优化分配策略的密度峰值聚类算法*
2020-05-13丁志成葛洪伟
丁志成,葛洪伟+
1.江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122
2.江南大学 物联网工程学院,江苏 无锡 214122
1 引言
聚类作为一种无监督的学习方法,是数据挖掘的重要分支,它通过将对象的属性按照某种特定的标准进行相似性划分从而将数据集分割为若干不同的簇类,最大化相同簇类内的数据属性相似度,并最小化不同簇类间的数据属性相似度[1]。在信息全球化的背景下,对于挖掘潜在、有价值数据的要求与日俱增,因此聚类在航天航空、市场分析、信息安全、人工智能、Web搜索等领域[2-3]得到了深入的研究与推广。
由于聚类分析有着极强的实用性与延展性,经过学者们的多年研究和努力,众多优越的相关算法被相继提出,其中较为经典的算法有:基于划分的Kmeans[4]、K-medoids[5]算法;基于网格的STING(statistical information grid)[6]、CLIQUE(clustering in quest)和WaveCluster[7]算法;基于层次的CURE(clustering using representatives)[8]、Chameleon[9]等聚类算法;基于密度的DBSCAN(density-based spatial clustering of applications with noise)[10]、OPTICS(ordering points to identify the clustering structure)[11]算法。
Rodriguez、Laio 于2014 年在权威期刊Science中发表了一篇关于新型的基于密度的聚类算法论文:快速搜索与发现密度峰值聚类(clustering by fast search and find of density peaks,DPC)[12]算法。DPC 算法的关键点在于:利用决策图手动选择密度峰值作为所需要的聚类中心点,随即将剩余点分配给与之距离最近的聚类中心点所属类簇,最后对分配结果进行噪声识别从而完成聚类。与大部分经典的基于密度的算法相比,该算法简洁高效,无需迭代,只需一个截断距离参数dc,能够发现数据集中所有任意形状的簇类并且可以有效消除离群点。尽管如此,DPC算法依然容易在分配复杂结构数据集数据点时出现错误,导致聚类效果不理想。
针对DPC 算法存在的缺陷,Xu 等人提出了基于γ线性拟合的DenPEHC(density peak based efficient hierarchical clustering)密度峰值聚类算法[13],利用γ排序图的变化趋势产生了自适应的聚类中心并改进了聚类分配机制,但在高维数据处理上容易出现错误聚类。Xu 等人提出了分别基于网格划分和圆划分的密度峰值聚类算法GDPC(density peaks clustering algorithm with gird-division strategy)和CDPC(density peaks clustering algorithm with circle-division strategy)算法[14],两者都优化了密度峰值的聚类分配。GDPC算法耗时更少而CPDC 算法在大型数据集上具有更高的准确率,但在处理复杂结构数据集时会出现分配错误的情况。金辉等人提出了自然最近邻优化的
