融合知识图谱与深度学习的疾病诊断方法研究*
2020-05-13董丽丽
董丽丽,程 炯,张 翔,叶 娜
西安建筑科技大学 信息与控制工程学院,西安 710055
1 引言
在大数据的推动下,医疗诊断不断朝着智能化方向发展,借助人工智能技术可以实现对医疗数据的挖掘与分析。目前,深度学习在疾病诊断领域中已取得较好的成果,如Coudray 等[1]通过训练神经网络来预测肺癌、腺癌中10 个常见的突变基因,其预测突变基因模型的准确率为0.733~0.856;Tsehay 等[2]提出使用基于深度学习的卷积神经网络(convolutional neural network,CNN)架构识别前列腺癌,通过获得结构化的高抽象映射使得疾病分类更准确;Esteva等[3]构建了能自主检测和分类皮肤癌的深度学习模型;Camps等[4]提出使用腰部佩戴式测量单元和深度学习算法预测帕金森病。然而深度学习作为一种数据驱动技术,依赖于大样本标记数据,其采用自动提取特征的方法虽提高了效率,但往往缺乏医生专家诊断的经验和知识,其结果无法发现隐含的疾病与症状间的关联关系。
与此同时,当前人类社会也已积累大量知识,特别是近几年在知识图谱技术的推动下,这类蕴含大量疾病知识与症状特征的医学知识图谱不断被构建,如IBM 的Watson Health[5]、上海曙光医院的中医药知识图谱[6]、搜狗的AI 医学科普知识图谱[7]和华东理工大学构建的中文症状库等,其在医学知识检索与医疗文本挖掘中受到关注和研究。与传统知识表现形式相比,知识图谱具有实体和概念覆盖面广、语义关系多样、结构友好以及质量较高等优势,使得机器语言认知成为可能。智能诊断旨在让机器“学习”医生诊断的经验知识,通过模拟医生的思维进行诊断推理。因此如何把知识和数据结合起来,利用蕴含于医学知识图谱中的经验知识指导深度神经网络模型的学习,对疾病的挖掘与诊断有着重要的研究意义。
以急性心肌梗塞的诊断为例,缺乏经验的深度学习往往比较注意经常出现的典型特征,如心前区压榨性疼痛及胸闷不适等,而对其他一些非典型特征则可能学习不到。如患者以咽喉部疼痛为主要表现就诊时,可能会被诊断为慢性咽炎而给予对症治疗。实际上咽痛也可以是心肌梗塞的非典型体征,只是面向数据提取特征的深度学习对此缺乏认识和经验。如果应用具有丰富诊断经验的疾病知识图谱进行诊断,当它发现相同的咽痛症状时,则会根据结构化知识的相连直接或间接推理注意到咽痛的时间性及性质,迅速将咽痛与心肌梗塞联系起来,并结合其余症状排除有无心肌梗塞的存在。因此在现有研究当中,虽然知识图谱或深度学习的方法都可用于诊断疾病,但只有两者结合,才能使“机器医生”做出正确诊断,达到尽可能降低疾病误诊率目的。
基于上述问题,本文提出融合知识图谱与深度学习的基于病情描述文本的疾病诊断方法(disease diagnosis method combining knowledge graph and deep learning,KGDeL)。首先识别病情描述语句中的疾病特征词,使用词嵌入将其转化为词向量;其次通过结构化知识提取得到医学知识图谱(medical knowledge graph,MedKG)中与疾病特征相关的实体和关系,并利用知识图谱嵌入将其转化为低维连续的向量;最后将疾病特征词向量与相关知识实体向量作为CNN 的多通道输入,通过融合多个通道的信息从而使得网络能够学习到更丰富的疾病特征。实验表明本文方法通过加入MedKG 这一拥有医生经验的主观知识,使得CNN 在训练病情描述文本客观数据时能学习到更全面更直接相关的疾病特征,从而提高了不同类型疾病的诊断准确率,更适用于初步诊断病情描述的疾病。
2 医学知识图谱
2.1 三元组结构定义
医学知识图谱MedKG 是现实世界中根据医疗实体(结点)、实体间关系(边)相互连接起来所形成的一种网络结构,三元组作为知识图谱的一种通用表示形式,可将图谱中的每一条医学知识直观地表示 为MedKG=<head,relation,tail>,其中head、tail分别为三元组的头实体、尾实体,都属于MedKG 的实体集合,relation={r1,r2,…,r|R|}是MedKG 的关系集合,共包含R种不同关系。现有许多开放的语义库或各领域的中文知识图谱,本文采用华东理工大学构建的中文症状库作为MedKG,其新的实体集是由现有三元组数据头实体与尾实体所在列合并得到,关系集是将现有关系所在列构成。其中,医疗实体(head或tail)作为MedKG 中最基本的元素,主要由疾病、药物、症状、辅助检查、科室、部位等构成;关系(relation)存在于不同head或tail之间,主要包含类别、临床表现、病因、发病机制、预防、药理作用等。
三元组的存在表示图谱中的实体处于给定类型的关系中。例如支气管炎的描述为:支气管炎(Bronchitis)多见于中老年人和吸烟人群,临床表现为咳嗽明显、咳痰和(或)反复呼吸道感染,其通过三元组表示的结果见表1。同时将表1 中的所有三元组合并得“支气管炎”的知识图谱,如图1 所示,其中不同含义的结点表示head或tail,有向边表示head和tail之间的关系,边的方向表明实体是作为主体(head)还是对象(tail)出现,不同relation通过不同类型的边来表示。

