基于R语言的金融数据分析
——以新浪股票数据为例
2020-04-28杨晓伟杨鸿鲜刘相国刘倩倩
杨晓伟,杨鸿鲜,刘相国,刘倩倩
(巢湖学院 数学与统计学院,安徽 合肥 23800)
随着我国国民经济的发展及科学技术水平的提升,金融领域的发展受到社会各界的高度重视。然而,金融行业的数据分析是一个极为复杂的体系,有众多不同的分支。因此大数据分析技术在这个新经济时代意义重大。近年来,数据分析软件层出不穷,如R、SPSS、Eviews、Matlab等数据分析软件。其中R语言以其独特的优势活跃于各个领域数据分析之中。R具备可拓展能力,且拥有丰富的功能选项,可帮助相关领域工作人员开展数据分析与研究活动。
金融数据分析离不开切实可靠的数据,数据是经济分析的基础,严谨的经济理论和经济形势预判均需真实有效的数据作为依据。由于R软件包涉及的领域极广,包含社交网络分析、统计、绘图、自然语言处理、生物信息统计等,并且它们拥有共同的一套R语言语法和语义规则,操作灵活简便。本文主要运用R的quantmod包和fBasics包从雅虎网的财经板块抓取新浪股票数据,为股票的市场走势分析打下基础。
在如今这个大数据时代,数据分析成为生活和工作中必不可少的项目。而数据分析就是采用恰当的统计分析技术对收集来的庞大的数据体系进行分析整理,提取有价值信息,形成一般规律或结论,并给出详细的概述[1]。例如经典的营销案例如沃尔玛啤酒与尿布;Suncorp-Metway使用数据分析实现智慧营销;还有辛辛那提动物园使用数据分析提高客户满意度等经典数据分析案例,深刻反映出数据分析的实用性遍布日常生活和工作过程中,帮助人们做出判断,利于人们采取适当行动[2]。而本文主要是运用R软件,实现对新浪股票数据的基础分析,这具有一定的现实指导意义。
1 R语言概述
