基于移动边缘计算的NOMA 异构网络资源分配
2020-05-11张海君张资政隆克平
张海君,张资政,隆克平
(北京科技大学计算机与通信工程学院,北京 100083)
1 引言
无线通信网络技术飞速发展,对数据速率、能量消耗都有更高的要求[1]。满足用户的通信需求是每代移动通信系统演进的首要驱动,而新的通信技术则是每代系统演进的必要支撑[2]。未来无线通信网络不再是单一的结构,在小区内的热点区域内部署大量小基站,从而形成异构网络以提升网络性能[3]。此外,非正交多址接入(NOMA,non-orthogonal multiple access)和移动边缘计算(MEC,mobile edge computing)都是未来移动通信网络十分关键的技术,已成为当前研究的热点[4-5]。
NOMA 通过在发射端采用非正交传输方式,在接收端采用串行干扰删除(SIC,serial interference cancellation)技术实现解调,从而将同一信道分配给多个用户,实现提高频谱效率的目的[6]。社交媒体平台的日益普及导致了更多数据的产生,因此,在无线通信网络管理和优化中考虑社交网络和本地信息变得越来越重要[7]。MEC 指能够在网络边缘执行计算卸载和数据缓存的技术,该技术将当下流行的内容缓存到网络的边缘,从而改善服务,为移动用户提供更高效的存储和传输[8]。
通过在NOMA 异构网络中部署缓存,可以有效提升网络的传输效率,降低网络能耗。然而异构网络中由于宏基站和众多小基站的存在,产生了用户与基站的匹配问题;同时为了降低能耗,需要对有限的功率进行分配。针对部署缓存的NOMA 异构网络场景下,如何通过匹配用户基站和合理地分配功率以提升网络缓存收益、提高能量效率的问题,本文提出了NOMA 联合优化算法。
2 建立网络模型
部署缓存的NOMA 下行异构网络如图1 所示,该网络包含一个宏基站和K-1 个小基站,宏基站与小基站均部署了缓存;允许子信道被多个用户使用,信道条件较差的用户优先被解码,解码信息将被广播给信道条件较好的用户,从而实现干扰消除。在该网络中,k∈{1,2,…,K}表示第k个基站,其中第1~(K-1)个基站为小基站,第K个基站为宏基站;n∈{1,2,…,N}表示第n条信道;l∈{1,2,…,L}表示第l个用户。

图1 部署缓存的NOMA 下行异构网络
定义用户l与基站k的缓存参数为zl,k∈{0,1},zl,k=0表示基站k中用户l没有获取缓存;表示基站k中用户l获取了缓存。因此,整个网络的缓存收益可表示为
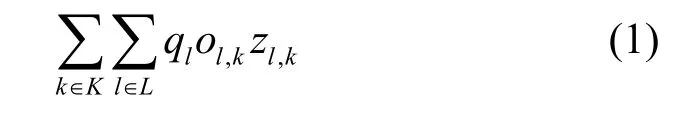
其中,ql表示用户l对内容的请求率,ol,k表示缓存增益。系统内根据不同的收益目标为缓存的增益赋予不同的含义,例如网络带宽利用率的提高、时延的减少、能量效率的提升等[9]。本文采用能量效率的提升作为缓存增益,则式(1)所示的缓存收益变为
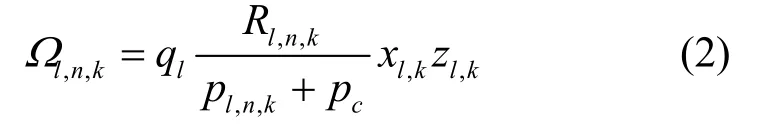
其中,pl,n,k表示用户l在基站k下通过信道n传输分配的功率,Rl,n,k表示对应的信息速率,xl,k∈{0,1}表示基站与用户的匹配参数,pc表示附加的电路功耗。
因此,最大化缓存收益P1为
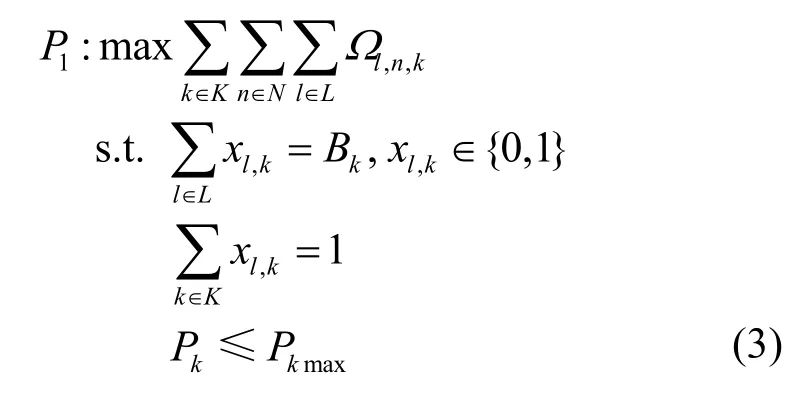
其中,Bk为基站k允许的用户接入数量,Pk为基站k的总发射功率,Pkmax为基站k的最大功率限制。
3 NOMA 联合优化算法
3.1 消息传递用户协同策略
消息传递用户协同优化通过在多个节点之间分配计算负载来解决复杂问题:通过在节点间多次交换信息并计算节点边缘来得到全局问题的解[10]。
为了使用消息传递,定义以xl,k为函数变量的节点Wk(x)及Cl(x)为