TNDP(optimized density peak clustering algorithm by natural nearest neighbor)算法[15],利用自然邻居概念计算数据点的局部密度,再使用类簇间相似度合并簇类,算法虽然有较优的聚类效果,但无法很好地识别数据集噪声。
因此,本文针对以上算法的缺陷,提出一种优化分配策略的密度峰值聚类算法(density peaks clustering with optimized allocation strategy,ODPC)。新算法利用相似度指标MS分配对象数据集的数据点,然后通过dc近邻法重新界定边界区域中的噪声点。实验证明,在数据集对象存在高维数据、复杂数据结构、噪声数据的情况下,新算法可以得到更优的聚类结果。
2 DPC 算法及其缺陷
DPC 算法将符合以下特征的数据点对象定义为密度峰值点即聚类中心:被拥有相对较低局部密度的邻居点所环绕并且此类数据点和其余拥有相对较高密度的数据点间有较大的距离。算法仅需要截断距离dc这一个输入参数,通过人工选取聚类中心点,一步完成所有数据点的聚类与分配。
对于任意数据点Xi,DPC 只需要计算其局部密度ρi以及距离具有更大密度的点的最短距离δi这两个变量。
局部密度ρi为以dc为半径的范围内其余数据点的数量:

式(2)中,di为所有点间的欧式距离的升序排列;N为数据总量;M=N(N-1)/2;round函数表示对M×P/100 四舍五入取整;P为可调参数,DPC 原文中选取P值为2。
δi为距离具有更大密度的点的最短距离:

式(3)中,对于数据集最高密度的数据点K,默认它为数据集的聚类中心点并令其δk为所有距离中的最大值,即δk=max(dij)。
在得到数据点的ρi和δi值后,DPC 算法首先生成相应的决策图并将同时具有较大ρ和δ值的点视作聚类中心,然后将非聚类中心点依次分配给最接近的聚类中心点所在簇,最后对聚类结果进行噪声识别,完成聚类。DPC 算法为识别出聚类结果中的噪声点,引入边界区域密度ρb的概念:在某簇内却与属于其余簇的点距离小于截断距离dc的数据点中局部密度最大值。而在簇中局部密度ρi大于边界区域密度ρb的数据点被认为此簇的核心点,反之则视为该簇的噪声点。
尽管DPC可以快速高效地完成聚类,但是算法仍存在一些缺陷:只有当数据点的ρ和δ值同时大的情况下,该数据点才有可能被选为聚类中心点;对于复杂结构的数据集来说,仅仅通过将数据点分配给距离最近的聚类中心点所属簇类容易出现错误的聚类结果;在噪声识别阶段,直接通过边界区域密度对核心点及噪声点进行一次性的划分也并不是较优的方法。
综上所述,DPC 算法在面对以下三种情况时仍然会出现较大的误差:
