基于动态模糊聚类的数据挖掘研究
——以安徽城市综合实力分析为例
2020-04-28吴晓兵童百利
李 眩,吴晓兵,童百利
(安徽省铜陵职业技术学院 经管系,安徽 铜陵 244061)
地级城市的综合实力是推动地域发展的重要动力,分析其综合实力并进行相应解析,对研究我国地域经济具有重要意义,同时也可衡量城市的发展水平和发达程度[1]。城市综合实力聚类是对比城市间综合实力的一种常用方法,其要解决的关键问题是分析指标的选取和聚类方法的选择。国内外学者从不同角度对构建城市综合实力评价指标体系进行了许多研究,为本文的研究提供了有益借鉴。
聚类分析是数据挖掘研究领域中一个非常活跃的课题,就是将一组物理或抽象对象分组为类似对象组成的多个类的过程,使同类对象彼此类似,不同类对象彼此相异。如果分类数量已知成为静态聚类,在分析过程中获得类的数量则为动态聚类[2]。传统的聚类方法是基于经验或者简单的统计方法,聚类主观性强,效果不理想。其聚类方法一般都是硬划分,将对象进行严格区分,分类界限分明。而电子商务客户群具有多样性的特点,往往不能用某一严格界限对其进行具体类的划分,采用传统方法聚类不理想。模糊理论的出现为聚类提供新的思路,聚类思想由硬划分中的“要么属于,要么不属于”变化为“用属于程度来描述”[3]。客观事物之间没有一个截然区别的界限,不是严格分明的,是带有模糊性的,因此用模糊方法解决聚类问题必然更符合实际。模糊聚类结果不是说事物绝对地属于或不属于某类,而是指属于某类的程度有多大,其在聚类分析的基础上,引入“隶属度”来度量每个样本与各类的隶属程度,聚类结果比较科学合理。本文提出的动态模糊聚类应用于城市综合实力的分析,MATLAB仿真结果表明了该算法的可行性、有效性和优越性。
一、数据挖掘理论
随着大数据时代的到来,以云计算、大数据、移动互联网、智能终端、物联网为代表的新一代信息技术普及速度不断加快发展,使得数据的采集、存储、计算和分析能力得到的大幅度提升,传统的对于数据的查询、处理和统计分析已经不能满足于人们对于数据应用的需要,迫切希望能够对其进行更高层次的分析以便更好地利用这些数据,进而获取能指导未来行为的规律和模式,并提高企业、社会、组织和机构的效益以及效率。计算机处理数据的速度很快,但从海量数据中挖掘规律并不是简单的操作,因此需要有行之有效的分析算法来完成在数据中“沙里淘金”的过程,因此数据挖掘技术也就应运而生了。