基于YOLO算法的行人检测方法
2020-05-09汪慧兰许晨晨张保俊
戴 舒,汪慧兰,许晨晨,刘 丹,张保俊
(安徽师范大学 物理与电子信息学院,安徽 芜湖 241000)
0 引言
随着汽车保有量的增加,有效地检测和识别道路交通场景下的行人目标,对减少交通事故、保证行人的出行安全具有重要的研究价值与现实意义。因此作为基于图像视频序列中的场景目标检测之一的行人检测一直是计算机视觉领域的研究热点[1-2]。随着人工智能快速发展,基于卷积神经网络的目标检测算法[3-4]逐步取代了采用机器学习的传统目标检测的方法[5],显著提升了目标检测的精确度和鲁棒性。目前基于深度学习的目标检测任务主要有以下两类检测方法:一类是基于区域建议提取目标候选区域的两步检测网络,通常具有高检测精度,如Fast-RCNN[6],Faster-RCNN[7],Mask-RCNN[8]等;另一类是基于回归思想的单步检测模型,如YOLO(You Only Look Once)[9],SSD[10]以及在此基础上改进的检测模型[11-13]等。从COCO,VOC等公开数据集上进行测试分析,单步检测网络虽然在精度上稍稍逊色,但在检测速度方面能更好地达到实时检测。相比通用的目标检测任务,交通场景下的车辆行人川流不息,行车安全至关重要,需要以最快速度将行人目标准确检测出来,这对目标检测算法的运行速度提出了更高的要求。综合考虑,本文针对道路交通场景下的行人目标检测任务,采用同时兼顾速度和检测精度的YOLO[9]算法进行研究。
1 YOLO网络模型
YOLO最早是由Joseph Redom 等人于2016年在CVPR上提出的一个端到端的深度卷积神经网络模型[9],相比基于区域建议提取目标候选区域的两步检测网络,在检测速度方面能更好地达到实时检测。但是由于输入图像尺寸固定,对检测速度造成了一定程度的限制,同时每个格子最多只预测出一个物体,当物体占画面比例较小或重叠时,对较小的目标检测效果不好。所以基于YOLO一代的问题,YOLOv2[11]提出了一些改进和提升。首先在卷积层后加入批量标准化操作[14],给模型收敛带来显著的提升;其次,输出层使用卷积层替代全连接层,采用k-means在训练集上进行聚类产生合适的先验框使得模型的表示能力更强,任务更容易学习;训练时每隔几次迭代后就会微调网络的输入尺寸,这使得网络可以适应多种不同尺度的输入。但是由于该算法仅检测最后一层卷积输出层,小物体像素少,经过层层卷积,在这一层上的信息几乎体现不出来,导致难以识别,所以对于小物体的检测,YOLOv3[12]在这部分提升明显。
1.1 YOLOv3网络架构
YOLOv3采用特征融合以及多尺度检测的方法,使得目标的检测精度和速度得到有效提升。YOLOv3的网络架构从YOLOv2的darknet-19[11]已经发展到darknet-53[13],去掉了YOLOv2中的池化层和全连接层,并且在前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的。同时,YOLOv3采用了残差的设计思想,用简化的残差块加深了网络结构,这样的改进使得网络的速度得到很大的提升,YOLOv3结构如图1所示。
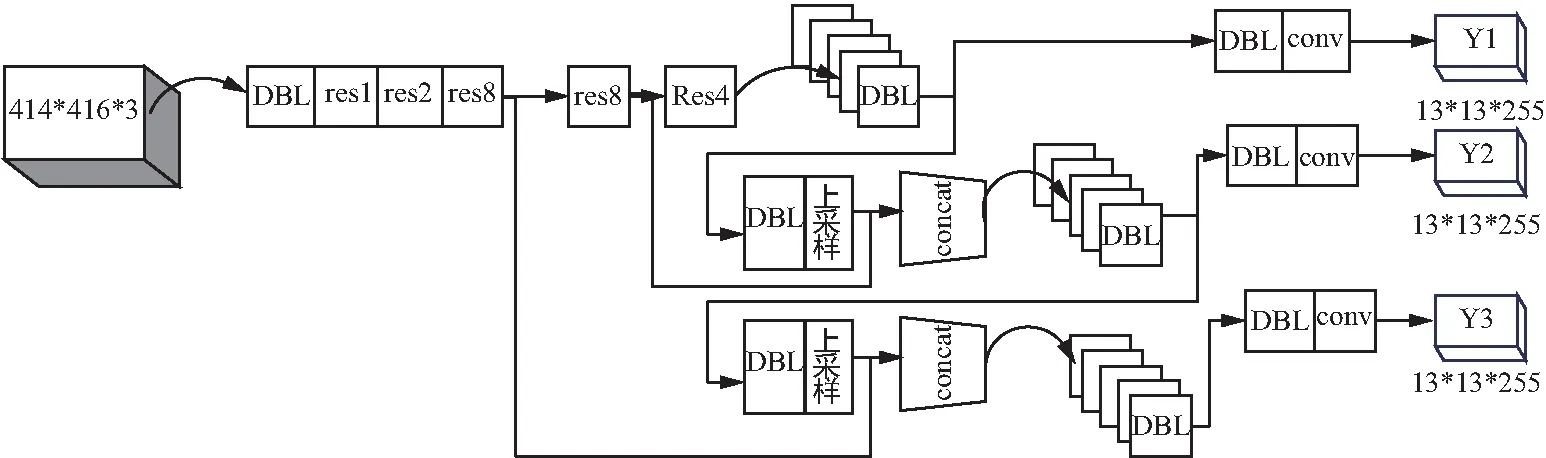
图1 YOLOv3的结构图Fig.1 Structure of YOLOv3
darknet-53与网络结构对比如表1[13]所示,通过与网络结构比较,可知darknet-53与ResNet-101[15]或ResNet-152[15]的准确率接近,但速度更快。
表1 Darknet-53与网络结构对比Tab.1 Darknet-53 is compared with other network structures

