GRU-BP在数字化车间关键部件寿命预测中的研究
2020-05-12郝俊虎崔宁宁韩丰羽徐崇良
郝俊虎,胡 毅,崔宁宁,韩丰羽,徐崇良
1(中国科学院 沈阳计算技术研究所, 沈阳 110168)
2(中国科学院大学 计算机与控制学院,北京 101408)
3(沈阳高精数控智能技术股份有限公司, 沈阳 110168)
E-mail :ekkohao@126.com
1 引 言
大数据的发展正驱动着传统数控车间的数字化和智能化变革,其研究的本质在于探测事务无法被直接观测的内在规律,从而对事务未来的发展方向进行预测.工业4.0可以通过应用大数据处理方法,数字化系统,以及更多面向未来的智能技术等使数字化车间变得智能化.然而,数字化车间的高复杂性、高自动化和灵活性给数控设备的可靠性和安全性带来了新的挑战.
预测性维护作为数字化车间制造维护的重要组成部分,在调度、维护管理和质量改进中起着至关重要的作用[1].数字化车间安全保证中最重要的环节是故障的排查和维修,但是目前故障的排查和维修都是需要在停机的状态下完成,这不仅可能会影响生产加工的进度,还可能会增加人工干预的风险.人工排查和维修还有一个最难解决的问题是检查周期的选择,周期过短则会影响机器的正常运行,周期过长又会增加生产的风险.如果能够对数字化车间关键设备的关键部位的剩余使用寿命(RUL)进行预测,那么将会极大的改善这个问题.
数字化车间的部件或系统的RUL定义为从当前时间到该部件或系统使用寿命结束时的长度[2].RUL预测可以看作是数字化车间安全运行的基础,自提出以来受到了大量的研究学者对其预测方法进行研究.Camci[3]和Liao[4]等人将剩余使用寿命预测分为了基于数学和物理模型的、基于经验的和基于数据的三种方法.基于数学和物理模型的的方法需要构建退化的物理故障模型,例如裂缝,磨损,腐蚀等.物理模型对于在没有足够数据可用的情况下解决RUL问题非常有用.在这种情况下,通过物理模型结合实际数据学习出RUL估计模型,可以很大程度上减少故障的发生.但是,这种物理故障模型非常复杂且难以构建,并且许多部件可能也并不存在物理模型,所以这种方法很难应用于复杂的系统.基于经验的包括专家系统和模糊逻辑理论,这种方法非常依赖经验的准确程度以及经验知识的多少,需要大量的经验积累和总结.基于数据的方法则不需要探索和理解繁琐的机械工作原理,只需要采集足够的数据用于模型训练和预测即可.即对于具有足够退化数据的设备,使用传感器数据和操作条件数据来估计RUL的数据驱动方法是优选的且有效的.在数字化车间中,这些数据也相对容易收集,为数据驱动方法提供准确的RUL估计提供了坚实的支持.
多种预测剩余使用寿命的方法近年来被需多研究学者提出并验证.陈雄姿等人[5]提出了使用贝叶斯最小二乘支持向量回归的时间序列预测模型,通过NASA的公开数据集做对比实验,证明了这种基于贝叶斯的改良方法在预测准确度是十分高的,但是由于模型对计算效率的要求,这种方法无法处理大数据条件下的预测.豆金昌等人[6]提出了使用ARIMA自回归模型和粒子滤波(PF)预测剩余使用寿命的框架,将粒子滤波应用于更长时间的预测,使得该框架在长期和短期预测中都有较高的正确率,但该方法也并没有考虑时间序列的输入顺序对预测结果的影响.
源于人工神经网络的深度学习具有很强的学习能力[7],使得深度学习在很多方面都极大地改进了现有技术.张国辉[8]提出了一种深度置信网络的时间序列预测方法,验证了深度置信网络在时间序列预测上的可行性,但是并没考虑实际应用中模型训练需要动态更新的问题;高育林[9]提出了一种基于深度学习的多模态剩余寿命预测方法,研究了多模态在描述准确性中的提高方法,并着重解决了传统深度学习的精度不足的问题,成功将多模态下的深度学习网络进行有效训练并进行预测,但是多模态模型需要准确的对数据模态进行分组归类,面对没有明确分组的数据该模型无法使用.Yan等人[10]为了减少专家经验和人类决策对预测的影响,提出了一种设备心电图(DECG)的概念和一种基于深度去噪自动编码器(DDA)和回归操作的算法来预测工业设备的剩余使用寿命.
