基于深度学习的端到端乐谱音符识别
2020-04-28黄志清郭一帆
黄志清,贾 翔,郭一帆,张 菁
基于深度学习的端到端乐谱音符识别
黄志清,贾 翔,郭一帆,张 菁
(北京工业大学信息学部,北京 100022)
光学乐谱识别是音乐信息检索中一项重要技术,音符识别是乐谱识别及其关键的部分.针对目前乐谱图像音符识别精度低、步骤冗杂等问题,设计了基于深度学习的端到端音符识别模型.该模型利用深度卷积神经网络,以整张乐谱图像为输入,直接输出音符的时值和音高.在数据预处理上,通过解析MusicXML文件获得模型训练所需的乐谱图像和对应的标签数据,标签数据是由音符音高、音符时值和音符坐标组成的向量,因此模型通过训练来学习标签向量将音符识别任务转化为检测、分类任务.之后添加噪声、随机裁剪等数据增强方法来增加数据的多样性,使得训练出的模型更加鲁棒;在模型设计上,基于darknet53基础网络和特征融合技术,设计端到端的目标检测模型来识别音符.用深度神经网络darknet53提取乐谱图像特征图,让该特征图上的音符有足够大的感受野,之后将神经网络上层特征图和该特征图进行拼接,完成特征融合使得音符有更明显的特征纹理,从而让模型能够检测到音符这类小物体.该模型采用多任务学习,同时学习音高、时值的分类任务和音符坐标的回归任务,提高了模型的泛化能力.最后在MuseScore生成的测试集上对该模型进行测试,音符识别精度高,可以达到 0.96的时值准确率和 0.98的音高准确率.
光学乐谱识别;音符识别;深度学习;端到端;目标检测
光学乐谱识别(optical music recognition,OMR)是光学字符识别在音乐上的应用,用于将乐谱识别为可编辑或可播放的形式,如MIDI(用于播放)和MusicXML(用于页面布局)[1-2].相对于乐谱其他符号,音符所占比例极高,其用于记录音高和时值,具有重要的语义信息,因此,音符识别是乐谱识别的核心与关键.
音符形态千变万化,其多样性和多态性特点决定了音符难以识别.传统的音符识别方法可划分为3类:分段、语法/规则、图形.分段的方法根据音符形状将音符划为不同分组,在每个分组中进行音符识别,例如Fornés等[3-4]提出符号描述符来分组音符并进行识别.第2类方法定义一组语法或规则来组合基元符号(如符头、符杠、符尾、符梁),如Baro等[5]将基元符号与一组预定义规则连接起来,之后使用树状图识别音符.最后基于图的方法[6]使用图来定义基元符号的关系并编码音符的形状.传统音符识别方法需要预先删除五线谱,之后抽取基元符号,通过组合基元符号完成音符识别,整个过程十分冗杂,每个步骤都会影响音符识别精度.
近年来深度学习在计算机视觉领域的突破使得OMR处理方式发生巨大改变,越来越多的研究集中于用深度学习解决OMR,研究方法大致分为两大类:目标检测和序列识别.目标检测的方法检测出乐谱图像中符号的位置并识别符号的类别.Pacha等[7]最先提出基于区域的卷积神经网络识别乐谱符号,通过将乐谱图像切割成许多单行五线谱图像,并使用R-CNN检测器获取单行五线谱中符号的位置和类别.Hajičjr等[8]结合语义分割模型和后续检测器识别乐谱,语义分割是用U-Net[9]架构完成的.音符识别问题被分解为一组二进制像素的分类问题,并随后使用连通分量检测器来得出符号的类别.Tuggener等[10]提出分水岭检测器来识别乐谱音符,它通过训练卷积神经网络模型使其学习自定义能量函数,该能量函数采用分水岭变换对整个乐谱进行语义分割.Tuggener等[11]使用DeepScores和MUSCIMA++数据集[12]评估算法性能.然而上述目标检测方法存在共同的局限性:模型只能识别符号类别,无法识别音符的音高和时值.序列识别方法直接将乐谱图像处理成序列输入到循环神经网络模型,模型预测出音符识别结果. Van der Wel等[13]将整张乐谱图像切割成多个图像片段,经过卷积神经网络和循环神经网络编码为固定大小的序列,然后用循环神经网络解码该序列识别音符的音高和时值.该方法的局限性在于无法直接输入整张图像,只能将图像切割成单行五线谱依次输入,该方法还存在着对多声部乐谱识别精度极低的问题.
