人体活动识别数据集的数据处理方法
2020-05-08钟楚轶朱建军
钟楚轶 ,朱建军
(1.长春博立电子科技有限公司,吉林 长春 130012;2.吉林化工学院 信息与控制工程学院,吉林 吉林 132022)
人类活动识别(简称HAR)是通过收集和分析其运动数据来对人正在做的事情进行定义和分类[1-2].除了采用图片形式的数据集对模型进行训练,传感器数据集也被广泛应用到人体活动识别问题当中.传感器数据序列是由智能手机或可穿戴式传感器收集的,然后对数据进行分析并将其分类为已知的明确定义的运动或活动,例如坐着、跑步或跳跃等[3-5].目前的研究难点在于每秒大量的观测数据、观测时间的连续性以及缺乏将加速度计数据链接到已知运动的明确方法.随着机器学习以及人机交互技术的发展,神经网络技术现在已经被成熟运用到各个领域,在人体活动识别领域中,神经网络识别出的结果可以达到很高的水平,但存在的困难仍然是海量数据的处理[6-9].传统采用传感器数据集对神经网络模型进行训练时,数据集中包含大量的噪声干扰以及无效数据,会影响训练效率以及神经网络的性能.提出一系列针对传感器数据集的处理方法与见解:1.如何准备和预处理传感器时间序列分类数据;2.如何根据数据可视化对数据集进行优化;3.构架问题,搭建神经网络和HAR网络模型的评估和改进.
