基于改进YOLO v3的相似外部特征人员检测算法
2020-04-29梁思源罗凡波徐桂菲
梁思源,王 平,罗凡波,徐桂菲,王 伟
(西华大学 电气与电子信息学院,四川 成都 610039)
0 引言
计算机视觉是指用计算机实现人的视觉功能,希望能根据感知到的图像(视频) 对实际的目标和场景内容做出有意义的判断[1].随着计算机视觉技术的发展,智能视屏监控已经成为一个热门的研究领域.近年来计算机硬件技术尤其是GPU技术的飞速发展,使得深度学习已经在视屏监控领域占据了不可替代的位置.但是现在针对相似外部特征人员的检测算法还相对较少,而公共场所多个相似特征人员的聚集往往预示着异常情况的发生.就此现状笔者针对大雾和强曝光天气下的外部特征相似人员提出一种基于深度学习的检测算法.
深度学习不需要人工对目标的特征进行设计和提取,而是由机器自动地学习获得.这种自动学得的特征具有很好的泛化能力与鲁棒性[2].但是深度学习的分类结果受训练样本的影响较大,尤其是在大雾和强曝光之下,图像的特征丢失严重,会导致最后的分类效果并不理想.因此笔者对自建数据库中质量不佳的训练样本进行了暗通道去雾算法处理,得到更优质的样本模型进行训练[3].该算法是一种实用性很强的算法,该算法作者还在2015年提出了Fast Guided Filter,笔者采用结合了Fast Guided Filter的暗通道去雾算法,实验表明该算法在去雾的同时保留了更多的目标人物的边缘细节,为后期的图像特征提取也保留了很多有价值的特征信息.
行人检测作为目标检测的一个重要分支,经过几十年的发展已经在检测的速度和精度上取得了很大的进步,很多方法已经完全能够达到视屏级的实时性.传统方法采用人工设计的特征提取器来提取特征并对分类器进行训练.例如通过提取Haar特征、HOG(Histogram of Oriented Gradient)特征 、LBP(Local Binary Pattern)特征等进行训练.其中文献[4]采用HOG+LBP特征处理行人的遮挡问题,提高了检测的准确率.但由于人体的柔性特征和人群中的遮挡问题,人工设计的行人特征很难适应行人的大幅度变化[5].笔者采用经过去雾处理的自建数据集对改进的YOLO v3网络进行训练,并将得到的结果与HOG+SVM方法进行对比,结果证明在实时性和准确性方面该方法均优于传统的HOG+SVM方法.
提取出目标人员之后再对其进行特征的提取.很多相关研究已经在颜色、形状和纹理特征这几方面展开,其中效果相对较好的特征主要为颜色与纹理的特征.常见的颜色空间有RGB颜色空间、HSV空间和YUV空间.目前已有方法对RGB空间分量和YUV空间分量的特点和优势进行综合并进行特征提取[6].纹理特征经过多年的发展,已经发展出灰度共生矩阵(CLCM)、灰度行程长度法(gray level run length)、自相关函数法等,同时随着应用领域的不断扩大和新理论如分形理论、马尔科夫随机场(MRF)理论、小波理论等的引入,又不断壮大了纹理特征提取的研究[7].但是由于提取出的特征往往具有较高的维度,因此处理这些数据所消耗的时间可能会较长,对于视屏监控的实时性不能满足.但如果为了提高处理速度而降低特征维度又会导致错误率的增加,不能适应复杂的场景,抗噪能力不足.
笔者基于人类视觉特征对图像感知的3个特性提出自适应颜色特征提取方法,颜色特征上使用RGB和HSV分别描述,因此在降低特征维度的情况下依然能获得较好的效果,并在此基础上使用灰度直方图、灰度共生矩阵、小波变换来获取多个新的纹理特征,用于更好地检测外部相似特征.最后将获取的特征放入极限学习机(ELM)中进行分类.实验结果表明本文算法能在个体目标相似度上取得较好效果,优于传统的相似度匹配算法.
1 暗通道去雾处理
为了提高图像的质量,减小大雾天气和强曝光天气对训练所造成的影响,提高检测的准确度和鲁棒性,首先对得到的数据集进行暗通道去雾处理.
1.1 暗通道定义
暗通道是指在图片中,除去天空、海洋等大面积单色区域,一些像素会出现一个或多个颜色通道的值很低的现象.对于一幅输入图像J,它的暗通道可以用式(1)表达:
(1)
其中Jc表示彩色图像的每个通道,Ω(x)表示以像素x为中心的一个窗口.r、g、b表示图像的3个通道[8].暗通道先验的理论指出:
Jdark→0 .