深度学习在OMR的处理上存在巨大优势,识别精度比传统OMR方法有大幅度提升,识别步骤也更加简单.但目前基于深度学习的目标检测方法无法识别音符的音高和时值,序列识别方法处理多声部乐谱识别精度低等问题,本文针对印刷体乐谱提出一个基于深度学习的乐谱音符识别模型,即输入整张乐谱图像到该模型,直接输出乐谱上音符的时值和音高.该模型完全端到端,能够精准识别多声部乐谱图像.
1 数据集
本文中使用的数据集是根据MuseScore乐谱存档[14]中的MusicXML文件编制的.存档由用户生成的乐谱组成,在内容和结构上都具有多样化.大约选取了10000个MusicXML文件用于训练和评估,这些文件分为3个不同的子集.60%用于训练,15%用于验证,25%用于评估模型.
1.1 数据预处理
从选取MusicXML文件的语料库中,创建乐谱图像和相应音符注释的数据集.使用MuseScore将MusicXML文件转换为乐谱图像,图1表示生成的乐谱图像,乐谱对应的标签用音高、时值和音符边界框位置组成的向量表示.每个音符用两个值表示:音高和时值.在本文中音高被重新编码为垂直距离,即音符与五线谱垂直轴上的距离.音符的音高值由音符到五线谱的垂直距离而定,如图2所示,边上的数字表示音高的标签,红色音符的音高标签为5,黄色音符的标签为-2.时值的表示如图3所示,Note显示不同时值音符对应的形态,Duration表示音符的时值,Label表示编码后的的时值标签.时值以四分音符为一个单位,所以,本文中乐谱对应标签的时值和音高按照上述编码.

图2 音符的音高
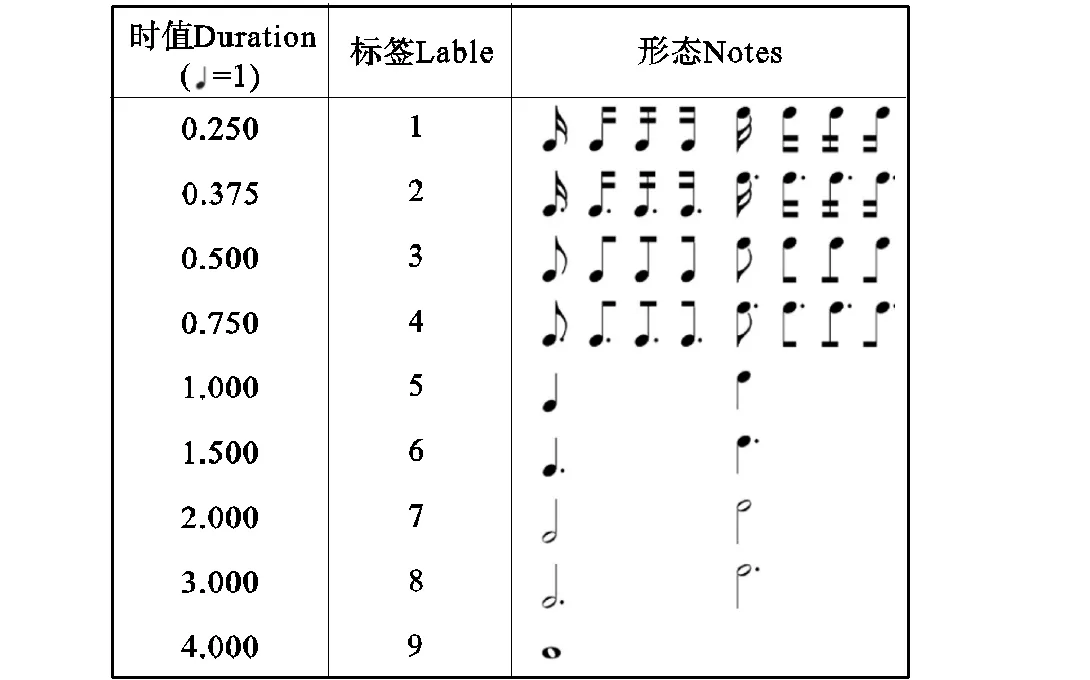
图3 音符的时值
1.2 数据增强
计算机生成的乐谱图像中不存在噪声和变化,训练出来的模型不具备泛化性.为了使本文的模型对较低质量的输入和不同类型的乐谱图像具有鲁棒性,本文提出了4种不同的增强方法,每种方法都模拟了自然环境下的输入噪声源.
