一种基于大数据架构的地震科普资源库的设计和开发
2020-05-06刘勇赵军张乐
刘勇 赵军 张乐
摘 要:当今时代,愈发庞大的数据难以有效处理运用和管理,需要一种更加合适的资源获取处理方式。该文基于大数据架构结合网络爬虫、数据清洗、信息检索等前沿技术,设计开发了地震科普知识资源库系统。其中运用了J2EE、Python、Hadoop、Elasticsearch、MySQL等技术。通过网络爬蟲和人工上传的方式采集地震科普相关信息资源,经过数据清洗转换后对信息资源进行自动分类,最后将资源上传至资源库hdfs分布式文件系统并将文件信息保存至Elasticsearch分布式文件索引系统,由此实现大数据架构下的全文检索。同时,建立资源库的后台管理系统,用于网站的日常管理和维护。相比以前的集群文件系统更加高速便捷、更加的安全稳定。
关键词:大数据 Hadoop Elasticsearch MySQL Python
Abstract: In today's era, the increasingly large data is difficult to effectively handle the application and management, and a more appropriate resource acquisition and processing method is needed. Based on the big data architecture combined with web reptile, data cleaning, information retrieval and other cutting-edge technologies, this paper designs and develops the seismic science knowledge resource database system. It uses technologies such as J2EE, Python, Hadoop, Elasticsearch, and MySQL. The seismic science related information resources are collected by means of web crawling and manual uploading, and the information resources are automatically classified after data cleaning and conversion, and finally the resources are uploaded to the resource library hdfs ,distributed file system, and the file information is saved to the Elasticsearch ,distributed file index. So