面向大规模集群的并行I/O用户层配置优化策略*
2020-05-06田鸿运武林平景翠萍罗红兵莫则尧
田鸿运 ,武林平,董 勇,景翠萍,罗红兵,莫则尧
(1. 北京应用物理与计算数学研究所, 北京 100094; 2. 国防科技大学 计算机学院, 湖南 长沙 410073)
近年来,我国的超级计算机系统数量持续呈现快速增长的态势,2018年11月公布的TOP500榜单中,我国以227台数量排名第一,远超第二名(美国)的109台[1]。如何用好大规模系统,充分发挥系统的巨大算力,已经成为超级计算行业面临的共性挑战问题[2]。要解决好这个问题,需要应用、系统、厂商的科研人员大力协同。
当前,计算能力排名世界前十的超级计算机已经达到数十万至数千万处理器核(ABCI 391 680核,Sunway TaihuLight 10 649 600核),整机内存容量达到数百TB~数PB(PizDaint 169 TB~Summit 2.8 PB)[1]。虽然TOP500榜单的Linpack Benchmark只关注计算和通信的性能,缺乏对I/O性能的考量,然而随着系统规模和应用并行规模的持续增长,应用对I/O性能的需求已经越来越迫切。为了应对系统故障、异常等因素引起的超大规模并行场景下的运行时可靠性问题,检查点技术应运而生[3]。应用必须每隔一定时间步就将中间计算结果存入文件系统,这将爆发大量的I/O写操作。此外,在程序计算完成后,应用科学家还需要对计算结果进行后处理分析(如:可视化分析),这将产生大量的I/O读操作。因此,应用科学家对于大规模并行场景下的I/O性能越来越关注。
要充分挖掘并行文件系统的性能,既需要应用层I/O实现的优化(如:使用并行I/O接口替代POSIX串行I/O接口,如HDF5、MPI-I/O等),也需要系统级的并行I/O组件优化(如:Filter Cache技术[4]、MDDS技术[5]、针对MPI-I/O的优化[6]等),同时,还需要根据系统I/O特征对应用的I/O进行参数配置优化,这项工作需要应用用户、程序开发者和系统管理员协作来完成。例如,我们的测试发现,在大规模并行场景下,并非所有的作业进程都参与I/O操作时性能最优,而是应该根据作业输出目录使用的条带化数量动态调整。因此,需要在应用I/O特征的牵引下对大规模集群上的并行I/O性能特征开展有针对性地测试分析,从而指导应用I/O配置参数优化。
1 Lustre并行文件系统
目前,在超级计算机上广泛使用的并行文件系统主要有Lustre、GFS、GPFS、PVFS等。其中,Lustre占据绝对主导地位,在最近一期的TOP500榜单中,超过70%的超级计算机采用Lustre文件系统[1,7]。
1.1 Lustre文件系统架构
Lustre采用基于对象的存储技术,主要由元数据服务器(MetaData Server, MDS)、对象存储服务器(Object Storage Server, OSS)、客户端(Client)三部分组成。其中,MDS用于存储数据的描述信息,管理命名空间和目标文件的存储地址,元数据的存储目标称为MDT(metadata target)。为了增强元数据服务器的可靠性,Lustre支持多个MDS访问同一套MDT,分别用于元数据管理和容灾备份。OSS进行实际的数据存储,提供文件I/O服务,每个OSS下可以管理多个对象存储目标服务器(Object Storage Target, OST)。Client负责与MDS和OSS进行信息交互操作。