(2)
1.2 暗通道去雾原理
在计算机视觉中常用公式(3)来表示雾图形成模型.
I(x)=J(x)t(x)+[A(1-t(x))].
(3)
式中,I(x)表示现有未去雾图像,J(x)表示要得到的去雾后图像,A表示全球大气光成分,t(x)表示透射率.为得到方程的解,将(3)式变化为(4)式.
(4)
这里的c表示RGB三个通道,为了得到我们定义的暗通道,求c的最小值得到式(5):
(5)
由前述暗原色先验理论可得
(6)
由此可得
(7)
将(7)代入(5)中可得
(8)
空气中的颗粒和雾感能给人带来一定的景深效果,这里笔者在(8)中引入一个[0,1]之间的数来保留一定的雾,本文仿真取值为0.95.
(9)
而全球大气光A的求取,笔者借助于暗通道图来从有雾图像中获取该值.目前A值的求取主要分为以下两种方法:1、从暗通道图中按照亮度的大小取前0.1%的像素[8];2、在这些位置中,在原始有雾图像I中寻找对应的具有最高亮度的点的值,作为A值.当投射图的t值很小时,会导致J值偏大,从而使得图像整体向白场过渡,因此一般可设置一阈值t0,当t值小于t0时,令t=t0,本文中所有效果图均以t0=0.1为标准计算.因此,最终去雾公式如下:
(10)
1.3 导向滤波算法
导向滤波算法是通过一个引导图像I来对p进行滤波而得到q,其数学公式为
(11)
Wij(I)表示由引导图像I来确定加权平均运算中所采用的权值.
噪声的特点通常是以其为中心的各个方向上梯度都较大而且相差不多.边缘则不同,边缘相比于区域也会出现梯度的跃变,但是边缘只有在其法向方向上才会出现较大的梯度,而在切向方向上梯度较小.相比普通平滑和高斯平滑,导向滤波的加入能保护更多的边缘信息,使后期算法能学习到更好的模型,同时也保留了更多的纹理特征.
Fast Guided Filter[9]是何凯明博士于2015年提出的一种很实用的更快速的导向滤波流程.其本质是通过下采样减少像素点,计算meana和meanb后进行上采样恢复到原有的尺寸大小.导向滤波的时间复杂度为O(N),其中N为像素点的个数.假设缩放比例为s,那么缩小后像素点的个数为N/s2,那么时间复杂度变为O(N/s2).去雾效果如图1~3所示.

图1 原图图2 未加入Fast Guided Filter的暗通道去雾效果图图3 加入Fast Guided Filter后的暗通道去雾效果图
2 目标检测
2.1 YOLO算法
YOLO v3[10]作为目前最优秀的目标检测框架之一,其实时性相比之前的RCNN[11]、SPP-Net[12]、Fast-RCNN[13]、Faster-RCNN[14]都有很大的进步.YOLO的核心思想是利用整张图片作为输出,直接在输出层回归bounding box(边界框)的位置及其所属的类别.首先将一幅图片分割成7×7个网格(grid cell),再对目标进行检测,如果目标中心落在某个网格中,网格就负责对该目标进行预测.预测的候选框还需要预测一个confidence值来判别目标是否存在[5].
confidence=Pr(Object)×IOUTruthPred.
(12)
如果有目标落在一个网格里,那么Pr(Object)值取1,否则取0.IOUTruthPred是预测的bounding box和实际的groundtruth之间的交并比.
(13)
在预测时,每个候选框的分类置信分数为预测目标的类别概率和bounding box预测的confidence信息相乘.
Conf=Pr(Classi|Object)× Pr(Object)×IOUTruthPred.
(14)
得到每个分类置信分数之后,设置阈值将得分低的boxes筛除掉,就得到最终的检测结果.
但是由于YOLO的全连接层输入输出的特征向量必须固定长度,所以YOLO只能接收固定尺寸的图片.当物体占画面比例较小的时候,有可能会出现一个格子包含多个目标物体,但是YOLO这时只能检测出其中一个.
2.2 YOLO算法的改进
目前大多数神经网络的改进趋势都是往更大更深的网络发展.通常情况下层级更多的神经网络往往能在实际情况中学习到更多的细节从而达到更好的效果.YOLO v2[15]并没有致力于加深神经网络的层数,而是通过Batch Normalization、High resolution classifier、Multi-Scale Training等方法使其在保持原有速度的同时提高了精度.整个网络应用了Darknet-19的网络架构,包含19个卷积层和5个max pooling层,卷积的计算量相较于YOLO大大减少.YOLO v3[10]采用了Darknet-53的基础网络结构,在保证速度的同时又再一次大大提高了精确度.
