基于特征流融合的带噪语音检测算法
2020-05-11龙华杨明亮邵玉斌
龙华,杨明亮,邵玉斌
(昆明理工大学信息工程与自动化学院,云南 昆明 650031)
1 引言
语音检测就是从带有背景噪声的音频中准确定位出语音的开始点和结束点,去除静音和纯噪声部分,提高语音信号的有效利用率,不同的应用场景对语音检测的要求有所不同。例如在语音通话系统中,为了提高语音分组转发的有效性(节约话路资源)与通话用户的舒适性(语句完整),从干扰环境下准确检测出语音段(即具有完整含义的句子,由若干短时语音帧组成)的起始位置且保证语音段不被检测割裂的语音检测技术就显得尤其重要,这是有别于语音检测中的关键词检测、词中的音节起始检测(英文多为多音节词)及语音特征提取前端的语音活动检测(VAD,voice activity detection)等应用的。语音特征提取前端常使用的检测方法有双门限法[1]、谱熵法[2]等,其目的都是去除音频段中的静音段、纯背景噪声段以及表现为随机噪声特性的清音部分,进而获得音频信号中的浊音信号,而语音通话系统中完整语句的所有信息都是需要保留的。再者,语音通话系统中完整语句的检测对语音段中的加性噪声抑制处理(如谱减法[3]等)也是有利的(完整语句中保留着原始的噪声帧,便于信噪比估计)。
当前的语音检测可大致划分为基于阈值、基于分类器和基于模型的VAD。基于阈值的VAD 主要包括双门限法、谱熵法等,通过提取语音特征(短时能量、过零率、谱熵等)并设定判决门限,对静音段、清音浊音具有较好的效果,但在噪声较大的环境下则表现得无能为力。基于分类器的VAD 则有基于网络框架的语音检测方法[4-5]及利用指数核函数构建语音检测模型[6],将噪声和语音的帧特征作为分类数据进行目标训练和测试,在语音检测时,从带噪音频中检测出的语音丢掉了原始语句中应有的短时字间隔,严重降低了听众的舒适度。基于模型的VAD 主要包括统计模型和算法模型。基于统计模型的语音检测包括文献[7],以及在统计基础上构建谐波加噪声模型与最大后验概率相结合的语音检测模型[8]。算法模型则包括利用语音谐波检测技术用于语音检测[9],同基于阈值的VAD 一样,在面对复杂环境下,其检测性能也表现得不太好。
Shamma 等[10]分析并指出,语音流的形成主要取决于编码声源各种特征响应之间的时间一致性,即多条相干的特征流(一系列连贯实体/声音的内部特征,流强调了一个事实,声音特征同声音信号一样是随着时间而展开的。同一段语音的不同时刻所对应的同一特征在特性上是具有差异的,如声音的振幅是动态变化的,在数学上则表现为不同的数值序列即特征流)构成了一条与其他源非相干特征分离的流,这也是多通道语音可以利用不同通道之间的差分信息进行语音检测[11]而单通道行不通的原因。Teki 等[12]指出人类听觉系统对某些特征有显著敏感,这些特征是根据混合声音中小部分音频元素的时间重合而调整的,即当前所熟知的语音特征并不能完全表征语音的全部独特信息,这也是网络模型对反映语音特征的独特之处。