从R的起源史来看,R工具的开发其实是用来替代昂贵的SPSS工具和SAS工具[3]。1992年开始,由两位新西兰奥克兰大学的统计学家为了方便讲授初等统计课程,而发明的以他们名字的首字母R为名称的编程语言,可认为R是S语言分支的一种实现[4]。R是目前使用最广泛的数据挖掘和分析工具,已成为一款极具特色且拥有广阔前景的应用软件。尤其在金融行业,金融数据的分析更是离不开R的。如人们可通过R对股票数据进行抓取,对获取的数据进行挖掘,得出分析结果,对金融行业及股票市场进行合理预判,以便对企业发展有更好的评估[5]。
1.1 R包的介绍
简而言之,R是一个关于包的集合,而包是关于函数、数据集、编译器等的集合。编译R程序的过程是通过创建R对象来组织数据,并通过调用系统函数或创建和调用自定义函数来逐步完成每个数据挖掘各阶段的任务。包作为R的核心思想可划分为基础包和共享包两大内容。基础包是R默认下载和安装的包,它支持各类数据基本统计情况的分析和基础制图等,其中还包括一些共享数据集供用户使用。而共享包是由R的全球性研究型社区和第三方提供的各种包的集合,涵盖了各类现代统计和数据挖掘方法,涉及的应用领域较多。使用者可根据自身的研究目的,有选择地自行指定下载、安装和加载。
1.2 R的基本函数
表1的函数主要用来对数据统计性质进行分析,利用R软件编程来呈现数据结果。
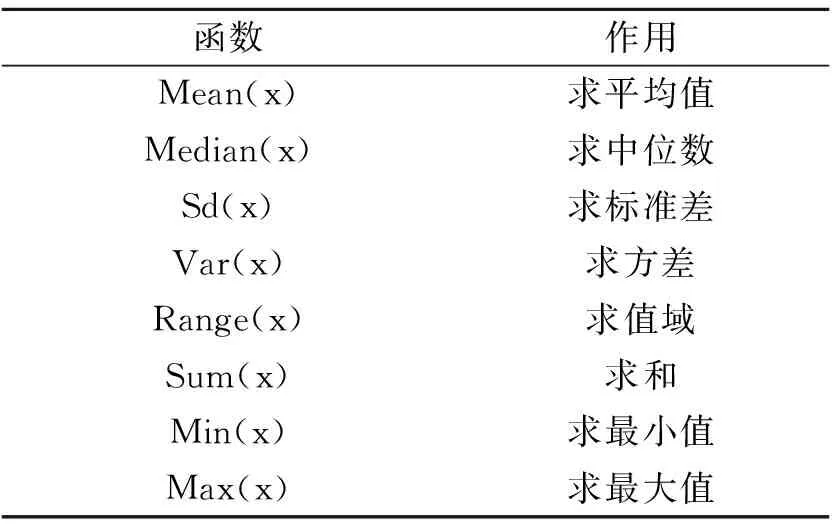
表1 基本统计函数介绍
表2是本文用来抓取股票数据并调用相关算法进行技术分析的R函数命令。

表2 主要调用R函数介绍
①library() 函数用来加载各种R包,其相当于一个大型“图书馆”,用来查找资料的。
②getSymbols() 函数是用来访问和下载作用对象的数据,如用来抓取新浪股票数据。
③chartSeries() 函数主要是用来绘制数据的K线图。
2 金融数据分析的理论介绍
金融行业数据信息量大且更新速度极快,因此应及时、准确、清晰的掌握金融数据,并对其进行精准的分析,以此判别金融市场走向,从而规避风险,作出正确抉择[6]。
2.1 金融数据分析的“统计常识”
金融数据分析需要一些基本的统计指标,如均值、方差、偏度、峰度等[7]。