Darknet-53网络结构借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections).图4左侧的1、2、8等数字表示残差组件的个数,每个残差组件有两个卷积层和一个快捷链路.同时还采用多尺度预测方案,针对COCO数据集,YOLO v3设计了9个不同大小的预测框,将其按照大小均分给3个尺度.
但是YOLO算法的预测框均是建立在COCO数据集的基础之上的.种类较多,尺寸比例差异较大,笔者仅在INRIA数据集上对行人进行检测和识别.因此笔者在设计预测框时对INRIA数据集进行了K-means方法聚类.最后对INRIA数据集的聚类结果,取消了YOLO v3原来在三个维度上的输出检测,而直接将anchor boxes的个数和宽高维度设定为聚类所得到的结果.

图4 Darknet-53网络结构
从图5中可以看出簇K值在等于4之后逐渐趋于平稳.所以笔者将变化的拐点定为最佳anchor boxes的数量.实验证明聚类后的预测框大大缩短了训练的收敛时间,同时还可以消除候选框带来的误差.
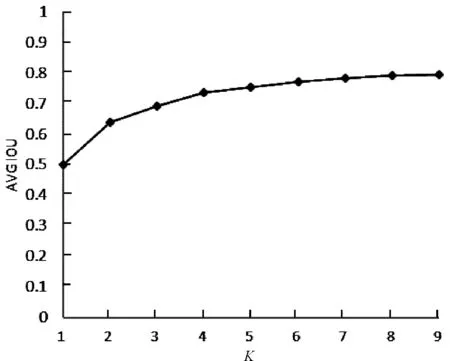
图5 K-means聚类分析结果
2.3 目标检测结果分析
笔者采用深度学习架构YOLO-Darknet53 搭建仿真的运行环境,并配置NVIDIA的CUDA 环境进行GPU 并行加速计算.图6是训练过程平均损失变化的对比.
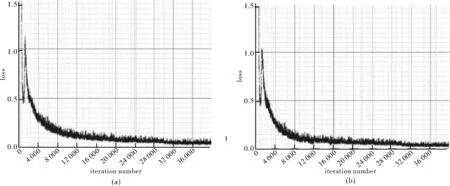
图6 平均损失值变化比较
仿真实验中每轮迭代从处理后的训练集里随机抽batch=64个样本进行训练,由于本次实验采用的显卡为2G显存,为了减轻内存占用压力,每轮的64个样本又被均分为 subdivision = 16 次送入网络参与训练.同时采用分步学习策略,为了提高学习效率,又避免过拟合现象,笔者将最初的学习率定为10×0.001,在15 000次迭代后,学习率更改为0.1×0.001,30 000次后再更改为上次更改后的0.1倍,最终,经过40 000次迭代,YOLO v3平均损失值最后保持在0.042 2.而经改进后的YOLO v3平均损失值可以达到0.36.并且从图中可以明显地看出经K-means方法聚类出预测框的YOLO v3算法收敛速度更快.算法对比效果见图7~9.

图7 HOG+SVM目标识别效果

图8 YOLO v3目标识别效果
图9 本文算法目标识别效果
3 图像特征提取
3.1 颜色特征的提取
颜色通常是用3个独立的属性来描述,常见的颜色空间有RGB、HSV和YUV.3种颜色空间各有自己的特点和优势,RGB颜色空间是通过3种不同颜色的分量叠加形成任何颜色的光,RGB表示的物理意义很清晰,但是不能很好地适应人的视觉特点.而HSV空间则能够描述人看到物体时所使用的色调、饱和度和明度.YUV主要用于优化彩色视频信号的传输.笔者使用RGB与HSV分别描述前景个体颜色特征.
在RGB颜色空间提取R分量平均值μR、G分量平均值μG、B分量平均值μB、RGB平均值μRGB、RGB标准差σRGB5个颜色特征值.
分别提取目标对象的R、G、B 3个分量各自的平均值μλ:
(15)
式中分别取R、G、B,Nobj为提取目标对象后图像的像素数,Iλ(i,j)为像素点(i,j)的λ分量,得μR、μG、μB三值.
RGB平均值:
(16)
式中IRGB(i,j)为像素点(i,j)的RGB平均值,得到μRGB.
RGB标准差:
(17)
得到σRGB.
在HSV空间用同样方法提取H分量平均值μH、S分量平均值μS、V分量平均值μV、HSV平均值μHSV、HSV标准差σHSV5个颜色特征值.
由RGB颜色特征组成的五维向量标记为:
Vrgb=(μR,μG,μB,μRGB,σRGB) .
由HSV颜色特征组成的五维向量标记为:
Vhsv=(μH,μS,μV,μHSV,σHSV) .