BackboneTop-1Top-5Bn OpsBFLOP/sFPSDarknet-19[11]74.191.87.291 246171ResNet-101[15]77.193.719.71 03953ResNet-152[15]77.693.829.41 09037Darknet-53[13]77.293.818.71 45778
1.2 分类器设置
针对小目标漏检率高的问题,YOLOv3增加了从上至下的多级预测,输出了3个不同尺度的特征图,如图1所示。这里借鉴了特征图金字塔网络[16](Feature Pyramid Networks,FPN),采用多尺度来对不同大小的目标进行检测,其中,Y1,Y2,Y3的深度都是255,边长的规律是13∶26∶52。这是因为对于COCO类别而言,有80个种类,所以每个候选框应该对每个种类都输出一个概率。YOLOv3设定的是每个网格单元设置3个候选框,所以每个候选框需要有(x,y,w,h,confidence)5个基本参数,然后还要有80个类别的概率,所以网络输出的维度为3×(5+80)=255。
本文针对道路交通场景下的行人目标检测来说,只检测行人这一个类别,输出维度的张量应为3×(5+1)=18。所以本文在原来YOLOv3的基础上修改模型的分类器,将网络模型的输出修改为18维度的张量。
1.3 损失函数
YOLOv3的损失函数主要分为三部分:目标置信度损失Lconf(o,c),目标分类损失Lcla(O,C),以及目标定位偏移量损失Lloc(l,g),其中,λ1,λ2,λ3为平衡系数。总的损失函数如式(1):
L(O,o,C,c,l,g)=λ1Lconf(o,c)+λ2Lcla(O,C)+
λ3Lloc(l,g)。
(1)
YOLOv2的分类损失为交叉熵,针对COCO数据集,使用一个80类的交叉熵可以实现。YOLOv3在分类损失上不使用softmax+交叉熵来做,而是使用n个二值交叉熵来实现。比如在COCO上,使用Logistic+二值交叉熵处理,将一个80分类问题转化为80个二分类问题。具体来说,与YOLOv2不同,YOLOv3的损失函数最大的变动就是置信度损失和分类损失换成了二值交叉熵损失,其能刻画两个概率分布之间的距离,也就是说,交叉熵值越小,两个概率分布越接近,同时利用sigmoid将神经网络的输出映射到一个(0,1)区间。目标置信度损失和目标分类损失分别如式(2)和式(3)所示,都采用了二值交叉熵损失。
(2)
(3)

由式(2)和式(3)可知,当第i个网格的第j个bounding box负责某一个真实目标时,才会去计算分类损失函数。对于一幅图像,一般而言大部分内容是不包含待检测物体的,这样会导致没有物体的计算部分贡献可能会大于有物体的计算部分,这会导致网络倾向于预测单元格不含有物体。因此,本文通过减少没有物体计算部分的贡献权重来提高检测的精确度。
目标定位偏移量损失如式(4)所示。采用的是真实偏差值与预测偏差值之差的平方和。
(4)