所谓均值(mean)表示一组数据集中趋势的统计指标,是指一组数据中所有数据之和再除以这组数据的个数,其公式为:
对于方差(variance),它是度量随机变量或一组数据离散程度的指标,在很多实际问题中,方差的研究具有重要意义。其公式为:
标准差是样本中各个样本点到均值的距离之平均。简而言之,标准差描述的就是数据的“散布度”,其公式为:
偏度和峰度是数据分布情况的度量,数据在比较集中的地方会呈现出一个高峰,这个高峰可能偏左也可能偏右,因此引进了这两个指标,即偏度和峰度。偏度(skewness)是统计数据分布偏斜方向和程度的度量,也是统计数据分布非对称程度的数字特征,它是度量关于其均值的对称性。峰度(kurtosis)又称峰态系数,它反映了概率密度曲线在平均值处峰值高低的特征数[8]。
表3是对本文金融数据处理中一些描述性统计量的简单介绍。
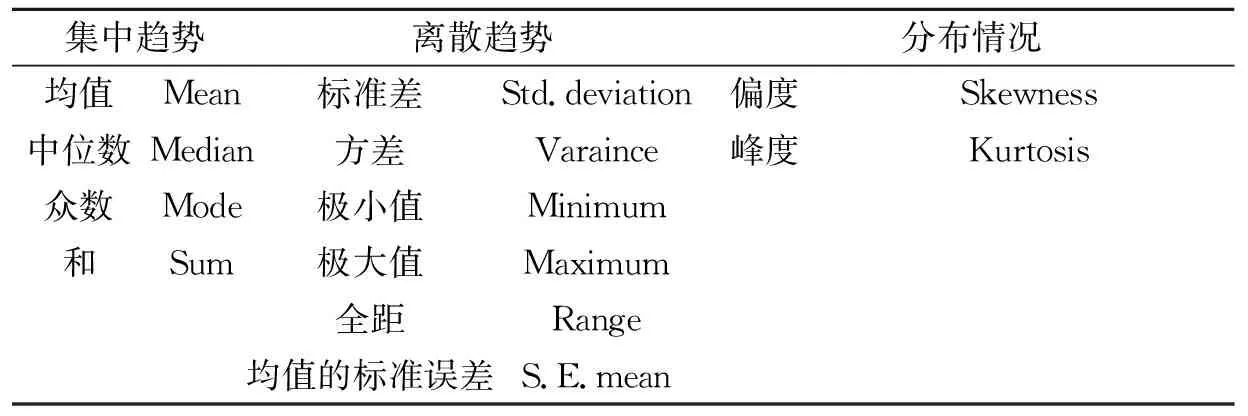
表3 描述性统计量介绍
2.2 正态性检验原理
正态性检验方法多样,本文主要用到的方法是JB正态性检验。所谓JB正态性检验,是Jarque和Bera两个人将单独的偏度t检验和峰度t检验融合在一起而建立的正态性检验原理。其公式为:
其中,n表示样本容量,S表示偏度,K代表峰度。若在规定的显著性水平下(通常为5%),则拒绝原假设,不满足正态分布;反之接受原假设,满足正态分布。
2.3 股票基础知识
股票是一种有价证券,它是由股份有限公司签发的证明,股东所持股份的凭证[9]。股票具有收益性、风险性、流动性、永久性、参与性五个特点。了解掌握和分析股票数据,必须了解股票数据的K线图、成交量、股票收益率等技术分析指标。
3 实例分析
在本文的主要目标是判断新浪股票数据是否服从正态分布并实现基础分析。若假设所研究时间段的新浪股票数据服从正态分布,收集数据后将使用适当的方法进行检验。
3.1 收集数据
3.1.1 加载R软件包
在金融数据分析中不可避免要运用R包来调用所需的分析方法或模型,本文主要调用“quantmod”和“fBasics”两种R包进行数据分析。
