制的GAN 模型,它可以通过自适应学习局部与全局特征的依赖性以及各类别间的依赖性,有效地捕获图像的几何结构和分布,从而描绘出更细致逼真的图像。
3 孪生注意力机制
图像生成是计算机视觉中的一个重要的研究方向,GAN 框架的出现使该方向的研究取得了巨大的进展。该模型擅长合成如数字、海洋和天空等较少结构约束的图像,但在种类较多的数据集上训练困难,无法捕捉某些类中多次出现的几何结构和形状。造成该问题的原因可能是目前的模型过度依赖卷积模拟图像不同区域间的依赖性,由于卷积具有局部感受野,因此只能通过多个卷积操作才能得到大范围区域间的依赖性。如图1 所示,仅获取7×7 感受野间的特征关系就需要3 个3×3 大小的卷积层,但在卷积操作的过程中,优化算法可能难以协调这么多卷积层,而且越多的卷积层捕获的依赖关系越弱。如果扩大卷积核的大小,如采用7×7 大小的卷积核,仅通过一个卷积层就可以获取7×7 感受野间的特征依赖性,但这样做不仅没有采用几个小滤波器卷积层组合的效果好,而且会大大增加计算量。故仅通过卷积层获取图像间的依赖关系甚为困难。
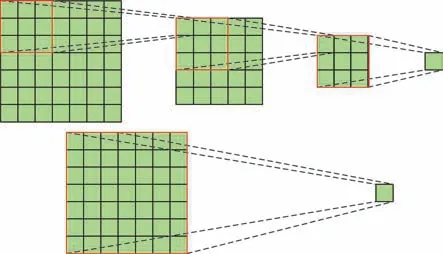
Fig.1 Schematic diagram of obtaining 7×7 receptive fields by different convolution kernels图1 不同卷积核获取7×7 感受野示意图
针对CNN 无法有效捕捉图像的几何结构和形状的问题,有学者将广泛应用在其他领域[19]的注意力模型引入GAN,弥补CNN 框架的不足。注意力模型的本质是通过一系列的注意力分配系数,即权重系数,来强调或选择目标对象的重要信息,并且抑制一些无关的细节信息。注意力机制可以灵活且一步到位地捕捉局部和全局的联系,提升模型的表示能力,且模型复杂度小。因此,为了生成更高质量的图像,本文提出一种基于孪生注意力机制的GAN 框架(twins attention mechanism based generative adversarial network,TAGAN),引入两个不同的注意力模型,即特征注意力模型和通道注意力模型,分别捕获特征空间和通道两个维度上的特征依赖性。下面具体介绍本文提出的模型框架。
3.1 特征注意力机制
为了在特征图的局部特征中增添其与全局特征的依赖性信息,引入一个特征注意力模型,该模型通过将广泛的全局空间信息进行编码,增添到局部特征信息中,从而增强其表示能力,具体框架如图2 所示,其中C代表特征图的通道数,H和W分别表示特征图的高和宽。
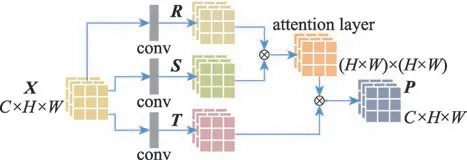
Fig.2 Feature attention model图2 特征注意力模型
首先,前一层的特征图X∈ℝC×H×W经1×1 卷积形成R、S、T三个特征空间,各特征空间的通道数量分别为C/8、C/8、C。其中对特征空间R和S的转置进行矩阵乘法,再应用softmax,得到特征注意力层的参数,具体参数值由式(2)计算得到。

其中,pj,i表示第i个位置的特征对第j个位置的特征的影响,两个位置的特征越相似,它们之间的相关性就越大。然后,对特征空间T与特征注意力层的转置进行矩阵乘法操作,得到特征注意力特征图P=(P1,P2,…,Pj,…,P(H×W))∈ℝC×(H×W)。