Table 1 Triple representation of Bronchitis description表1 支气管炎描述的三元组表示
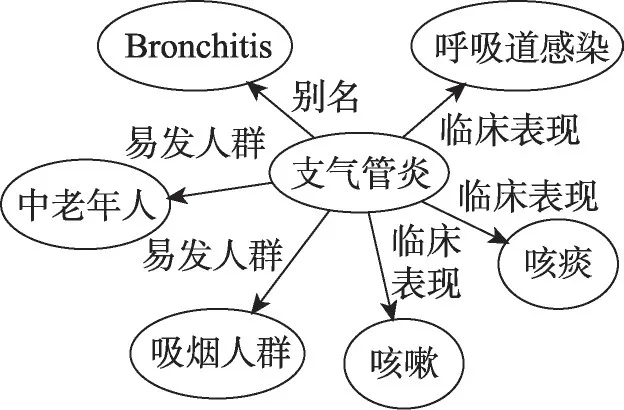
Fig.1 Example of medical knowledge graph图1 医学知识图谱示例
2.2 知识图谱嵌入
知识图谱嵌入(knowledge graph embedding)旨在对图谱中的头实体、尾实体和关系进行表示学习[8],通过将head、tail或relation投影到低维向量空间,来保存知识图谱中的语义结构信息,从而得到实体向量表示,以用作实体间的相似度计算或其他领域的应用等。不同知识图谱嵌入方法因其模型结构不同,所习得的知识向量也存在较大差异,如TransE 作为最具代表的翻译模型,对于给定三元组<h,r,t>,关系r被解释为从头实体h到尾实体t之间的平移向量,即当<h,r,t>成立时应有h+r≈t,否则t与h+r应当远离,得分函数如式(1)所示,下标指计算时使用L1距离或L2距离。