“quantmod”包是金融数据分析中抓取数据主要的R包之一,调用“quantmod”包可从一些相关的网站访问下载所需数据,如可利用此包直接从Yahoo、Google、MySQL、FRED等网站的财经板块下载所需的股票数据,本文主要从雅虎上访问下载相关数据。加载“quantmod”包需用到R软件中library() 函数。其中,如图1所示,在加载过程中需载入三个依赖的包。同样地,fBasics包的加载操作也是如此。
图1 加载quantmod包的操作过程
3.1.2 抓取股票数据
访问下载股票数据需要用到getSymbols()函数,以此命令来访问雅虎网上财经板块的数据,直接从网站下载股票数据。其中主要调用的股票代码为“SINA”,假如要读取某股票数据,首先要查询相应股票的代码,“SINA”正是本文所需的新浪股票代码。本文主要访问下载的是2018年3月到2019年2月的新浪股票数据,具体操作如图2。

图2 下载股票数据的指令
由于从雅虎网上抓取的新浪股票数据量巨大,查看完整数据非常不方便。因此本文仅查看已下载数据的前六行和后六行,调用命令head() 和tail()即可。图3表示已下载的前六行和后六行数据。

图3 查看指定行列数据
从图3中可看出,所访问的新浪股票数据的6个指标,包含每天的开盘价、最高价、最低价、收盘价、成交量和调整后的收盘价。这是研究股票收益率的重要依据。
3.1.3 数据预处理
一般常见的数据预处理就是判断是否有缺失值[10],基于R识别数据中是否存在缺失值NA一般调用函数is.na()或complete.cases(),但二者在判断的表达上有明显差异。
is.na()作用于对象之后,如果对应的数值为缺失值则返回TURE,否则为FALSE,使用求和函数sum()可计算出缺失值总数;
complete.cases()识别缺失值与is.na()刚好相反,缺失值为FALSE,正常数据为TURE。
从图4和图5的结果可看出两种方法呈现的结果是一致的,在抓取数据中并没有显示缺失值存在,因此判断该数据中无缺失值NA。