(1)由于DPC 算法分别单独考察ρ和δ的大小,仅当数据点在两值上均大于所选点时才会被确定为聚类中心点,而事实上仍存在部分ρ大δ小或者是ρ小δ大的数据点也为实际聚类中心。如图1 所示,DPC 算法仅识别到两个团状簇的聚类中心而没有发现环形簇的聚类中心。因此会导致数据集聚类中心点的少选、漏选。
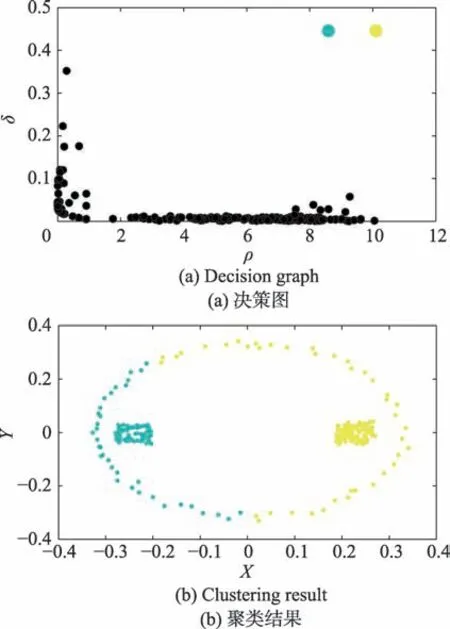
Fig.1 DPC gets less clusters by decision graph图1 DPC 算法通过决策图少选聚类中心
(2)当DPC 算法处理如流形数据集等具有复杂数据结构的对象时,会因为只考虑局部密度而无视整体结构一致性以及数据点间的连通性而导致在分配数据点所属类簇时产生相应的错误。如图2 所示,很明显,区域C和区域D的数据点应该归属于聚类中心点a所属类簇A类。而在DPC 算法中,由于C区域与D区域中的点距离B类聚类中心点b的距离比a更近因此都被分配到B类中,因此出现了如图2(b)的错误聚类。
(3)DPC 算法依据边界区域密度ρb的定义对数据集划分,从而实现聚类结果的噪声识别。算法会在噪声点较为密集、局部密度ρ较大的情况下将其错误地归类为核心点或是在核心点较为稀疏、ρ值较小时将核心点错误地识别为噪声点。如图3 所示,大量的核心点因此被错误地识别为噪声点。
3 优化分配策略的密度峰值聚类算法
3.1 优化的分配策略
定义1令γi作为判断点i是否为密度峰值点,即聚类中心点的参数指标:
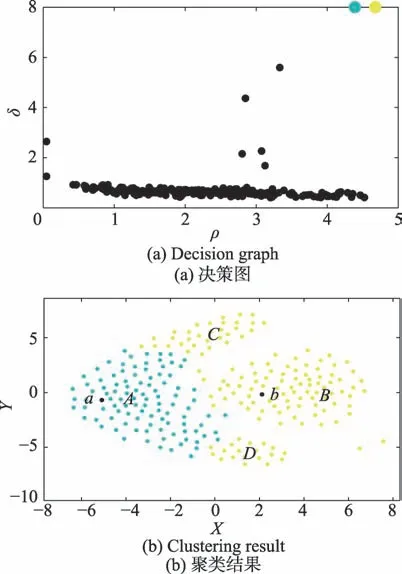
Fig.2 Wrong clustering results caused by allocation strategy of DPC图2 DPC 分配策略导致的错误的聚类结果
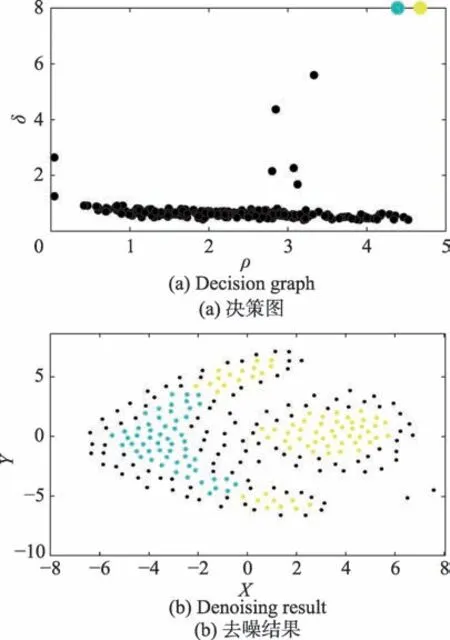
Fig.3 Bad denoising result caused by DPC图3 DPC 导致的不佳的去噪结果

对于拥有相对较大ρ或δ值的聚类中心来说,γ值同样也会取得较大值,因此γ值具有判断数据点能否为聚类中心的作用。记对象数据集为U(x),样本数据点总量为N,对所有数据点进行关于γ的降序排列γdes。在决策图上,将数据点的参数积γi大于被选点γ值的点视作聚类中心。
定义2令MS为衡量数据点间相似度的参数指标,称为相似度指标,其公式为:

本文借鉴牛顿万有引力定律[16]对数据点进行基于相似度的局部连通性分配。万有引力公式为F=,公式中M和m表示两个差异个体的各自质量,G为万有引力常量,r为个体间的距离,反映的是存在于力场中的任意两个不同个体间都存在着互相吸引的力,这个力与它们的质量成正比而和它们间距离的平方成反比,其本质是物体将力通过空间向四周传递,距离越长则传递的力越小。
参照自然界中物体间的吸引力作用,将之引申到数据结构空间中,可以发现数据空间中也有类似“场”的存在,其表现为:数据集中距离越近,密度越大,局部密度越相似的两点,其相互作用力越大,同样其相似度也越高。因此本文利用万有引力公式的变式来描述数据点间的相似度,式(5)中的G为相似度参数,ρi、ρj分别为数据集中任意两点的局部密度,而dist(i,j)则表示任意两点间的欧式距离。