图 1是典型的大规模集群上的Lustre文件系统架构示意图。为了满足大规模集群的I/O需求,Client、MDS、MDT、OSS、OST分别部署在不同的节点上,并通过高速互联网络(如InfiniBand、TH-Express2、Intel Omni-Path等)进行连接。OST下挂载多块硬盘(SAS、SSD、SATA),并使用RAID技术构成一个存储卷。在MDS的管理方面,Lustre采用active-standy的方法,即双机热备。

图1 Lustre文件系统架构示意图Fig.1 Lustre architectural diagram
1.2 Lustre文件系统内的数据流
从应用的视角看,Lustre文件系统内的数据流如图2所示。由于Lustre采用基于对象的存储技术,因此元数据和目标数据是分别存储管理的。如果不考虑cache的因素,用户的读I/O操作会先访问MDS获取相关文件的目录、权限等信息,再向OSS发起具体的读操作;用户的写I/O操作也会先通过MDS获取文件的元数据信息,再由客户端向OSS进行通信以实现数据的写操作。
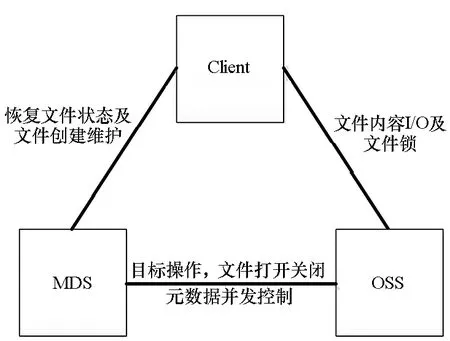
图2 Lustre文件系统内的数据流Fig.2 Dataflow diagram inside the Lustre file system
除了元数据和数据的分离,Lustre还使用条带化技术将数据按照条带大小(stripe size)进行切分,再根据条带数量(stripe count)进行轮转分配,从而使数据文件均匀地分布到多个OST上,保持存储系统整体的负载均衡。
在I/O过程中,计算节点上的I/O数据通过高速通信端口进行传输,每个计算节点上的所有进程通常共享一个高速通信端口(虚拟通道),当计算节点上的所有I/O进程同时竞争该通道时,可能构成I/O性能的瓶颈。
2 应用特征分析与并行I/O配置优化空间
要开展大规模集群上的并行I/O配置参数调优,必须对应用当前的I/O模式有充分的调研和了解。科学计算数值模拟程序是大规模集群并行应用中的一类重要应用,本小节介绍科学计算数值模拟程序的I/O模式特征,分析这些I/O模式下的Lustre文件系统行为特征,进而研究大规模集群上的并行I/O配置优化空间。
2.1 科学计算数值模拟程序的I/O特征
当前,北京应用物理与计算数学研究所的科学计算数值模拟程序在I/O方面主要表现出如下5个方面的特点:
1)编程接口:目前大多数科学计算数值模拟遗产程序还使用Fortran提供的文件操作编程接口,底层调用使用的是每个进程一个文件(one file per process)的I/O操作模式,少量程序使用了HDF5等并行I/O接口。在我们的调查中,还没有生产型的科学计算应用程序使用MPI-I/O的编程接口。
2)分组I/O:一些科学计算数值模拟程序已经基于领域编程框架JASMIN[8]进行重构,利用该框架提供的合并输出功能,用户可将多个进程的输出数据合并到一个进程进行输出,用户可以在运行时设定进程合并输出的分组大小,从而控制用于I/O的进程数。缺省情况下分组大小为1,即每个进程输出到独立的文件中。
3)数据大小:科学计算数值模拟程序I/O的数据主要包括计算结果数据(用于可视化后处理分析)和检查点数据(用于错误恢复、重启动),经过我们的调查发现,应用传输的文件数据大小波动范围大,单个进程I/O的文件大小在数KB至数百MB量级。
4)输出模式:大多数科学计算数值模拟程序采用向文件追加写入的方式进行写操作,计算过程产生数据之后随即进行写操作,单次写入的数据大小与源数据结构大小相关,无明显的特征;有一些开发者习惯于将输出数据通过归约操作汇集到某一个管理进程(通常是0号MPI进程),再由管理进程负责数据结果的输出。