图4 is.na判断缺失值

图5 complete.cases判断缺失值
3.2 股票数据的图形绘制
3.2.1 股票数据的K线图
对于金融行业股票数据分析,要对股票数据做一个直观的了解,需要绘制股票数据的K线图[11]。K线图是记录某种股票一天的价格变动的范围。利用R绘制K线图直接调用chartSeries函数即可,这是绘制K线图的常用方法。
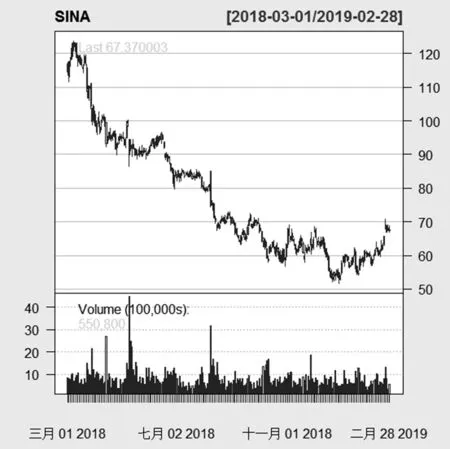
图6 新浪股票数据K线图(红涨绿跌)
图6的K线图表示新浪股票日收盘价和成交量变化趋势。从图中很直观地反映了2018年3月初到2019年2月底,新浪股票数据的收盘价最高点在2018年3月中旬,而成交量最高点在2018年5月中旬。
3.2.2 增加参数指标
本文主要通过应用R软件,对新浪股票数据进行典型图形绘制,主要增加了布林线(BBands)指标和趋向指标(ADX)等及技术分析指标,为什么要增加布林线指标和平均趋向指标呢?首先,根据其原理,一般来说股价一般是围绕如均线、成本线等价值中枢在一定的范围内波动,布林线指标在这一基础上认为股价信道的宽窄会随着股价的变化而变化,自动加之调整,具有变异性。所以这一指标以直观、灵活的特点逐步成为市场投资人关注的重点指标。其次,平均趋向指标虽然在呈现趋势的发展方向上有所欠缺,但是,如果存在一定的趋势,ADX(趋向指标)就可以用来衡量趋势的强度[12]。ADX的读数上升,说明趋势变强;反之,趋势变弱。因此布林线指标和平均趋势指标具有重要参考意义。
根据图7的布林线趋势图看出,2018年3月到5月,上、中、下轨线同时向下运行,说明市场弱势特征明显,这一时期内呈下跌趋势,股价一路下跌。之后的时间里,新浪股票的股价大致出现下跌,这可能是市场外部因素所致。
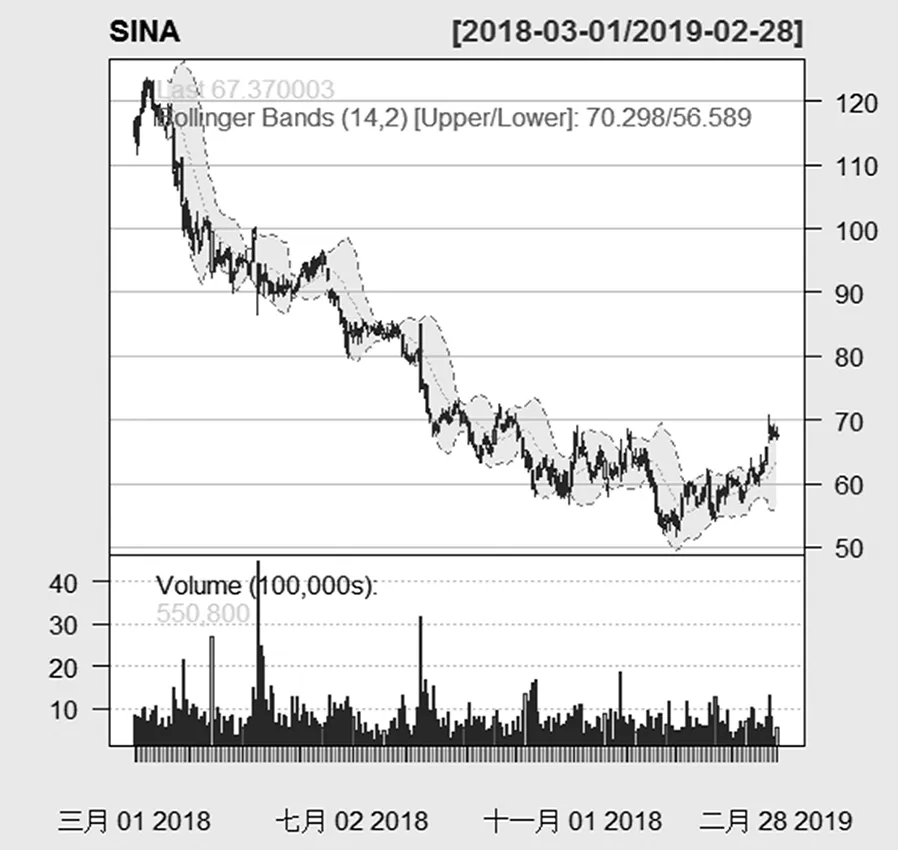
图7 增加布林线指标的线图
从图8的趋向指标图可看出,ADX值在高位由升转跌,预示行情即将反转,股票市场的行情属于不稳定阶段。