3.2 纹理特征的提取
笔者采用统计理论与小波变换2种方法对纹理特征进行描述.一副图像的灰度图像由无数灰度值的像素点组成,灰度直方图能够直观地表现图像中灰度分布情况,包含了大量的图像特征.笔者基于灰度直方图提取了均值m、标准方差σ、平滑度R、三阶矩μ3、一致性U、熵e.
(18)
(19)
(20)
(21)
(22)
式中L是灰度级数,zi表示第i个灰度级,p(zi)是归一化直方图灰度级分布中灰度为zi的概率.将6个特征组合成六维特征向量Vgh:
Vgh(m,σ,R,μ3,U,e) .
(23)
灰度共生矩阵是相距一定距离的两个特定灰度值的像素同时出现的矩阵表达形式.它描述了空间位置上特定两个像素点之间的联合分布,包含了大量的图片纹理特征信息.但是由于数据量较大,一般会基于其构建一些统计量作为分类特征.笔者基于灰度共生矩阵的特征,提取了能量ASM、对比度CON、相关COR和熵ENT,并求取四个特征的均值和标准差组成八维向量Vcm.
(24)
(25)
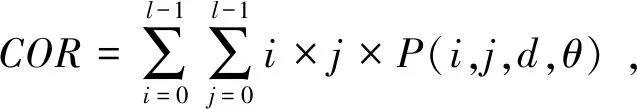
(26)
(27)
式中:
P(i,j,d,θ)={P[(x,y),(x+Dx,y+Dy)]|f(x,y)=i;f((x+Dx,y+Dy)=j} ,
(28)
Dx、Dy是位置偏移量,d为共生矩阵的生成步长,θ为共生矩阵的生成方向.由以上4个特征:能量、对比度、相关和熵的均值、标准差组成八维向量,记为Vcm.
Vcm=(ASMm,ASMσ,CONm,CONσ,CORm,CORσ,ENTm,ENTσ) .
(29)
本文在小波变换的描述上基于小波系数能量WE对目标灰度通道进行两层小波分解,得到6个子细节图的平均能量向量WEgrey.其中:
(30)
WEgrey=(WEgreyhl2,WEgreylh2,WEgreyhh2,WEgreyhl1,WEgreylh1,WEgreyhh1) .
(31)
式中:m×n为图像像素大小;w(i,j)为对应点的小波系数;WEgreyhl1,WEgreylh1,WEgreyhh1分别为灰度通道小波分解的第1层垂直分量、水平分量和对角系数能量;WEgreyhl2,WEgreylh2,WEgreyhh2分别为灰度通道小波分解的第2层垂直分量、水平分量和对角系数能量.
3.3 特征向量组合
为了对比不同特征向量组合对具有相似外部特征人员检测的效果,笔者对提取到的特征进行不同的编组,得到不同的特征组如下:
F1=(Vrgb,Vhsv) ,
(32)
F2=(Vrgb,Vhsv,Vgh) ,
(33)
F3=(Vrgb,Vhsv,Vcm) ,
(34)
F4=(Vrgb,Vhsv,WEgrey) ,
(35)
F5=(Vrgb,Vhsv,Vgh,Vcm,WEgrey) .
(36)
4 基于极限学习机的特征分类
极限学习机(Extreme Learning Machine)[16]是由黄广斌教授提出的求解单隐层前馈神经网络的算法.其核心内容是输入层与隐藏层之间的权值参数求解,以及隐藏层的偏置参数的求解,其求解过程也较简单,可划归为求解一个矩阵的广义逆的问题.在保证相同学习精度的情况下,与传统的神经网络相比也能拥有较快的速度.针对隐含层与连接层初始值的选取,本文通过rand生成.笔者针对两组测试数据,选取的隐含层神经元个数为45和50个.
4.1 极限学习机分类
1)训练集:给定Q个不同样本(xi,ti).其中xi=[xi1,xi2,…,xin]T;ti=[ti1].xi为上述几种特征组合;ti为一个标签,表示对应目标属于哪一类人群.

3)对经过训练的ELM输入测试视频,即可对当前视频中人群类别进行分类,将具有共同颜色和纹理特征的人分离出来.
4.2 算法步骤
1)针对两组不同的测试集,笔者选取的隐含层神经元个数分别为45和50个,对ELM在(0,1)区间采用均匀分布随机设定输入层与隐含层的链接权值ω与隐含层神经元的阈值b.
2)选择S函数作为隐含层神经元的激活函数,进而计算隐含层输出矩阵H;
使用ELM算法对提取的颜色特征、纹理特征参数进行分析,对人群进行相似度分类,把人群分为一般人群和具有相似外部特征人群.
