基于大数据的网络产品众包模型研究
2020-05-11孙端
孙端
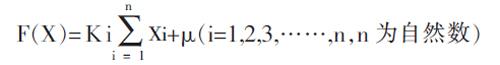
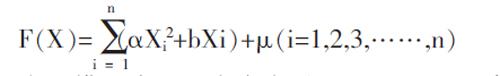
关键词:大数据;网络产品;众包模型;聚类分析;Apriori算法
中图分类号:C931 文献标识码:A 文章编号:1009 — 2234(2020)01 — 0077 — 03
随着网络经济的崛起,新技术、新生产方式、新商业模式等不断涌现,云计算、大数据、众包等一系列新的生产技术、生产方式、新的商业模式逐渐成为企业市场创新的新宠。国家在“十三五”规划纲要中明确提出要“拓展网络经济空间,牢牢把握信息技术变革趋势,实施网络强国战略”。习近平治国理政思想中对网络强国战略思想有着深入和系统的论述,强调新时代发展网络经济具有重要意义和价值。如何贯彻国家网络强国政策,把众包等新技术、新生产方式、新商业模式利用好、发展好、维护好,成为学界和业界研究的新课题、新任务、新挑战。采用众包模式,利用大数据分析方法,识别网络消费者网络行为,挖掘网络消费者的消费行为特征,在消费行为特征与消费者需求之间建立关联关系,构建一个符合网民需求的网络产品众包模型,对指导企业面向网络消费者,从事网络产品设计与开发具有重要意义。
一、国内外研究现状
以“众包”为主题词,在中国知网上,选择期刊页面,设定CSSCI来源期刊类别,截至2019年6月25日,共计获得417篇相关论文。从这些CSSCI来源期刊的论文看,国内学者们主要从众包创新、众包模式、众包模式应用、众包参与者行为等方面进行研究,其表现为:一是众包创新研究。如孟庆良等(2017)从双边视角出发,构建了众包创新模式的关键用户知识源识别体系,提出基于BP神经网络的关键用知识源识别方法。〔1〕二是众包模式研究。如王谦等(2014)系统性地探讨了网络众包模式的基本内涵、构建方法及现实效用〔2〕。三是众包模式应用研究。如杨雪(2016)从参与门槛、预期收益和信任程度等方面总结了众包生产中可能遇到的问题。〔3〕四是众包参与者行为研究。如张雪峰等(2019)构建了综合考虑参与者胜任度和接受度的任务推送模型,提出了参与者胜任度测量方法。〔4〕
国外众包研究早于国内研究,其研究涉及范围更广、内容更深、与实践结合更为密切。具体来看,国外众包研究主要表现为:一是众包内涵探讨。美国《连线》杂志记者Jeff Howe(2006)首先提出众包概念,并认为众包是一个公司或机构将过去由员工执行的工作任务以自由自愿的形式外包给非特定的大众网络的做法〔5〕。二是众包与创新关系研究。如开放式创新之父H W Chesbrough(2003)将“众包”视为开放式创新的一种有效的方式,能够充分利用外部资源,提高企业产品研发的创新性〔6〕 三是众包主体研究。如 Guido Jouret(2009)认为众包主体越广泛,越有利于创新〔7〕四众包驱动因素研究。如Brabham等(2012)提出大众参与者的内在动机比外在动机更能影响参与者的行为。〔8〕五是眾包绩效研究。如Blohm等(2011)认为参与者进行合作可以提高创意质量,并能显著提高众包竞赛的绩效水平。〔9〕
国内外众包理论相当丰富,从基本概念和内涵、参与要素、模式模型、及其各个领域中具体应用都有丰富的研究成果,这为本文提供了重要的理论基础。基于网民行为大数据,探讨网络产品众包模型的研究文献鲜见,特别是利用大数据聚类分析技术和Apriori算法,以网络消费者在网络平台上的浏览、购买、评价等行为大数据为基础,深度挖掘网络消费行为背后的真实需求,把消费者需求前置到企业的网络产品设计开发之中,则更为少见。
二、网络产品众包概念界定
学术界对网络产品概念存在着争议。有学者把人与人之间通过网络交往的信息产品和物质产品界定为网络产品;有学者认为网络产品是虚拟市场经济中的数字产品和智能产品;还有学者将网络产品定义为能够在网络上实现所有交易事项的产品;也有人认为网络产品是以网络信息作为载体的产品。这些概念在一定的条件下对其内涵进行了解释,有一定的合理性,但也存在局限。网络产品是网络技术为基础,直接面向网络用户提供的具有商品价值的信息或服务,该定义重点突出网络的商品价值性质,弱化网络的工具性质。