为了进一步提高语音通话中语音段起始检测的准确性以及避免语音段被检测割裂等问题,本文提出了基于特征流融合的带噪语音检测算法。利用神经网络的非线性拟合能力构建语音谱图特征与语音之间的映射关系,实现对语音的检测[13]并取得了一定的效果,而语音统计特征在工程中的成功应用已证实其表征语音信号的有效性,时域信号更是语音信号最直观的反映形式。由于利用单一特征进行语音检测性能不佳,因此首先对待检测语音提取时域特征流、谱图特征流及统计特征流并分别对带噪音频中的语音段进行估测后,然后对各个特征流估测得到的语音预测概率进行加权融合。过去语音检测从帧层级出发,忽略了语音连贯性特征,而高阶隐马尔可夫模型可以充分考虑过去的状态信息[14],对滑动窗时长内的语音起着平滑的作用,保证了检测后语音段保持原始语句的连续性。
2 基于特征流的语音估测
2.1 时域特征流的语音估测
现实采集到的带噪语音可定义为
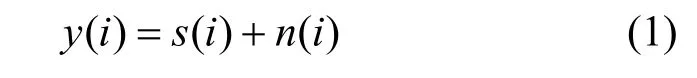
其中,y(i)为观测到的音频信号,s(i)为纯语音信号,n(i)为噪声信号,i为数据点号。每一帧信号的语音信号可分为以下2 种状态

其中,下标n表示第n帧信号,每一帧信号中包含M个数据点,即。这里假设噪声nn的均值为0,对角协方差矩阵为。语音信号可以看作具有随机、周期和拟周期性质的非线性时间序列,那么依据谐波理论可将语音信号分解为k阶谐波[15],即
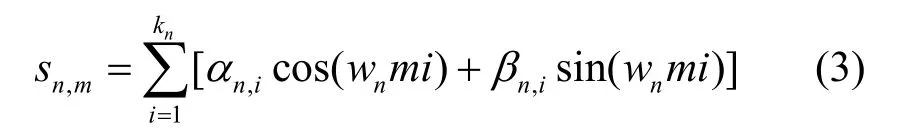
其中,sn,m表示第n帧第m个元素值,kn表示谐波阶数,αi,n与βi,n表示第i阶谐波的线性权值,为基频(弧度),fs为音频信号采样率。进一步地,将语音信号用矩阵向量表示,并引入一个隐变量hn用于表示音频帧信号中语音是否存在(其中,1 为语音,0 为非语音),可得

其中,
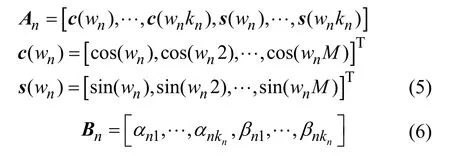
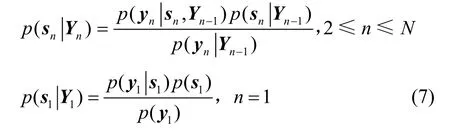
其中,N为总帧数目。等式右边分子的第一项可由拉普拉斯近似算法表示,第二项可写成
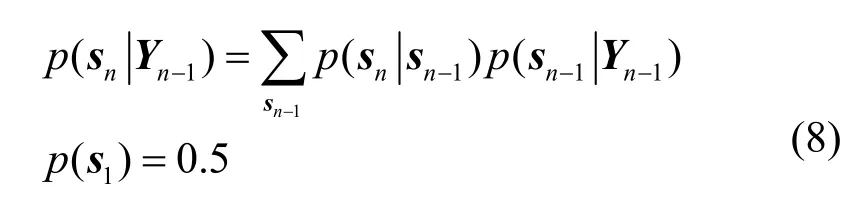
语音信号状态具有连贯性,带噪音频信号中的语音状态应满足隐马尔可夫模型,为了便于计算,这里假设时序帧的语音状态满足一阶隐马尔可夫,即。第n帧音频信号的状态空间可进一步表示为
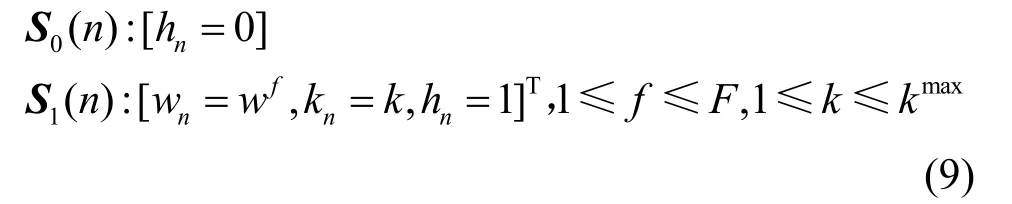
语音帧推断后一帧为语音帧的条件概率为
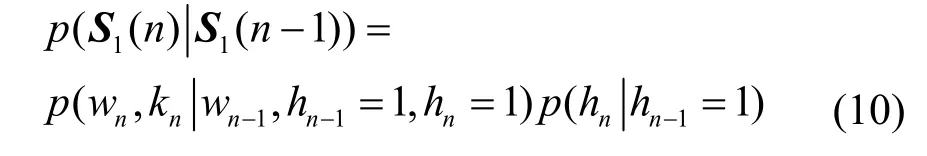