相关实验表明,在ELM中许多非线性函数都可以使用,甚至还可用线性激活函数分类非线性样本.针对本文数据集,根据相关研究[17],选取Sigmoid函数作为激活函数的分类效果优于其他函数,隐含层神经元个数根据样本数的变化而做出改变能获得较好的分类精度.
5 实验分析
本次仿真基于普通PC机平台(CPU为6500K,3.2 GHz,6.00 GB内存,显存为2 G)完成.YOLO采用深度学习架构YOLO-Darknet53 搭建仿真的运行环境,并配置NVIDIA的CUDA 环境进行GPU 并行加速计算.特征提取和分类部分通过MATLAB 2014a编程仿真环境编写代码并进行仿真[18].笔者在拍摄的视频数据集里提取了248个目标个体与纹理特征数据作为训练集并做了大量仿真实验,最后选取其中两帧的仿真结果对比图,并对仿真整体做了平均准确率的计算.
本文特征分类部分训练集为248个目标个体,具有相似外部特征的样本有4组,其中每个类别含有6个目标个体.测试集数据为77个目标个体,具有相似外部特征的个体有2类,每类中有4个目标个体,其余均为普通个体.表1为不同的特征组合的人群类别分类准确率;图10~14为测试集预测分类的结果与真实值的对比.在表1中可以看到F1特征组合的识别率为84.415%,相比于其他组合识别是最低的,说明在复杂条件下仅仅依靠颜色特征无法可靠识别出目标个体,而在一定程度上增加特征数量可以提高识别的准确率.最后一组F5特征组合在实验条件下达到了96.104%,该组融合了文中提到的全部特征向量,各种特征之间相互弥补了各自的不足,呈现出较好的仿真效果.ELM作为一种机器学习分类算法,学习效率高、泛化能力强,相比于传统单隐层前馈神经网络,在保证精度的前提下速度更快.