5)读入特征:数据读操作主要发生在程序初始化和重启动时,在程序初始化时程序主要读入输入文件以及网格模型文件,输入文件的大小通常在几个KB,而网格模型文件则可能在几百MB到几个GB量级,未来随着物理建模的精度进一步提高,还将使网格模型文件进一步增大;在程序重启动时,程序读入的是上一次退出时的内存镜像数据,重启动数据的大小与程序并行规模直接相关,数据大小可能在数百GB至TB量级。
2.2 系统视角下的I/O特征分析
IOR[9-10]是由LLNL实验室开发的并行文件系统性能基准测试程序,支持对不同编程接口(POSIX、MPI-I/O、HDF5、parallelNetCDF)、不同I/O文件大小(file size)、不同数据传输尺寸(transfer size)、不同文件输出策略(SSF-Single shared file,FPP-File per process)、不同写入方式(direct I/O、buffer I/O)的I/O模式进行模拟,基于上述优良的特性,IOR可以很好地模拟前述数值模拟应用的I/O特征。因此,本文以IOR为例分析系统管理视角下的应用I/O行为特征,在此基础上分析并行I/O配置优化空间。
如图 3所示,在IOR中,transfer size代表单次I/O操作的数据大小,对应于POSIX文件操作接口read()、write()中单次数据的传输大小,每个Block包含若干个transfer size,一个Block对应一个I/O进程,若干个Block构成一个Segment,对应于数值模拟程序中的一个数据区。在读写数据时,多个I/O进程可以参与数据区中不同数据块的I/O操作,每个数据块的I/O操作被分解为若干个transfer size来完成。IOR这种分层特征与数值模拟应用的I/O特征相似。

图3 系统视角下的应用I/O过程Fig.3 Application I/O feature from system perspective
在Lustre文件系统的层面,应用传输的文件大小被按照条带切分,并将切分后的条带均匀地分布到不同的OST上。用户可以在程序运行前设置程序输出目录的条带数量(stripe count)和条带大小(stripe size)从而控制Lustre文件系统的I/O行为。IOR的transfer size与Lustre文件系统的stripe size在大小上并没有直接关联,前者由程序实现决定,后者由用户或者系统管理员进行配置。
2.3 大规模集群上的并行I/O配置优化空间
从2.2节的分析可知,用户可以从如下5个方面进行并行I/O配置调优:
1)根据节点的并行I/O性能特征,选择每个进程单次I/O传输的数据量(对应IOR的transfer size);
2)根据节点的并行I/O性能特征,调节每个进程传输的数据量(对应IOR的block size×segment_count);
3)根据节点的并行I/O性能特征,调节每个节点上用于I/O的进程数(process per node);
4)根据预估计的输出文件大小和文件数量,为输出目录配置合适的条带化大小(stripe size)和条带化数量(stripe count);
5)在大规模并行场景下,选择合适的客户端数量参与并行I/O操作,以获取最优的I/O性能。
3 大规模集群并行I/O性能特征测试与分析