网络产品众包一种融合产品开发、设计、生产的工作任务以自由自愿的方式给非特定网络用户的新颖性生产开发模式。网络产品众包的本质是把原本由企业自己依据产品开发流程,进行产品研发,转变为依据网络,由无数网络消费者自愿参加产品开发来完成。在网络产品众包过程中,企业支付的成本与企业自己开发成本相比具有比较优势,因而,网络产品众包不仅能有效解决网络产品创新问题,而且大大降低企业网络产品开发成本,能够有效挖掘消费者真实需求,增强网络消费者对网络产品忠诚度,提高企业销售业绩,进而增强企业市场竞争力。
三、网络产品众包模型构建
(一)模型构建逻辑
对网民行为数据样本进行Q型聚类分析本质上是把海量大数据按照亲疏关系进行聚类,目的是把不同样本中的同一变量划分为一个簇,进而用准确的语言把这些簇的特征表达出来。对属于同一簇的特征变量进行R型聚类分析,目的是降低特征变量的维数,减少特征变量的数量。采用Apriori算法,挖掘出特征变量的频繁集。以频繁集中频繁项为自变量构建网络产品众包模型。总体来看,网络产品众包模型构建逻辑是依据网民行为大数据,经过Q型、R型二次聚类,从样品中提取共性特征、降低特征变量维数,再利用Apriori算法找出特征变量的频繁集,构建以频繁项为自由变量,以网络产品众包需求为因变量的众包模型。
(二)模型基本假设
1.网民对网络产品核心利益具有显著正向影响。无论是作为理性消费者,还是作为有限理性消费者,网络消费者购买网络产品最初的动机是来源于网络产品的核心功能,网络产品的核心功能是满足网络消费者需求的基本条件;网民作为网络消费者,对网络产品核心利益是有正向需求的,网民对网络产品核心利益具有显著正向影响。可见,网络产品核心利益越大,网络消费者的需求也越强。
2.网民对网络产品消费偏好具有显著正向影响。消费偏好是影响消费者行为的重要因素,消费偏好往往支配者消费者的消费习惯。在网络市场中,网民往往会依据自身网上购买经验、体验以及对网络产品的认知和判断,对某种网络产品产生某种倾向性的依赖,这主要是消费偏好在起着支配作用,网络消费者对某种网络产品消费偏好往往具有长期性依赖,这种依赖可能是来自感情体验、技术性依赖或者其他消费需求。网民作为网络消费者,对网络产品拥有着某种偏好,从而影响着自己的网络购买行为,网民对网络产品消费偏好具有显著正向影响。网民对网络产品消费偏好越强,网络消费者的需求也越强。
3.网民对网络产品信用具有显著正向影响。在网络市场中,网上消费者购买网络产品时,往往会关注网络产品的各种评价以及商户的网络信用。当网络信用较好时,促使网络消费者对网络产品及其商户产生正向的心理倾向,认为该网络产品及其商户很注重自己的网络信用,不会采取虚构或者欺诈的方式从事商业交易。网民作为网络消费者,对网络信用有着内在的需求,网民对网络信用有着显著正向影响。网络产品信用越好,网络消费者的需求也越强。
4.网民对网络产品正面情感需要具有显著正向影响。网络市场是一个虛拟的市场,网络消费者情感释放比现实中更为直接、自由和真实,受外界因素的干扰相对较小,一旦网络消费者对某种网络产品产生情感需求,会更加直接及真实地释放自己对某种网络产品的感情,当然这种情感需要可能是正面的,也可能是负面的。我们只筛选正面的情感需求,剔除负面的情感需要。网民作为网络消费者,对网络产品正面情感需求有着内在的一致性,网民对网络产品正面情感需要有着显著正向影响。网民对网络产品正面情感需要越强,网络消费者的需求也越强。
(三)网民行为大数据聚类分析
依据不同分类对象,聚类分析可以分为Q型聚类分析和R型聚类分析。基于Q型聚类的特征,本研究以清洗整理后的网民行为大数据为样本,如对品种、规格、款式、质量、特色、包装、商标、品牌、服务等等各种网络评价相关数据,进行Q型聚类分析,并对聚类结果进行解释,用准确词描述各个类别的特征,设定A1,A2,A3,……,An(n∈N且n31,N为自然数)参数表示样品类别特征。