2 YOLO算法的应用比较
基于以上分析,将YOLOv2和YOLOv3目标检测算法应用到针对道路交通场景下的行人目标检测当中,对两种网络模型得到的行人目标检测结果进行客观分析,验证了基于YOLOv3的行人检测方法的有效性。图2展示了基于YOLO的行人检测算法的流程框图。

图2 基于YOLO的行人检测算法的流程框图Fig.2 Flow diagram of pedestrain detection algorithm based on YOLO
2.1 行人数据集的制作
为使训练数据集具有较高的质量,实验主要从VOC2007数据集中获取包含行人的图片1 000张,根据Pascal VOC的标签标注标准,使用LabelImg标注工具,生成训练所需要的xml文件,每一个图片名对应一个相应名字的label.xml。为提高模型的检测能力,选择加州理工大学提供的Caltech Pedestrian Benchmark行人检测数据库,将获得的不同时间段的视频按1帧/s进行截图,获取训练样本后再进行筛选,得到包含图片和标签文件的行人数据集共2 000张,最后将图片生成相应的训练集和测试集文件。图3为训练集及测试集中部分样本图像。

图3 训练集及测试集中部分样本图像Fig.3 Sample images of part of training set and test set
2.2 网络训练过程
本实验操作系统为Linux 16.04.5LTS,实验显卡为NVIDIA GeForce GTX1080GPU,GPU数量为4,系统的内存为64 G,CUDA的版本为9.0。
为了加速网络参数的训练,通过加载darknet53的预训练模型,修改参数文件,设置batch=64,subdivisions=8,这样每轮迭代会从所有训练集里随机抽取64个样本参与训练,64个样本又被均分为8组,送入网络进行训练,减轻内存占用的压力。如果学习率设置过大,权值更新速度过快,容易越过最优值;相反,学习率设置得太小又更新得慢,效率低。所以将学习率调整到0.001,加快网络的收敛。当迭代次数大于1 000时,采用policy的更新方式。在此基础上利用行人数据集进行模型的训练并保存日志文件。
3 实验结果分析
3.1 损失函数及Avg IOU曲线分析
算法损失变化曲线如图4所示,纵坐标Avg Loss值表示整个网络结构在训练过程中损失函数的变化情况,最后期望趋近于0。观察可知,YOLOv3在前几百次的迭代中损失函数值较大,之后从0.6骤然下降到0.1附近,当训练迭代到4 000次时,学习率衰减10%,损失值缓慢下降。到达6 000次迭代时,学习率又会在前一个学习率的基础上再衰减10%,学习速率变慢,损失函数值小幅度减小。14 000次以后,损失函数的值基本不再减小,趋于稳定。YOLOv2在接近5 000次的迭代后,损失从一开始的25下降到1附近,之后损失值缓慢下降趋近于零,到达40 000次的时候基本趋于稳定。分析比较可知,YOLOv3较YOLOv2在训练过程中,损失下降迅速,网络更加稳定且收敛较快。IOU值变化曲线如图5所示,Avg IOU表示在当前迭代次数中,候选框与真实标记的边框之间交集与并集的比值。它的值最好趋近于1。
观察曲线的变化情况,可知随着迭代次数的增加,YOLOv2的Avg IOU值整体呈上升趋势,但震荡严重,不够稳定;YOLOv3的Avg IOU值整体呈不断上升趋势,迭代次数到达5 000次以后,基本趋近于期望值1,矩形框跟目标较好重合,模型检测行人目标性能较优。
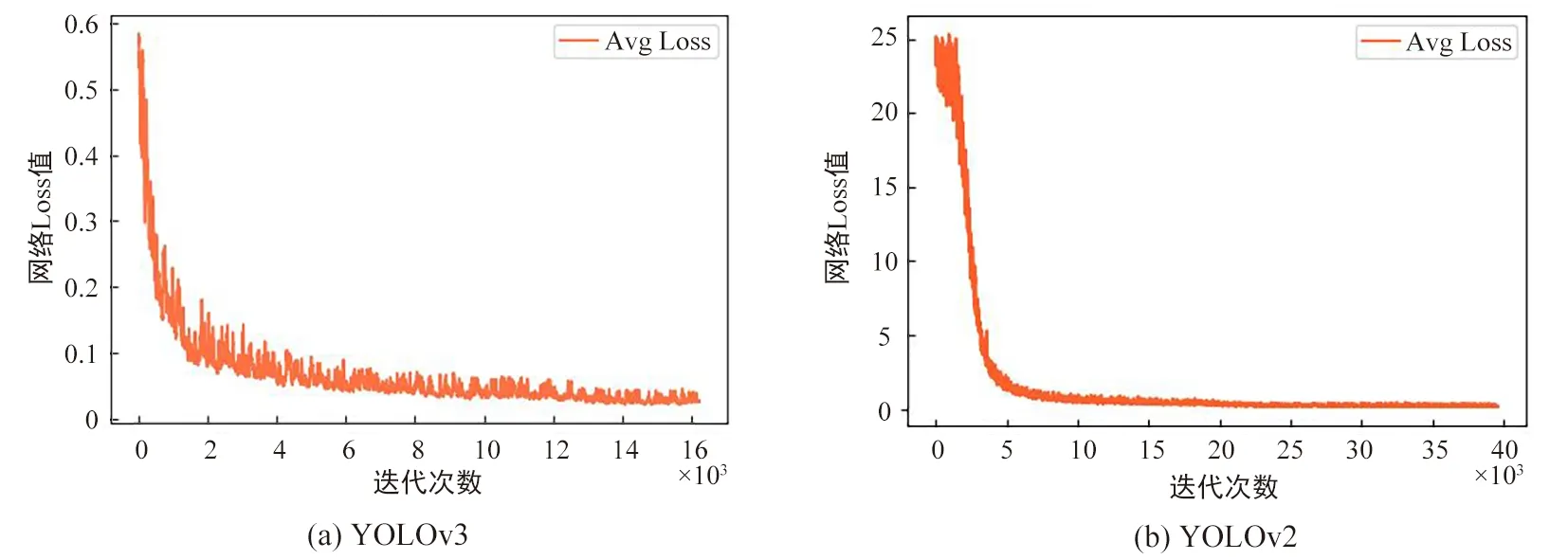
图4 损失变化曲线Fig.4 Loss curve