首先将整张乐谱图像裁剪为左上、左下、右上、右下4张图像来扩增数据集,这样数据总量扩大了4倍.之后采用了模糊、弹性变换、色彩变换、仿射变换4种数据增强方法处理裁剪后乐谱图像.如图4所示,图1中的整张乐谱经过裁剪生成了4张图像,图4(a)经过高斯模糊处理;图4(b)采用弹性变换,改变图像视角;图4(c)经过仿射变换,向左旋转了5°;图4(d)经过色彩变换模拟光照对图像的影响.

图4 数据增强
2 端到端音符识别模型
本节介绍应用于端到端乐谱音符识别的深度卷积神经网络模型,模型的输入是预处理后的乐谱图像,输出为音符时值和音高,识别流程如图5所示.
2.1 模型结构
音符识别模型具体流程如下:将乐谱图像输入卷积神经网络,经过一系列卷积、残差、拼接操作,提取乐谱图像的特征图;之后在特征图上分类输出音符时值和音高并回归音符的边界框.
如图6所示,为了让音符有足够大的感受野,模型采用YOLOv3[15]中darknet53基础网络来提取特征,darknet53的网络结构分为5个部分,分别是conv1_x、conv2_x、conv3_x、conv4_x和conv5_x.其中conv1_x、conv2_x、conv3_x、conv4_x和conv5_x分别包括1、2、8、8、4个building block,每个building block包括2个卷积层和1个残差连接层.考虑到小物体经过卷积后会出现特征丢失,在darknet53基础网络输出特征图之后上采样8倍与上层网络的特征图进行特征融合来获取更加全面的特征信息.
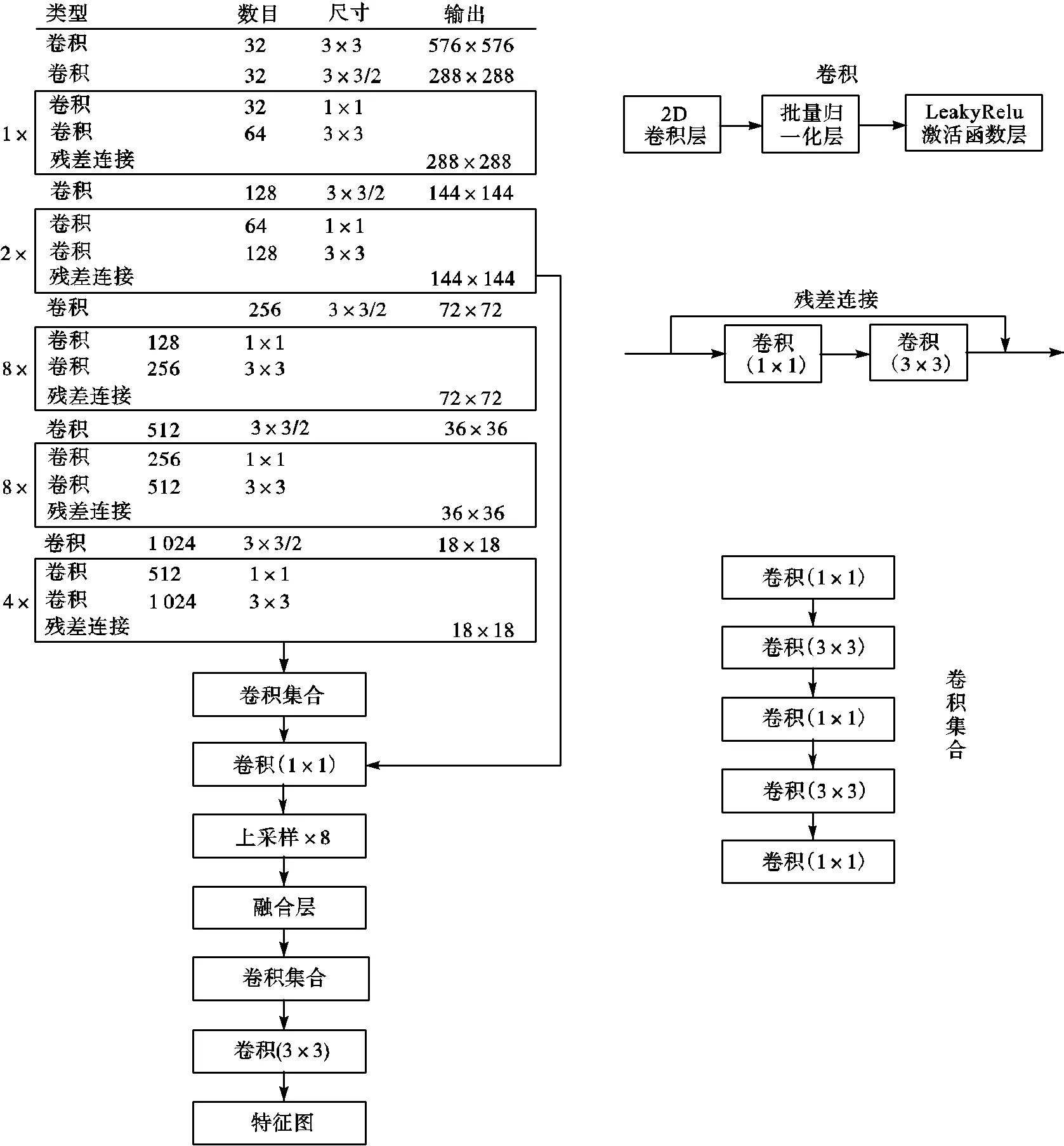
图6 网络结构
如图7所示,在卷积神经网络输出特征图之后,基于特征图上的每个像素点经过中间层生成维特征向量,特征向量的维度为7×(置信度+候选框坐标+音高类别+时值类别),即在维特征向量产生7个目标候选区域.对于每个目标候选区域,用sigmoid激活函数得到目标框的置信度、候选框的坐标、音符音高、音符时值,实现多任务训练.
置信度:sigmoid激活函数,值为0~1,输出维度为1.
候选框坐标:sigmoid激活函数,值为0~1,输出维度为4.
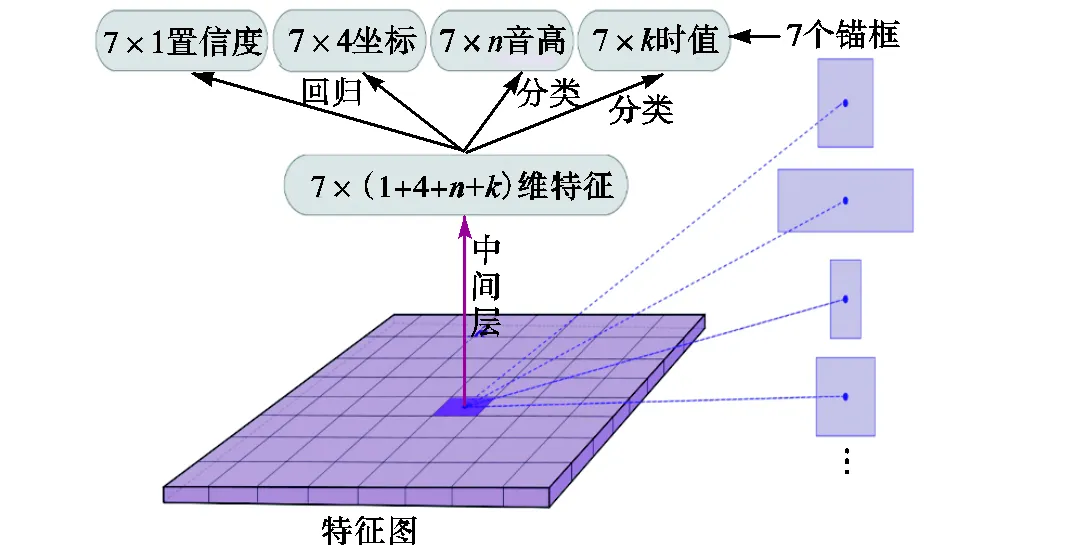
图7 网络分类和回归
音符音高:sigmoid激活函数,值为0~1,输出维度等于音符音高类别总数.