数据挖掘(Datamining)是知识发现(简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算科学有关,并通过统计、聚类分析、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标[4]。近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括商业智能,生产控制,市场分析,工程设计和科学探索等。数据挖掘利用了来自如下一些领域的思想:(1) 来自统计学的抽样、估计和假设检验;(2)人工智能、模式识别和机器学习的搜索算法、建模技术和学习理论;(3)模糊理论以及新型的灰色系统理论。数据挖掘也迅速地接纳了来自其他领域的思想,这些领域包括最优化、进化计算、信息论、信号处理、可视化和信息检索。分类、估算、预测、相关性分组或关联规则、聚类、图形图像分割,视频及音频检索等都属于数据挖掘研究。
数据挖掘技术已经在商业方面得到了广泛应用,根据顾客购买记录,使用序列模式挖掘顾客的消费变化,分析顾客的忠诚程度。电商平台基于用户的基本属性、购买能力、行为特征、兴趣爱好,使用数据挖掘技术构建客户画像,实现精准营销;在制造领域,数据挖掘技术可以在生产、装配、质检、维修等多个环节来帮助企业解决传统管理与技术难以的解决的问题。基于产品生产工艺流程和缺陷分析,找出生产过程影响生产质量的因素,从而通过重点改进相关环节及工艺,来提高企业的生产效率,保障产品质量。通过设备故障数据分析,发现影响设备故障的因素,提前进行故障预测,实现预测性设备检修维护。以及最优的设备装备方案、最佳产品生产工艺参数组合、产品质量分析与问题追溯。数据挖掘已经深入到生产制造的各个环节,是制造行业智能化转型的核心基础支撑;在电子政务应用方面,基于智慧交通、智慧政务、智慧旅游等多领域数据分析与挖掘技术应用的智慧城市建设,已经成为当今时代的主题。政府在城市规划中,通过对城市地理、气象等自然信息和经济、社会、文化、人口等人文社会信息的挖掘,可以为城市规划提供强大的决策支持,强化城市管理服务的科学性和前瞻性。大数据时代下的电子政务具备海量繁复的数据资源,而数据挖掘则是提升数据利用价值,为舆情管控、业务创新提供支撑的核心所在。数据挖掘在各领域的应用和重要性不胜枚举,应用相应算法对数据进行挖掘来指导工作提供决策依据,是目前各个领域备受关注的热点。