在数据空间中,数据点默认体积一致,将其视作单位1,则质量M、m分别转化为局部密度ρi、ρj。由路网模型及其应用[17]可知,数据点所处区域的局部密度密切影响着点间相似度,并且在两点的局部密度越接近时,其相似度也越高,因此使用相似度参数G用以表示空间数据集的局部连通性。公式G=中,|ρi-ρj|用以表示不同数据点的局部密度差异,与其对应的相似度成反比,因此对公式的指数取反;引入ρmax-ρmin并使用e为底的指数函数以限制G的取值范围,因此式(6)最终为取值在[1/e,1]区间的相似度参数,其参数值与点间相似度成正比。相似度指标也最终根据万有引力公式变式为式(5)。
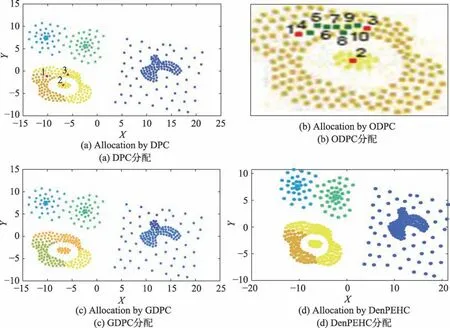
Fig.4 Clustering results caused by different allocation strategies of algorithms图4 不同的算法分配策略导致的聚类结果
DPC 算法中,利用数据局部密度ρi和该点到具有更大局部密度的点的最短距离δi两值确定聚类中心点后,直接依照距离簇中心的距离,将数据点归类为最接近的聚类中心点所属簇。而ODPC 算法使用优化的分配策略如下:首先通过式(4)计算所有点的γi值,将参数积γi大于选中点γ值的点作为聚类中心点;然后按照降序排列γdes的顺序,依次将γ值渐小的点分配给在已被分配簇类的数据点中,与其相似度最大的点所在的类簇,完成聚类。
以数据集Compound 为例,如图4(a)所示的DPC算法在数据集Compound 上的聚类结果,点1 和点2分别为两簇的聚类中心点,DPC 算法通过最近聚类中心点分配的方法将点3 与点2 错误地归于同一类。而在新算法ODPC 中,如图4(b)所示,点4 在已被分配类簇的数据点集合中与点1 的相似度指标MS值最大,因此两点被分为同一类。同理,点5 与点4,点6 与点5,点7 与点6,点8 与点7,点9 与点8,点10与点9,直到点3 与点10 都通过相似度指标MS归为同一类,因而点1 与点3 属于一类。依此类推,整个环状流形区域均被划分为一类,而中间的团状簇则被划分为另一类,因此ODPC 算法得到如图4(b)所示的正确聚类效果图。
3.2 优化识别噪声点
DPC 算法中,使用边界区域密度的概念对所有数据点进行统一识别,大于边界区域密度的点定义为核心点,反之则视作噪声点。这一策略容易导致分布较为稀疏的核心点或是分布较为稠密的噪声点被错误识别,如图5(a)所示,大量的核心点被错误识别从而降低了算法的鲁棒性。
分布较为稀疏的核心点与分布较为稠密的噪声点多出现于簇类的边缘区域,而这块区域与DPC 定义的边界区域极为相似。因此为了更好地识别数据集的噪声点与核心点,新算法对边界区域的数据点进行二次识别,有助于从健壮性角度提升ODPC 算法的聚类质量。由于初次识别后所有数据点都已经被划分为相应的核心点或是噪声点,本文参照K近邻算法[18],使用新的dc近邻法优化噪声识别。