音符时值:sigmoid激活函数,值为0~1,输出维度等于音符时值类别总数.
本文采用单阶段目标检测模型,直接给出候选框的先验条件.实验不是手工选择先验候选框,而是在训练集对边界框的面积运用k-means聚类来自动找到好的先验候选框的宽高.在笔者的工作中,一共选取了7种尺寸的宽高作为先验条件输入.本文对7个不同的宽高运行k-means,并用最接近质心的宽高作为先验候选框输入给神经网络.使用k-means来生成候选框将使神经网络模型具有更好的效果,并使模型更容易学习.
2.2 音高和时值识别
图7展示了特征图上每个像素点会生成7个特征向量,在每个特征向量经过sigmoid激活函数输出音符的边界框的坐标、音高和时值.其中音符音高和时值采用二分类交叉熵计算损失函数,即


2.3 音符边界框回归
特征向量为每个候选框回归4个偏移量x、y、w、h.如果单元格像素点距图像左上角的偏移为(x,y),且候选框具有先验信息宽和高(w,h),则预测结果为
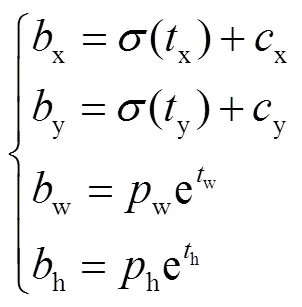
式中:b为模型输出的候选框坐标,=x,y,w,h;t为模型预测的偏移量.
特征图上的每个像素点预测7个特征向量,每个特征向量采用sigmoid激活函数回归边界框的偏移量(x,y,w,h),实验中使用均方误差计算损失函数,

2.4 损失函数
网络模型采用多任务训练,即同时训练分类和回归任务,损失函数为

式中:losstot为总的损失函数;lossb、lossc、lossd分别为回归偏移量的损失函数、音符音高分类的损失函数、音符时值分类的损失函数;lossconf为边界框置信度的损失函数.
模型使用逻辑回归预测每个边界框的置信度.首先设置预测的边界框和真实边界框之间面积重叠的阈值为0.6,如果预测的边界框与真实的回归框重叠部分超过任何其他预测的边界框,设定此边界框为最佳匹配且置信度为1.如果重叠部分超过阈值但不是最佳边界框,则忽略该预测边界框,即此边界框losstot为0.如果重叠部分小于阈值,则边界框的置信度为0.最后应用二分交叉熵计算置信度的损失函数.

式中:conf为候选框的置信度;overlap表示重叠面积;threshold为设定的阈值0.6.
3 实验及结果分析
本节介绍了端到端模型的训练方法,接着确定了评价方法并评测了实验结果,最后分析了实验的优点以及不足之处.
3.1 模型训练
在训练期间应用数据增强,并且每次向网络模型呈现不同的训练样本.使用随机梯度下降优化器训练模型的批量大小为32,初始学习率为0.001,学习率恒定衰减,每10个周期的学习率减半.大概40个周期后,模型开始收敛.采用单个Nvidia Titan X用于训练,在大约6h内训练完模型.
3.2 评价指标
在测试集上,本文计算了3种评测指标:时值准确率、音高准确率、音符精度均值.
(1) 音高准确率,准确预测音高的比例.
(2) 时值准确率,正确预测时值的比例.
(3) 音符精度均值,衡量预测的边界框准确率.