二、城市综合实力评价指标的选取
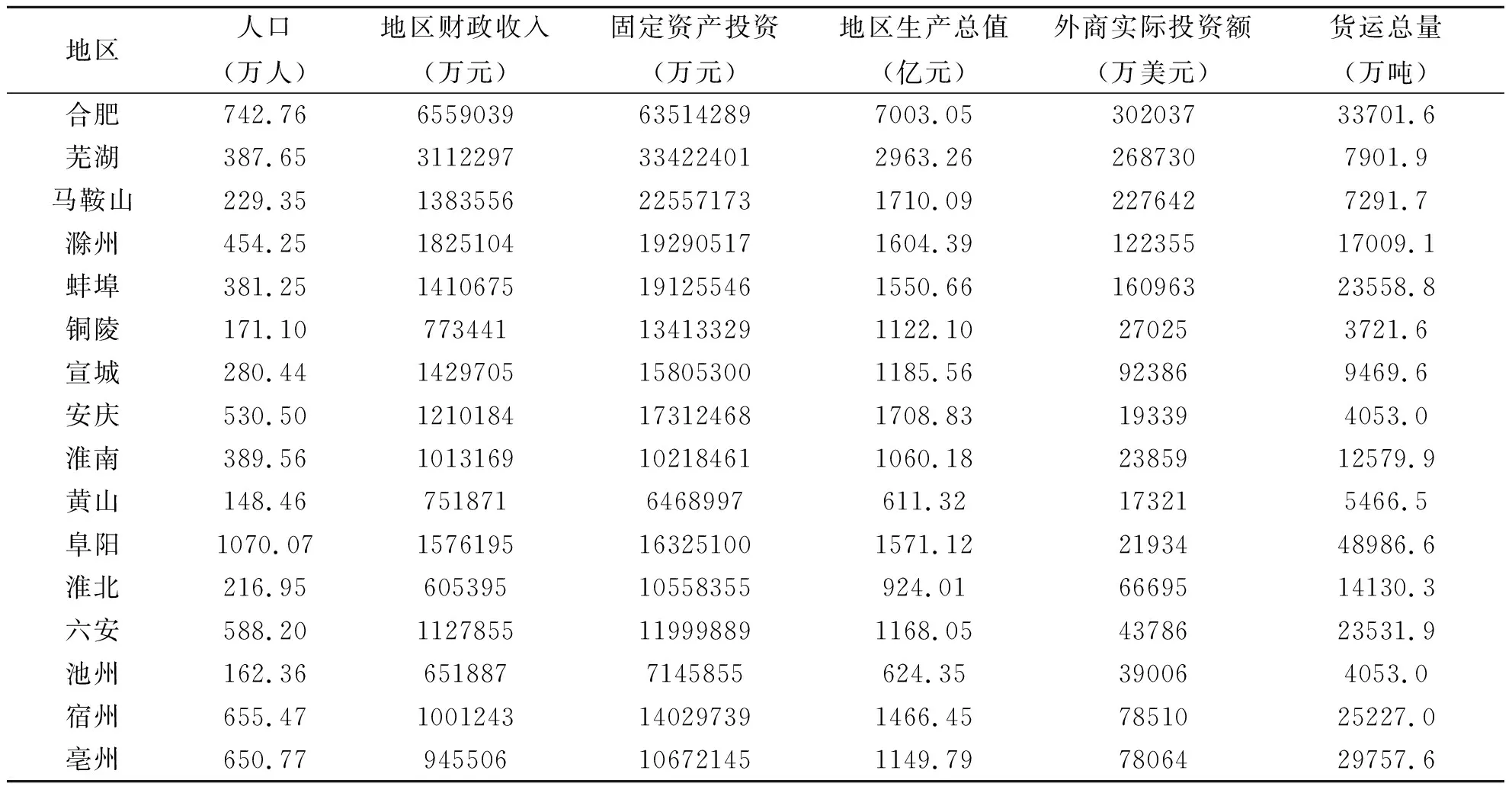
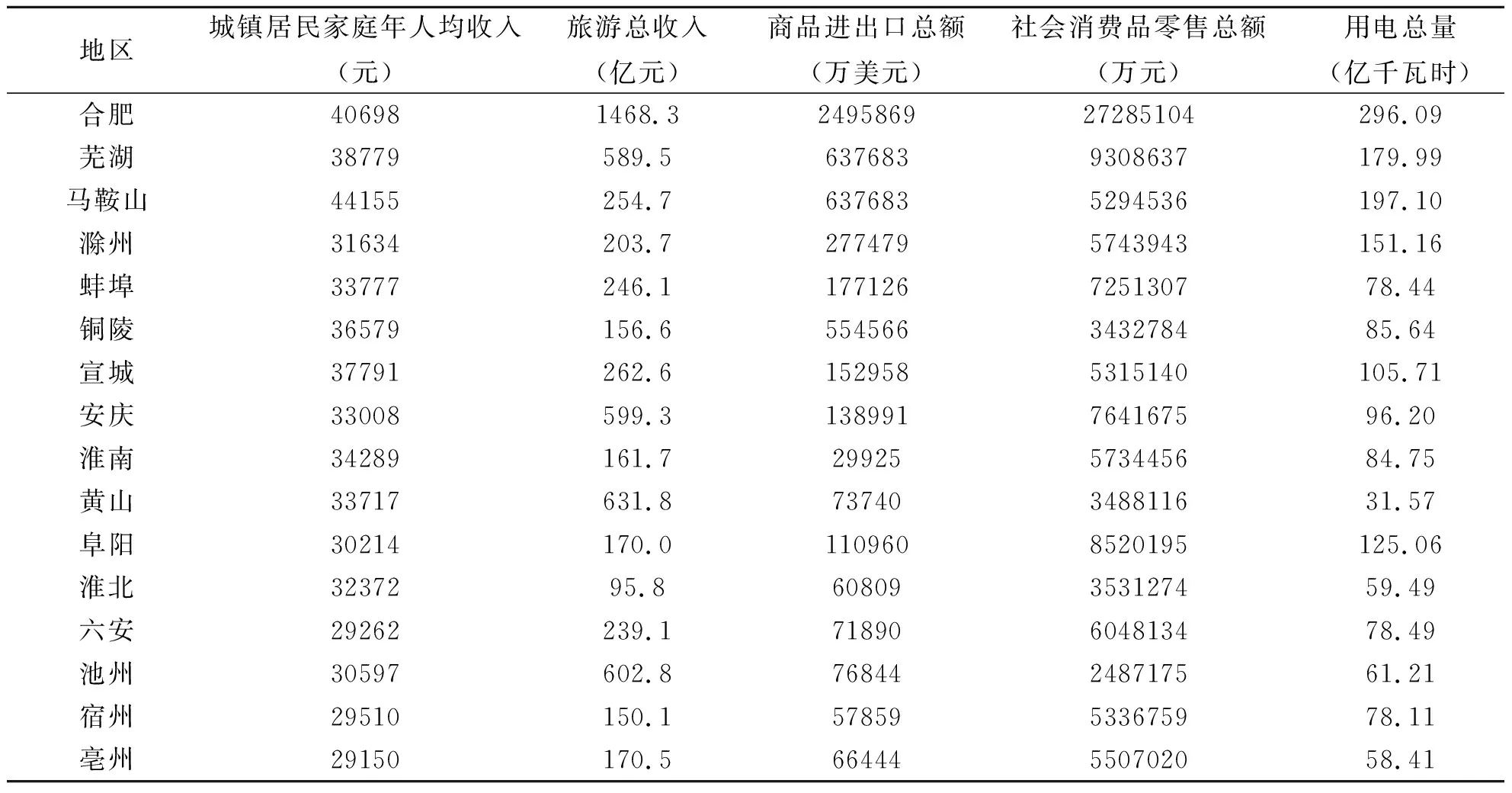
任何事物包含的信息是多方面的,对其进行合理全面评价,必须构建全面科学的评估指标体系,城市的综合发展状况亦是如此。依据层次性、代表性、独立性、综合性和可行性等原则选取指标[5]构建评价指标体系。本文选取了11个典型的指标来评价城市综合实力,分别为人口、地方财政收入、固定资产投资、地区生产总值、外商实际投资额、城镇居民家庭年人均收入、旅游总收入、货运总量、商品进出口总额、社会消费品零售总额、农村居民年人均收入。这11项指标涵盖城市经济及人口规模、工业和商业化程度、进出口贸易、招商引资能力等诸多方面。2018年安徽省16市的主要经济指标数值如表1所示。
三、动态模糊聚类算法
(一)模糊聚类的原理
模糊聚类算法是基于目标函数优化基础上的一种数据动态聚类方法[6],每项数据是哪类是比较模糊的,不能精确断定,只是在某些方面有相似性,这相似性聚类结果是每个数据对聚类中心的隶属度来度量得出的,该隶属程度用一个数值来表示[7]。
模糊聚类算法执行步骤如下:
模糊聚类分析的目标函数:
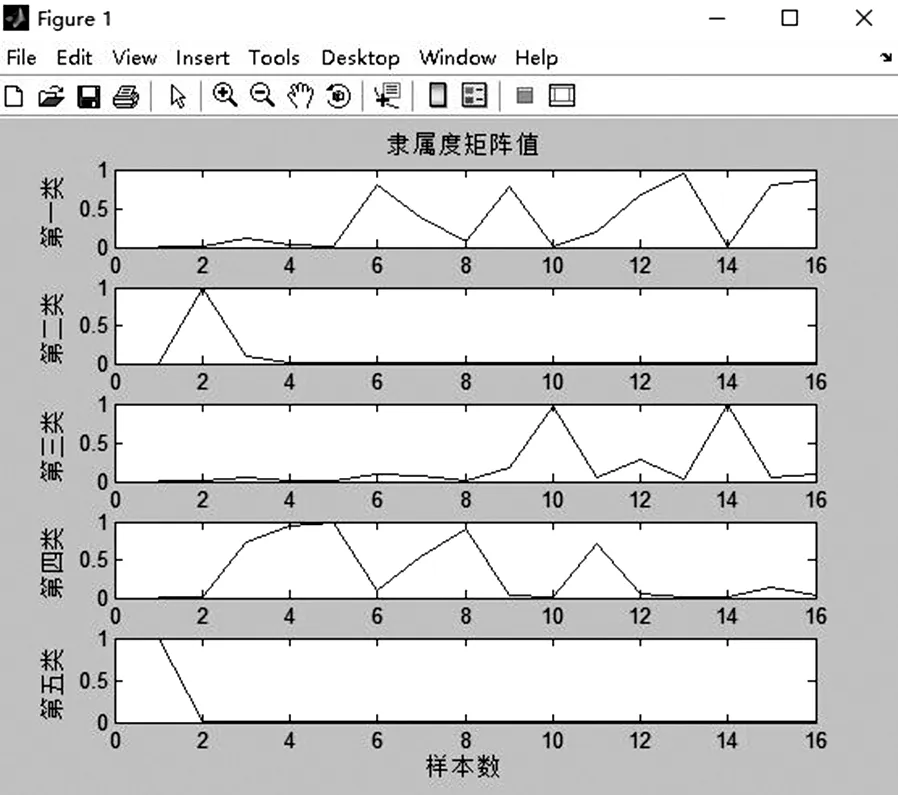
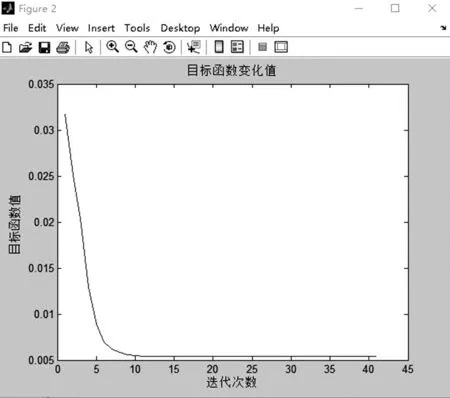
其中,uji表示样本xj对应第i类中心vi的隶属度,m是模糊权重因子(m>1),dji=||xj-vi||是样本xj到第i类中心vi的欧氏距离,c为分类数目(1 s×c矩阵,s代表维数。 (1)设定聚类数目c和模糊权重参数m,随机初始化聚类中心; (2)计算所有样本数据的隶属度矩阵,并且是每列元素之和满足恒等于1的约束条件; (3)计算Uk,则有: (4)计算Vk+1,则有: (5)更新聚类中心,若||UK+1-UK||≤ε,停止迭代,输出聚类结果,否则k=k+1,转向步骤(3)继续执行。 