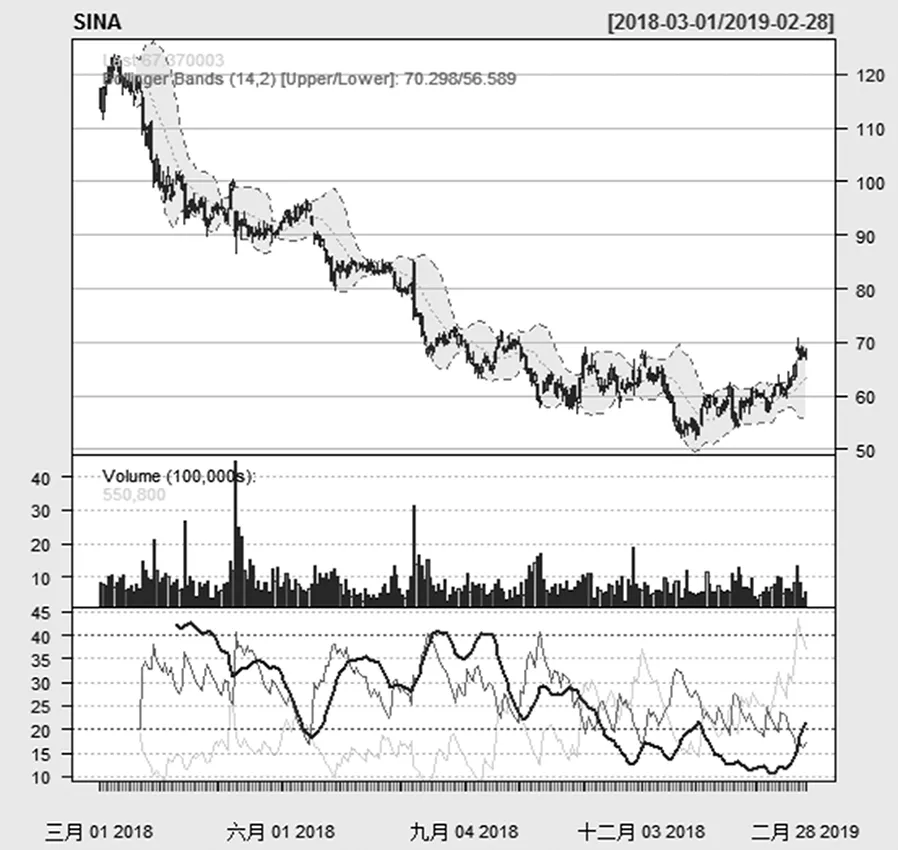
图8 增加ADX指标后的线图
3.3 股票收益率及典型图形
在股票市场中,研究股票收益率每天变化情况是非常重要的。除去周末,市场计算每天的收益率既可用开盘价,也可用收盘价。但是,通常来说以收盘价为基准计算收益率。在收益率的计算中,可以分为简单收益率和对数收益率,但基本上使用的是对数收益率,因为对数收益率具有严谨的“对称性”,同时也更容易体现统计特征。
由于R的功能强大,可利用R计算出对数收益率来分析新浪股票日收益率。此时需要载入PerformanceAnalytics安装包,然后载入程辑包,且计算对数收益率时需调用periodReturn函数来计算不同阶段的收益率,类型选择对数类型即可。
因为观察每天的对数收益率是一个庞大的数据,因此仅查看了2018年3月份6天的对数收益率,以及2019年最后6天的对数收益率,操作结果如图9所示。

图9 对数收益率的处理
根据对数收益率计算结果,绘制新浪股票收益率的K线图,如图10。从图中可看出股票收益率的波动情况。其中,股票价格使用的是调整后的收盘价。
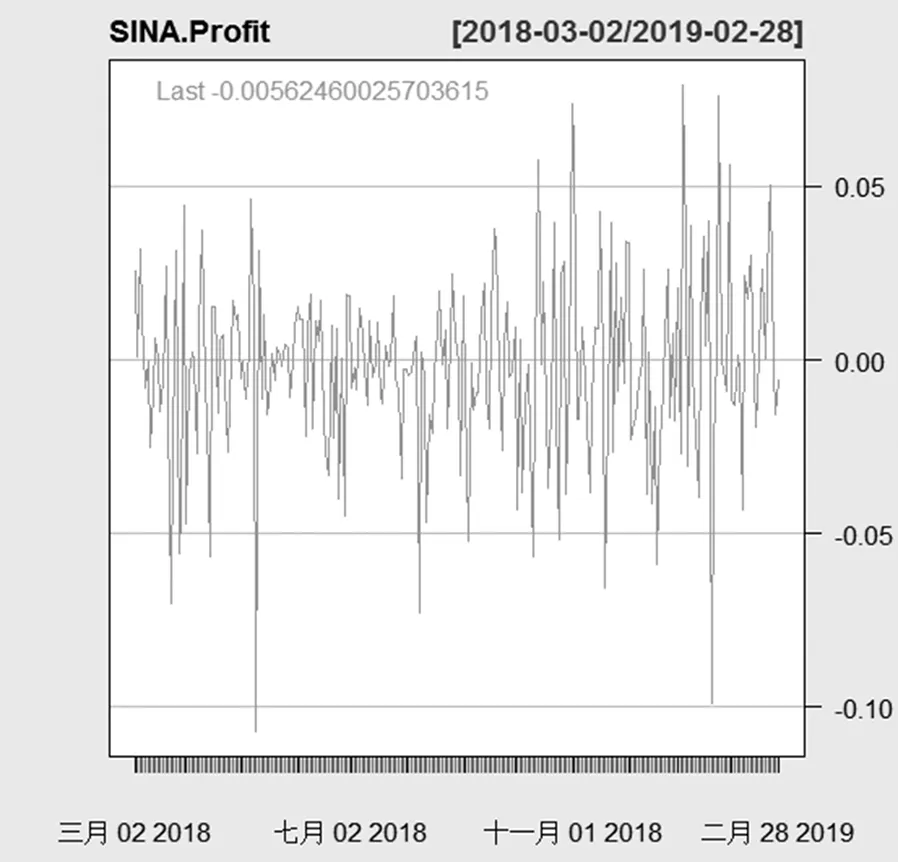
图10 股票收益率的K线图
绘制密度函数图之前需下载fBasics软件包,在R中编写代码载入相关程缉包,获取密度函数,查看数据的取值范围,根据这一范围,绘制密度函数即可。图11、图12加载了作密度函数图所需的R包,图13求出了该收益率密度函数的取值范围值。
图11 加载fBasics包

图12 求收益率的取值范围
图14是收益率密度函数图,可看出新浪股票数据的密度函数有明显的高峰厚尾现象,与正态分布差别很明显。
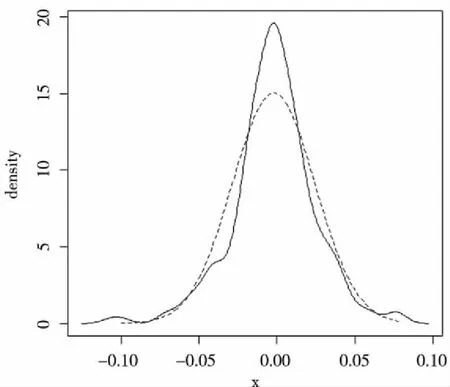
图14 股票收益率的密度函数图
3.4 股票收益率的正态性检验
在上文基础上,通过绘制新浪股票收益率的密度函数图与正态分布差异显著,因此需进一步利用正态性检验来验证。