神经网络模型输出一组候选区域,候选区域包含音符的边界框、音符时值、音符音高和音符置信度.当候选区域的音符时值与对应的实际音符时值一致时,将其设置为正样本FS.否则设置为负样本NS.时值的准确率为

音高准确率与时值准确率计算方式一样,预测音高正确为正样本,反之为负样本.
如果候选框与真实边界框iou大于设定的阈值且该候选框的音符类别与真实边界框的音符类别匹配,则认为是正样本TP,否则为负样本FP.如果特征图上存在真实边界框,网络模型却没有预测到候选边界框,则记为漏检FN.精度均值AP定义为精度和召回率曲线下的面积,式(8)表示召回率和准确率的计算.
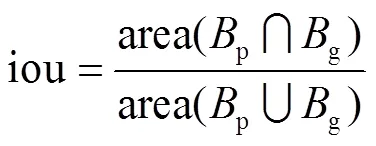
式中:p为模型输出的候选框;g为真实边界框;area表示面积.
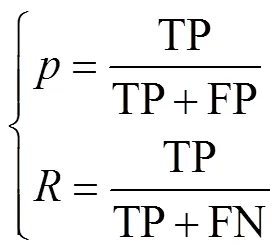
式中:TP为正样本;FP为负样本;FN为漏检.
3.3 实验结果与分析
模型一共测试了2500张由MuseScore转换的乐谱图像,整体的识别结果如下:音符的精度均值AP为0.87,时值准确率为0.96,音高准确率为0.98.识别结果如图8所示.图8中绿色数字表示音符的音高,红色数字表示音符时值.

图8 音符识别结果
表1展示了目前针对OMR具有代表性的工作.Van der Wel等[13]应用MuseScore数据集,与本文的工作相似,结果能够得到0.80的音符准确率、0.94的时值准确率和0.81的音高准确率,但其系统需要先将乐谱图像切成单个五线谱图像输入,大大增加了系统的运行时间,且对多声部乐谱音符识别精度极低.本方法能够获取0.98的音高准确率和0.96的时值准确率,相比有精度优势,同时能够识别多声部乐谱.表1中其他人的方法由于采用不同的数据集,且OMR中很少有固定的评估标准[17-18],只能定性地比较识别结果,本文有0.87的符头精度均值,高于Tuggener等[10]的0.74符头精度均值.Hajičjr等[8]在MUSCIMA++上识别乐谱,其结果在音高和符头表现很好,但时值的准确率非常低,原作者没具体展示.本文时值识别较其有很大的优势.
本文的方法在Intel Xeon 5310的CPU上,识别一整张乐谱的时间是1.02s,整个过程完全端到端,输入乐谱图像,输出音符时值和音高.但是本文的方法存在一些不足之处.
(1) 音符识别范围有限:如图1所示,五线谱上下扩展2条线,音高的范围在-4~12;时值识别的范围在十六分音符到全音音符之间.
(2) 音符识别的准确性:本方法只有在检测到音符的边界框后才会识别音符的时值、音高,也就是说,是否能够准确检测到音符,对音符的识别结果影响非常大.