则1P的优化问题可表示为
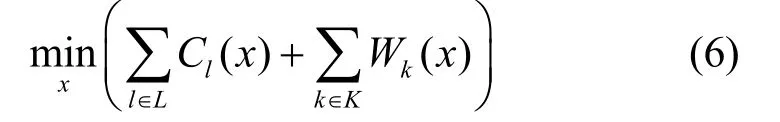
根据最小和消息传递式,在以xj(1≤j≤J)为变量节点和以gr(1≤r≤R)为函数节点的消息传递中,由变量节点xj向函数节点gr传递的消息为

由函数节点gr向变量节点xj传递的消息为

变量节点x与函数节点Cl(x)和Wk(x)之间的消息传递路径如图2 所示。将式(4)代入式(8)可得函数节点Wk向变量节点xl,k传递的消息,如式(9)所示。
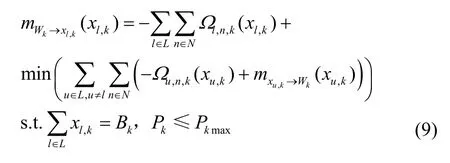
将式(5)代入式(8)可得函数节点Cl向变量节点xl,k传递的消息,如式(10)所示。
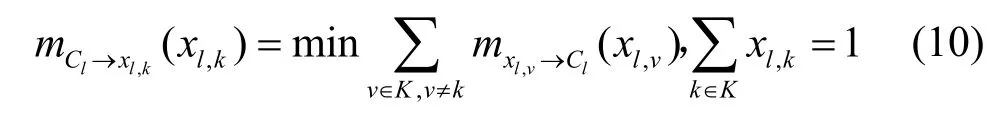

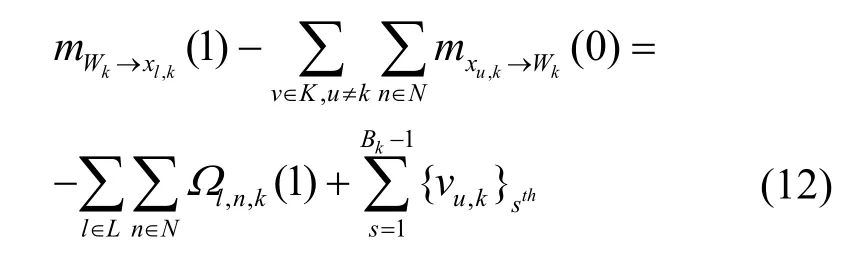
当xl,k=0时,式(11)的值为
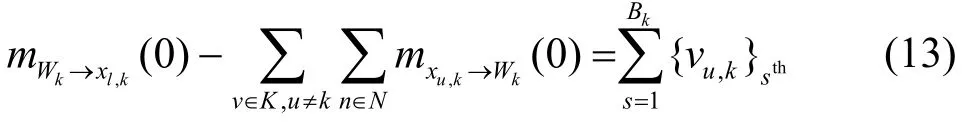
定义标量信息μl.k,,则式(12)减去式(13)得