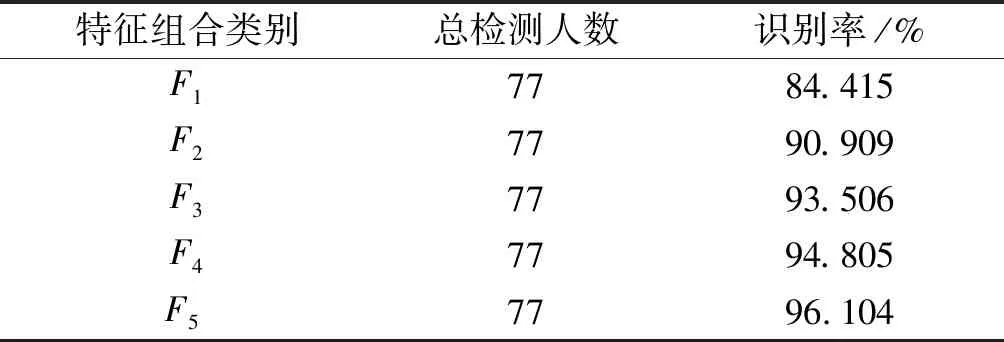
表1 5种特征组合在ELM下的准确率
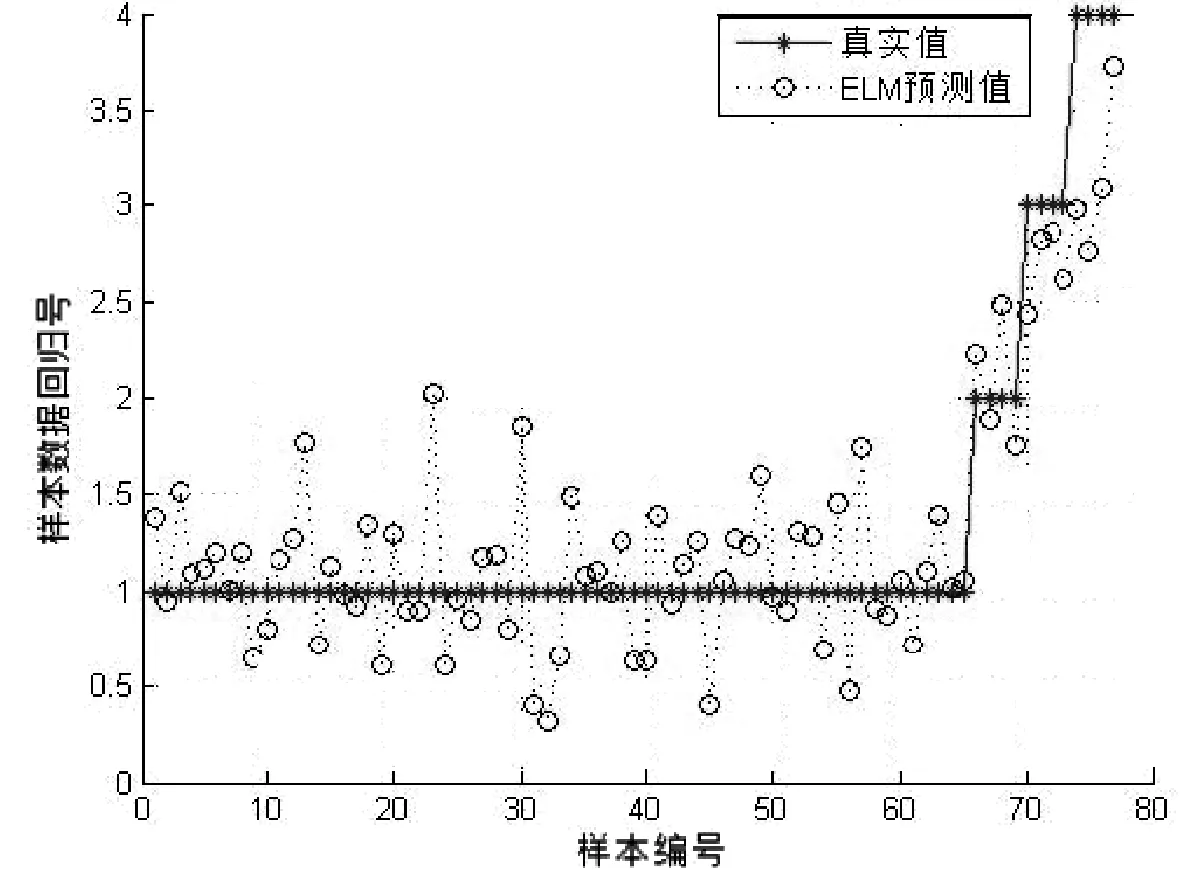
图10 F1特征组合
6 结论
笔者提出的基于深度学习的相似外部特征人员检测算法利用了加入Fast Guided Filter的改进暗通道去雾算法对拍摄的视频数据集进行优化,再将经过优化增强后的样本图片投入到经K-means方法聚类出预测框的YOLO v3网络框架下进行训练.然后用训练出的深度模型提取出需要检测相似性特征的目标人物.最后将目标任务提取多种颜色及纹理特征并结合ELM对其进行分类.深度学习的加入大大降低了由于遮挡和弯曲所造成的目标漏检问题,多特征的应用也让分类准确率有了极大的保障.