TransE 由于模型参数较少,计算复杂度低,能够有效处理简单的1∶1 关系,故适用于大规模稀疏医学知识图谱。但在处理1∶N、N∶1 以及N∶N复杂关系时其性能明显降低,针对复杂关系的医学知识图谱MedKG,本文采用TransD 模型来对其三元组数据进行表示学习。
对于给定三元组<h,r,t>,TransD 认为关系所连的头实体、尾实体包含不同的语义。通过使用两个投影矩阵Mh和Mt将头实体h和尾实体t分别投影到关系空间,并将每个关系的投影矩阵分解为两个向量的乘积,其得分函数如式(2)所示:
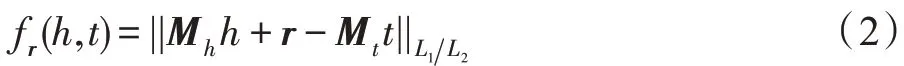
其中,Mh=rphp+Im×n,Mt=rptp+Im×n,hp,tp∈Rm、lp∈Rn是映射向量,Im×n是单位矩阵。显然,Mh和Mt与实体和关系均相关,通过向量运算转换,提高了模型计算速度。
3 融合知识图谱的卷积神经网络疾病诊断方法
3.1 基本思想和框架
本文疾病诊断KGDeL 方法主要包括三部分:疾病特征选择、结构化知识提取以及知识驱动的卷积神经网络。图2 为KGDeL 的整体结构图。

Fig.2 Overall architecture of KGDeL图2 KGDeL 整体结构图
3.2 疾病特征选择
病情描述是患者对自身疾病症状、病因以及严重程度等的描述语句。为了识别语句中所有与疾病特征相关的关键词,对文本数据进行清洗、分词、词性标注以及医疗实体识别等预处理操作。本文使用清华大学THULAC(THU lexical analyzer for Chinese)中文分词系统及医疗专业疾病与症状词典,对病情描述语句进行分词、词性标注及识别医疗实体,并通过去除停用词及无意义的单字,得到一组与病情描述相关的疾病特征关键词。一条由n个特征词构成的疾病特征为x=[w1,w2,…,wn],其中wi为构成一条完整疾病语句其第i个位置的词汇,本文使用word2vec的CBOW(continuous bag-of-words)模型[9]将选择得到的每个疾病特征词转换为词向量,即映射为对应的d维表示向量w1:n∈Rd。
3.3 结构化知识提取
结构化疾病知识提取过程如图3 所示。首先使用实体链接技术[10]将文本中的疾病特征词w1:n与MedKG 中的三元组候选病症实体head或tail(统一记为实体e)进行实体相似性计算以消歧,获得MedKG 中的相关实体知识;其次在此基础上构造疾病知识子图(subgraph of MedKG,sub-MedKG),即根据获得的实体提取子图中所有与实体相连的关系relation;最后利用2.2 节介绍的知识图谱嵌入TransD模型对sub-MedKG 进行表示学习,将学习到的实体向量作为KGDeL 模型中CNN 层的输入。
虽然大多数知识图谱嵌入方法在实体、关系向量化过程中可以保存原始图谱的结构信息,但在后续疾病特征学习过程中,这种单个实体的知识嵌入信息仍然是有限的。由于上下文实体在图谱中的语义关联和逻辑结构都与当前实体有着密切关系,因此本文为每个实体提取额外的上下文信息,实体e的“上下文”定义为其在MedKG 中相邻的一跳结点集合,即:

其中,r为实体间关系,使用上下文实体可提供更多的补充知识,提高实体可识别性。
例如,对于病情描述语句中出现的疾病特征词“咳嗽”,图4 所示为一个包含上下文实体知识的sub-MedKG 示例,除了使用“咳嗽”本身来代表实体,疾病知识子图中还包括其上下文如“肺癌”(疾病)、“支气管炎”(疾病)、“吸烟”(病因)等作为它的补充信息。由于语义上越相近的词语,其映射在同一个向量空间中的实数向量会越相似,故对于实体上下文向量,可通过计算其所有上下文实体的平均值得到,相应计算公式如式(4):

Fig.3 Extraction steps of structured disease knowledge图3 结构化疾病知识提取步骤

Fig.4 Example of sub-MedKG图4 sub-MedKG 示例

其中,ei是上下文实体通过知识图谱嵌入方法学习得到的实体向量。最后在实验部分验证了引入实体上下文向量的有效性。
3.4 知识驱动的卷积神经网络
由3.3 节结构化疾病知识提取可得,每个单词wi都有一个与之相对应的实体向量ei∈Rk×1、实体上下文向量∈Rk×1,其中k为实体嵌入的维数。对于每一段病情描述文本x=w1:n=[w1,w2,…,wn],使用其疾病特征词向量w1:n=[w1,w2,…,wn]作为CNN 层的输入,并引入词语-实体对齐后的实体向量:

与相关实体上下文向量:

作为输入。g是词语-实体对齐的转换函数,即:

其中,M∈Rd×k为变换矩阵,b∈Rd×1为偏差。由于转换函数tanh 是连续的,故它可以将实体向量与上下文实体向量从实体空间映射到词向量空间,并保持原来的空间关系。类似于图像RGB 通道,词向量w1:n、转换后的实体向量g(e1:n)与转换后的实体上下文向量具有相同的维数与大小,因此将这三个向量矩阵对齐并叠加便得到CNN 层的多通道输入:

应用多个不同卷积核尺寸的l来提取X中的局部特征模式。子矩阵对w的局部激活函数如式(9):

并在输出特征图上使用max-over-time pooling 操作来选择最大的特征:


其中,m为卷积核的数量。
3.5 疾病分类模型训练
将病情描述文本表示e(x) 输入给softmax 分类器,p(yk)为病情描述文本e(xk)在第k种疾病上的输出概率,经softmax 归一化后如式(12)所示:

其中,si与bi分别表示对应输出为yi的参数与偏置,n为疾病输出类别的总数。模型训练采用自适应矩估计(adaptive moment estimation,Adam)算法[11]来最小化目标函数,并通过反向传播来更新每轮迭代过程中网络的各种参数,直到模型达到拟合要求。
4 实验及结果分析
4.1 实验数据
本文实验数据由两部分组成,如表2 所示。一部分是从“好大夫”网站中爬取的已经确诊的8 类疾病描述文本数据集,包括糖尿病、高血压、肺癌、肠胃疾病、牙周病、妇科肿瘤、支气管炎和甲状腺疾病,其中训练集数据6 400 条,测试集数据1 600 条,验证集数据800 条。

Table 2 Experimental dataset表2 实验数据集
另一部分是医学知识图谱MedKG,采用的是华东理工大学构建的中文症状库,它以垂直型医疗健康咨询网站、中文百科网站和大量电子病历为数据来源,以疾病为侧重点包含了1.3 万余条的症状实体与3.2 万余条的疾病-症候-特征相关三元组数据的知识图谱,图谱中也对应的有上述8 类疾病的症状实体知识。
由表2 中统计数据可知,每段病情描述文本的平均长度为56 字,相应文本中的疾病特征词平均有7个,这表明病情描述文本中几乎每4 个字就有一个疾病实体,与疾病相关实体的高密度出现也为KGDeL的设计提供了经验依据。
4.2 实验设置和评价指标
本文模型的参数设置如表3 所示。

Table 3 Model parameter setting表3 模型参数设置
本文实验采用准确度(Accuracy)、精度(Precision)、召回率(Recall)和F1值4 个指标[12]来评价疾病诊断方法的性能,相应计算公式如式(13)~式(16)所示:

其中,TP、TN分别表示正确分类下的正样本数与负样本数,FP、FN分别表示负样本误分类为正样本的数量、正样本误分类为负样本的数量。
为了研究模型中超参数的不同选择对KGDeL 性能的影响,本文采用控制变量法分别将输入向量维度、卷积核尺寸以及卷积核数量作为被测参数,其余参数值均按表3 设置,通过计算各自的精确度来确定最优参数值,结果如图5 所示。
由图5(a)可以看出,词向量维度d与实体向量维度k是由测试集合{20,50,100,200}组合确定的。当给定实体向量维度为k时,KGDeL 的性能会随着词向量维度d的增加而提高,这是因为词向量的维数越多,越可以编码出更多有用的语义信息。当d进一步增大时,KGDeL 的性能则会下降,因为过大的d(如d=200)可能会引入噪声,从而误导后续的预测。因此将本文模型的输入向量(即词向量、实体向量以及上下文向量)维度均设置为100 时模型性能最佳。