2 RUL预测系统架构设计
本文将数字化车间关键部位的RUL预测分为两个阶段,分别为采集阶段和分析预测阶段.采集阶段从加工中的数控车床采集数据,如刀具和轴承可采集的信号有振动、温度、空间位移、切削力以及主轴电流等.采集得到的数据将用于分析预测阶段,该阶段首先对数据进行预处理,需要处理的情况有缺失值、异常值以及信号中的噪音.然后通过特征提取和特征选择得到与RUL预测最相关的特征.最后输入进选定的模型进行训练和预测.
图1描述了用于数字化车间关键部件RUL预测的系统架构.如前所述,分析预测阶段包含了五个步骤.第一步为对信号的预处理,一般是对信号的异常值进行检查,但对于设备采集的信号,如振动等信号,一般还要包括降噪的过程,本文使用了小波降噪的方法进行降噪.第二步为特征提取,一般采集到的信号都是时域的,很多频域和时频特征不能直接拿到,也无法观测,所以还要经过频域和时频域转换来挖掘更多特征,本文使用了傅里叶变换和小波包变换来完成此项工作.第三步为特征选择,经过第二阶段得到的特征可能是几十维甚至上百维,所以要通过相关分析或主成分分析等一些可以降维的方法来选择与目标结果最相关的特征.第四步为模型训练,经过前面几步的处理,得到的数据已经满足训练的要求,把这些数据输入进合适的模型来训练,这个过程最常见的问题之一就是过拟合,改善的方法就是优化结构风险和增加训练数据.最后一个阶段为预测阶段,即应用模型来完成预测,并根据预测结果做出相应的建议.
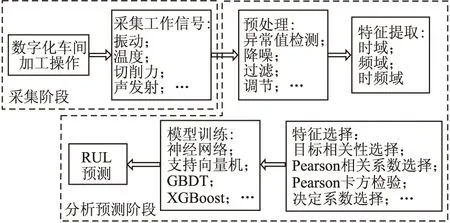
图1 RUL预测系统架构
3 理论基础
3.1 BP神经网络
传统的BP神经网络是经典的3层模型.第一层是输入层,它用来接收自变量,其神经元个数由具体的预测输入维度决定.第二层为隐藏层,该层的神经元个数可任意.最后一层为输出层,为最终的预测结果.BP网络的训练过程首先由输入层计算出前向传播的输出,然后根据输出层的误差反向调整各层连接的权重.
3.2 门限循环单元
门控循环单元(GRU)是由Cho和Chung等人提出的一种深度学习网络[11].GRU是对长短期记忆网络(LSTM)在计算效率上的改进算法,它们的共同基础是循环神经网络(RNN).RNN改进了传统的神经网络没有考虑输入时序相关性的问题.RNN网络隐状态的值不仅仅取决于当前计算时序的输入,还与前一个计算时序的隐状态有关.隐状态和输出值的计算公式如式(1-2)所示.
Ht=σ(U*Xt+W*Ht-1)
(1)
yt=Softmax(V*Ht)
(2)
式(1-2)中σ为sigmoid激活函数,U为输入层到隐藏层权重向量,V为隐藏层到输出层权重向量,W为时间序列计算向量.RNN最大的改进是把前一次计算的信息带到当前的计算过程,但是,当两次计算的时间帧相距过远时,需要十分苛刻的设置RNN训练参数才能使长距离的时间信息被计算到,这种苛刻的条件实际计算时很难达到,一般将这种问题称为长期依赖丢失问题.
Hochreiter和Schmidhuber提出的LSTM[12]旨解决RNN存在的长期依赖丢失的问题,它可以认为是一种能够学习计算时序中的长期依赖性的特殊的RNN.RNN在时序计算中仅简单的将上一步的输入作为下一步的输入,LSTM对此做出了改进.LSTM的核心是设计了一个记忆单元的用来存储长期记忆,在时间序列的训练中,记忆单元的值缓慢更新.每个LSTM单元接收三个输入,一个是当前时序的输入,另外两个输入是由前一时序的计算结果而来,一个结果保存了长期记忆,它在每次计算中仅作比较小的更新,另一个结果保存了短期记忆,完全由上一时序的输入决定.LSTM网络通过将新的信息递增地添加到单个存储器槽中来处理可变长度序列x=(x1,x2,...,xn),使用门来控制信应该记住的新信息,应该删除的旧信息,以及应该暴露输出的当前信息.LSTM的内部结构如图2所示.