Fig.5 Effect of different noise recognition methods图5 不同噪声识别方法的效果
定义3(dc近邻法)对以边界区域数据点i为核心,dc为半径的区域进行考察,若范围内噪声点更多则识别该点为噪声点,反之则识别为核心点。
根据DPC 中局部密度ρi的定义,本文通过dc近邻法引入边界区域噪声密度ρi′的概念,对边界区域的数据点重新识别噪声。
定义4定义边界区域i点的区域噪声密度ρi′为,以i点为核心,dc为半径的区域内噪声点比核心点多的数量,其计算公式为:

其中,对象数据集为U(x),噪声点集合为Ni,核心点集合为Co,j∈U(x)。对边界区域的数据点按照γ值降序排列的顺序进行重新分配,若ρi′≥0,i点的dc近邻中噪声点较多,将其划分到噪声点集合Ni中;若ρi′<0,则其dc近邻中有更多核心点,因此将i点划分到核心点集合Co中。将识别过程中未改变所属集合的点的集合作为新的边界区域,递归该识别过程直到边界区域不再发生变化,至此完成对边界区域所有数据点的噪声识别。以图5(b)中数据集Flame 的聚类效果为例,经过ODPC 的dc近邻法对边界区域噪声点的重新识别,流形簇和团状簇中均有更多分布较为稀疏的核心点被正确识别。不同于DPC 算法将噪声识别与算法聚类效果割裂开,ODPC 算法则是将数据对象中的噪声去除后再进行聚类效果分析,消除了数据集噪声点对聚类效果的负面影响,因此新算法在Flame 数据集上的两个聚类评价指标均为1,得到了完全正确的聚类结果。实验证明优化的噪声识别有着更好的准确性和抗干扰性。
3.3 算法步骤分析
输入:实验数据集U(x)={x1,x2,…,xn},数据点的邻居点数目占数据总数的比例P。
输出:聚类结果C={C1,C2,…,Ch},h为总簇类数量。
步骤1选取P值为2,根据式(2)计算出截断距离dc。
步骤2根据式(1)、式(3)分别计算数据集中所有点的局部密度ρi以及最短距离δi。
步骤3生成有关ρi和δi的决策图,根据式(4)得到的γ值在决策图上选取聚类中心。
步骤4根据式(5)、式(6)引入相似度指标MS,对关于γ的降序排列γdes中的非聚类中心点,进行依次分配:将未划分簇类的数据点分配到已归类并且相似度指标MS最高的点所在簇。
步骤5根据式(7)计算数据集边界区域点的边界区域噪声密度ρi′,若ρi′≥0,将i点识别为噪声点;若ρi′<0,则识别该点为核心点。
步骤6将识别过程中未改变所属集合的点作为新的边界区域,重复步骤5。
步骤7边界区域不再发生变化,完成噪声识别。
3.4 时间复杂度分析
假设聚类实验的数据集共有n个数据,由第2 章DPC 算法及其缺陷的描述可知,DPC 算法的时间复杂度主要由计算欧式距离(O(n2))、对欧式距离降序排列(O(lbn2))、计 算ρ和δ(O(n2)) 和去噪处理(O(n)) 组成。因此,DPC 的时间复杂度为O(n2)。而DenPEHC算法相较于DPC 算法,不同点在于:对γ降序排列(O(nlbn))和改进的分配机制(O(n2)),因此DenPEHC的时间复杂度为O(n2)。