3.2 通道注意力机制
对于特征图,每个不同的通道可视为代表特定的类,不同的通道彼此具有关联性,故提出通道注意力模型,提取不同通道间的依赖性,通道注意力模型框架如图3 所示。
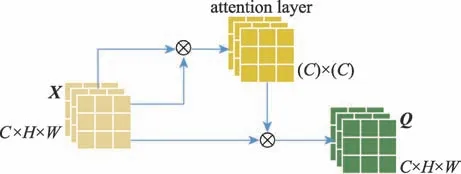
Fig.3 Channels attention model图3 通道注意力模型
与特征注意力需要对特征图X∈ℝC×H×W进行卷积不同,通道注意力直接使用特征图X计算通道注意力特征层参数,但计算过程类似,计算公式如式(4)所示。
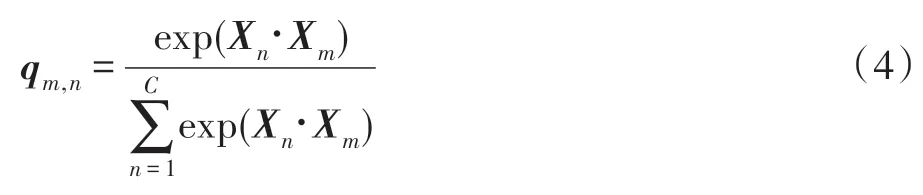
其中,qm,n为第n个通道对第m个通道的影响,两个通道的特征越相关,它们之间的依赖性就越大。另外,对通道注意力特征层和输入特征空间X的转置执行矩阵乘法,最后输出通道注意力特征图Q=(Q1,Q2,…,Qm,…,Q(H×W))∈ℝC×(H×W)。

3.3 孪生注意力机制
图4 所示为孪生注意力模型框架图,将输入的特征图与特征注意力模型和通道注意力模型的输出P和Q融合,得到具有局部与全局特征依赖信息、各类别依赖信息的特征空间E∈ℝC×H×W,其计算公式如式(6)所示。

其中,α和β分别为P和Q的超参数,初始化为0,通过反向传播更新。在网络训练过程中,随着两个注意力模型从简单的特征依赖性开始,逐渐学习到复杂的依赖关系,P和Q的权重α和β逐渐增加,将注意力模块学习到的加权的特征图加在原始的特征图上,从而强调了需要施加注意力部分的特征图。在G和D的高层网络中,孪生注意力机制作为一个GAN 的辅助结构,级联在CNN 之后。如图5 所示为TAGAN 网络训练流程图,其中CNN 表示卷积操作,TA 表示引入的孪生注意力机制,通过G和D不断循环交替训练,G生成愈来愈逼真的图像。
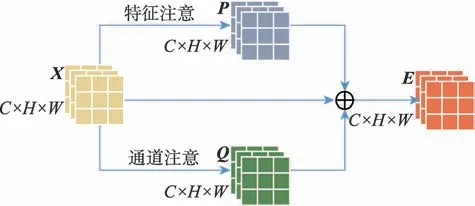
Fig.4 Twins attention mechanism framework图4 孪生注意力模型框架
4 实验结果与分析
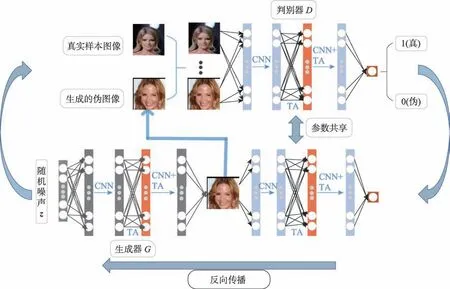
Fig.5 Twins attention based generative adversarial network图5 孪生注意力生成对抗网络框架
在实验过程中,引入谱归一化[15]和SeLU(scaled exponential linear unit)[20]技术,损失函数采用Hinge对抗损失[21]。谱归一化是一种权重归一化技术,用于稳定D的训练过程。通过谱归一化约束D的梯度,确保D可以给G提供有效的梯度。在网络传播时,激活函数SeLU 可以自动将样本分布推向零均值和单位方差。考虑到SeLU 的归一化特性一定程度上也可以稳定D,因此本文采用结合谱归一化和SeLU来稳定D的训练过程,单独使用谱归一化调节G,通过Hinge 对抗损失,交替优化G和D。本文实验是在MNIST、CIFAR10 和CelebA64 数据集上进行训练。MNIST 是手写体数字识别数据集,包含0 至9 共10个数字。CIFAR10 是一个包含飞机等交通工具、鹿等动物10 个类别的,32×32 像素图像的数据集。CelebA64 是一个每张图像为64×64 像素的人脸图像数据集。本文实验使用的深度学习框架和计算机运行环境如下:Pytorch,Ubuntu16.04,计算机处理器为Intel Xeon®E5-2683 v3,显卡为GeForce GTX 1070。
为验证本文提出的孪生注意力机制生产对抗网络模型的有效性,与流行的WGAN-GP(Wasserstein generative adversarial networks-gradient penalty)[22]和同样使用注意力机制的SAGAN[18]进行比较。与其他类似单纯增加批次尺寸来扩大参数量不同的是,这几个模型的共同特点是结构简单,参数量相对较少,仅占用较小的GPU 内存,使用这种相似的GAN 框架模型作对比,更能验证所提方法的有效性。生成的图像如图6 所示,图(a)、(d)、(g),图(b)、(e)、(h)和图(c)、(f)、(i)分 别 是SAGAN、WGAN-GP 和TAGAN 生成的图像,图(a)、(b)、(c),图(d)、(e)、(f)和图(g)、(h)、(i)分别为利用MNIST、CIFAR10 和CelebA64 数据集训练的GAN 模型生成的图像。SAGAN 模型因为同样使用了注意力机制,其生成的图像风格与TAGAN 的图像相似,但SAGAN 生成的图像出现较多的异常结构图像,尤其是在复杂的CIFAR10 数据集上,如图(d)所示。究其原因,SAGAN 虽然通过注意力模型捕获了单张特征图上的特征依赖关系,但无法捕捉各通道之间的联系,无法整合各个类别间的依赖信息,故未能成功捕获图像的所有几何特征和结构。从图(h)可明显看出,WGAN-GP 生成的图像有尖锐的锯齿状边缘,没有引入注意力机制的GAN 框架生成的图像平滑。从3 幅MNIST 图像也可明显看出,图(b)比图(a)和图(c)模糊。SAGAN 和WGAN-GP 因为无法完全模拟真实样本的结构分布而出现较多的无序图像。与它们相比,TAGAN 图像表现出更好的有序性,能够更好地捕捉真实样本的特征信息去模拟几何结构,使图像看起来更逼真,例如图(i)所示,混乱图像大大减少,绘画出的人脸图像也更逼真更细致。