Lustre文件系统的性能受到很多因素的影响(例如:通信网络带宽、存储设备性能、Lustre本身设置参数等),如果单纯进行系统级的I/O性能特征测试分析,则无法建立起它们与应用I/O性能优化间的关联关系。因此,需要在应用并行I/O配置优化空间的指导下,有针对性地开展系统I/O性能特征的测试分析。围绕2.3节所述的并行I/O配置优化空间,本节以某国产高性能计算机系统为例,介绍大规模集群并行I/O性能特征测试分析方法。
实验平台的每个计算节点包含32个处理器核,每个计算节点的内存为128 GB,平均内存量为4 GB/核,节点操作系统版本为RHEL-7.4,内核版本为Linux-3.10.0。实验平台的Lustre文件系统为2.10,全系统共配置96个OST。测试使用到了该集群其中的256个节点(8192核),使用的IOR为3.0.1,编译器版本是Intel 17.0.4,MPI版本为3.2.1。
3.1 每个进程单次传输的最佳数据量
每个进程单次传输的数据量是指进程单次I/O操作调用read/write接口时,传入的buf长度,见图4。buf长度将会直接影响到数据传输时调用I/O接口的次数,从而对应用的I/O性能产生影响。当传输的数据量大时,单次传输很小的数据量将会引入过多的网络传输启动开销,从而使I/O性能下降。

图4 POSIX I/O接口
Fig.4 POSIX I/O API
如图5所示,调节每个进程单次传输的数据量(transfer size)和程序输出目录的条带大小(stripe size),可以看到读/写带宽随stripe size的变化不太明显,但受transfer size影响很大。其中,写带宽随transfer size增大而增大,读带宽随transfer size增大也有明显增大,但是当transfer size大于8 MB后,再增大transfer size则读带宽出现了下降,性能下降的原因可能是由于节点上高速网卡读数据vp通道成了性能瓶颈。在目标测试平台上,基于读和写性能的综合考虑,每个进程单次传输的最佳数据量在64 KB ~ 8 MB之间。

(a) 写操作的I/O带宽(a) Write bandwidth

(b) 读操作的I/O带宽(b) Read bandwidth图5 传输尺寸和条带大小对I/O带宽的影响Fig.5 Influence of transfer size and stripe size to I/O bandwidth
3.2 每个进程传输的最佳数据总量
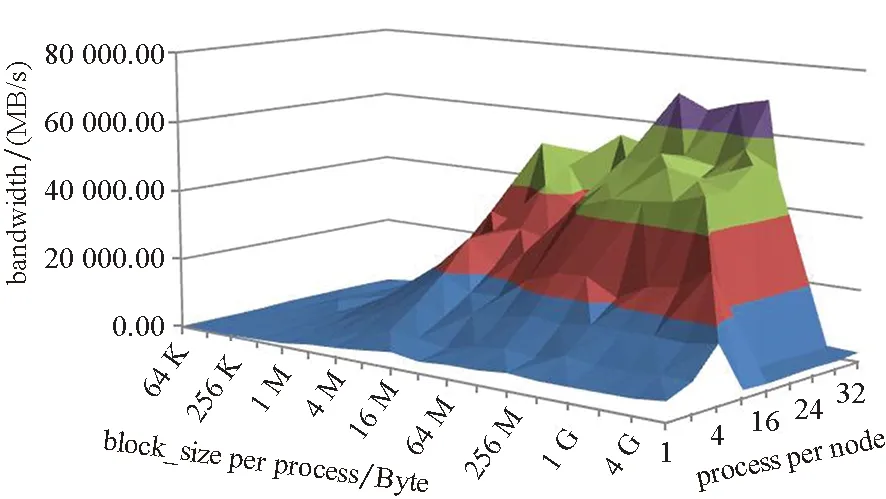
每个进程传输的数据总量是指每个进程负责传输的总数据量。当I/O进程传输的数据量很小时,无法充分利用网络带宽和磁盘带宽;当I/O进程传输的数据量过大时,又会因为对网络和存储资源的竞争而导致性能的下降,因此用户需要调节每个进程传输的数据总量。
如图6所示,当每个进程传输的数据总量小于1 GB时,读操作的性能受益于vfs的page cache,获得了很高的读带宽,但是随着数据量的增大,缓存开始失效,读带宽迅速下降。写操作在每个进程传输的数据总量大于64 MB之后,基本达到饱和。可见,针对目标测试平台,每个进程传输的数据总量在64 MB~1 GB之间是较好的选择。

图6 每个进程传输的数据总量对I/O带宽的影响Fig.6 Influence of block size per process to I/O bandwidth
3.3 每个节点的最优I/O进程数