通过式(14)和式(15)可求得用户与基站的边缘,如式(16)所示。

用户与基站的匹配结果如式(17)所示。

通过迭代计算,可得xl,k最终收敛,即,得到最终的用户与基站的匹配结果。
3.2 DC 功率分配策略
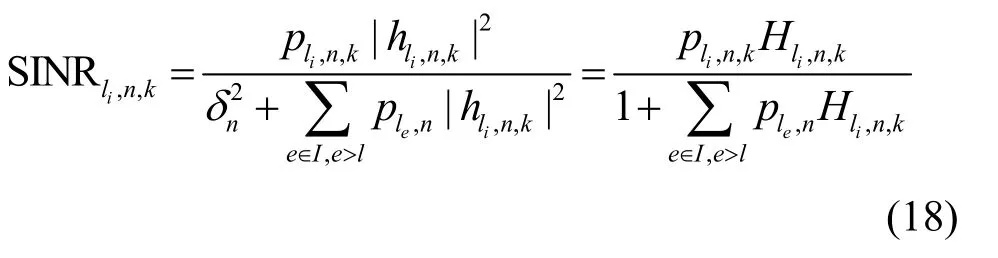
用户li的信息速率为
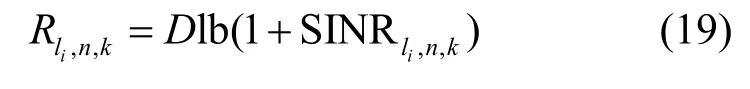
为了降低接收机的解码复杂度,考虑每个信道仅分配2 个用户的情况,将式(18)代入式(19),可得用户l1和用户l2的信息速率分别为
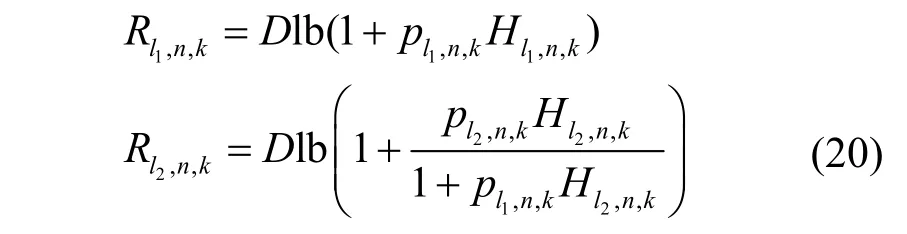
令pn,k=pl1,n,k+pl2,n,k,可得

其中,ρn∈(0,1)表示信道带宽。因此,最大化缓存收益P1可表示为P2,如式(22)所示。

由于P2为非凸优化问题,要找到其全局最优解需要进行穷举搜索,该搜索过程具有很高的复杂度,因此采用式(23)所示的DC(difference of convex)规划来寻找问题次优解[11]。

DC 规划适用于形式为2 个凸函数相减的目标函数,分别令


f(ρn,k)和g(ρn,k)为严格凸函数、f(pn,k)和g(pn,k)为拟凸函数,证明过程如下。
证明对于f(ρn,k)和g(ρn,k),由于变量只存在于分母中,可求得∇2f(ρn,k)> 0和∇2g(ρn,k)> 0,故f(ρn,k)和g(ρn,k)为严格凸函数。
对于f(pn,k)和g(pn,k),令
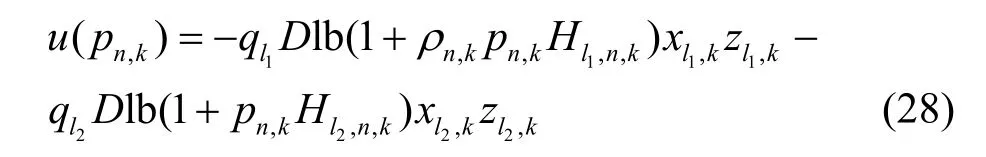
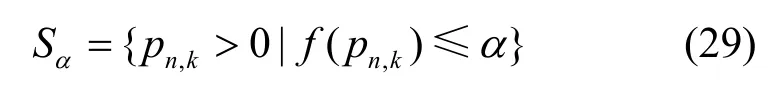
当Sα对于任意α均为严格凸集时,f(pn,k)为拟凸函数。当α≥ 0时,由 于u(pn,k)< 0,pn,k+pc> 0,因此f(pn,k)< 0≤α,故当α≥ 0时,Sα为严格凸集;当α< 0时,Sα={pn,k>0|u(pn,k)-α(pn,k+pc)≤0},α(pn,k+pc)< 0,由于u(pn,k)为严格凸函数,故当α< 0时,Sα也为严格凸集。因此,f(pn,k)为拟凸函数。同理可证g(ρn,k)也为拟凸函数。
证毕。
因此,P2可以转化为以pn,k和ρn,k为变量的2 个DC 规划问题。对这2 个问题先后进行求解即可得到以最大化缓存收益为目标的局部最优功率分配结果。
3.3 NOMA 联合优化算法流程
通过迭代计算NOMA 联合优化算法,直至NOMA 下行网络缓存收益稳定,得到了最终的用户协同及功率分配结果,具体算法流程如算法1 所示,其中,ε表示差值容限,当小于此值时便停止迭代。
算法1NOMA 联合优化算法
1)初始化部署缓存的NOMA 下行网络,初始化用户功率。
2)消息传递用户协同