1 数据集可视化处理
1.1 个体数据可视化处理
图1、2是两个不同参与者身上传感器所收集的数据组的可视化.对比发现在总体趋势一致的情况下仍可以看到一些差异:与图1相比,图2的整体波动更大,每个部分的边界更加模糊.在图1、2各自的第4个子图中,可以看到整个序列是相似的,并且某些动作匹配得很好.但是,它们之间仍然存在一些差距,例如图2输出的类别7的持续时间比图1输出的持续时间更长,并且其中没有0值.每一个类别代表一种动作,因此可见数据中存在一些误差或无效数据.
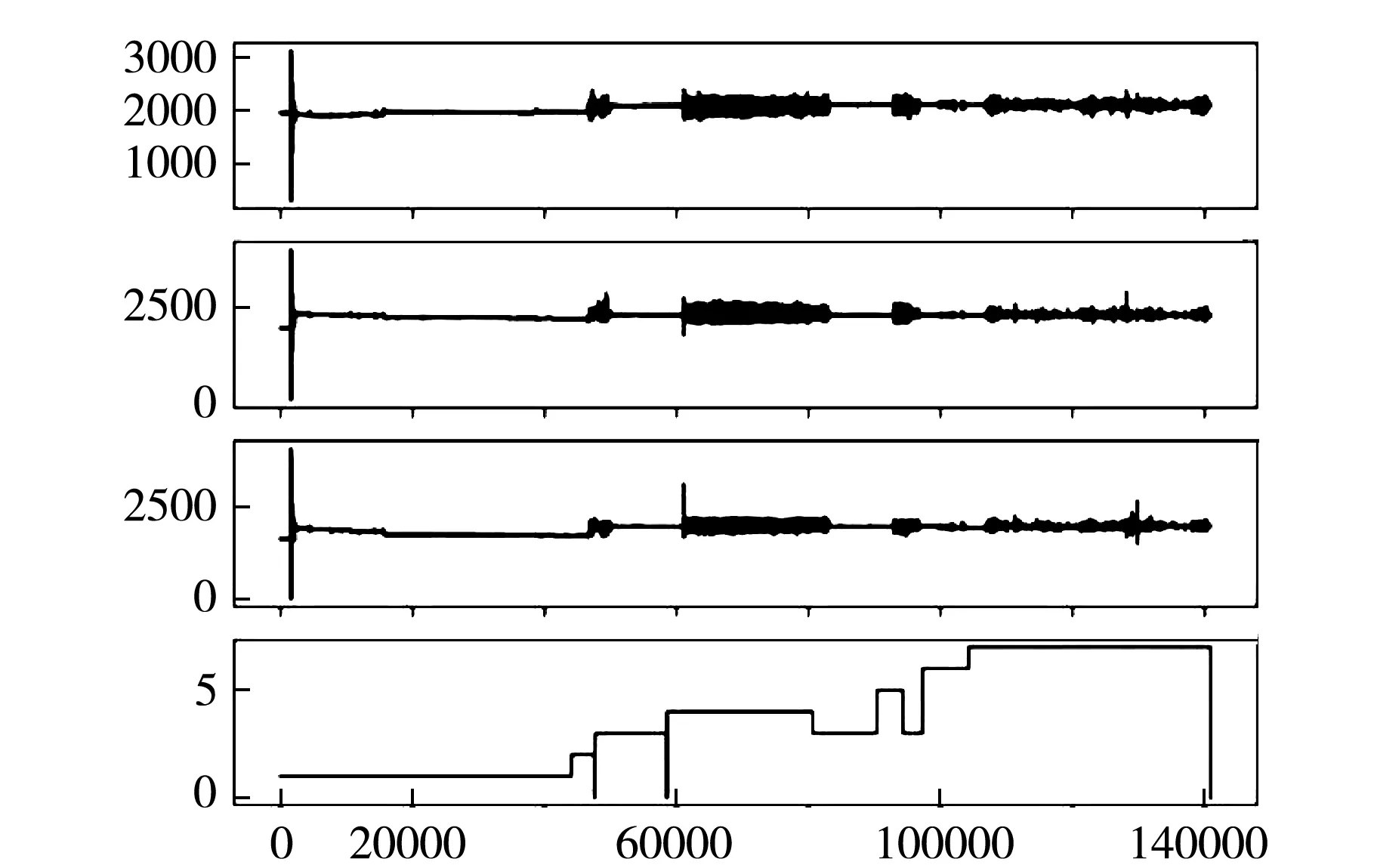
图1 单个个体参与者数据组可视化a
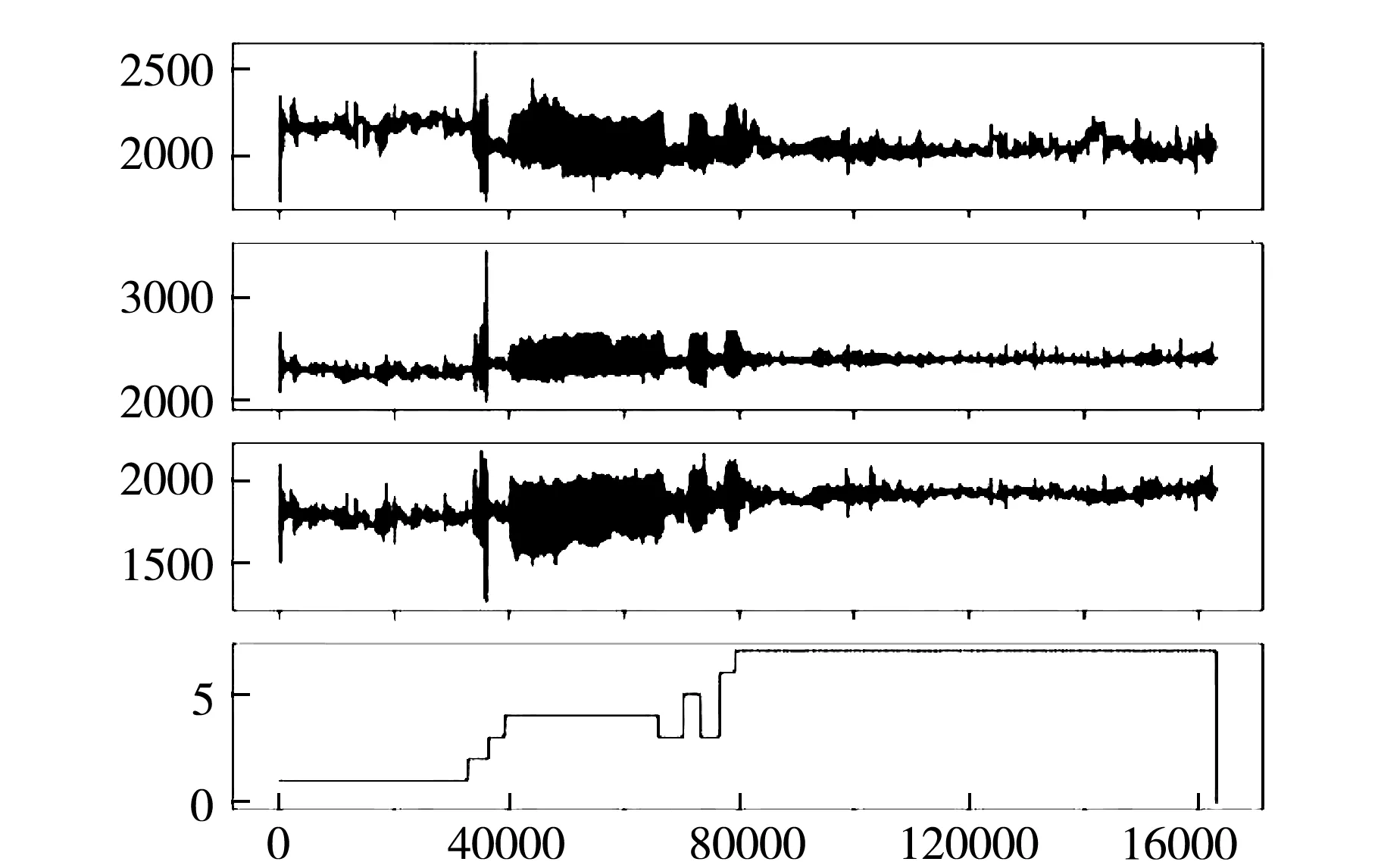
图2 单个个体参与者数据组可视化b
这些误差或无效数据可能是由于每个个体受试者执行一系列动作所花费的时间、每个动作之间是否存在延迟以及每个个体身体运动幅度的差异所产生的影响.这些影响看似微弱,但实际上严重干扰了结果的预测.例如,每个单独活动之间的延迟可能是受试者站立或坐一段时间,这可能被检测为活动站立或坐,这样的数据在网络模型训练中会造成很多不必要的计算,影响训练效率并会干扰到网络模型的性能.
为了避免上述问题的发生,需要进一步对数据进行处理,弄清楚每个活动持续的时间,由此可以判断出哪些部分是噪声,并去除掉这些噪声.如果在可视化中,一项活动的数据要多于另一项活动,这表明代表性较低的活动可能更难建模.采用盒须图的方式达到上述目的.
1.2 数据盒须图
按主题和活动将所有观察结果分组,以查看每个活动花费了多少时间以及每个个体花费在一个特定活动上的时间.图3显示了每个主题的每个活动持续时间的分布.每个盒里面的横线代表该活动持续时间的平均值,从图3中可以看到活动0(无活动)在整个时间序列中没有发生,而活动1(坐在电脑前)和活动7(站立交谈)出现的频次最多, 其他活动例如活动2(起立行走)、活动5(上下楼梯)以及活动6(和他人行走并交谈)出现的频次较少,通过图3,可以轻松了解活动在整个持续时间内的分布情况.在数据准备以及模型训练中,重复次数较少的活动可以排除在外,这样可以减少计算量,提升效率.