R型聚类分析是研究变量之问的相关关系,即把同一样本中的不同变量进行比较,以确定不同变量间的亲疏关系,进而对变量进行分类。本研究是把Q型聚类后的各个类别特征作为变量,进行R型聚类分析,并对聚类结果进行解释,用准确词汇表述各个类别特征,设定B1,B2,B3,……,Bm(m∈N且m31,N为自然数)参数表示变量类别特征。R型聚类分析过程如下:
Q型聚类和R型聚类都是基于数据的聚类方法,一般要求是数字型数据,但是随着聚类技术的发展,文本聚类近年来也取得了长足的进步,在大数据分析中也实现了聚类功能。文本聚类是一种基于自然语言的文档作为数据进行聚类分析的方法,它处理的数据是文本数据。因此,上述采用的Q型聚类分析和R型聚类分析都是以网络消费行为的文本数据作为分析对象的,这是进行Apriori运算的基础和条件。
(四)Apriori算法分析
Apriori算法是Rakesh Agrawal等人1994年提出来的一种经典的大数据挖掘方法,其核心思想是利用重复迭代法找出数据中最多项的频繁集,具体实现分为两个步骤。首先,利用迭代法在数据库中搜索出支持度不低于用户设定阀值的项集,目的是通过迭代找出数据的候选项集,这在数据挖掘中较为关键,直接影响着数据挖掘的质量。其次,利用频繁项集构造出满足用户最小信任度的规则,目的是根据候选项集找出频繁项集。在网民大数据中,经过Q型聚类和R型聚类之后,网民大数据得到了恰当的特征变量表述和降维,但是大数据的复杂性决定了仍然无法构建模型,这就需要进行深度挖掘,找出大数据的频繁项集,目的是让复杂的大数据再次降维,找出与网络产品众包高度关联的频繁项,为有限项特征变量构建网络众包模型奠定基础。
Apriori算法看起来很完美,但是因为采用迭代搜索,大大限制了运行速度,因此,可以先将候选项集进行分类,然后逐个对候选项集进行Apriori运算,最后将运算后的候选项集合并,再进行Apriori运算,这样可以在一定程度上提高Apriori运算效率。根据以上Apriori算法分析,我们可以将经过Q型聚类和R型聚类之后的特征变量集设为L,将L分为N类,逐个对向量集进行Apriori运算,最后将频繁项集进行合并,再采用Apriori算法进行运算,从而挖掘出最多项频繁集。
(五)众包模型构建
在上述假设条件下,将Apriori算法挖掘出的各个频繁项分别设为自变量X1,X2,X3,X4,……,Xn,n为自然数,将网络产品众包目标设为因变量F(X),考虑到网民行为受网络质量影响,比如出现断网、网速、网络设备等等不可控因素,在因变量和自变量之间建立数学表达式如下:
F(X)=F(X1,X2,X3,X4,……,Xn)+μ
(X1,X2,X3,X4,……,Xn表示特征自变量,n为自然数;μ为不可控因素)
由于并不清楚自变量与因变量之间的关系属性,我们分别从线性关系、二次曲线关系两个维度分别构建网络产品众包模型,再根据各个具体模型的具体评价指标,分别对模型进行评估和验证,最后从两个模型选中一个较为优质的模型作为网络产品众包模型。
模型1:假设特征变量与众包模型因变量是线性关系,网络产品众包模型可以具体表示为:
在此模型中,Xn为自变量,即Apriori运算处理后的频繁项,Kn为对应自变量的系数,即对应的频繁项系数,Xi、Ki分别为第i个自变量及其系数,即第i个频繁项及其系数,μ为其他不可控因素。该网络产品众包的线性关系模型可以利用多元线性回归法确定该模型的系数,进而对模型进行验证和评价。
模型2:假设特征变量与众包模型因变量是二次曲线关系,网络产品众包模型可以具体表示为
在此模型中,Xn为自变量,即Apriori运算处理后的频繁项,a、b为其对应的二次项和一次项系数,n为自然数,μ为不可控因素。该网络产品众包的多元二次曲线关系模型可以利用序列二次规划算法求解该模型的系数,进而对模型进行验证和评估。