3)DC 功率分配

4)对步骤2)和步骤3)进行迭代运算,获取网络模型优化的缓存收益
4 实验仿真
4.1 实验的建立过程
在部署缓存的NOMA 下行异构网络下,本文对提出的联合用户协同及功率分配算法进行了实验仿真。异构网络模型包含一个宏基站和19 个小基站,小基站均匀地分布在宏基站的覆盖范围内。在NOMA 系统中,为减少接收机配置的复杂度,一个信道只分配2 个用户,在正交频分多址(OFDMA,orthogonal frequency division multiple access)仿真中,采用与NOMA 联合优化算法相同的算法流程,但不同的是一个信道只分配一个用户。考虑即使用户所属基站中没有所需要的缓存内容,但用户仍有多种方式获取网络中的缓存内容,因此本文默认用户能获取缓存内容。其他实验参数如表1 所示。

表1 仿真参数设置
4.2 仿真结果分析
系统容量随总发射功率的变化曲线如图3 所示。从图3 可以看出,随着总发射功率的增加,系统容量逐渐提升,且提升量逐渐减小,这符合香农公式。本文将 NOMA 联合优化算法与MPFT-RA(message passing and fractional transmit resource allocation)次优化算法及OFDMA 方案进行对比,NOMA 联合优化算法中设置ε为0.01;在MPFT-RA 次优化算法中,,其中,α∈(0,1)表示比例因子,本文将α设置为0.7。在总发射功率从10 W提升到60 W 的过程中,本文所提出的NOMA 联合优化算法的系统容量始终是最高的,MPFT-RA次优化算法次之,OFDMA 方案最低。这是因为在OFDMA 方案中,由于一个信道只分配一个用户,频谱资源不能得到充分的利用,而MPFT-RA次优化算法只根据信道增益情况以固定的衰减系数来分配功率,因此没有获得更好的缓存收益。
缓存收益随总发射功率的变化曲线如图4 所示。从图4 可以看出,随着总发射功率的增加,总缓存收益先上升后缓慢下降,这是因为NOMA联合优化算法将缓存增益ol,k设置为系统的能量效率,而在能效功率分配过程中,系统的功率消耗和系统容量存在权衡,在权衡的过程中随着总发射功率的增大,能效先达到最大值然后逐渐降低。从图中可以看出,NOMA 联合优化算法的缓存收益高于MPFT-RA 次优化算法和OFDMA 方案。在总发射功率为25 W 时,NOMA 联合优化算法的缓存收益较MPFT-RA 次优化算法提升了约14%,较OFDMA 方案提升了约23%。