由于单个计算节点上的I/O操作需要通过竞争网络资源来将数据传输到I/O节点(MDS、OST),因此单个计算节点上的每个进程传输数据总量(block size per process)和每个计算节点上的I/O进程数量(process per node)将会对I/O性能产生影响。
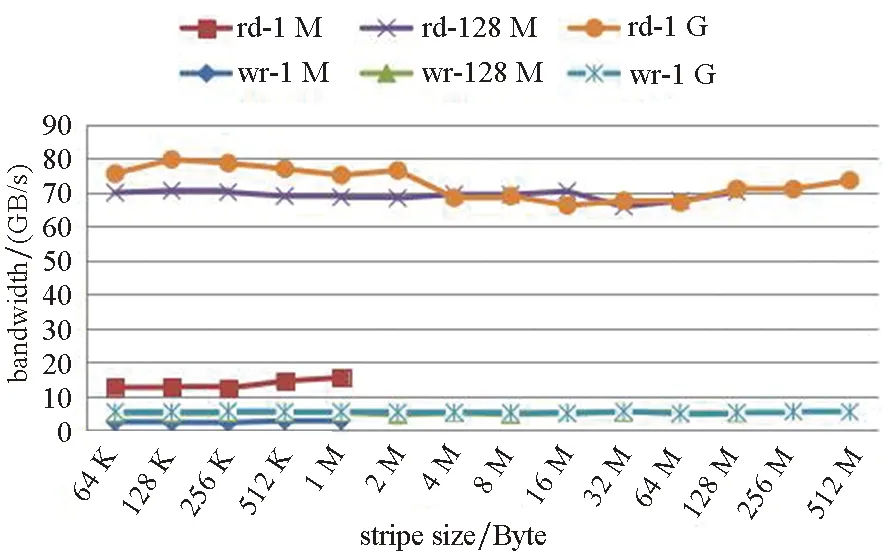
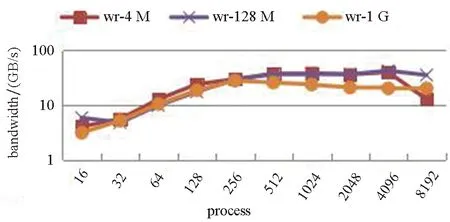
假设点到点的通信带宽为xGB/s,每个OST可提供的I/O带宽为yGB/s,为该作业分配的条带数(stripe count)为n。则当x 在图7中,将输出目录的条带数设置为4,并根据3.1节和3.2节的测试结果,将单次I/O的数据量(transfer size)设为64 KB,条带大小设置为64 KB,调节每个进程传输的数据总量(block size)以及节点上的I/O进程数(process)。从图7可以看出,当节点上的I/O进程数较少时,没有充分利用节点的网络带宽资源,I/O带宽较低。单个计算节点的I/O进程数大于8之后,对计算节点的高速通信网络带宽基本达到饱和。进一步的测试数据表明,当单个进程传输的数据量(block size)为8 MB,单个计算节点的I/O进程数为32时,写带宽达到了最大值9.785 GB/s,此时的I/O写带宽性能值与该系统平台的网络点到点传输性能基本相当,表明此时I/O性能已经因为网络带宽达到了极限。 (a) 写操作的I/O带宽(a) Write bandwidth (b) 读操作的I/O带宽(b) Read bandwidth图7 每个节点的进程数对I/O带宽的影响Fig.7 Influence of process per node to I/O bandwidth 在目标测试平台上,每个进程的传输数据量(block size)较优选择在4 MB~2 GB之间,相应地,每个节点上的较优I/O进程数(process)在8~32之间。综合来看,每个节点上的I/O进程数为8时始终能够获得较好的I/O性能。 条带大小和条带数量对于Lustre文件系统的性能会产生较大影响,这在很多文献中都有提及[6,11-16],但是它们的最优参数设置与文件大小的关系,文献中没有给出答案。为此,针对文件大小与条带大小(stripe size)、条带数量(stripe count)进行了测试分析。 对于小文件I/O,条带大小和条带数量都无法带来直接的性能提升;对于大文件I/O,条带过大则实际用于存储该文件的条带数会减少,从而无法充分利用存储带宽资源。本文分别针对条带大小和条带数量进行了测试。 如图8(a)所示,对于小文件(1 MB/进程)条带大小与该文件大小相当时I/O的性能较高;对于中等文件(128 MB/进程)和大文件(1 GB/进程),I/O性能都随着条带增大而有所下降。如图8(b)所示,条带数量对于I/O性能提升起到了一定的促进作用。图中,条带数为2相比条带数为1时性能出现了下降是因为传输的文件较小,数据分块导致的I/O性能下降。图8(a)中部分曲线没有画满,是因为stripe size增大到文件大小时,再增大该参数已无意义。 综合来看,在目标测试平台上:①增大条块数量能够带来一定的I/O性能提升;②对于小/中/大文件的I/O操作而言,条带大小设为1MB是一个较优的选择。 (a) 条带大小对I/O性能的影响(a) Influence of stripe size to I/O performance (b) 条带数量对I/O性能的影响(b) Influence of stripe count to I/O performance图8 条带大小和条带数量对I/O带宽的影响Fig.8 Influence of stripe size and stripe count to I/O bandwidth 根据前面的调研,科学计算数值模拟程序大多采用每个进程一个文件的I/O模式。然而,在大规模并行场景下,所有进程都参与I/O操作显然不是一个最优的选择。这主要是因为:①所有进程都参与I/O会导致节点上高速网络资源的竞争;②所有进程都参与I/O操作,会产生大量的元数据操作请求,进而加大MDS的响应开销;③所有进程都参与I/O操作,则每个OST都要响应全部作业进程,这会超出OST的响应能力。其中,对于节点上高速通信网络资源的竞争,3.3节已有分析。 对于并行文件的操作开销,图9给出了目标测试平台的统计结果。可以看出,在目标测试平台上,当作业进程数大于1024之后,作业并行开关文件的开销迅速增大,对于数万核进程并行的作业,如果采用每个进程一个文件的I/O操作模式,则其并行I/O性能势必会受到很大的影响。 图9 并行文件开关操作开销Fig.9 Overhead of parallel file open/close operation 为了考察并行I/O进程数对I/O性能的影响,我们在目标测试平台上,将作业输出目录的条带数量固定设置为16,然后对比不同I/O进程数量下的I/O写操作带宽。对于不同大小的文件,8192进程时的I/O带宽都比4096时的I/O带宽出现了下降,如图10所示,表明此时的I/O进程数已经超过了OST的响应能力。对于每个进程1 GB的I/O数据量而言,最优的并行I/O进程数是256。 图10 并行I/O进程对I/O性能的影响Fig.10 Influence of process number to I/O bandwidth 结合前述测试分析,我们给出目标测试平台的并行I/O配置优化策略,如下: 1)每个进程单次传输的数据量对I/O性能有较大的影响,建议控制单次数据传输量在64 KB~8 MB之间。 2)每个进程传输的数据量对I/O性能有较大的影响,建议单进程数据传输总量在8 MB~1 GB之间。 3)受限于节点的高速通信网络带宽,建议每个节点的I/O进程数在8个左右。 4)通过预估计需要进行I/O操作的文件大小,设置合理的条带化大小和条带化数量,可以提升I/O性能。对于小文件,建议条带化设置为1,对于中等大小的文件,建议条带化设置为4,对于大文件,建议条带化设置为16。考虑到实际生产环境下的存储可靠性以及多个大规模作业之间可能产生的影响,不建议对于大文件设置过多的条带数。 5)考虑到大规模并行I/O时的文件操作开销,建议大规模并行时的I/O进程数不超过1000;考虑到条带数量设置导致的文件系统对应用并行I/O的响应能力限制,建议大规模并行作业的I/O进程数量不超作业输出目录条带数(stripe count)的16倍(经验值)。对于基于结构网格编程框架的程序,建议使用合并输出功能,调节合并输出的分组大小,将单个计算节点上的I/O进程数控制在8左右,将总体的I/O进程数控制在1000以下。 上述策略的具体配置数值可能因为各系统平台的配置不同而不同,但该策略的优化思路可以推广应用到其他同类超算系统平台。基于上述优化策略,针对两类典型并行I/O场景进行了测试验证: 1)场景1:大规模并行程序加载初始化。针对某生产应用程序,通过:①增大条带化数量(条带数从1增大到16),从而增大响应读操作请求的OST数量;②调节参与读操作的I/O进程数(每个节点指派1个读数据文件的I/O进程),减小多进程读取同一文件时引入的文件锁竞争。