谐波阶数和基音频率无直接关系,进而可对等式右边第一部分进行条件联合分布分解
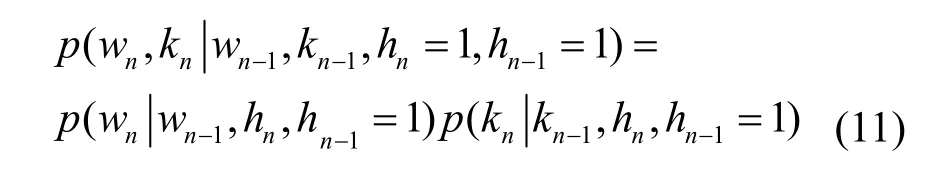
当前一帧为非语音帧时,后一帧为语音帧的条件概率为
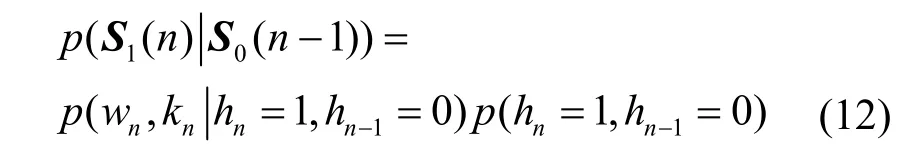
当前一帧为非语音帧时,选择离当前帧n最相近的过去语音帧c作为推断,根据文献[16]的式(18)对式(12)等号右边第一部分做条件联合分布分解,即
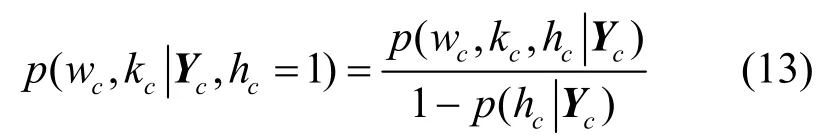
联合式(9)~式(11)可得
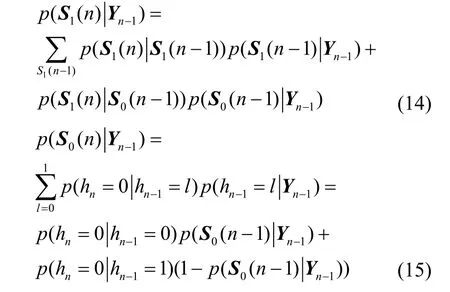
根据文献[16]的式(23)得到状态空间的后验概率为
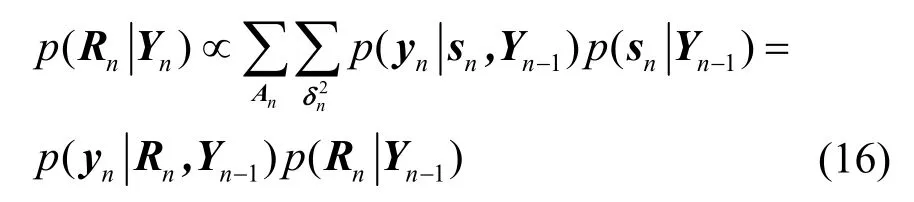
由此,按照文献[16]中的策略,根据式(10)、式(12)、式(14)和式(15)对状态空间做出概率预测,依据式(5)~式(8)和式(16)计算状态空间的后验概率,并联合文献[15-16]的快速基频估计和谐波阶数估计对进行迭代更新,其约束条件为
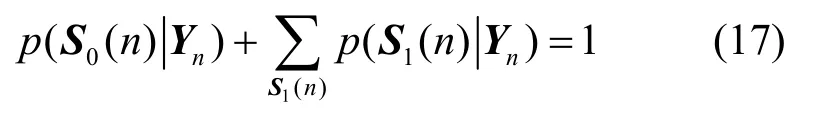
2.2 谱图特征流的语音估测
因为短时功率谱是对按照时间序列展开的帧信号进行傅里叶变换得到的,所以谱图特征也是以“流”的形式出现的。时频谱图的频率分辨率为线性,而人类听觉系统对低频十分敏感,对高频就比较迟钝,为了解决频率分辨率的问题,本文利用64 个Gammatone 滤波器组提取Cochleagram 特征[17-18],并利用窗长为32 ms、帧位移为16 ms 的汉明窗口对其输出进行了瞬态积分。Gammatone 滤波器的脉冲响应h(t)为其中,g为输出增益;t为时间;a为滤波器阶数;b为矩形带宽,它随中心频率f的增大而增大。
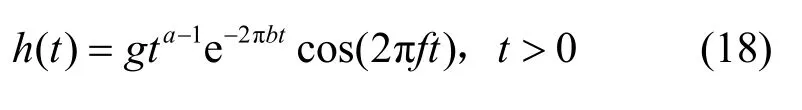
梅尔频谱倒谱系数(MFCC,Mel frequency cepstrum coefficient)特征是一种基于人耳对等距的音高变化的感官判断而定的非线性频率刻度,现已应用于语音识别、音乐检索等多个方面。Gabor 滤波器是一个频率和方向表达同人类视觉系统类似、用于边缘提取的线性滤波器,在图像的纹理表达和分离方面具有优异的性能。故利用Gabor 滤波器对MFCC 的纹理特征进行提取(详见文献[13])。
长时信号变化特征(LTSV,long term signal variability)测量方法[19]在多个语音检测应用研究中证明,其在平稳噪声环境下具有较好的稳健性。首先,计算第n帧短时能量谱为
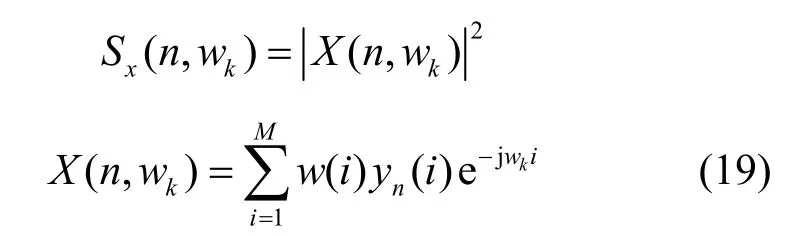