GDPC 算法的时间复杂度主要由网格化数据点(O(n))、快速排序移除稀疏网格(O(nlbn))、利用决策图聚类数据点(O(h2))、分配其余数据点至K个聚类中心(O(k(n-h)))组成,其中h为经过筛选的数据点(h<n),因此GDPC 算法的时间复杂度为O(n)+O(nlbn)+O(h2)+O(k(n-h))。而根据3.1节、3.2 节的描述,ODPC 相较于DPC 算法,不一样的步骤在于优化的分配策略(O(n2))和改进的噪声识别方法(O(n)+O(m2)),其中m为边界区域数据点数量,数值远小于n。因此,ODPC 的算法时间复杂度与DPC 算法一致,也为O(n2)。
4 仿真实验与性能分析
为验证ODPC 算法的效果与性能,本文分别在人工数据集以及真实数据集上进行实验分析。
4.1 人工数据集的实验结果与分析
仿真实验中使用到四个人工数据集,相关信息见表1。分别运行DPC 算法、ODPC 算法、同样优化分配机制的DenPEHC[13]和GDPC[14]算法,对表1 中数据集进行实验,实验结果如图6~图9 所示。
对于线状簇的数据集Spiral,如图6 所示,四种算法均能得到正确的聚类结果。对于Aggregation 数据集,由图7 可知,DenPEHC 算法利用γ线性拟合中出现的第一个异常增幅点,将数据集错误地分为八类;GDPC 将数据集错分为十类;DPC 与ODPC 算法则可以得到正确的聚类结果。而对于复杂数据集结构的Compound 数据集,如图8 所示,DenPEHC 与DPC 算法虽然得到了正确的六个聚类中心点,却在环形簇的分割上出现了错误,将其分成了两类;GDPC 算法则错误地将其分为七个类簇;而ODPC 算法由于使用了基于相似度指标MS的优化分配策略,使得算法能够在流形簇等复杂的数据集结构中通过局部连通使得聚类能够反映数据集的全局一致性,从而得到正确的簇类,并且提高了聚类准确度。在Flame 数据集上,DPC 算法则将流形簇两端的区域错误地分配给了团状簇,如图9(a)所示;而DenPEHC 算法通过基于γ线性拟合,ODPC 算法通过对数据点进行相似度连通分配,GDPC 算法通过对数据点的网格单元映射分别可以取得如图9(b)~图9(d)所示的正确聚类效果。综上所述,在人工数据集上,ODPC 算法较之DPC、DenPEHC 和GDPC 算法,可以提高密度峰值聚类算法的准确度,得到更优的聚类结果。
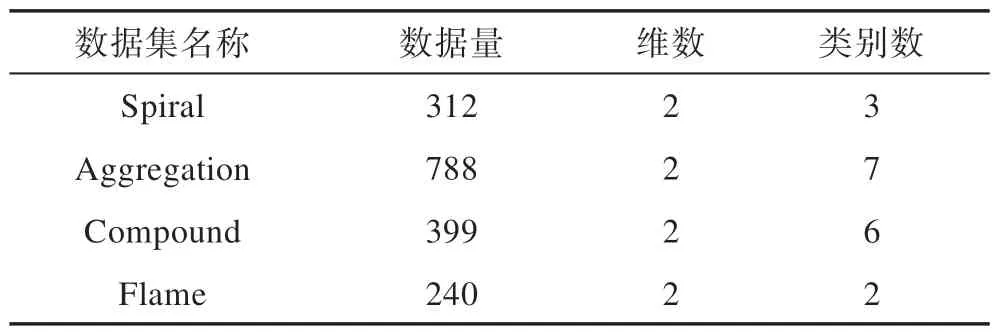
Table 1 Four synthetic data sets表1 四个人工数据集信息

Fig.6 Clustering results of Spiral by four algorithms图6 四种算法在数据集Spiral上的聚类结果
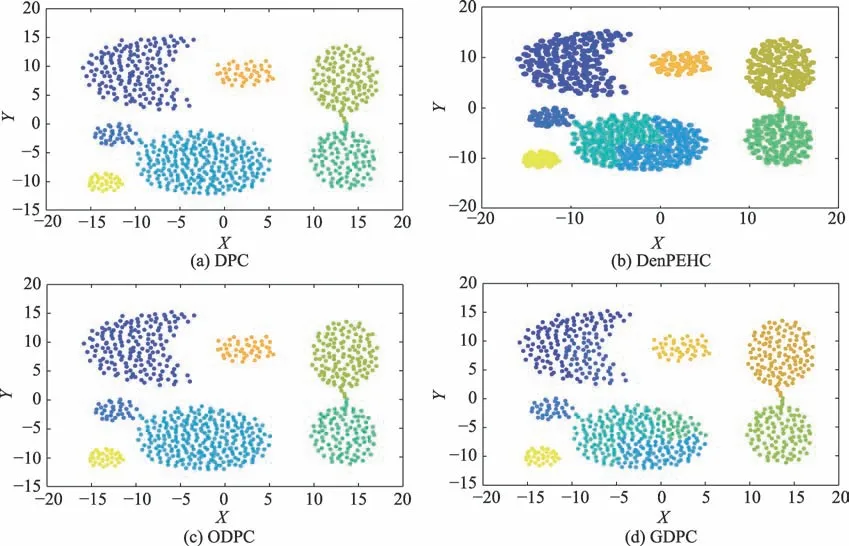
Fig.7 Clustering results of Aggregation by four algorithms图7 四种算法在数据集Aggregation 上的聚类结果