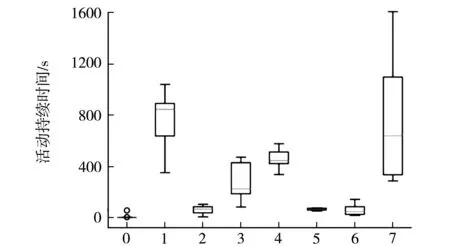
活动序号图3 数据盒须图
1.3 数据集整体数据可视化处理
了解单个个体的数据后,将着重研究15个个体整体的情况.图4(a)将15个个体的数据统一用图像表示出来,每个子图代表一个个体数据的轨迹,每个迹线是X,Y和Z加速器值的混合迹线.从图中可以看出,绝大多数的子图都由两个迹线叠加而成,这也符合对所有活动的理解,在每个个体所做的7项活动中,x,y轴方向发生的运动占了绝大部分,鲜有z轴方向上的活动轨迹.可以看出,两个迹线波动是同步的,这意味着X和Y加速器的一般变化是同时发生的.对于所有轨迹,都可以在开始时找到较大的峰值,这可能是实验启动的干扰,这些干扰会影响后面训练的进程,将被视为噪声被过滤掉.迹线看起来具有相同的比例,但幅度可能有所不同,例如将迹线1和2做比较,迹线1要平稳得多.迹线内的重新缩放似乎比交叉迹线好得多,如果这种情况发生在测试结果上,则会干扰相应的预测和识别.
图4(b)是15个对象的直方图.每个对象有3个直方图,分别代表X,Y和Z的加速器值.之前已经了解到Z加速器值数据在数据集中占的比例很小,因此在直方图中Z部分也很少出现.从图中可以看出,每个直方图的分布都类似于高斯分布.X加速器值和Z加速器值的直方图位于轴的左侧,Y加速器值直方图位于右侧.Y加速器值的分布比X和Z的分布更锐利.尽管看起来有些分散,但大多数直方图都聚集在2 000左右.这种现象表明,对每个主题数据的主题和轴上的坐标进行规范化非常重要(例如以单位方差平移到零均值,或标准正态分布).通过数据可视化,对数据集所包含的内容有了更深的理解,也方便处理数据集中包含的噪声和无效数据.至此,将对数据进行规范化,过滤掉噪声以及无效数据,提高使用数据的效率,因此也可以更好地对问题进行建模.

(a)数据集整体数据轨迹图
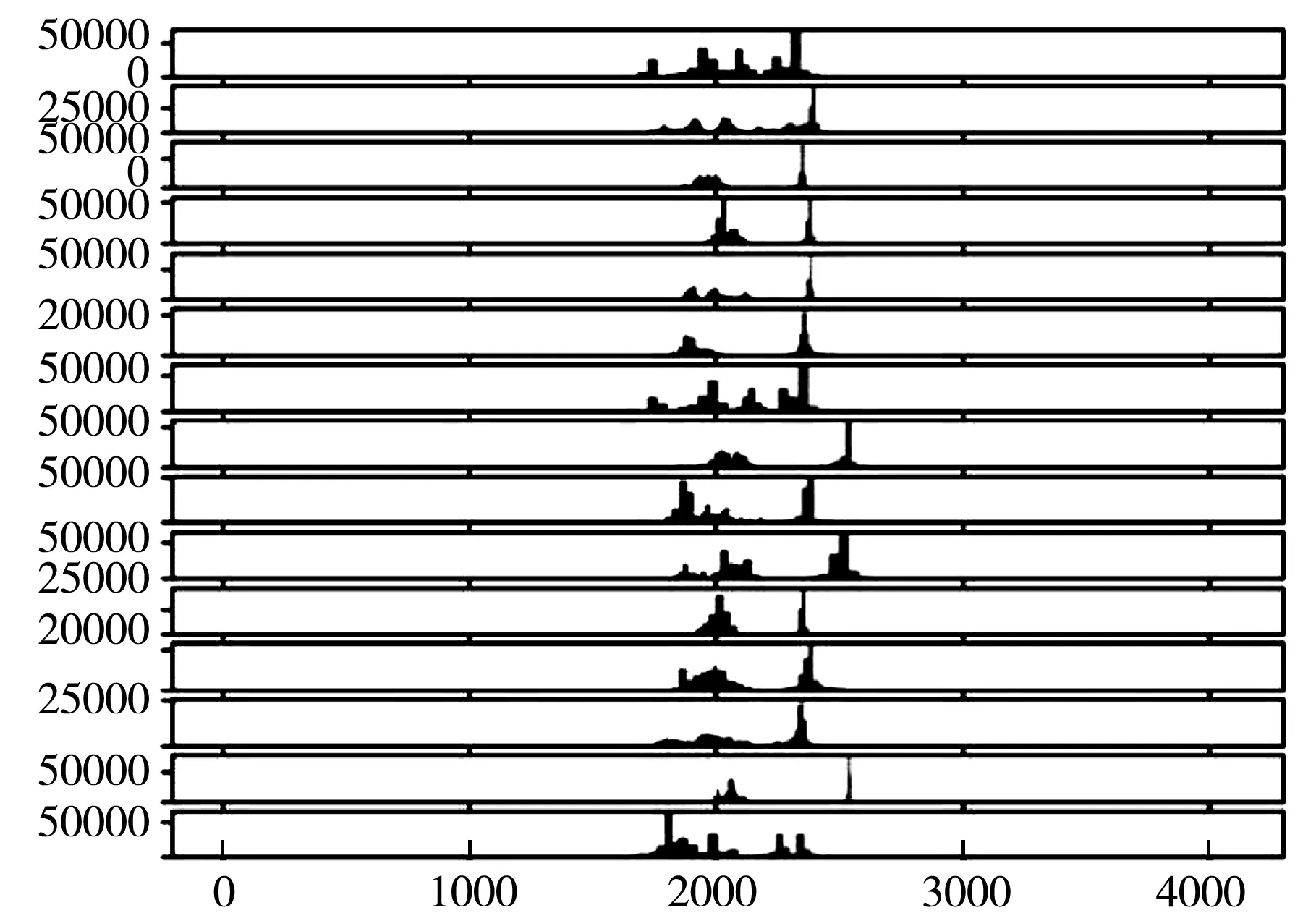
(b)数据集整体数据直方图图4 整体数据集可视化
2 模型搭建及测试