其中,X(n,wk)为第n帧信号yn在频率wk处的短时傅里叶变换,w(⋅)为短时窗,M为帧长。根据文献[19-20]对LTSV 的定义,对每一帧的每个频率点进行熵的计算,有
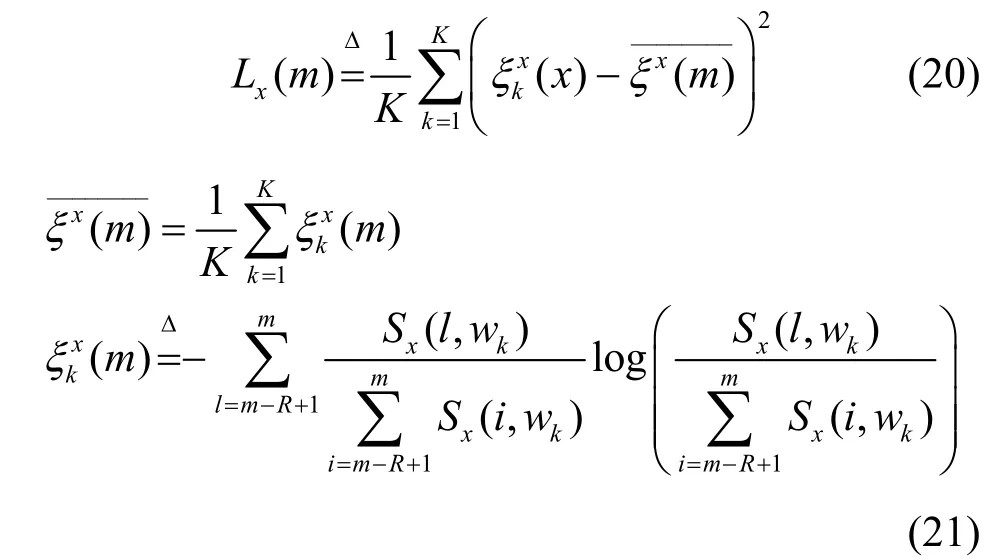
其中,m≥R,R表示长时滑动窗包括的帧数目,这种滑动处理通过计算第m帧K个频点下熵的方程Lx(m),实现了对语音的长时分析。
语音具有一定的周期性,通过利用谐波理论估算带噪音频信号的基音周期,然后根据自相关函数计算相关图,为了克服吉布斯现象,此处在进行自相关函数计算时需要对帧信号进行加窗和预加重处理,其中窗长为32 ms,帧移为16 ms。随后,每次都推导出一个语音测量值,即信号能量归一化估计基音周期时的自相关值,为了考虑前后帧之间的相关性,对一维预测概率做了前后扩张,最终取五阶自相关值。
2.3 统计特征流的语音估测
语音发音通常是由清音和浊音交叉构成的,而非语音却不满足这样的构造特点,清音的过零率远高于浊音,故语音过零率的变化一般要比非语音激烈。高过零率比率(HZCRR,high zero crossing rate ratio)用于描述一段音频段过零率变化的剧烈程度,计算式为[21]
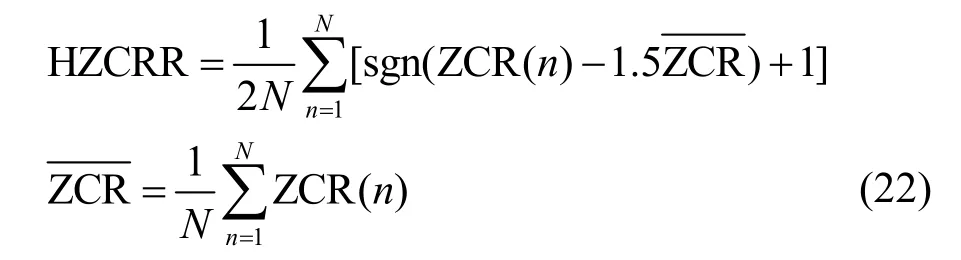
其中,N为帧数目,n为帧索引,sgn 为符号函数,ZCR(n)为第n帧的过零率,为ZCR 均值。为了避免一些非语音段能量较低,但过零率比率高于所设阈值0.08 的误判,本文加入式(23)所示的短时能量特征共同进行判断。
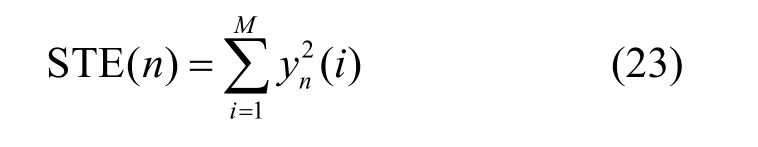
其中,符号i为帧内音频数据点索引,M为帧长,yn为第n帧归一化信号。此处阈值设置为0.05。
3 特征流的融合
基于特征流融合的带噪语音估测流程如图1所示。
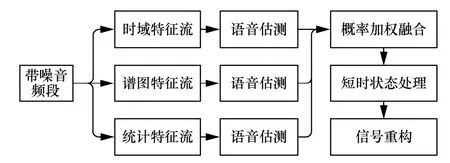
图1 基于特征流融合的带噪语音估测流程
为了减少估测语音概率的复杂性,在2.1 节整个初步估计中假设状态空间为一阶隐马尔可夫模型,只考虑前一帧的影响,忽略语音长时帧的相关信息,而事实上,可将基于特征流对每帧音频预测的语音概率值序列看作离散平稳有记忆信源X:{a1,a2,…,ar},在任何时刻tm+1,随机变量Xm+1所发符号aim+1通过其前m个符号(ai1,ai2,…,aim)进而与更前面的符号发生联系[22],即aim+1只与它前面的m个符号相关,与更前面的符号无关。假设每一个短时状态由m个信源构成,而这m个符号取遍信源X的符号集,m-M信源共有rm种不同的消息,令Si为(i=1,2,…,rm)某一状态,则有
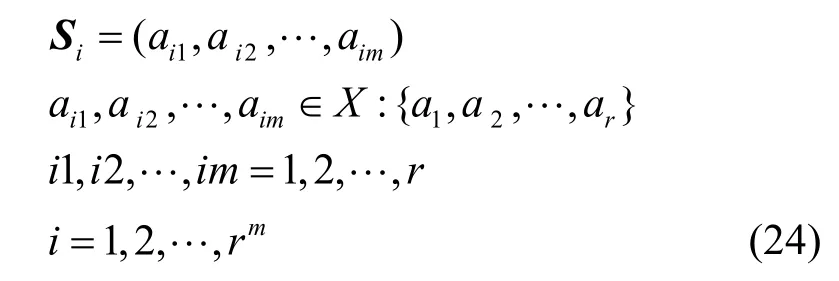