Fig.8 Clustering results of Compound by four algorithms图8 四种算法在数据集Compound 上的聚类结果
Fig.9 Clustering results of Flame by four algorithms图9 四种算法在数据集Flame上的聚类结果
4.2 真实数据集的实验结果与分析
为进一步验证ODPC 算法的性能与效果,本文采用F-measure[19]与ARI[20]两类聚类评价指标并利用表2中的五个真实数据集对DPC算法、基于γ线性拟合的密度峰值算法DenPEHC、基于网格划分优化的密度峰值算法GDPC 和本文的ODPC 算法进行对比实验。
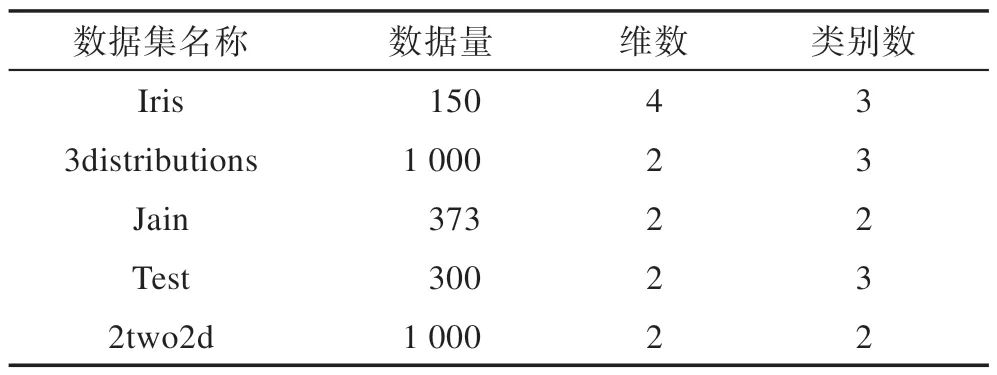
Table 2 Five real data sets表2 五个真实数据集信息
两类评价指标F-measure 的取值在0 到1 之间,而ARI 的取值范围为-1 到1,在取值范围内评价指标值越接近1 则表明聚类效果越佳。实验结果如表3、表4 所示。
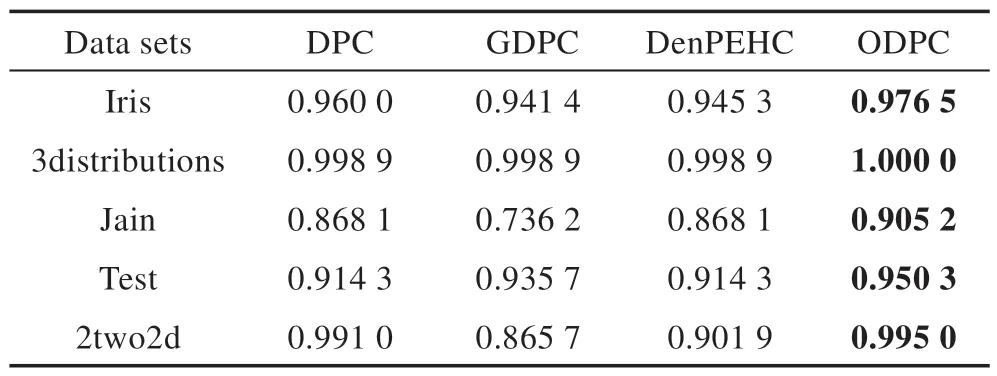
Table 3 F-measure index value of four algorithms on real data sets表3 四种算法在真实数据集上的F-measure值
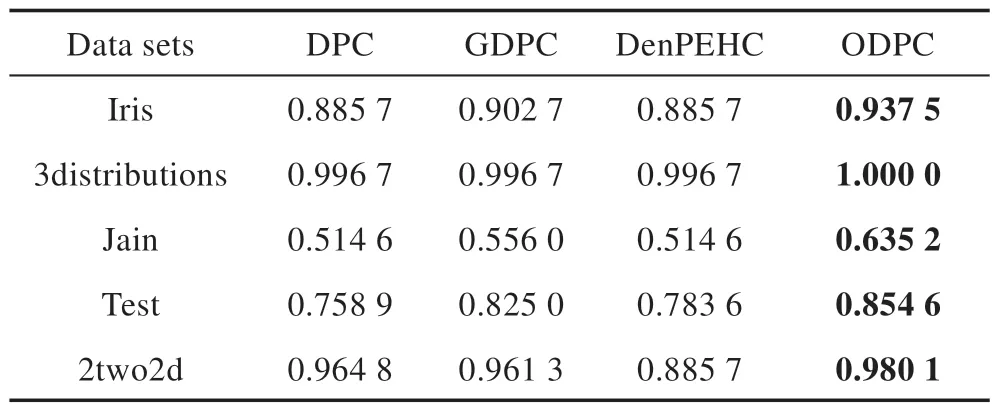
Table 4 ARI index value of four algorithms on real data sets表4 四种算法在真实数据集上的ARI值
由表3、表4 的聚类实验结果可知,在两类聚类指标值上,ODPC 算法在所有五个真实数据集上均能取得四种算法中的最大值。DPC、DenPEHC、GDPC 算法尽管在部分数据集上的聚类结果较好,但在面对具有复杂结构的数据集时,数据点更容易被错误分配,聚类效果不如ODPC 算法。因此整体来看,ODPC 算法是其中最优的算法。
综上,ODPC 算法对DPC 算法进行了成功的优化改进,在人工以及真实数据集上的仿真实验可以有效说明算法能够获得更好的聚类分配效果。
5 结束语
为了解决DPC 算法在面对复杂结构数据集时容易出现分配错误的问题,本文提出了一种优化分配策略的ODPC 算法。新算法参考万有引力公式,利用基于相似度指标的MS值对数据集数据点进行更加科学合理的连通性分配;使用dc近邻法对边界区域的数据点进行优化的噪声识别。通过实验证明,新算法在保留原DPC 算法简单高效的同时,能够获得更好的聚类分配和更优的噪声识别效果。
由于ODPC 算法没有实现对聚类中心的自动选择,在实际运用时会造成额外的时间成本。但是算法引入γ扩大了聚类中心的范围以避免漏选潜在的密度峰值点,通过算法的多次运行来确保聚类中心选取的正确性和有效性。尽管如此,在实际应用时辨别数据对象是否被正确划分依然会受到人为判断和经验值的影响。因此,如何使ODPC 算法在保证准确率的同时自动选取聚类中心,将会是下一步的研究方向。