在对数据进行可视化分析处理之后,将数据载入一维神经网络中进行训练.从原始数据中过滤掉噪声以及无效数据,并设计一个滑动窗口作用于数据集上,数据将被分成2.56秒的窗口序列,窗口之间有50%的重叠值.数据集的70%(11个个体)用于训练,而30%(4个个体)用于测试.
一维神经网络模型将获得一维数据序列,它将学习从观测序列中提取特征,以及如何将内部特征映射到不同的活动类型.使用一维神经网络作为模型的优势在于,它可以直接从原始数据序列中学习,而无需领域专业知识来手动重新组织输入功能,从而提高了效率.一维神经网络模型可以学习数据序列的内部表示,并且在理想的情况下可以对具有工程特征的数据集进行模型拟合并达到出色的性能效果.
2.1 模型拟合
预期输出是一个六维的向量,其中包含活动类型和给定窗口的相对概率,模型的结构为:两层的一维卷积神经网络层,用于规范化的辍学层,以及池化层.池化是在卷积层之后通常在卷积网络中使用的特征提取层.池化技术用于在卷积层后获得的小邻域中集成特征点以获得新特征.一方面,它防止了无用参数增加计算时间和复杂度;另一方面,它增加了特征的集成.池化过程是提取高度抽象特征表示图像,图像具有“静态”属性,这意味着图像区域中的有用特征同样的可能适用于另一个领域.因此,为了描述大图像,集合不同位置的特征要素信息,通常取平均值或最大值用于汇总统计信息.CNN层(卷积神经网络)通常以二层为一组进行设计,因此该模型可以更好地从输入数据中学习特征.CNN模型的学习速度非常快,因此需要一个辍学层来减慢学习过程并获得更好的最终结果.池化层将有助于减少复杂度和优化学习功能,从而将其合并为最重要的特征元素.在CNN层和池化层之后,学习到的特征将作为矢量存储.在矢量到达输出层之前,它将经过另一个缓冲层,该缓冲层是学习的特征和输出之间的完全连接层,以便在预测之前进行最终积分.在本模型中,并行选择64个特征图,内核(Kernel Size)大小为3.特征图是输入被处理或集成的次数,内核大小是输入被读取或处理到特征图上所需要的时间单位.拟合模型后,将模型在测试数据集上进行评估,并将返回测试数据集来检测模型拟合的准确性.