对应于带噪音频帧的语音检测只存在2 种状态,即信源X的符号集X:{0,1},i1,i2,…,im为符号状态序列号。因为本文分帧帧长为32 ms,帧移为16 ms,又考虑到正常语速7 个音节需要3 s,所以此处m=39,即39 阶马尔可夫信源,由式(24)即有
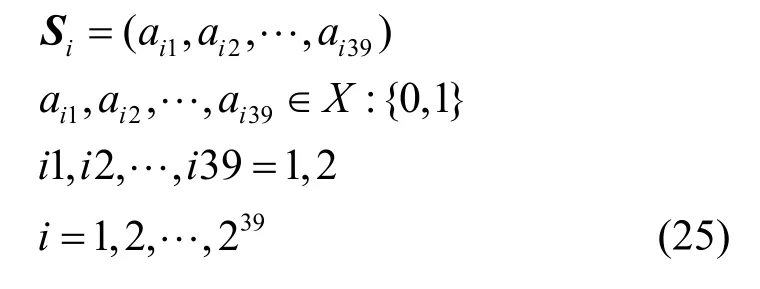
符号序列号为1 时对应符号集中的符号0,符号序列号为0 时对应符号集中的符号1,进一步即有
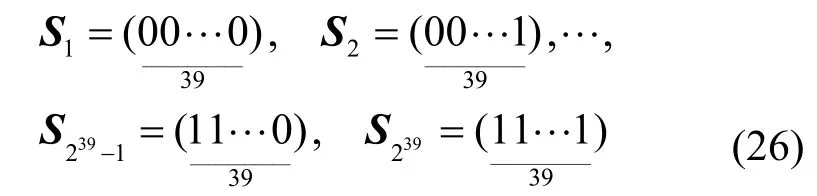
将预测语音概率值大于0.5 当作状态1,其余的为状态0,为了对语音概率曲线做平滑处理,本文统计了每一个短时状态中0 与1 的个数,令1 的个数大于20 且小于35(设定个的判决阈值)的短时状态Si内的符号状态值均为1,其他的短时状态符号值均为0。为了保证最终重构语音舒适度和可理解性,短时状态时序步长取11 帧。
令时域特征流的输出概率为prob1,经过短时状态处理的时域特征流的输出概率为序列),谱图特征流输出的概率为prob2,统计特征流的输出概率为prob3。为了突出的语音部分,即有
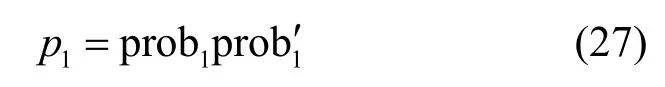
将p1与谱图特征流的语音概率融合并利用统计特征流prob3突出谱图特征流prob2的语音部分,与此同时将prob1与prob3加权融合,则有

最后,将两两特征流融合结果再次加权融合,有
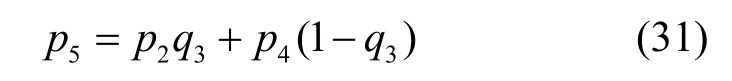
其中,q1、q2、q3分别为不同特征流语音估测的权重系数。根据人类听觉系统自身的特殊特性,以及对某些特征更加敏感的理论[13],对权值进行猜测和检验(如同深度学习模型中卷积核大小的选择一样)。经实验测试推断,谱特征流包含有更多区分语音和噪声的有用信息,因此取q1=0.35,q2=0.40,q3=0.35。最后,利用隐马尔可夫短期状态对语音概率曲线进行平滑处理,得到最终的语音估测0-1折线p5(其中,1 为语音,0 为非语音)。
4 实验设计与结果分析
4.1 实验设置
1)数据准备
实验测试检验中,本文采用的语音库为TIMIT语音库、THCHS30 语音库、2018 方言种类识别AI挑战赛(DRC,dialect recognition contest)语音库3种,语音为采样率fs=16 000 Hz、单通道的wav 音频文件,每句语音时长在4~7 s 左右。语音训练数据集包含TIMIT 语音库中美国8 个地区462 个说话人语音,每人10 句英语语音;THCHS30 语音库包含11 个来自中国各地的说话人语音,每人20 句普通话;DRC 语音库包含中国10 个方言地区的300 个说话人,每人10 句中国方言。