the system enables full-text retrieval under the big data architecture. At the same time, the background management system of the resource library is established for daily management and maintenance of the website. It is more convenient and safer than the previous cluster file system.
1 科普知识资源库的建设现状
1.1 资源库数据时效性低
一些资源在采集时没有考虑到数据资源的不断更新性特征,数据资源缺乏时代性和建设性,造成数据库的资源质量低[1]。
1.2 资源库数据利用率低
由于资源库的建设缺乏先进的理念和技术架构,造成各类资源库分散在不同的系统中,数据资源的整合缺乏层次性和规律性,整体上体现出综合性差。在使用搜索功能时,一切与搜索目标相关的资源都会呈现出来,但是这些资源,衡量的标准、规划的层次不统一,造成实际应用中的搜索难度大,利用率低。
1.3 资源库数据冗杂质量低
为了提高资源库的可用性和有效性,在资源库的建设中,往往采用大批量、大规模资源采购的方式,希望能够提高资源的应用水平。但是在实际应用中,这些采购的资源观点重复、模式相仿、形式单一,甚至有些存在明显的学术性错误,资源库的整体数量较多但是质量较低,无法有效地服务于用户。
2 地震科普资源库的架构
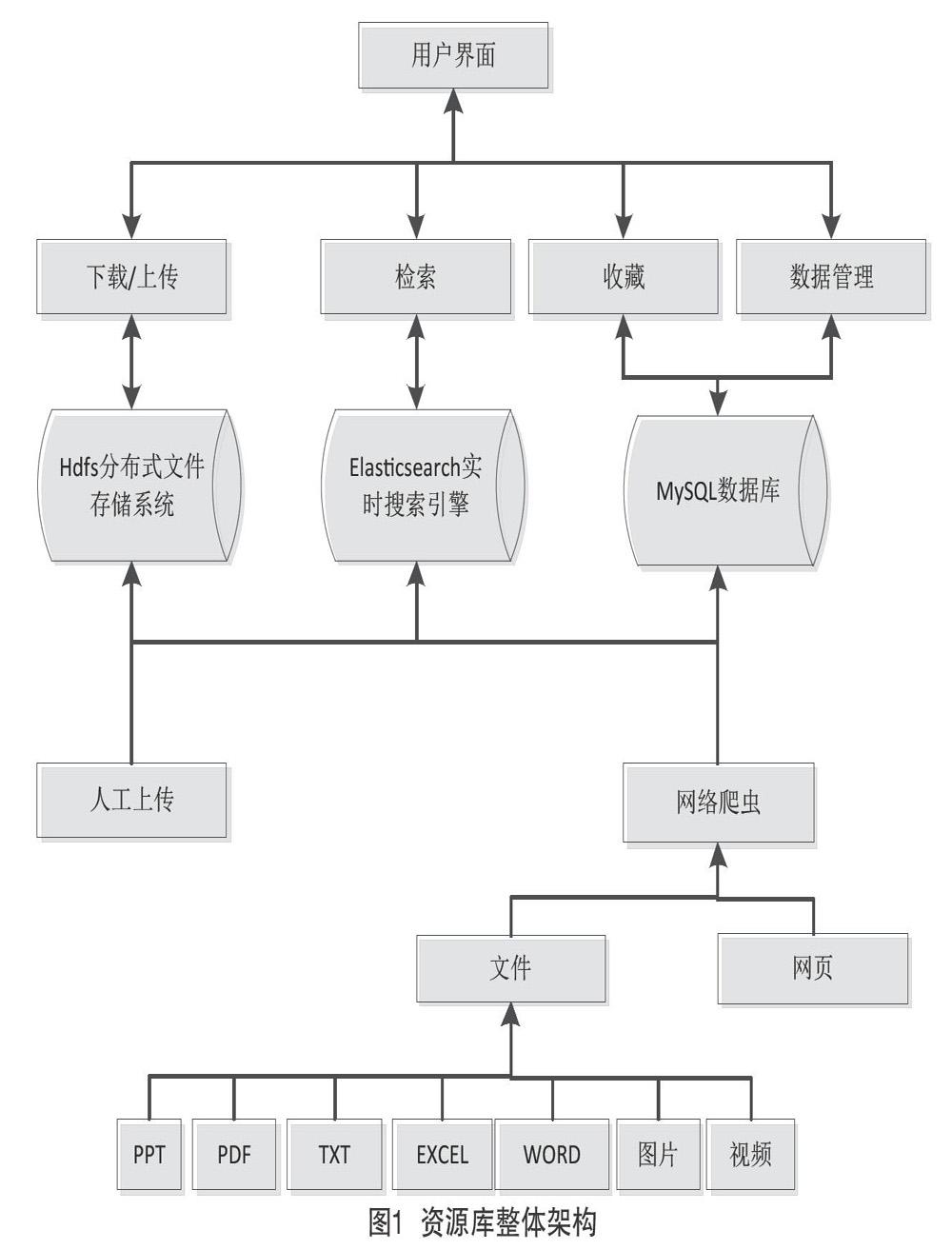
地震科普资源库是通过网络爬虫和人工上传两种方式进行数据采集并将记录保存至数据库中,然后对采集到的数据进行数据清洗,清洗之后根据既有分类标准将资源划分到对应的类别,最后,将文件上传至HDFS中,同时将资源信息保存至Elasticsearch中,以便用户进行全文检索和资源下载,资源库的整体架构如图1所示。
3 地震科普资源库的功能模块
3.1 数据采集
数据采集分人工上传和网络爬虫两种,使用爬虫抓取数据可以提高数据采集的效率。网络爬虫会根据给定网址进行爬取,通过spiderkeeper对爬虫进行管理。该文运用spiderkeeper配合scrapyd管理爬虫,支持一键式部署、定时爬取任务、启动、暂停等一系列的操作。
3.2 数据处理
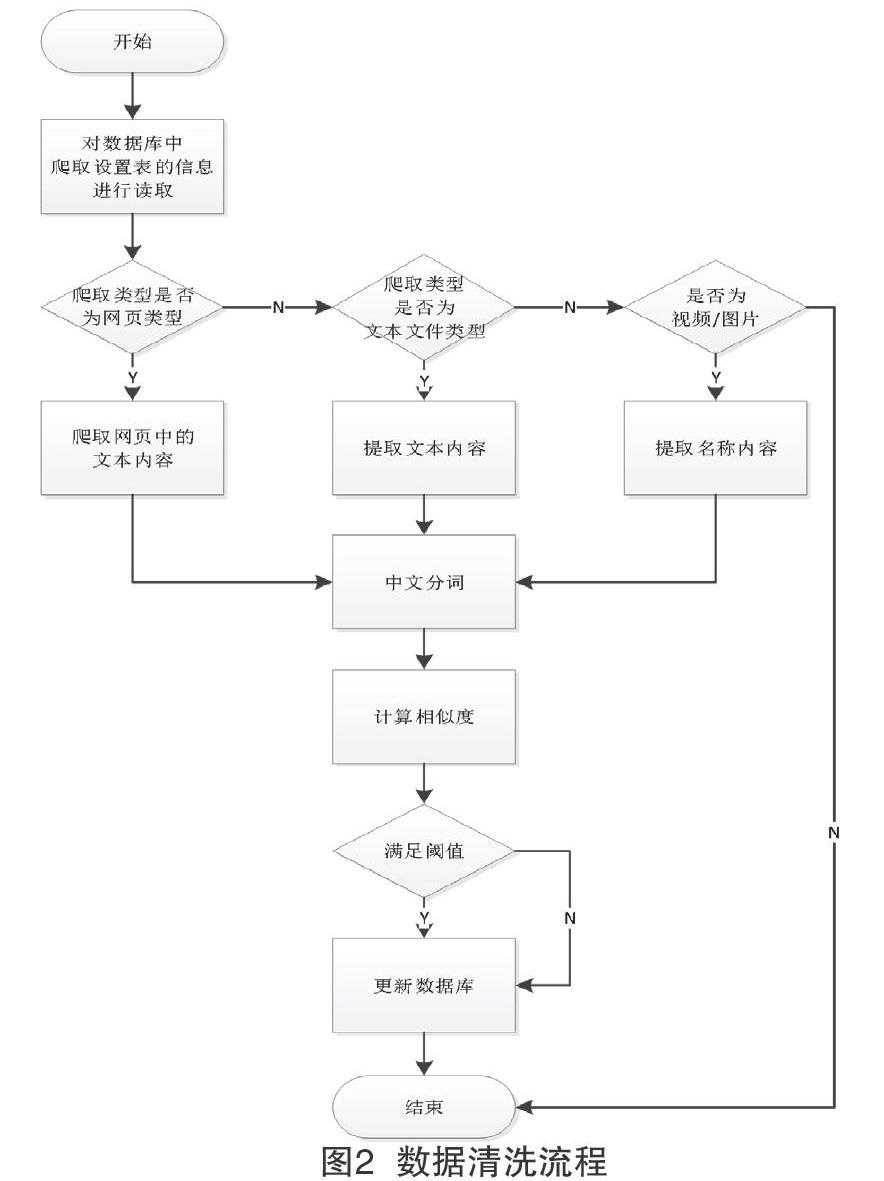
由于爬取的数据或上传的数据存在重复或不符合资源库的需求等问题,因此需要对资源进行清洗,将不符合要求的资源过滤掉。该文通过计算文本内容的相关度,将那些内容相关度低的资源过滤掉。数据清洗整体流程如图2所示。
首先,读取grasp_data数据表中的抓取记录信息,并判断数据的类型。如果是网页类型,按照网页内容的提取方式提取网页中的内容;如果不是网页,判断是否是文本文件类型(分别判断txt、doc、docx、xls、xlsx、pdf),如果是文本类型,根据文本类型按照相应的方式提取其文本内容;如果不是文本类文件,再判断是否为图片/视频类型,如果是图片或视频,则提取其文件名称内容,否则直接结束。