2.2 模型测试
为了获得更高的准确性,通常进行多次实验,因此重复此过程数次以获得更好的结果.首先将采用未经过处理的原始数据集进行训练,随后在同样的网络模型结构下用处理后的数据集进行训练,训练后模型的准确率结果如表1所示.
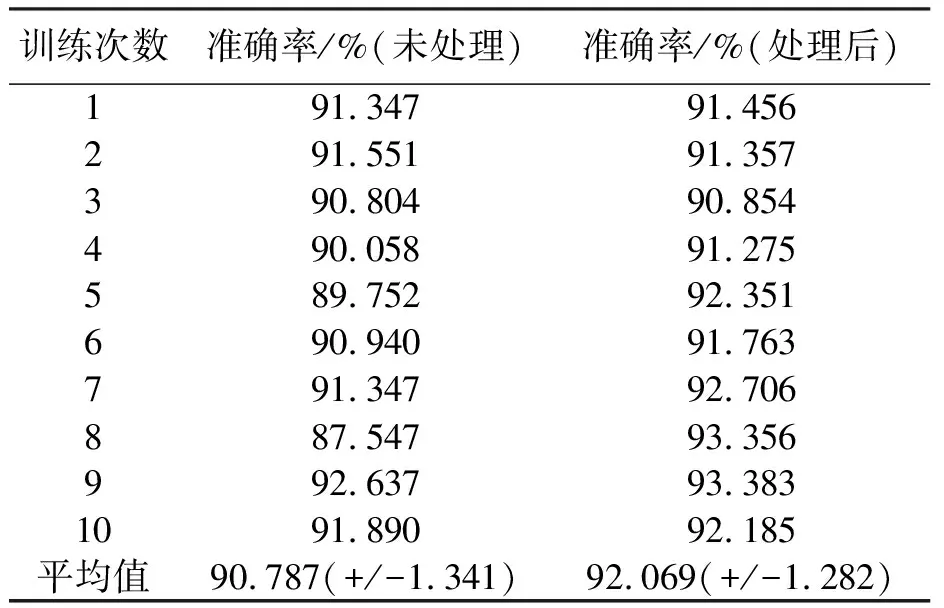
表1 训练结果对比
从表1数据对比可以看出,对数据集数据进行处理,可以使训练后的网络性能得到提升,与此同时,精简数据集后,减少了很多不必要的计算,提升了训练速度.一维神经网络模型在人体活动识别问题中可以取得不错的准确率(90+%).
3 结 论
通过对数据进行可视化处理,找到数据集中噪声以及无效数据,并去除掉这些干扰.随后构建一维卷积神经网络模型进行数据集的训练以及网络的机器学习.整个网络在python语言环境下搭建,并得出相应精准度结果.将原始数据集和经过处理后的数据集作用于同样结构的神经网络模型进行训练,通过对结果的对比分析,经过处理后的数据集使网络模型在训练后准确率得到提升,并通过精简数据集使训练速度和网络效率都有所提升.神经网络已经可以在人类识别方面得到不错的结果,后续可通过研究多维卷机神经网络以及其他神经网络从而得到更精准的结果,并延展到其他相关领域.