Fig.5 Effects of different selections of parameters on KGDeL图5 参数的不同选择对KGDeL 性能的影响
图5(b)所示,给定卷积核尺寸w,模型的准确度通常随卷积核数量m的增加而增加,这是因为卷积核越多越能在输入语句中捕获更多的局部模式,并增强模型功能。当m太大(m=200)时,可能会由于过拟合现象使得趋势发生变化。因此在CNN 层的多通道中分别采用{2,3,4}3 种尺寸的卷积核,并将每种尺寸卷积核个数均设置为150,以保证CNN 从不同维度提取多个文本特征。
4.3 实验结果分析
为了分析引入知识图谱结构化特征的影响,设计对比算法。算法包括:只包含词向量的传统卷积神经网络(CNN)、加入实体向量的卷积神经网络(CNN with entity embedding,Entity-CNN)、加入上下文实体向量的卷积神经网络(CNN with context embedding,Context-CNN)以及本文采用的KGDeL 算法(即同时加入实体向量和上下文实体向量的卷积神经网络)。为了分析不同知识图谱嵌入方法对KGDeL 融合模型的影响,结合2.2 节介绍的知识图谱嵌入方法,设计对比实验包括:TransE-KGDeL、TransHKGDeL、TransR-KGDeL 和TransD-KGDeL。表4 列出了这8 种算法实验的对比结果。

Table 4 Experimental results comparison in different structures of KGDeL表4 KGDeL 不同结构的实验结果对比 %
由表4可知,Entity-CNN、Context-CNN和KGDeL的分类准确度或精度等值均优于CNN,即在传统CNN 模型中引入知识图谱的实体向量或实体上下文向量,可以使得分类准确率分别提高1.3%或0.7%,这是因为医学知识图谱中包含着大量的疾病与症状实体,这部分知识的加入丰富了输入的语义信息,使得CNN 可以更好地学习疾病描述文本表示,并能综合考虑不同症状特征对疾病分类的影响,提升了算法的分类性能。通过KGDeL 和Entity-CNN、Context-CNN 的实验结果对比可知,同时引入知识图谱的实体和实体上下文向量所得的分类结果,要比只引入其中任何一种所得的结果好,其原因也正是由于图谱中的这两部分信息有着直接的关联关系,这种结构信息的加入增强了疾病的描述语义表示,提升了模型获取高层文本特征的能力,因此验证了本文算法中加入这两种知识向量的可行性和有效性。
对比表4 中KGDeL 使用知识图谱嵌入方法评价指标结果可知,本文使用TransD 方法进行知识向量化的效果最好。通过分析模型结构发现,TransD 是4种知识图谱嵌入方法中最复杂的模型,它能够更好地捕捉到结构化知识之间的非线性关系,减少向量化过程中的语义损失,从而学习得到实体以及实体上下文向量的质量较高,作为KGDeL 的输入时提高了疾病诊断分类性能。
基于特征方法、基于深度学习方法和基于疾病知识方法是目前解决疾病诊断问题常用的3 种方法,分别选取上述3 种方法中的一些经典算法与KGDeL进行对比实验。对比算法如下:Sun 等[11]提出的基于支持向量机的方法(support vector machine,SVM);Wu 等[13]提出的基于循环神经网络的方法(recurrent neural network,RNN);Zhang 等[14]提出的基于病情自述和知识图谱的方法(disease readme and knowledge graph,DRKG)以及Hu 等[15]提出的基于动态采样与迁移学习的方法(dynamic sampling and transfer learning,DSTL)。所有方法的实验参数选择对应参考文献中的最佳配置。表5 列出了这5 种算法实验对比结果。