图2 LSTM内部结构
图2描述了在计算时序t,记忆状态和隐藏状态的计算过程.图中从下往上第3层为3个控制门f、i和o,它们的值范围都是0到1,0代表着完全删除信息,1代表完全保留该信息.f为忘记门控,用来从上一步的记忆单元忘记不需要的信息.i为输入门控,用来从输入中选择需要更新的信息,其右边的tanh激活函数则是用来创建新的记忆候选项.o为输出门控,用来从tanh激活的记忆单元中输出当前需要的信息.记忆状态和隐藏状态的具体公式如式(3-5)所示.
(3)
(4)
ht=ot⊙tanh(Ct)
(5)
式(3-5)中,i、f和o是控制门,⊙表示哈达玛乘积.结合内部结构和上述公式就可以理解LSTM与经典的RNN网络的不同,LSTM保持了额外的记忆状态更新,将记忆状态与预测时与时序环境相互作用的隐藏状态分开.但也可以看到,LSTM的计算是较为复杂,导致其计算速度慢,训练耗时较长.针对这个问题,GRU设计了重置门和更新门来简化LSTM的结构.


图3 GRU内部结构
(6)
Zt=σ(xtWxz+ht-1Whz+bz)
(7)
式(6-7)中,W为权重参数,b为偏差参数.更新门和重置门也是通过sigmoid激活得到,所以它们的取值范围也是从0到1,0同样代表着完全删除信息,1也同样代表完全保留该信息.重置门的作用在于删除预测无关信息.GRU在计算隐状态之前,最重要的一部是首先计算出一个候选隐状态,它是从两部分得到,一部分是上一时序的隐状态与重置门的哈达玛乘积,另一部分是当前时序的输入,这两部分作为输入经过tanh激活得到候选隐隐状态.总结其计算公式如式(8)所示.
(8)
从式(8)中可以看出,重置门是用来控制上一计算时许隐状态的值对当前输入的影响,上一时序的隐状态包含了长期记忆和短期记忆(上一时序的输出)两部分,经过重置门控制后可以将这两部分中的垃圾信息(以后预测不再使用的信息)删除.然后与当前时序的输入Xt一起求和并经过tanh激活就得到了候选隐状态,从名字上就可以看出,候选隐状态的计算是为下一步得到真正的隐状态做准备.
最终当前时序的隐状态由两部分求和得到,一部分是经过更新门更新的上一时许的隐状态,另一部分是更新门更新的候选隐状态.其计算公式如式(9)所示.
(9)
综上,可以总结GRU单元的计算分为4步.第一步,使用重置门删除上一时序的隐状态中的与之后预测无关的信息,第二步,第一部分得到的结果同当前时序的输入一起经过tanh激活得到候选隐状态.第三步,使用更新门的带经过遗忘后的上一时序隐状态,第四步,将第三步的结果结合候选隐状态最终得到当前时序的隐状态.
4 RUL预测模型
本文的RUL预测模型输入为时序多维特征,输出为单维预测序列,是典型的多对一结构.为充分使用输入提供的时间序列信息,设计了一种多对一的双GRU神经网络模型,其结构如图4所示.
图4中的神经网络模型共包括6层,各层的输入输出参数中,B为Batch个数,T为时序数,I为输入的特征数,O为输出向量长度,U为隐藏层个数.RUL预测模型是个多对一的模型,所以输出长度O为1.第1层为GRU层,输出全部时间序列的结果;第2层为TimeDistributed层,是对第一层结果在每个时间序列上进行多对多的映射,用来提高单个时序内的学习能力;第3层为第二个GRU层,用来增强时间序列信息,但只输出最终的时序结果;第4层为Dropout层,用来丢弃某些输入,防止过拟合;第5层为全链接层,选用relu激活函数,其作用为保证学习率的情况下降低隐藏层个数;第六层为全链接层,也是最终输出层,输出为1维.下一节将使用此模型训练神经网络,然后使用训练好的神经网络预测刀具和轴承的RUL序列.