其次,采用IK分词技术对提取到的文本内容进行切分,去除无用的停用词,保留可以代表文件内容的关键词,同时读取数据库中的关键词及权重信息。基于VSM算法计算文本内容的相似度并设定阈值条件,相似度大于阈值说明文件符合要求,小于阈值则文件不符合要求。
最后,更新数据库抓取数据表中的数据处理标识和数据删除标识。
3.3 资源存储
地震科普资源库中的资源类型包括网页、文本、图片、视频等,数据类型较多,数据量较大,针对数据类型较多,建立sql数据表,将数据类型作为一个表项进行存储,将不同的数据存储到一个sql表当中,针对数据量较多,采用分布式文件系统,可以对海量数据进行存储。
3.4 资源检索
用户可以通过输入关键字、选择标签、选择资源分类等多种方式进行资源的在线检索,系统通过用户输入的信息进行统计,并提交到多个服务器上进行分布式资源检索,利用集群将多台服务器的检索结果进行高速运算和存储并返回给用户。利用ES框架構建索引库,提供搜索服务,Restful API支持搜索器可以在多台机器上相互合作、相互分工进行信息发现,以提高信息发现和更新速度;索引器可以将索引分布在不同的机器上,以减小索引对机器的要求。返回的结果需要经过多次的数据清洗,避免出现错误数据。系统将采纳率高、阅读次数多的资源进行优先展示。
4 相关技术
HDFS分布式文件存储系统主要用于各类资源的存储和下载,可运行于廉价的商用机器集群上,对硬件要求低,且具有很大商业价值。Elasticsearch是一个实时的分布式搜索和分析引擎,是天生为分布式执行数据分析操作而生的架构,海量数据下的近实时(秒级)性能支持,以及无比强大的搜索和聚合分析的语法支持,让ES更加适合进行大数据场景下的数据分析应用。
5 结语
在当今数据庞大可用度普遍不高的现状下,该文基于大数据架构开发的地震科普知识资源库系统对地震数据有效地处理分析,并保证信息的可用性和时效性,为地震科普资源提供一个高效的使用平台。在数据量日益庞大的社会趋势下,大数据相关技术必定会得到更为长足的发展。
参考文献
[1] Adrien Grand .Frame of Reference and Roaring Bitmaps[Z].2015-02-18.
[2] 怀特.Hadoop权威指南(中文版)[M].北京:清华大学出版社,2010.
[3] 范继魏.教学资源库现状及发展趋势分析[J].现代商贸工业,2016,37(31):153-154.
[4] Clinton Gormley,Zachary Tong.Elasticsearch:权威指南(中文版)[EB/OL].https://www.doc88.com/p-9993865282100.html.
[5] 董西成.Hadoop技术内幕:深入解析MapReduce架构设计与实现原理[M].北京:机械工业出版社,2013.