噪声训练数据集采用自建噪声库(SBNL,self-built noise library),其中包括动物鸣叫、公共场所噪声、户外活动噪声、室内活动噪声、工厂噪声、音乐、自然音效、交通噪声共8 类噪声类型,每一类噪声又包含10 段不同的噪声段。从语音训练数据集和噪声训练数据集中随机选取一种语音和噪声,随机选择SNR=[-5,0,5,10,15,20]dB 中的信噪比进行带噪语音合成,建立多条件训练集用于训练基于谱图特征流的语音概率预测深度神经网络(DNN,deep neural network)模型。
实验测试语音数据包含TIMIT 语音库中168 个说话人(女性52 人,男性114 人,每人10 句)、THCHS30 语音库中20 个说话人(女性18 人,男性2 人,每人10 句)、DRC 语音库中50 个说话人(女性30 人,男性20 人,每人10 句)。为了更加贴近真实环境,在原始语音数据基础上的语音段前后随机补充2~4 s 的静音段,以便与噪声混合成的带噪音频更符合现实情况,噪声库采用Nonspeech公开噪声库,合成语音的信噪比等级SNR=[-5,0,5,10]dB。测试语音库中的语音段与噪声库中随机选取的噪声依次按照-5 dB、0 dB、5 dB、10 dB 这4个信噪比等级合成4 个不同信噪比的测试数据库。语音库的分配设置如表1 所示。
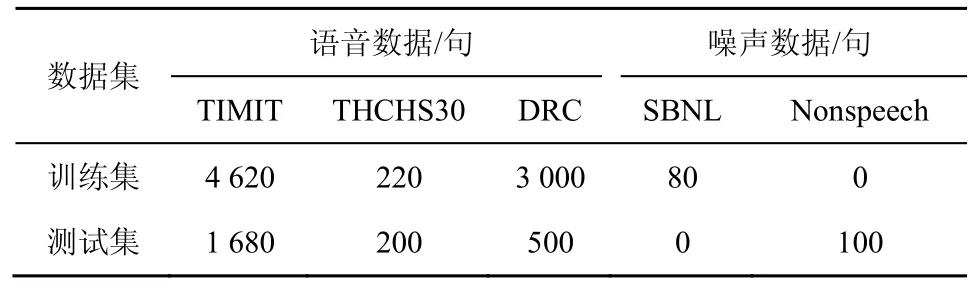
表1 语音库的分配设置
2)模型设置与训练
基于谱图特征流的语音估测部分,将提取的64维Cochleagram 特征、110 维Gabor 特征、5 维LTSV特征以及5 维基音周期自相关值构建成184 维特征流,再将特征流送入3 层网络[13]、节点数为184→64→64→1 的DNN 中进行训练(迭代),得到一个谱图特征流的语音概率预测模型。其余按照第3 节特征流融合策略进行构建系统。
4.2 实验测试与分析
为了分析不同程度噪声对带噪语音估测性能的影响,用4 组不同信噪等级的音频测试库对不同语音检测方法进行性能测试。以基于贝叶斯特征流(BFS,Bayesian feature stream)[16]和光谱特征流(SCS,spectral characteristic stream)[20]的带噪音频语音概率估测作为本文特征流融合(FSF,feature stream fusion)的基线模型。因为HZCRR 在干净环境下能够准确地对语音段进行估测,故以2.3 节的统计特征流作为原始干净环境的语音检测方法,其语音检测结果作为音频段语音状态的标准标注。以误检率(Pf,false-alarm probability)、漏检率(Pm,miss probability)、正确率(Pc,correct probability)作为性能评价指标(其中,Pf 和Pm 越小越好,Pc越大越好),则有
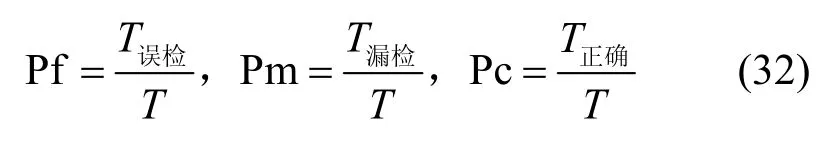