3.4.1 股票收益率的基本统计量
调用basicStats()函数可获得新浪股票收益率,从图15中的计算结果来看,调整后的新浪收益率数据中,均值等于-0.002123,非常接近于0,表示新浪股票收益率有显著向0集中的趋势;方差等0.000704,接近于0,表示这段时期内新浪股票收益率的离散程度比较小,也可说是不分散的;偏度为-0.270431,明显不等于0,说明新浪股票收益率分布具有非对称性;峰度(Kurtosis)等于1.737217,明显小于3,说明了新浪股票收益率存在明显的高峰厚尾现象。这与之前绘制的密度函数相吻合,但仍需进一步进行正态性检验。
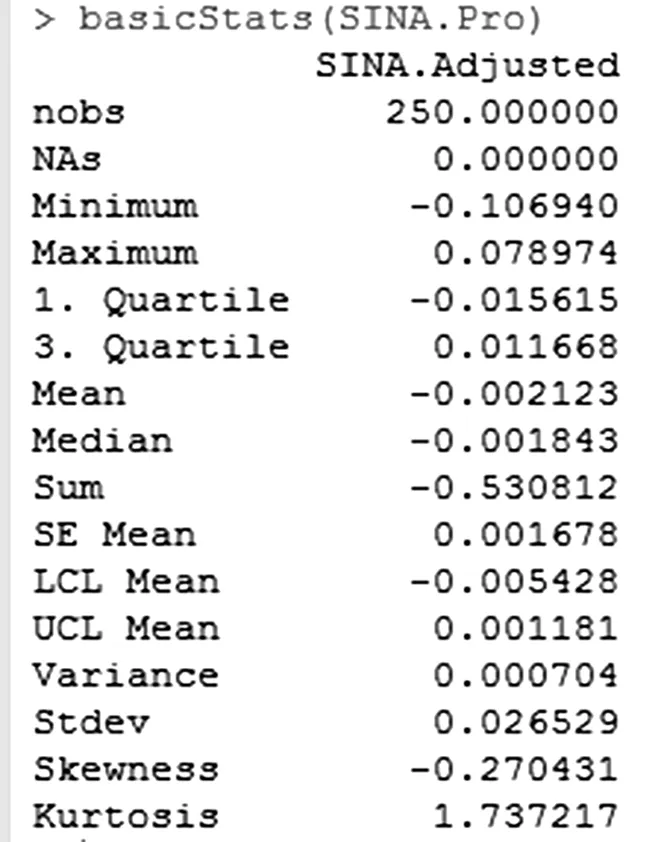
图15 新浪股票收益率的基本统计量
3.4.2 股票收益率的正态性检验
由于利用R计算JB统计量十分便捷,故本文主要运用JB检验。调用normalTest()函数,方法设置改为JB即可。根据图16的JB值为35.9158,且P=1.589e-8<0.05,表明在5%的显著性水平下应拒绝原假设,说明新浪股票收益率不服从正态分布。
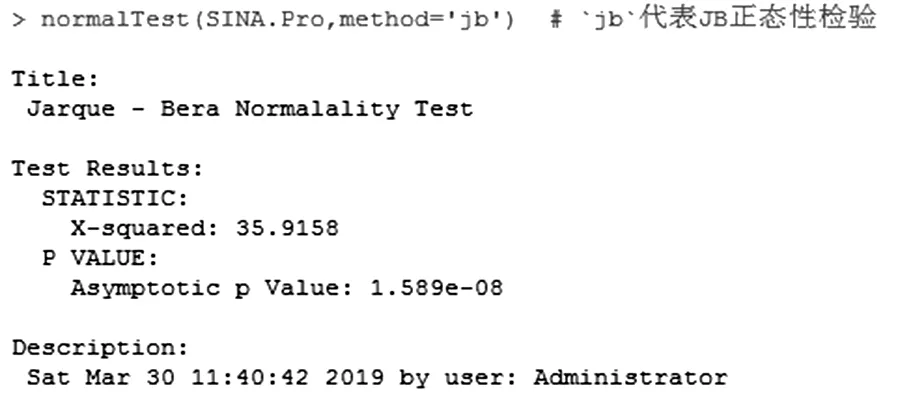
图16 JB正态性检验结果
3.5 成交量分析
由于股市成交量是股票买卖双方完成交易的数量,这也是技术分析中经常使用的重要指标。应用R计算某时间段股票总成交量是十分简便的,只需输入函数命令getSymbols,并分别调用chartSeries()、summary()和sum()三个函数便可得到股票成交量K线图和成交量数据汇总结果,如图17。从图中可看出新浪股票成交量在2018年4月、4月中旬、5月、8月中旬这几个时间点出现了“暴涨暴跌”的走势,之后从2019年初以后大致呈现上升趋势。
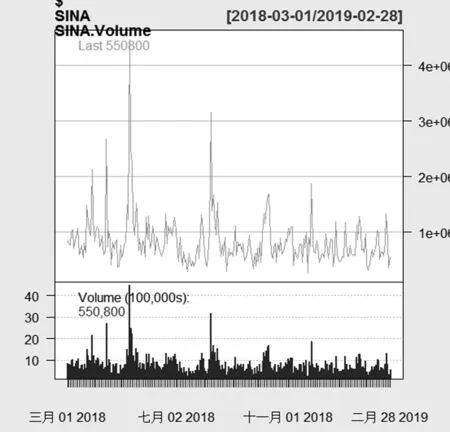
图17 股票成交量K线图