模糊聚类的MATLAB程序[8]代码共包括三个函数,通过相互调用能实现聚类的过程和结果输出,代码如下: Data为待输入的16市的11位数据矩阵。 function[U,V,objFcn]=myfcm(data,c,T,m,epsm) [m n]=size(data); for i=1:m data(i,:)=data(i,:)/norm(data(i,:)); end; c=5 if nargin<3 T=100; end if nargin<5 epsm=1.0e-6; end if nargin<4 m=2; end [n,s]=size(data); U0=rand(c,n); temp=sum(U0,1); for i=1:n U0(:,i)=U0(:,i)./temp(i); end iter=0; V(c,s)=0;U(c,n)=0;distance(c,n)=0; while(iter iter=iter+1; Um=U0.^m; V=Um*data./(sum(Um,2)*ones(1,s)); for i=1:c for j=1:n distance(i,j)=mydist(data(j,:),V(i,:)); end end U=1./(distance.^m.*(ones(c,1)*sum(distance.^(-m)))); objFcn(iter)=sum(sum(Um.*distance.^2)); if norm(U-U0,Inf) break end U0=U; end myplot(U,objFcn); function d=mydist(X,Y) d=sqrt(sum((X-Y).^2)); end function myplot(U,objFcn) figure(1) subplot(5,1,1); plot(U(1,:),’-k’); title(’隶属度矩阵值’) ylabel(’第一类’) subplot(5,1,2); plot(U(2,:),’-k’); ylabel(’第二类’) subplot(5,1,3); plot(U(3,:),’-k’); ylabel(’第三类’) subplot(5,1,4); plot(U(4,:),’-k’); ylabel(’第四类’) subplot(5,1,5); plot(U(5,:),’-k’); ylabel(’第五类’) xlabel(’样本数’) figure(2) grid