图4 基于GRU-BP神经网络的RUL预测模型
5 仿真实验
5.1 数据来源
1)铣削刀磨损数据.本为使用的铣削刀数据来源于PHM 2010 Data Challenge.该数据集包含6个6mm球鼻碳化钨钢刀的工作数据记录,分别用c1,c2,…,c6表示,取前4组作为训练数据,后2组作为测试数据.每个刀具反复用于切割同一类工件,主轴转速为10400RPM,进给率为1555 mm/min,横向切深为0.125 mm,纵向切深为0.2 mm,采样率为50 KHz进行实验.每次切割0.001 mm后测量刀具三个凹槽的磨损.此外,使用测力计测量X,Y,Z三个轴方向的切削力.三个加速度计用于测量X,Y,Z方向上的切割过程的振动.声发射(AE)传感器用于测量切割过程中工件的声学特征(AE-RMS).每组刀具数据包含315个切割文件,包含X轴切削力、Y轴切削力、Z轴切削力、X轴振动、Y轴振动、Z轴振动、声音信号RMS以及每次切割后产生的三个凹槽的磨损数据.
2)轴承退化数据.本文使用的轴承数据来源于法国国家应用力学实验室FEMTO-ST为IEEE PHM 2012 Prognostic challenge 提供的比赛数据[13].该数据由PRONOSTIA平台完成实验,共提供了17个轴承全部生命周期的温度和加速度数据(包括径向水平和垂直两个方向).每组数据包含约7万行温度数据和约180万行加速度数据.每个测量值都以100Hz的频率测量.振动传感器由两个微型加速度计组成,彼此夹角成90°,分别位于垂直轴和水平轴上.两个加速度计径向放置在轴承的外部通道上.加速度的采样频率为25.6kHz,温度采样频率为0.1Hz.17个轴承被分成三组负载进行实验,其中一组有7个实验轴承,负载为1650rpm转速和4200N径向力,分别将它们编号为b1,b2,…,b7,本文选取此组轴承的b1到b5作为训练组,b6和b7作为测试组数据进行实验.
5.2 小波降噪
刀具和轴承工作于数字化车间的关键部位,在高精度加工过程中,传感器获取到的信号往往含有噪声.因此,在正式分析数据之前,降噪是一个非常必要的过程.本文对刀具3个轴的振动信号和轴承2个方向共5组振动信号进行小波降噪,结合采集数据的实际环境,振动信号的噪声频带和有效频带未知,经过比较最终选用小波系数阈值法完成降噪.小波基函数选取了Daubechie、Coiflets和Symlets三种来对比效果,分解层数为5.阈值的选择采用启发式阈值选择方法,考虑到软阈值和硬阈值都有欠缺之处,转而采用了一种软硬阈值改良折衷法[14]来调整阈值.该改良方法在阈值附近接近硬阈值法,在向无穷大增长的过程中接近软阈值法.选用信噪比(SNR)衡量去噪效果,其计算方法如公式(10)所示.
SNR=10lg(ps/pn)
(10)
式(10)中,ps为有效信号的功率,pn为纯噪声信号的功率.表1为刀具3个轴振动信号在小波Daubechie、Coiflets和Symlets各个阶数时的平均信噪比.
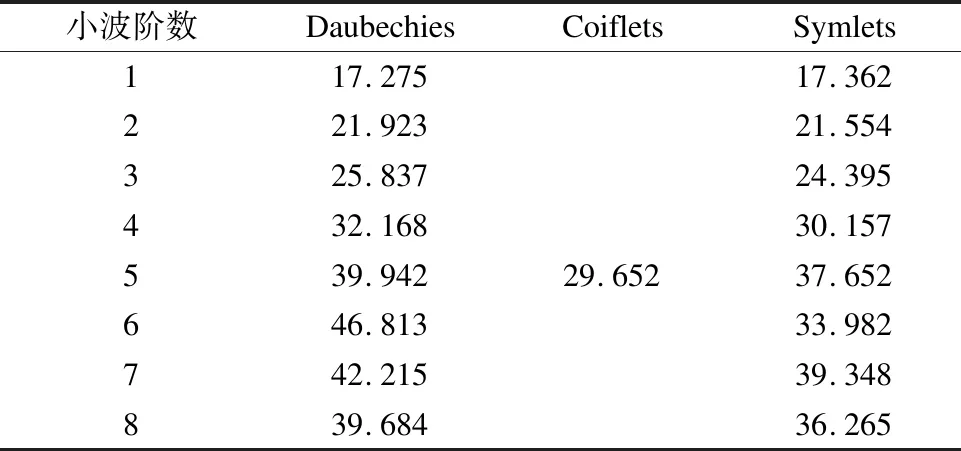
表1 Daubechie、Coiflets和Symlets各个阶数的信噪比
表1可以看出,使用db6小波降噪时的平均信噪比最高.图5显示了该小波在c1刀具x轴上的降噪效果.