从图18的股票成交量汇总数据图可看出:2018年3月至2019年2月这一期间新浪股票的6个指标的最大值、最小值、均值等。结果显示该期间内,开盘价最大值为2019年2月28日的123.16,最小值为2018年3月1日的52.76;同理,剩下五个指标的值也一目了然。并且新浪股票在此期间内的总成交量为210832200(million)。

图18 成交量汇总数据图
4 结论
本文借助R语言中抓取股票数据常用的两个软件包对新浪股票的各项内容展开分析。通过上述数据分析结果,从新浪股票K线图可看出:从2018年3月下旬开始,股票走势整体出现下滑,直到2019年1月开始股票走势大致呈上升的趋势。从收益率的密度函数图来看,虽然图象基本运动符合近似正态分布形式,不是非常严格的周期到周期的循环往复,但它的基本运动形态是基于绝对价格的,而投资回报即股票收益率是基于相对价格的。所以理论上,在价格变化趋势明显的条件下,投资回报显然不是完全随机的,即股票收益率不服从正态分布。新浪股票数据这一期间所形成的密度函数图象中明显存在高峰厚尾现象,可预判收益率不服从正态分布。从JB检验结果可看出,首先随机误差趋近于0,说明样本数据的随机误差影响较小,方差也趋近于0。JB值为35.9158,且P值远小于0.05,进一步验证了收益率不服从正态分布这一结论。对新浪股票数据的成交量分析可知,2018年总成交量非常不稳定,在几个时间段出现“暴涨暴跌”的情况,但是自2019年开始,股票成交量逐步趋于平缓,但研究的大多时间段呈下降趋势。
本文基于R语言编程,实现了新浪股票的K线图、收益率等技术分析,避免了复杂大量的计算过程,缩小了计算误差,更清晰、准确地反映新浪股票的大致走势,为股票市场的预判和风险评估提供了参考依据。但金融数据的分析不仅需要借助大数据分析软件的技术支持,还要有对其他因素认真观察的能力,如需做大量的行业分析、公司分析等基本面分析。数据分析并不是一件容易的事,影响数据结果的因素有很多,一个好的数据分析师更应从国家政策、市场结构各项内容上提高关注,这也是本人以后工作应关注的地方。