on plot(objFcn); title(’目标函数变化值’); xlabel(’迭代次数’) ylabel(’目标函数值’) 表1 2018年安徽省16市主要经济指标值 数据来源于《2018年安徽省统计年鉴》 表1 2018年安徽省16市主要经济指标值 数据来源于《2018年安徽省统计年鉴》 表2 模糊聚类隶属度 图1 隶属度矩阵值 图2 目标函数值变化 图3 3D聚类结果图 查阅《2018年安徽省统计年鉴》中获取16个地市的11项指标数值,每个城市数据包含人口、地方财政收入、固定资产投资、地区生产总值、外商实际投资额、城镇居民家庭年人均收入、旅游总收入、货运总量、商品进出口总额、社会消费品零售总额、农村居民年人均收入。这11项指标能较全面描述城市经济、人口、商业和进出口等方面的特征[7]。将每个城市的11维指标数据进行归一化处理,将原始数据映射为[0,1]区间内的数据,消除数量级和量纲不同对后续分析带来的干扰。 应用本文提出的模糊算法对16个城市的综合实力进行聚类分析来验证算法的可行性和合理性。MATLAB程序中,聚类数目设定c=5, data为16个城市的11维特征数据矩阵,模糊度m=2.在MATLAB环境中运行上述程序,得到每个城市划类的隶属度值如表2所示,图1为隶属度矩阵值的示意图,根据隶属度值的大小和图1能得知每位客户的最佳聚类,图2 为目标函数变化值示意图,大约经过12次迭代运算,动态模糊聚类算法收敛,目标函数值已经非常稳定,说明聚类迭代计算已达到要求。并且可以进一步作出3D聚类结果图,如图3所示。 最终将16个城市按综合实力分为五类,第一类:合肥,作为安徽省的省会,是经济、政治、文化、金融、信息中心,也是全省唯一的大型城市,城市发展基础很好,综合实力是最强的;第二类:芜湖,处于长江沿岸,经济地区条件优越,交通发达,是安徽省的门户城市和区域中心城市,得益于良好的区域优势、得天独厚的发展环境及发达的交通,综合实力在安徽省很强,其综合实力遥遥领先于除省会合肥外的其他地级城市;第三类:马鞍山、滁州、蚌埠、宣城、安庆、阜阳,马鞍山、滁州、安庆四个城市紧靠长三角和江浙,区域优势较好,受长三角、江浙的辐射带动,发展较好;蚌埠为皖北