Table 5 Classification performance comparison of different disease diagnosis methods表5 不同疾病诊断方法的分类性能对比 %
由表5 可以看出,传统SVM 的分类性能最差,基于RNN、DRKG 的疾病诊断方法都表现出较好的分类性能,这意味着相比深度学习算法,机器学习提取特征的方式与效率较低,并且SVM 算法结构本身就存在着优劣的更替。针对疾病诊断任务,RNN 与DRKG 算法更能从大量训练集中学习到数据的分布式特征表示。从准确率对比结果来看,DRKG 方法的分类准确率低于RNN 方法,而其F1值却高于RNN,这证明DRKG 在准确识别正向文本准确率方面要优于深度学习RNN 算法。KGDeL 的分类准确率最高,相比其他经典算法,KGDeL 表现出良好的分类性能,同时KGDeL 取得了最高的F1测度值。F1作为综合精度与召回率的一个有效评价标准,其优劣可以全面反映算法的性能,这进一步证明本文融合知识图谱结构化特征的KGDeL 方法相比传统方法优势更大,并且相比一些深度学习方法也具备一定优越性。为了保证实验的鲁棒性,进行了多种疾病的多次实验,本文方法的实验结果稳定,每种疾病的识别率都在85%以上。
同时,对KGDeL 方法在时间上的性能作进一步的分析,主要包括模型的时间复杂度以及疾病诊断所用时长两方面。模型的时间复杂度主要受数据量大小的影响,相较于传统算法,医学知识图谱主观数据的引入使得CNN 多通道特征提取、卷积运算等的计算复杂度增加,因此训练时长也会相应增加;并且模型训练时间的长短也与其硬件环境或操作系统有关。对于训练好的KGDeL 模型,当其在做疾病诊断处理新的病情描述特征时,所用时长会比训练时长少得多,并且由于其对主观客观数据的充分训练使得模型分类的准确率有所提高,因此从整体而言,对于疾病诊断任务,其诊断结果在准确性或精度上的性能往往比时间性能更为重要。
4.4 疾病诊断例子
实验按照4∶1 爬取训练集与测试集病情描述文本,使用有标签的训练集数据训练KGDeL 方法,并从病情描述文本集中抽取一些典型句子对比不同疾病诊断方法的分类结果,如表6所示。同时使用KGDeL方法对8 种疾病分类,并计算每种疾病的分类准确率、精度等指标,结果见图6。
由表6 不同疾病的分类结果对比可得,本文KGDeL 方法的整体分类结果可用于病情描述文本的辅助诊断中。根据进一步分析发现,其他疾病诊断方法将肺癌误诊样本多被判为支气管炎,将支气管炎误诊样本多被判成肺癌,而两种疾病也确实具有医疗联系,它们的临床症状多与吸烟、咳嗽有关。同样,在糖尿病和高血压中也有这种现象,二者受饮食与生活习惯的影响,在医疗中属于一种常见的并发性疾病。由图6 的评价指标结果值可知,牙周病与肠胃疾病的分类准确率是最高的,甲状腺疾病次之,原因是其各自的疾病特征较为明显,识别率高,并且多次实验结果稳定,KGDeL 可以根据这些疾病特征引入图谱中的相关知识,从而让模型学习到和训练集标注一致的分类结果,发现更多隐藏的疾病与疾病间的关系。

Table 6 Classification results of typical disease diagnosis examples表6 典型疾病诊断例子分类结果

Fig.6 Evaluation of discriminant results of 8 diseases图6 8 种疾病的判别结果评估
5 结束语
本文提出了一种融合知识图谱与深度学习的疾病诊断方法,通过加入医学知识图谱这一蕴含医生经验的主观知识,使得卷积神经网络在训练病情时通过描述文本客观数据,能够学习到更全面更直接相关的疾病特征。这种知识图谱结构信息的加入增强了疾病的描述语义表示,提升了模型获取高层文本特征的能力,从而提高了不同类型疾病的诊断准确率。通过对8 种疾病描述文本的分类识别,实验结果表明,本文提出的KGDeL 方法相比其他传统疾病诊断方法取得了更好的分类性能,提高了不同类型疾病的诊断准确率,更适用于初步诊断病情描述的疾病。在下一步工作中,可针对知识图谱嵌入方法进行深入研究,通过习得知识的高质量连续化表示,为深度学习更有效地提供结构化知识。