Fig.6 Comparison of generated images by TAGAN,SAGAN and WGAN-GP图6 TAGAN 与SAGAN、WGAN-GP 生成图像对比
此外,GAN 学习作为一个无监督的过程,很难找到一个客观、可量化的评估指标。有许多指标在数值上虽然高,但生成结果未必好,可能出现数值结果与人的主观判断结果相反的现象。为了客观评价TAGAN,本文采用一种相对有效且被广泛采用的评估方法——FID(Frechet inception distance)[23]。FID将真实样本x和生成样本g建模为高斯随机变量,其样本均值为μx和μg,样本协方差为Σx、Σg。两个高斯分布的距离可通过式(7)计算。

FID 作为两个分布之间的距离,数值越低表示两个分布越接近。生成的MNIST、CelebA64和CIFAR10图像与真实样本间的FID 数值如表1 所示。TAGAN在3 个数据集上的表现都优于SAGAN 和WGAN-GP的结果,表明TAGAN 生成的图像样本分布与真实样本分布更接近,能有效捕捉图像局部与全局特征之间的依赖、单个类别和多个类别之间的依赖关系,生成更高质量的图像。
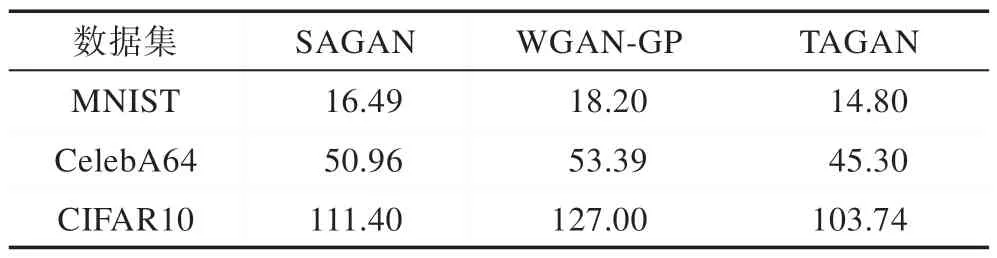
Table 1 FIDs with different GAN frameworks on MNIST,CIFAR10 and CelebA64表1 不同GAN 方法在MNIST、CIFAR10和CelebA64 上的FID 值
5 结束语
针对传统GAN 无法有效提取图像局部与全局特征间依赖关系以及各类别间依赖关系的问题,提出一种基于孪生注意力机制的生成对抗网络模型,包含特征注意力和通道注意力两个子模型。以注意力机制为驱动,两个子模型分别对局部特征和全局间依赖关系以及各类别间的依赖关系进行建模,用于图像生成任务。在3 个数据集上进行实验,结果表明本文提出的框架比其他框架能够更全面地获取图像中的特征信息,生成的图像结构分布也与真实分布更为接近。在未来的工作中,将致力于生成更复杂的高分辨率图像。