目前由于采集到的目标人物有限,实际的目标类别和特征都会远大于本文数量,故本研究成果对于实际的精准分类来讲还需要继续完善.另外YOLO网络对于图像中过小的目标依然存在漏检的现象,下一步的工作将考虑根据特定的环境改进现有神经网络的结构,使之更能适应当前环境的应用.
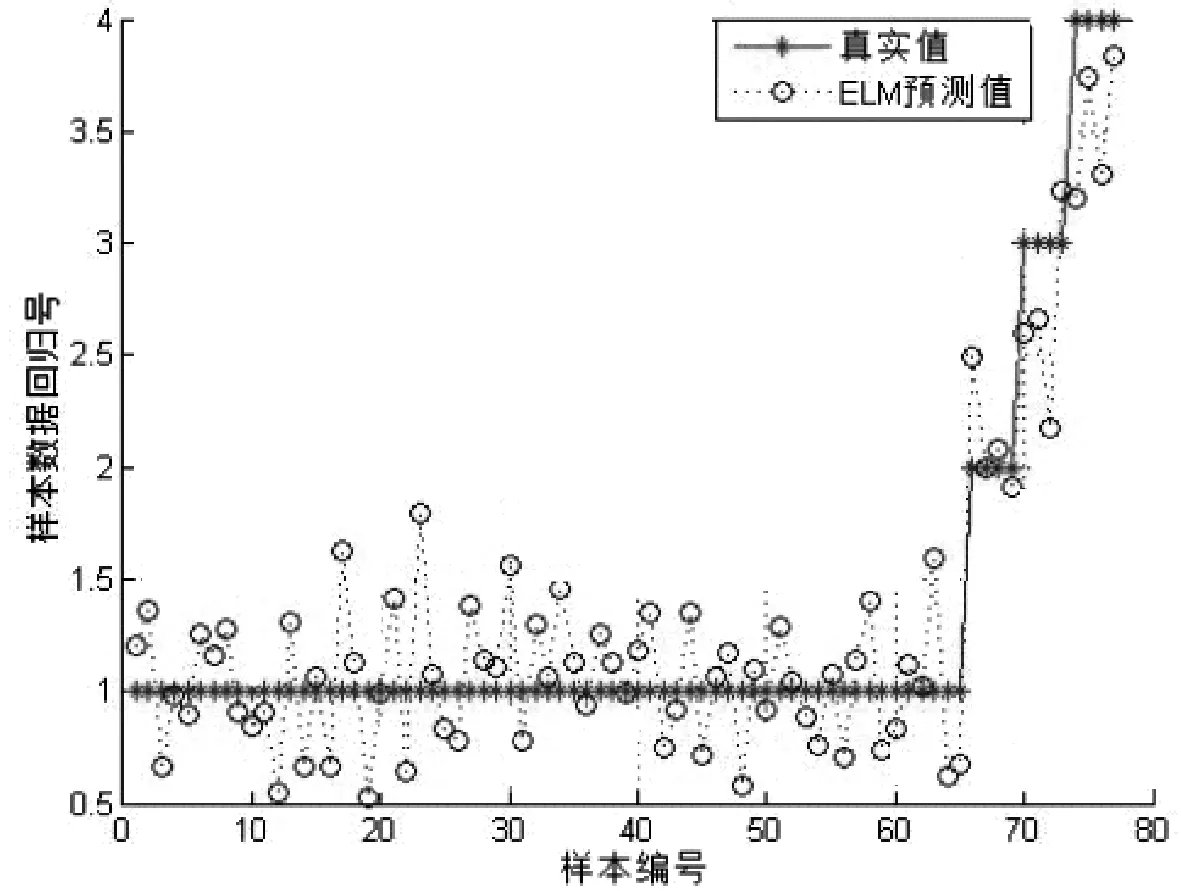
图11 F2特征组合
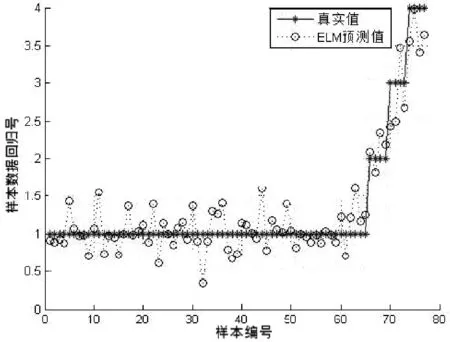
图12 F3特征组合
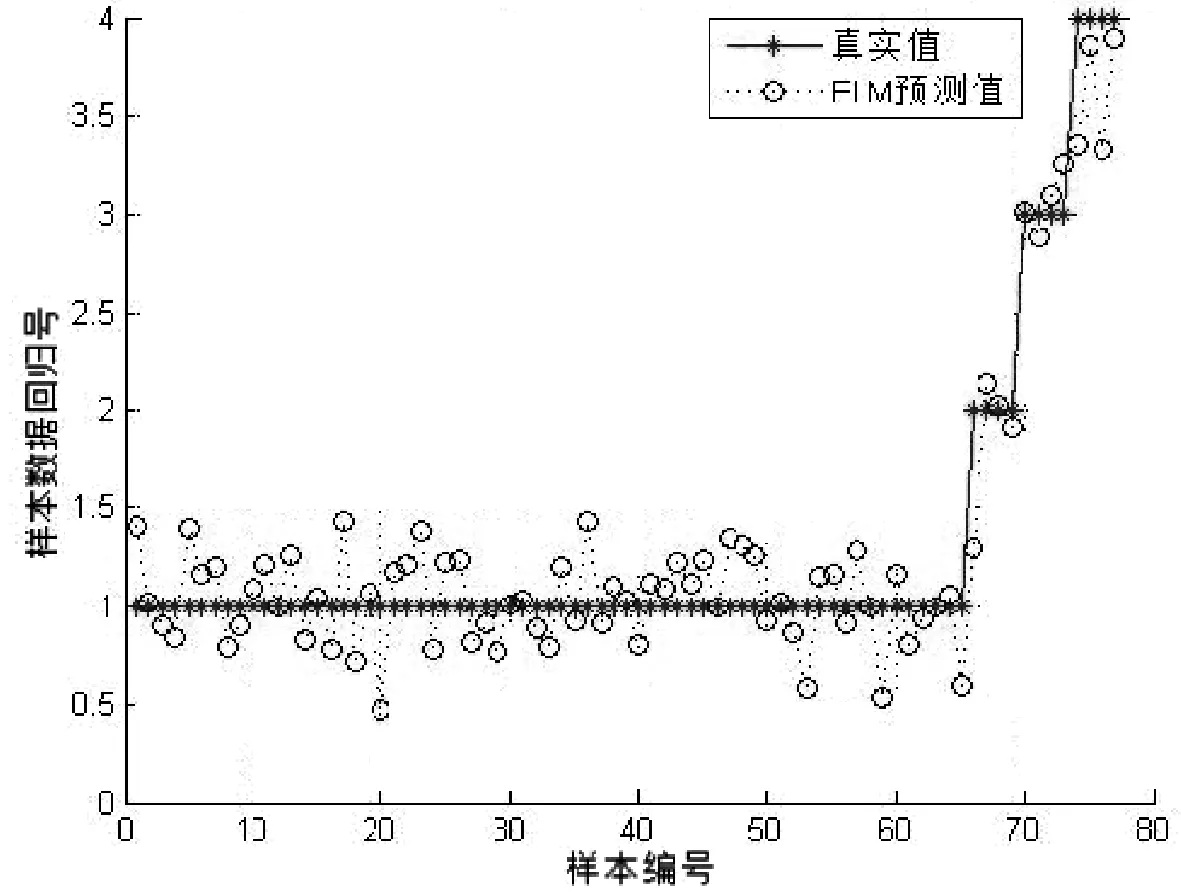
图13 F4特征组合
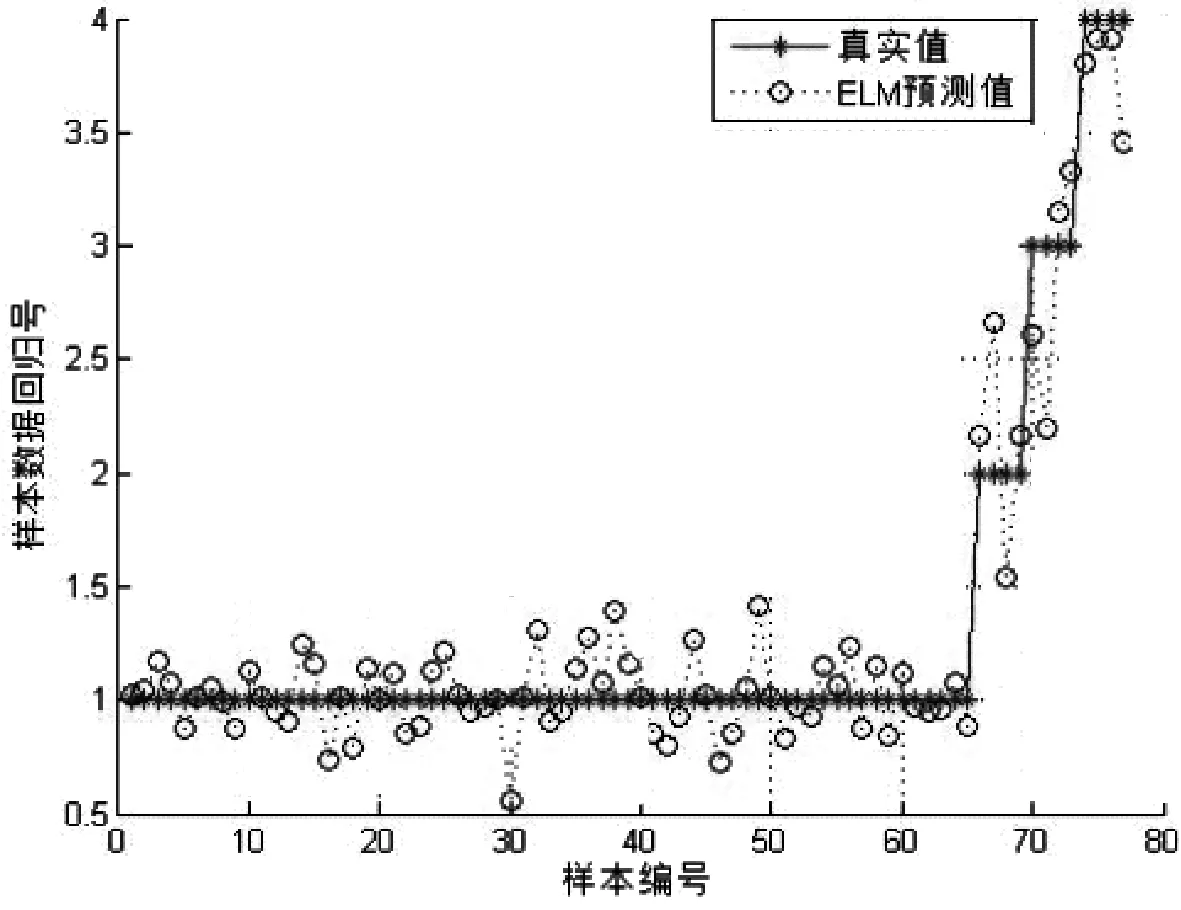
图14 F5特征组合