其中,T为总音频长度,T误检为误检为语音的音频长度,T漏检为漏检语音的音频长度。不同信噪比条件下的语音估测误检率、漏检率和正确率分别如表2~表4 所示。
由表2~表4 可知,对于4 个信噪比等级下的带噪音频段语音检测性能,除SNR=5 dB 和SNR=10 dB条件下BFS 的Pf 指标略优于本文所提的FSF 方法外,其余本文所提FSF 方法的性能指标都显著优于对比实验模型,根据表1~表4 可得,不同方法的平均语音检测性能如表5 所示。
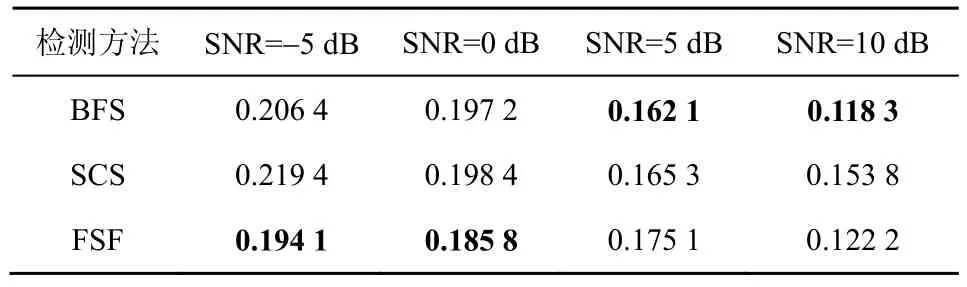
表2 不同信噪比条件下的语音估测误检率
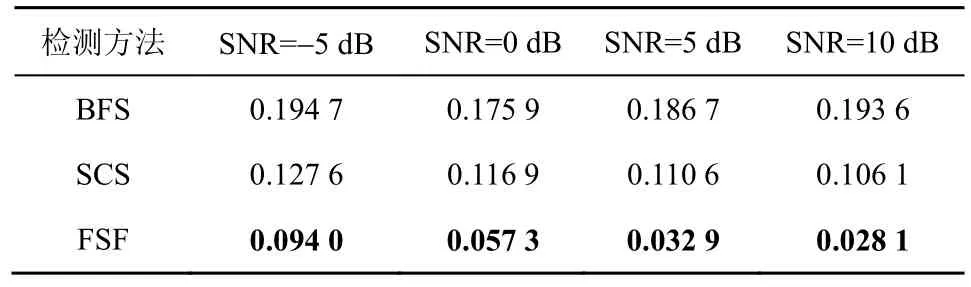
表3 不同信噪比条件下的语音估测漏检率
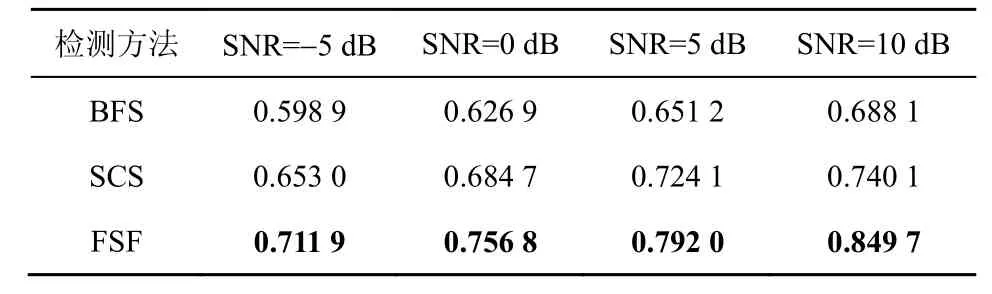
表4 不同信噪比条件下的语音估测正确率

表5 不同方法的平均语音检测性能
对表5 分析可知,相对于BFS,FSF 的Pf、Pm、Pc 评价指标分别提高了1.023%、71.73%、21.26%;相对于SCS,FSF 的Pf、Pm、Pc 评价指标分别提高了8.10%、53.97%、11.01%。
为了更直观地展示不同语音检测方法在不同信噪比条件下的检测性能,从4 个不同信噪比等级测试库中挑选不同音频进行性能可视化展示,分别如图2~图5 所示。
由图2 可知,当SNR=-5dB 时,语音完全被噪声所覆盖掉,无法从时频图中观察出语音信号的清晰脉络。在此条件下,BFS、SCS、FSF 都出现了不同程度的误检,其中SCS 的误检率最大,其次是SCS,BFS 的误检最少。漏检方面,FSF 的漏检最多,与总体测试结果中FSF 的漏检率最低的结论有所差异,但FSF 的检测正确率大于BFS 和SCS 的检测正确率。由于噪声环境的复杂性,出现了使FSF对个别音频段的语音检测性能低于BFS 或SCS 的情况。第1 节中已指出,对于语音通话中的语音检测,除了要求准确检测出完整语句的起始位置外,还需要避免完整语句被检测割裂的问题(保证听者的舒适度),另一方面也是语音增强的需要。例如,图2 中BFS 的语音检测结果以单个字或词的形式出现,这既不是语音通话中所期待的,也不利于检测语音段后续的语音增强(非平稳噪声很难被准确估计)。对于SCS 语音检测,其检测结果大部分都是连贯的,但在大约t=14 s 处也出现了检测波动(导致音乐噪声的产生),而FSF 由于进行了高阶隐马尔可夫处理,保证了检测出的语音段的连续性。

图2 不同语音检测方法在SNR=-5 dB 时的检测性能
将图2 与图3 对比可知,在信噪比提高的条件下,BFS、SCS、FSF 的检测性能都得到提高,特别是FSF 的误检和漏检大幅度降低,但BFS 和SCS仍然出现较多的误检。此外,在信噪比提高的情况下,SCS 检测的语音段连贯性得到较大改善(t=14 s处),但对于BFS 检测结果改善并不明显。
