基于Hadoop的网络舆情关键字监控体系分析
2020-05-03胡治宇
胡治宇
摘要:Hadoop作为数据分析的重要系统,已经广泛应用于数据监控领域当中。因此,本文将网络舆情关键字监控作为研究内容,简单介绍Hadoop平台的基本概念,分析基于Hadoop的网络舆情关键字监控的核心技术,如网络爬虫技术、文本挖掘技术以及关键词检索技术,再围绕着网络舆论数据收集、网络舆情数据处理、网络舆情数据分析以及网络舆情监控测试四个方面进行考虑,深入探讨基于Hadoop的网络舆情关键字监控的体系,发现基于Hadoop的网络舆情关键字监控的体系具有较强的可靠性,仅供参考。
关键词:网络舆情 关键词 监控体系
目前,截止2019年底,我国网络用户已经超过10亿,已成为全球网络用户最多的国家。在互联网环境下,网民可以自主了解不同的新闻,并能够在不同的平台中发表自己的言论观点,这就逐渐提高了网络舆情的影响力。为了更好的对网络舆情进行控制,就需要加强对网络舆情的监控。Hadoop平台属于分布式系统,可通过编程模型对庞杂海量的数据进行有效的分布式处理。因此,构建基于Hadoop的网络舆情关键字监控系统已成为未来发展趋势。
一、Hadoop平台概述
Hadoop平台属于分布式系统,可通过编程模型对庞杂海量的数据进行有效的分布式处理。目前,Hadoop平台的主要子项目就是HDFS,凭借HDFS可以对大型数据进行有效存储,并具有容错性较高的特点,能够通过较高的吞吐量对数据进行大规模的访问。同时,Hadoop平台还具有四大优势,分别是可靠性、效率性、低廉性以及扩展性,可以对数据进行稳定高效快速的处理,并能减少软件的应用成本。
二、基于Hadoop的网络舆情关键字监控的核心技术
(一)网络爬虫技术
网络爬虫作为一种依照特定规则在网络平台上抓取重要信息的程序,通常应用于关键词搜索引擎当中,能够稳定有效的抓取网络信息的关键词,属于构建网络舆情关键字监控的核心工具。一般来讲, 种子URL集合都会存放一些URL,包括门户网站网页以及论坛主页网页等,这些都是网络爬虫的运行起点。因此,网络爬虫首先都是从种子URL集合进行爬取,将种子URL页面中存放的URL全部放入到待抓取队列当中,再从带抓取列队当中准确获取一个URL,并对网址进行有效访问,从而将网页内容抓取到本地文件系统当中,最后对已经抓取的网页进行快速解析,以便提取一些能够指向其他网页的有效连接。目前,网络爬虫技术主要分为两种,分别是通用型网络爬虫以及聚集型网络爬虫。其中,通用型网络爬虫的应用范围相对较广,主要应用于门户搜索引擎;聚集型网络爬虫更多应用于与主题相关的网页类型,主要应用于校园网络舆情监控。
(二)文本挖掘技术
文本挖掘属于数据挖掘中最为常见的一项技术,主要由三个模块组成,分别是文本预处理、文本分类以及文本聚类。首先,文本预处理作为文本挖掘的基础,直接决定了文本挖掘的效率、精度以及模型。文本预处理主要涉及到中文分词以及文本特征表示两大内容。对于中文分词而言,主要就是将汉字序列精确有效的划分为单个的词,如jieba就是常见的中文分词工具;对于文本特征表示而言,主要就是将人类能够理解的文本信息进行有效转化,使其成为能够被计算机精确有效识别的一种格式,如概率模型以及空间向量模型就是常见的表示模型。其次,文本分类主要涉及到监督式学习算法,如支持向量机以及朴素叶贝斯就是常见的分类算法,往往能够有效确定分类的具体类别,包括经济、房产、娱乐以及体育等类别,并依照分类文本的实际内容以及具体含义进行深度计算,从而将文本有效归入到对应的类别当中。最后,文本聚类主要涉及到无监督式机器学习算法,通常会自动将文本进行有效归类,使同一类别的文本内容更加接近,而不同类别的文本内容则会相差较大。
(三)关键词检索技术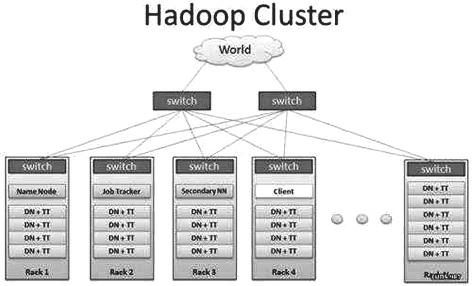
由于互联网储存了大量数据,如果选择整体检索的方式,不仅会消耗较多时间,还不能有效保证检索的准确性。关键词检索技术已成为信息检索的主要方式,能够有效保证信息检索的时效性。目前,在网络舆情监控体系中,关键词检索技术已成为核心部分,而关键词检索主要有三种方式,一是依照预先设定的语义分析来抓取关键词,二是通过大数据技术进行统计来抓取关键词,三是借助机器学习法来抓取关键词。由于关键词检索技术在实际应用中面临较多流程,可通过简化来完成相关操作。例如,首先,对信息内容的主题词进行有效分析,筛选出含义更为贴近的主题词,以便构建一个标准的主题词表。其次,对这个主题词表进行有效处理,提取文本中的关键词。最后,根据权重比例来抓取关键词,进而将关键词有效筛选出来。
三、基于Hadoop的网络舆情关键字监控体系分析
(一)网络舆论数据收集