图5 刀具c1在x轴方向降噪前后比较
5.3 特征提取和选择
完成信号降噪后,接下来就是分析并提取与刀具和轴承的RUL结果相关的特征.其步骤是首先提取特征,提取的维度包括时域特征、频域特征和时频域特征三个方面,然后再选择与预测结果最相关的特征集合[15].
1.3 评价指标 ①急诊效率指标:包括就诊至首次球囊扩张(DtoB)的时间和介入治疗前谷草转氨酶(AST)、乳酸脱氢酶(LDH)、肌酸激酶(CK)、肌酸激酶同工酶(CK-MB),均采用全自动生化分析仪器检测;②治疗7 d后采用心尖四腔切面彩色多普勒超声检测患者的心功能E峰值、左心室舒张末期直径(LVEDD)、E/A值及左心室射血分数(LEVF);③治疗7 d后测定氨基末端脑钠素前体(NT-proBNP)的水平;④治疗7 d后采用问卷调查评估患者的满意度,包括心理护理得分、生理护理得分、护理服务得分,满分为100分。
时域特征本文选取了均值、方差、标准差、偏度、峰度、均方根、峰-峰值、峰值因子、脉冲因子和裕度因子等十个维度.频域特征使用功率谱密度(PSD)来提取.获取PSD的直接方法是求傅里叶变换在一较大的时间间隔内幅度的平均值,但更简单的方法是直接通过信号的自相关方程进行傅里叶变换得到,本文使用的就是后一种方法.
时频域特征是特征提取时一个非常重要的考量方面,其对象主要是非平稳信号.小波包变换是提取时频域特征的一个非常合适的选择,它是连续小波变换和离散小波变换的折衷方法,计算效率和分辨率精度都满足要求.如图6为刀具c1的5级小波包分解图:
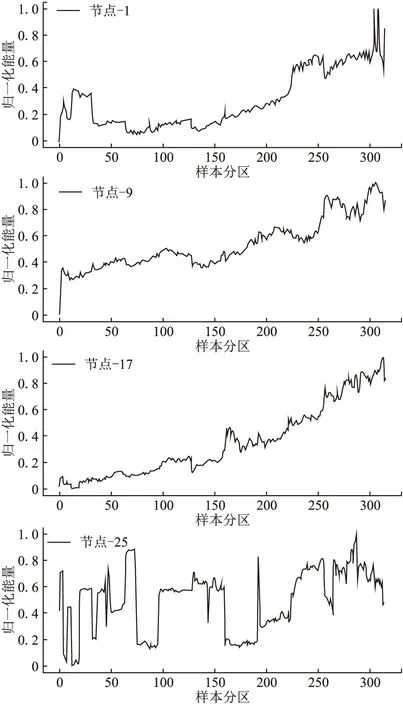
图6 5级小波包分解各节点的能量变化
图6中可以看到左上和右下两个图内的节点能量变化和剩余使用寿命的负相关性最强.图中还可以看到某些子节点的能量较高,说明这个节点对应的频段为能量的集中区域.小波包分解总共分解的到25个频段节点,将这32个节点的节点系数的归一化能量作为提取的时频域特征.
通过前面的特征提取,每个轴向通道分别分别获取了10个时域特征,7个频域特征以及32个时频域特征,共49个特征.刀具的振动信号有xyz三个轴向通道,轴承有径向水平和垂直两个轴向通道,所以刀具和轴承分别共有147和98个特征.这个特征数是非常庞大的,需要进一步选择出与RUL最相关的特征用于预测模型.本文使用Pearson相关系数来进行特征选择.分别计算刀具147个特征和轴承98个特征与剩余寿命相关性.刀具的每个候选特征与剩余寿命的相关性取4组用于训练的数据的平均值作为相关系数参考值.同样的,轴承的每个候选特征与剩余寿命的相关性取5组训练数据的平均值作为参考值.最终选取相关系数绝对值大于0.95为输入特征.
最终选择出的刀具输入特征有,x轴的小波包节点6、节点11、节点16和节点17,y轴的小波包节点7、节点10和节点11,z轴的小波包节点1和节点8,以及z轴的方差、标准差和均方根,总共12个特征.
最终选择轴承的输入特征有,x轴的小波包节点7、节点12、节点14和节点18,y轴的小波节点20和节点21,总共6个特征.