模型1和模型2是在相应的假设条件下构建的网络产品众包模型,具体那种模型更为优质,可以通过两种方法来比较。第一是利用各自的评估指标,对拟合度进行评估,可以判断出哪个模型更有。第二是对模型进行优化,利用数据条件,挖掘数据背后的逻辑,对其进行优化,然后再进行比较模型1和模型2的拟合度,这样可以判断哪个模型更优质了。
四、结论
通过大数据挖掘方法,对网民行为进行聚类分析,识别出具有显著影响网络产品价值的要素,从而构建网络产品众包理论模型,从而丰富产品生产开发理论。网络产品价值创造离不开网络用户参与,企业在网络市场竞争中需要主动引导网民群体参与其产品过程来优化和创新产品,实现企业与网民的协同发展。本文的创新之处在于,从大数据的视角,利用大数据聚类技术,先把网民行为数据进行关联分析,然后利用Apriori算法找出网民行为的频繁项集,从而把无线的变量问题变成有限变量问题,再以有限的频繁项为因变量,构建具有因果关系的数学统计模型。当然,在研究过程中,因为缺乏大数据的支撑,只进行理论的合理推演和可能性的论证,未来将利用网民行为大数据进行实证研究。
大数据时代,电商企业必须转换观念,树立大数据思维,利用大数据技术,分析企业行业大数据,为电商企业进行網络产品开发,制定产品策略提供良好的建议。据此,我们需要讨论:第一大数据挖掘工具自身倾向问题,一个工具的应用总是在一定条件下才能得到发挥,这就是要把问题和工具充分结合起来,只有二者有机结合,才能达到较好的效果。第二,大数据挖掘工具不是万能的,不能迷信于工具,在社会科学研究领域,甚至某些自然科学领域,寻找确定的答案越来越难。在现有条件下,依据大数据分析工具,找到事物背后的逻辑并加以佐证这种规律,从而在现实中加以合理运用和推广,为国家和经济社会发展服务即可。
〔参 考 文 献〕
〔1〕孟庆良,郭鑫鑫.基于BP神经网络的众包创新关键用户知识源识别研究〔J〕.科学学与科学技术管理,2017,(03):139-148.
〔2〕王谦,代佳欣.政府治理中网络众包模式的生成、构建及效用〔J〕.公共管理学报,2014,(04):61-70+141-142.
〔3〕杨雪.众包模式在广告生产中的可行性研究〔J〕.编辑之友,2016,(06):77-82.
〔4〕张雪峰,操雅琴,丁一.众包模式下基于参与者胜任度和接受度的任务推送模型〔J〕.管理科学,2019,(01):66-79.
〔5〕Jeff Howe.The rise of crowdsourcing〔J〕. Wired Magazine,2006,(06):01-05.
〔6〕Chesbrough, H. W. Open Innovation: The new imperative for creating and profiting from technology〔M〕. Harvard Business Publishing,2006:132–138.
〔7〕Guido Jouret. Inside Cisco's search for the next big idea〔J〕. Harvard Business Review,2009,(09):43-45.
〔8〕Brabham, Daren C. .The myth of amateur crowds 〔J〕. information,Communication and Society,
2012,(03): 394-410.
〔9〕Blohm,Ivo;Bretschneider,Ulrich;Leimeister, Jan Marco;Krcmar,Helmut.Does collaboration among participants lead to better ideas in IT-based idea competitions An empirical investigation 〔J〕. International Journal of Networking and Virtual Organisations,2011,(02):106-122.
〔责任编辑:孙玉婷〕