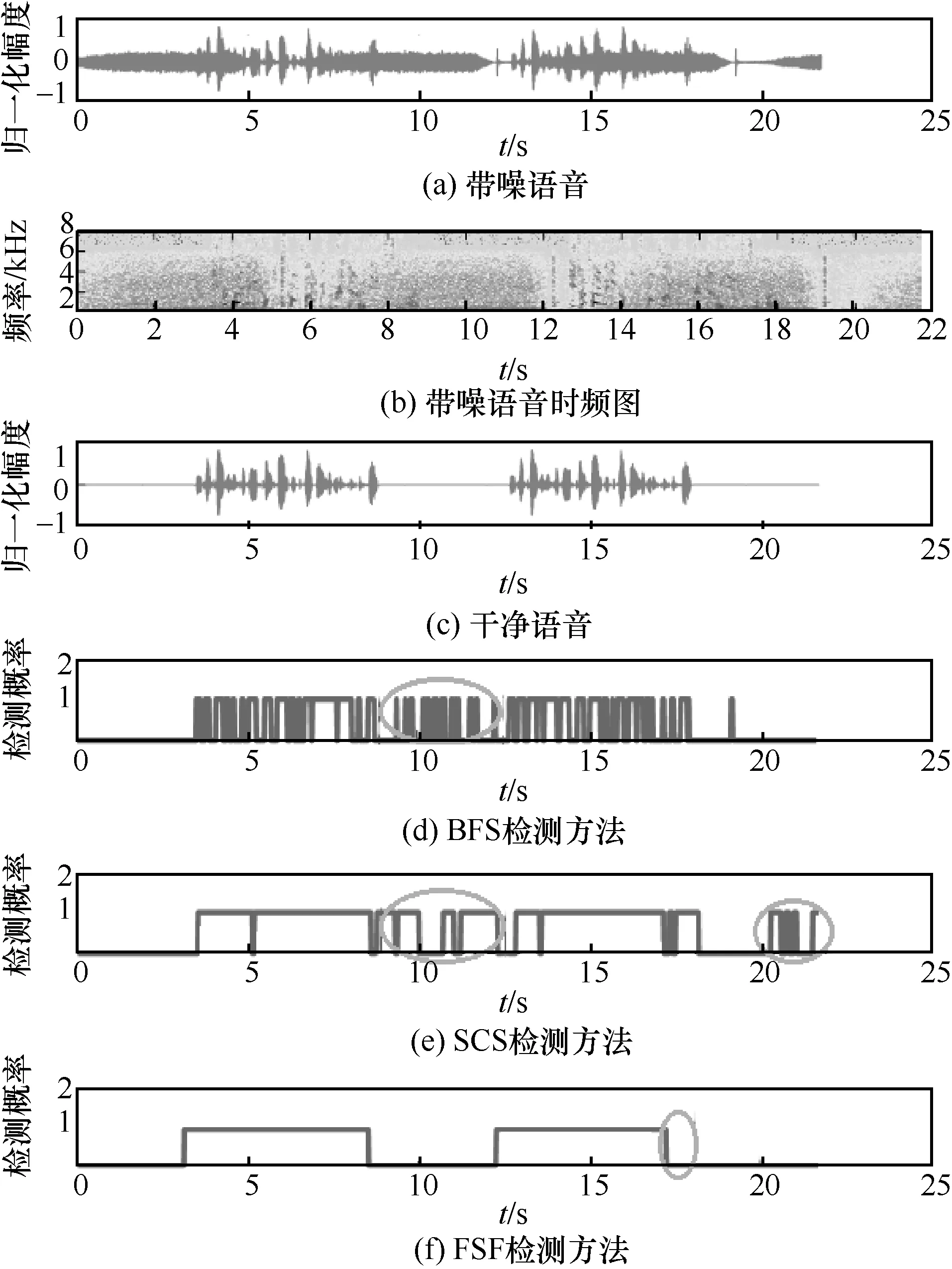
图3 不同语音检测方法在SNR=0 dB 时的检测性能
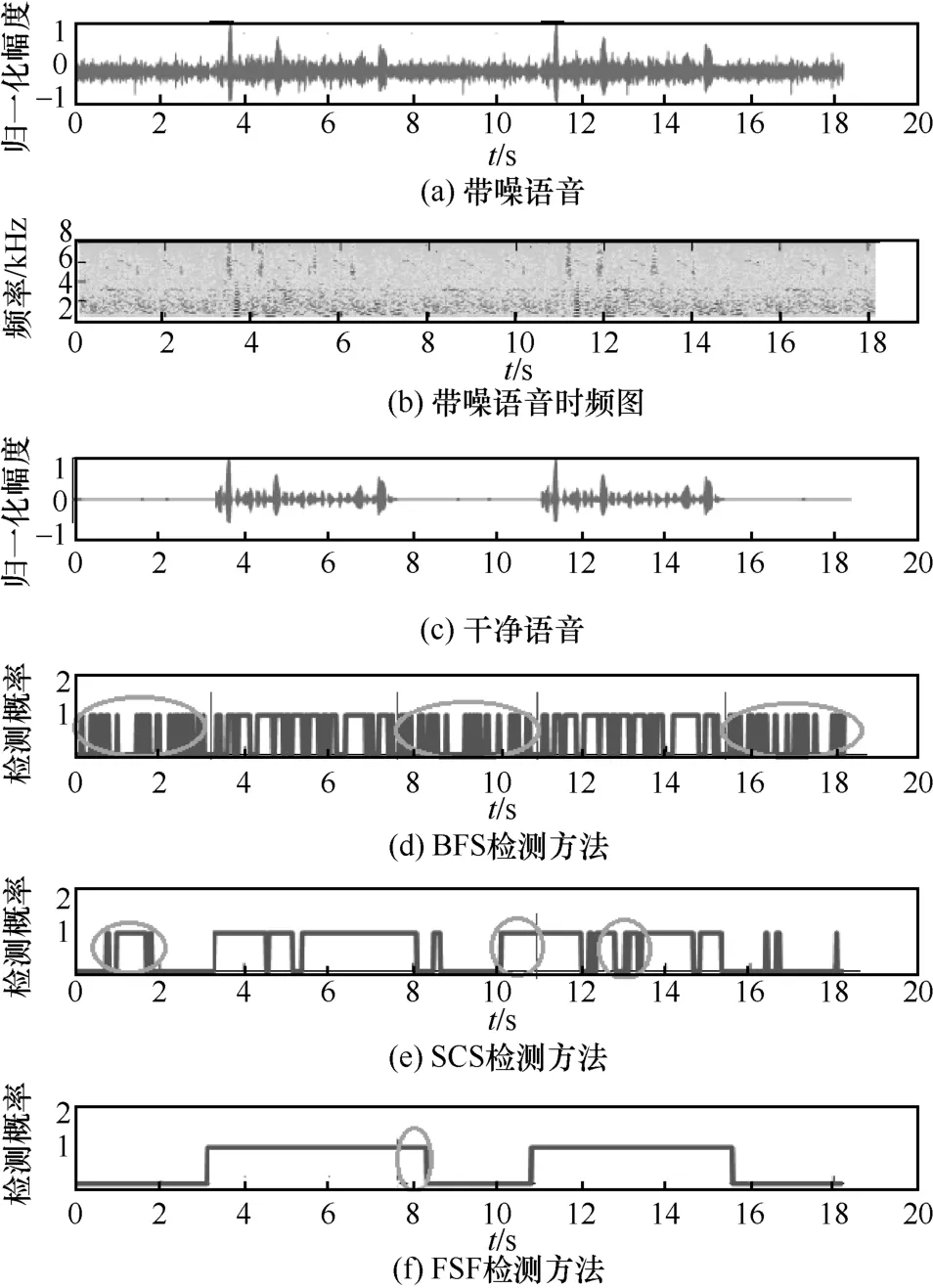
图4 不同语音检测方法在SNR=5 dB 时的检测性能
图4 和图5 展示了BFS、SCS、FSF 在噪声干扰环境SNR=5 dB 和SNR=10 dB 时的语音检测性能。从图4 可知,BFS、SCS 和FSF 仍然存在误检的情况,BFS 和SCS 的语音检测中还存在漏检的情况,而FSF 不存在漏检。图4 与图2、图3 所展示的结果一样,BFS 和SCS 的语音检测由于从帧层面进行语音检测判定,并未进行短时状态考虑,在语音检测时对语音段内的字间间隔进行了移除,使检测出的语音段连贯性受到破坏,严重影响着听者的舒适度,也制约着检测语音段后期的语音增强性能。
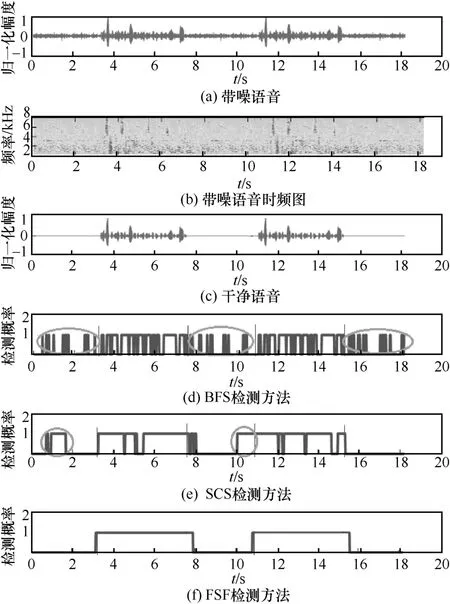
图5 不同语音检测方法在SNR=10 dB 时的检测性能
将图4 与图5 对比可知,当信噪比提高时,在图4 中被误检或漏检的部分也得以被正确检测出,但对于某些部分依旧无法正确检出,特别是BFS 和SCS 的语音检测方法。将图5 进一步与图2、图3 对比可知,在一定的信噪比范围内,影响语音检测性能的并非只有信噪比指标,噪声类型也是干扰语音检测性能的重要因素。从图5 语音检测的可视化结果中可知,此时FSF 可在尽可能去除静音段和纯噪声段的同时,避免完整语音段被检测割裂的问题。
5 结束语
为了进一步提高语音通话中语音段起始检测的准确性及避免语音段被检测割裂等问题,本文提出了基于特征流融合的带噪语音检测算法。相比于基于单纯的时域特征流或单纯的谱图特征流(DNN模型训练检测),所提算法在不同信噪比情况下的带噪语音检测性能(误检率、漏检率和检测正确率)都有了较大的提高。这主要归功于所提算法将多种特征流进行了融合,相对于利用单特征(如HZCRR统计特征等)进行语音检测方法,增大了语音检测的运算力。因为利用了高阶隐马尔可夫模型的多状态考虑能力即对语音估测结果进行了短时处理,使经过FSF语音检测方法的语音段保持原始的连贯性(即具有完整含义的句子)。进一步提高语音检测抗噪性能仍是未来的目标(同等数值漏检率比误检率更具破坏性,少量的误检率可以通过语音增强来进一步消除,而漏检率会破坏原始语句连续性结构)。影响语音检测准确性的因素有多种,其中包括噪声类型、噪声强度、个人习惯等,后期可发展自适应隐马尔可夫或使用深度学习模型来代替隐马尔可夫的作用,进而提高检测语音段的完整性和连贯性,通过构建多条件的训练数据集提高语音检测模型的稳健性。