图5 IOU值变化曲线Fig.5 change in IOU
3.2 模型检测准确度分析
训练完成后,将测试集分别输入到训练好的两种网络模型中进行测试验证,得到YOLOV2和YOLOV3两种目标检测算法对测试集中行人样本的检测结果,部分识别结果分别如图6和图7所示。

图6 YOLOv2的行人目标识别结果Fig.6 Pedestrian target recognition results of YOLOv2
通过观察识别结果可知,当图像中的行人目标大量重叠时,YOLOv2的识别率较低,有漏检现象,YOLOv3的识别效果较好。对于光线较暗以及目标像素较模糊的图像,相较于YOLOv3,YOLOv2行人目标存在漏检和误检现象较严重,YOLOv3的检测精确度更高。分析可知,YOLOv3在数据复杂多变的情况下,神经网络模型的泛化能力更好,抗干扰能力更强,可以有效应对在实际场景下的运动模糊和光线较差等不良因素。对两种算法在1 000张行人样本测试集中的识别结果进行统计,采用准确率和召回率对识别结果进行比较,各项指标对比情况如表2所示。
表2 两种网络模型的各项指标对比
Tab.2 Indexes of the two network models are compared

检测模型准确率/%召回率/%平均准确度/%YOLOv287.2982.8682.69YOLOv395.4393.3789.78
分析以上数据可知,基于本文的行人数据集,相对于YOLOv2,YOLOv3的准确度提升8.1%,召回率提升10.5%,平均准确度提升7%。同时,由于YOLOv3网络架构纵横交叉,许多多通道的卷积层没有继承性,而且每个真实目标矩形框只匹配一个先验框,每个尺度只预测3个框(YOLOv2预测5个框),降低了网络的复杂度,使得YOLOv3的检测速度较快,对于320*320的图像,YOLOv3的检测速度可以达到22 ms。
4 结束语
本文详细阐述了利用YOLO网络模型来实现复杂道路交通场景下的行人检测方法,包括修改模型的分类器以及优化网络参数。实验结果表明,YOLOv3无论是在检测精度还是速度上都远远超过YOLOv2,取得了良好的检测效果,并且模型具有较强的泛化能力。下一步,针对模型对图片中重叠目标的漏检情况,可从增加训练样本图片的数量和质量来着手,也可通过改进网络结构,使其在具有密集目标的场景下提高检测的准确率。