数据收集作为实现网络舆情关键字监控的第一步,具有奠定基础的作用。在数据收集过程中,应根据数据来源采取对应的收集方式。例如,网络舆情的主要数据信息通常来源于各大網络平台,包括搜狐新闻、网易新闻、新浪微博以及腾讯微博等平台。如果数据信息来源于新闻网站,主要借助Nutch来完成数据采集。目前,Nutch主要由两种类别,分别是分布式以及非分布式。由于分布式系统在实际运行中效率以及稳定性均优于非分布式系统,通常选择分布式Nutch,具体的数据收集过程如下:首先将URL列表准确添加到系统当中,并在URL列表中进行相应的操作;其次,创建一个Fetchlist,再通过内容解析器将收集的大量数据进行有效分析。最后,提取一个全新的URL,并对CrawIDB进行有效更新,以此完成数据收集工作。如果数据信息来源于微博网站,主要借助API接口来完成数据采集,并在此期间确保客户端能够通过微博平台的真实授权,再对相关应用进行开放。
(二)网络舆情数据处理

数据处理作为实现网络舆情关键字监控的第二步,具有承上启下的作用。目前,相关技术还不能直接对收集的数据进行处理,必须采取数字化处理措施。在对数据进行数字化处理过程中,由于国内网络舆情数据大部分都是中文数据,这就与英文数据的处理方式存在一定差异,再加上中文分词的具体界限较为模糊,应重点加强对中文分词的预处理。在数据预处理过程中,还应重点构建文本向量空间模型,使该模型具有基本元素,包括词频、词义、词性以及标题等内容,并对不同类型的特征词设置对应的权重比。在数据预处理结束后,还应对数据进行有效聚类,并设置相应的数据聚类模块,再借助层次聚类算法进行有序处理。在使用层次聚类算法时,应将各种因素作为实际考量标准,包括处理高维数据的稳定性、对参数的依赖性以及抗干扰性等,确保层次聚类算法能够发挥实际作用。
(三)网络輿情数据分析
数据分析作为实现网络舆情关键字监控的第三步,具有决定性作用。在整个网络舆情监控系统当中,核心部分就是舆情分析模块,只有舆情分析模块能够稳定运行,就能对网络舆情关键字进行强力有效的监控。一般来讲,网络舆情关键字监控主要有三种形式,分别是敏感话题关键字监控、热点话题关键字监控以及内容倾向性监控。其中,敏感话题关键字监控就是对于一些具有敏感特征的字词进行监控,如法轮功、邪教等敏感词。目前,国内网络具有较强的开放性,网民可以通过网络将自己的各种意见以及各种看法发布到网络平台当中,但在交互传播中难免会出现一些具有敏感性的关键字,为了避免这类敏感话题对社会造成影响,监控系统就会借助敏感词词库进行充分有效地匹配,如果发现网络传播的关键字与敏感词词库中的字词明显匹配,就能及时进行监控;热点话题关键字监控就是对于一些当前社会热议的内容进行监控,并借助数据聚类技术对网络传播的热门话题、热门文章以及热门评论进行有效分析,分别统计出这些热门话题、热门文章以及热门评论的关注度,并将其按照数值大小依次进行排列,以便对一定时期内的社会热议的内容进行准确有效识别;内容倾向性监控就是根据信息发布者的自身主观情感进行研究,以此得出信息发布者个人关于信息内容的立场以及态度,并借助数据聚类技术对于情感词进行有效匹配,并根据相应的权重进行准确计算。
(四)网络舆情监控测试
实验测试作为实现网络舆情关键字监控的最后一步,能够了解监控系统的实际运行效果。为此,本实验采用6台戴尔服务器,以此作为监控系统的硬件设施,并采用64位CentOS6.4以及64位jdk1.7,以此作为监控系统的软件设施。同时,将TDT作为本次实验测试的评估标准,对高校网络舆情的实际发展趋势进行评估,并将误报率以及漏报率作为评估指标。其中,误报率=监控到与主题有关的信息量/监控到与关键词有关的信息量,漏报率=未监控到与主题有关的信息量/监控到与关键词有关的信息量。在实验测试结束后,得出由网络爬虫技术抓取的实际数量达到6160条,并得出以下五个关键字,包括兼职、考研、饮食、旅游以及就业,这意味着高校学生在一段时期内对这些内容较为关注,同时发现误报率、漏报率以及识别代价等指标数值均处于较低状态,表明本次实验测试结果较为准确,体现了网络舆情监控的实际效果显著。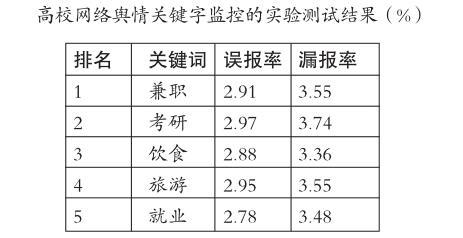
结语:
综上所述,基于Hadoop的网络舆情关键字监控体系主要应用到网络爬虫技术、文本挖掘技术以及关键词检索技术,并且涵盖了网络舆论数据收集、网络舆情数据处理、网络舆情数据分析以及网络舆情监控测试四个步骤,在实际应用中具有良好的关键字监控效果。
课题项目:江西省教育厅科学技术研究项目《基于Hadoop的高校网络舆情引导研究》项目编号:181120。
参考文献:
[1]唐存琛,王極可. 一种结合模型集成的舆情管理模型的研究[J]. 计算机应用与软件,2019,36(06):31-34+92.
[2]江瑾. 网络舆情监控系统的设计和实现[J]. 信息与电脑(理论版),2019(13):63-65.
[3]高为民. 微时代背景下高校大学生网络舆情预警研究[J]. 教育现代化,2017,4(13):90-91.
[4]聂琼,陶杰,吴凡. 浅谈高职网络舆情监测系统的设计[J]. 现代计算机,2019(32):88-90.