5.4 模型训练与预测
经过前面降噪和特征分析得到了用于模型训练的特征.将6组刀具的数据进行分区以便于提取特征和训练模型,最终选择用于训练的数据有25200行,用于训练的数据有12600行;同样对轴承的数据进行分区特征分析,得到6150行训练数据,1500行测试数据.将训练数据输入进模型进行训练.模型训练使用的损失函数为均方根误差,优化器算法采用自适应矩估计优化法.经过网格搜索超参数法,得到刀具和轴承RUL预测模型的参数如表2所示.

表2 RUL预测模型参数
将前面训练好的模型分别对刀具和轴承的测试组数据进行RUL预测,最终的结果如图7所示,其上半部分为刀具c5和c6的RUL预测结果,下半部分为轴承b6和b7的RUL预测结果.四个预测曲线图中,前20-50的样本区域误差相对其他区域稍大(推测可能的原因是此时部件工作处于磨合期),其余区域预测值和真实值的误差基本在50s以内.如果将剩余10%寿命作为维修报警的阈值,刀具和轴承分别在1250、1400、580和650样本区报警.整体上预测结果达到预期效果.
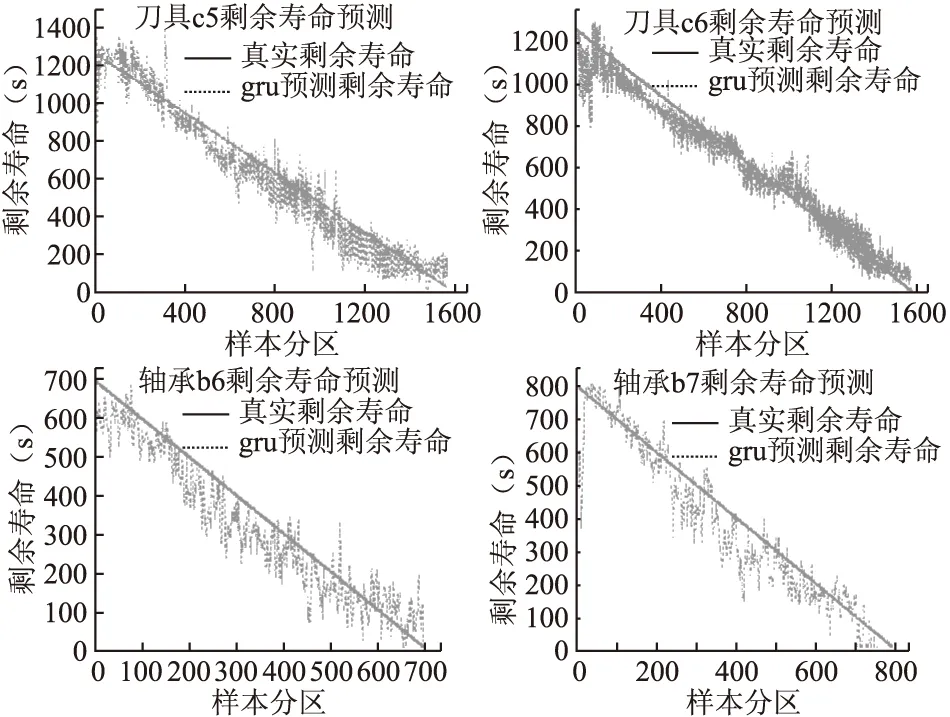
图7 RUL预测结果
本次实验除了使用常用的均方根误差(RMSE)评价方法外,还使用了PHM2012比赛针对RUL设计的打分方法RUL Score,该打分方法考虑了RUL预测产生的正误差(预测值大于目标值)和负误差(预测值小于目标值)对结果的影响不同.Score的计算公式如式(11)所示.
(11)
为了方便衡量本文的实验结果,将本文提出的方法同未考虑输入时序因素的梯度增强算法XGBoost和传统的BP网络预测结果相比较,比较结果如表3所示.通过表3的数据对比可以得到,两种评分方法都证明了考虑了输入时序因素的GRU-BP神经网络在RUL预测精度上要优于XGBoost和BP神经网络.

表3 RUL预测结果比较
6 结 语
本文主要针对数字化车间关键部件的RUL预测提出了一种多对一双GRU层神经网络的RUL预测方法.首先设计了RUL预测的基本系统架构,阐述了GRU对于RNN和LSTM的改进以及GRU的基本原理,然后搭建了基于GRU-BP的神经网络模型,在信号预处理时使用了改进的软硬阈值适中法进行小波降噪,并充分的考虑了输入时序因素进行RUL预测.最后通过实验验证了本文方法的可行性和正确性,并将其同XGBoost和BP神经网络方法做对比,进一步显示了GRU应用于RUL预测的准确性.