使得4096核的作业加载时间从10 min降到了5 s。 2)场景2:大规模并行程序写重启动数据。针对某生产应用程序,通过:①设置作业输出目录的条带数量(条带数从4增大到16);②调节参与写操作的I/O进程数(每个计算节点8个I/O进程),减少并行文件操作开销。使得8192进程下的重启动数据写操作时间下降了15%。 近年来,针对大规模集群上的并行I/O性能优化已有大量的研究工作,这些工作主要集中在并行I/O算法接口的实现优化以及针对Lustre文件系统的性能优化两个方面。 在并行I/O接口优化方面,文献[6]对MPI-I/O的聚合操作(Collective)进行了优化,文献[17]提出了一种针对MPI-I/O的自动调优框架,文献[18]针对HDF5的读操作使用增加数据块视图方法进行了优化。目前在调研的核科学数值模拟应用中,还没有生产型应用直接使用MPI-I/O的方式实现并行I/O。 在Lustre文件系统组件性能优化方面,文献[4]针对Lustre文件系统上的小文件I/O性能低下问题,提出了一种“Filter Cache”方法;文献[5]针对Lustre文件系统的元数据性能瓶颈问题,采用分层的元数据管理方法,设计实现了元数据代理MDDS,提升元数据访问性能;文献[19]基于TH-2的高性能互连网络,实现了针对该机文件系统的高速通信模块FSE优化,获得了更高的数据访问带宽和元数据性能。 然而,从并行I/O配置参数优化的角度开展大规模集群上的并行I/O调优还不多见,在这方面,与本文研究切入点最为接近的是文献[15-16,20],其中文献[16,20]分别针对Jaguar和RedStrom超级计算机系统上的并行文件系统性能展开了测试和分析,文献[15]则从应用I/O特征的角度提出了在Jaguar系统上的并行I/O优化建议。国内也有研究者开展Lustre文件系统的性能测试研究[11-14],但都仅限于在小规模下开展实验测试,其研究结论无法推广适用于大规模集群。 本文从科学计算数值模拟应用程序的I/O特征出发,从应用I/O配置优化的视角来看应用程序I/O过程中的应用行为和系统行为,进而提出了大规模集群上的并行I/O配置调优空间,给出了从5个方面开展配置参数优化的调优策略,在此基础上,在某国产超算系统平台上开展了上述5个方面的调优分析测试研究,并将优化策略在两类典型的应用I/O场景中进行了验证。对于大规模并行程序加载初始化以及程序写重启动数据两类典型I/O场景,提出的优化策略都分别取得了明显的效果。 本文提出的并行I/O配置参数优化策略,可以推广应用到其他同架构的超算系统平台,对于大规模集群上的用户层并行I/O配置调优具有借鉴意义。还需说明的是,本文提出的部分并行I/O配置参数优化策略,需要应用开发人员和系统研究人员共同参与完成,例如调整每个计算节点上用于I/O的进程数量这一策略,对于基于领域编程框架的应用程序,可以使用框架提供的聚合输出功能,在模型配置文件中调节聚合输出的分组I/O大小,而对于非框架应用程序,则需要在程序代码上进行改进。要实现科学计算数值模拟应用程序的I/O参数全部可动态调节,还需要应用开发人员和系统研究人员的持续共同努力。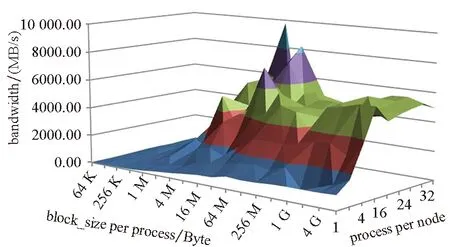
3.4 文件大小与条带大小、条带数量的关联分析

3.5 大规模作业的最优I/O进程数分析

4 大规模集群上的并行I/O配置优化策略及应用验证
5 讨论
6 结论