图3 系统容量随总发射功率的变化曲线
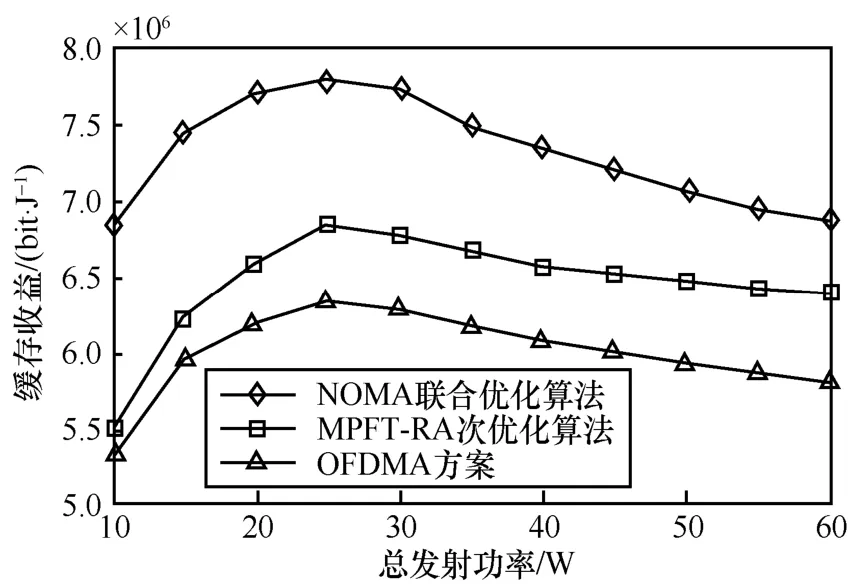
图4 缓存收益随总发射功率的变化曲线
缓存收益随电路能耗和总发射功率的比值的变化曲线如图5 所示。设置总发射功率为20 W,当电路能耗和总功率的比值变大时,意味着电路能耗在小区总能量消耗中所占的比例变大。随着电路能耗和总功率的比值的增大,缓存收益降低,这是因为在缓存收益计算式中,缓存收益与电路能耗与发射功率之和成反比。从图5 可以看出,NOMA 联合优化算法始终优于OFDMA 方案。
图6 和图7 为缓存收益随总用户数量的变化关系,仿真时用户的数量由40 个增加到80 个。从图6和图7 可以看出,随着用户数量的增加,本文所提算法的缓存收益也随之提高,这与香农公式是一致的。图6 对部署缓存和无缓存2 种情况下NOMA联合优化算法的缓存收益进行了对比。从图6 可以看出,在部署缓存的情况下缓存收益明显提升。图7对NOMA 联合优化算法与传统的最大化信噪比算法进行对比,从图7 可以看出,当用户数量为80 个时,NOMA 联合优化算法的缓存收益约为最大化信噪比算法的8 倍。这是因为每个基站的负载能力是有限的,NOMA 联合优化算法是在协调系统负载的情况下来寻求最大的缓存收益。而最大化信噪比算法的目标是最大化用户速率,并不考虑负载均衡和缓存收益,因此通常不会达到很高的缓存收益。与最大化信噪比算法相比,本文提出的NOMA 联合优化算法在缓存收益方面有了显著的提高。
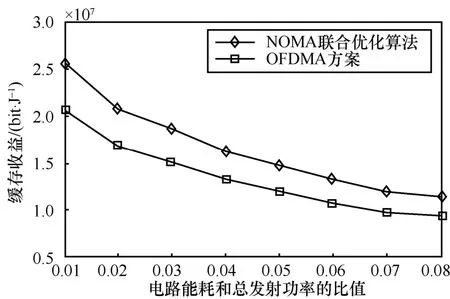
图5 缓存收益随电路能耗和总发射功率的比值的变化曲线

图6 缓存收益随总用户数量的变化关系(是否部署缓存)
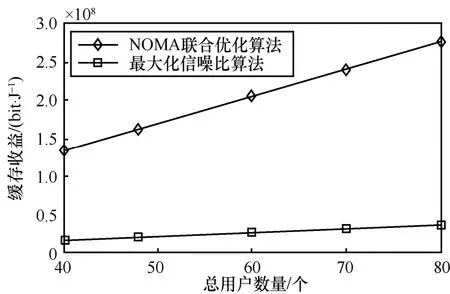
图7 缓存收益随总用户数量的变化关系
5 结束语
由于下一代移动通信网络对数据速率、时延和能耗都有更高的要求,为满足用户的服务需求,在NOMA 异构网络中部署缓存;为提升网络的缓存收益,提出了一种功率分配和用户协同方案。经过理论分析和仿真验证,与现有方案对比,所提算法能有效地提升缓存收益,这为未来无线异构网络部署缓存提供了理论依据。