区域的中心城市、铁路交通枢纽城市,交通区位优越,发展基础较好;阜阳市仅次于合肥的全省第二交通枢纽,六条高铁在此汇聚,由于高铁枢纽的带动,近年经济持续较快增长;宣城地处皖南山区和长江下游平原的结合部,处在沪宁杭大三角的西部腰线上,是南京都市圈成员城市,是中部地区承接东部地区产业、资本转移的前沿阵地,皖苏浙交汇区域中心城市,近几年利用好自身区域优势,厚积薄发,经济实力逐渐增强;上述六市综合实力在安徽省比较靠前;第四类:铜陵、淮南、宿州、亳州、淮北、六安,上述六市综合实力在安徽省是较弱的;淮南是安徽省重要的能源城市,能源工业比较发达,近年开始城市转型升级,经济稍有所增强。淮北虽属全国能源基地,但近年未能较快转型升级,未大力发展替代产业,实力在全省较逊色,应寻找新的经济增长点,优化产业结构;铜陵有较好的地域优势,但属于资源城市,资源枯竭的背景下,受限于城市规模较小和产业结构单一而导致城市竞争力下降,产业转型升级任重道远,将枞阳融入地区版图后,城市规模有扩大,但目前总体经济跟不上全省步伐,目前来看,做大城市、做高层次、做出产业特色是铜陵城市竞争力和产业区域地位提升的关键;六安地处皖西大别山麓,工业基础较薄弱,发展较缓;宿州和亳州地处淮北平原,农业长期占据优势,其他产业发展过缓,市区域优势不明显,没有较强的产业支撑,综合实力在安徽省是比较弱的。第五类:黄山、池州,黄山位于皖南山区,虽旅游业发达,但产业结构单一,今后应依托丰富的旅游资源、生态资源,优化环境改革创新加快发展;上述的动态模糊聚类分析结果与最近几年实际情况基本上是吻合的。 同时也表明:安徽省城市综合实力区域差异明显,各城市的区域特征及存在的问题和发展状况不尽相同。为消除城市间发展的不平衡和促进地域间的协调发展,需结合自身实际,因地制宜制定各自的发展战略。 本文提出了基于动态模糊理论的数据聚类方法,并将其应用于18年安徽省城市综合实力的聚类分析,应用结果表明,该方法对于具有非线性特征的数据(如城市的经济数据、交通流量数据、设备故障数据分类诊断等)聚类具有很好的应用前景.同时,该方法对于其他专业领域如模式识别、模糊控制亦有一定的实际指导意义,为问题的突破提供好的思路。(二)模糊聚类的实现代码


四、安徽省城市综合实力的模糊聚类分析
(一)数据的预处理
(二)模糊聚类结果分析
五、结语