表1 实验结果比较
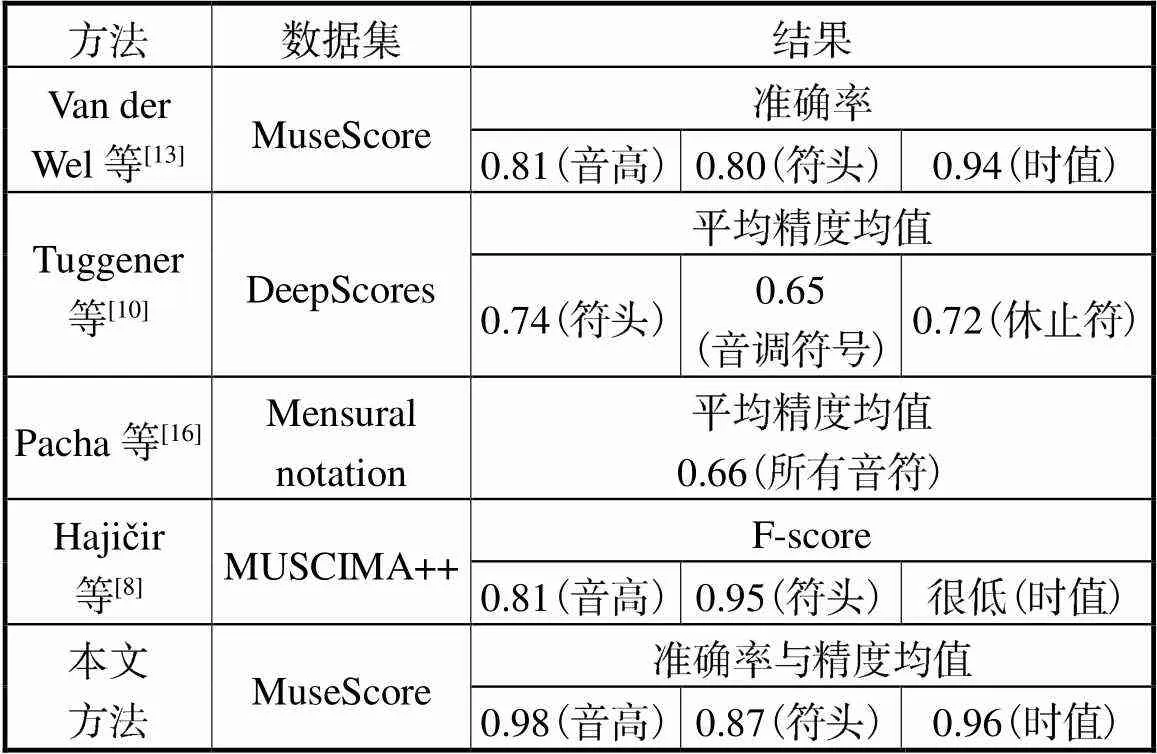
Tab.1 Comparison of experimental result
4 结 语
本文针对印刷体乐谱提出端到端的音符识别模型,应用深度卷积神经网络检测音符边界框并识别其时值和音高.实验测试结果显示识别一整张乐谱图像只需1s,并能够获取96%的时值准确率和98%的音高准确率.下一步的研究将集中在两个方面:乐谱记号,手写体乐谱.识别乐谱记号并语义重建乐谱完成OMR整个流程,之后将本文的方法扩展应用到自然手写乐谱.
[1] Bainbridge D,Bell T. The challenge of optical music recognition[J]. Computers and the Humanities,2001,35(2):95-121.
[2] 刘晓翔. 乐谱图像中的音符识别方法[J]. 计算机工程,2010,36(9):163-167.
Liu Xiaoxiang. Note recognition method in music score image[J]. Computer Engineering,2010,36(9):163-167(in Chinese).
[3] Fornés A,Llados J,Sanchez G,et al. Rotation invariant hand drawn symbol recognition based on a dynamic time warping model[J]. International Journal on Document Analysis and Recognition,2010,13(3):229-241.
[4] Escalera S,Fornés A,Pujol O,et al. Blurred shape model for binary and grey-level symbol recognition[J]. Pattern Recognit Lett,2009,30(15):1424-1433.
[5] Baro A,Riba P,Fornés A. Towards the recognition of compound music notes in handwritten music scores[C]// International Conference on Frontiers in Handwriting Recognition. Shenzhen,China,2016:465-470.
[6] Pinto J C,Vieira P,Sousa J M. A new graph-like classification method applied to ancient handwritten musical symbols[J]. International Journal on Document Analysis and Recognition,2003,6(1):10-22.
[7] Pacha A,Choi K Y,Coüasnon B,et al. Handwritten music object detection:Open issues and baseline results[C]// Proceedings of the 2018 13th IAPR Workshop on Document Analysis Systems(DAS). Vienna,Austria,2018:24-27.
[8] Hajičjr J,Dorfer M,Widmer G,et al. Towards full-pipeline handwritten OMR with musical symbol detection by u-nets[C]// Proceedings of the 19th International Society for Music Information Retrieval Conference. Paris,France,2018:23-27.
[9] Ronneberger O,Fischer P,Brox T. U-Net:Convolu-tional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich,Germany,2015:234-241.
[10] Tuggener L,Elezi I,Schmidhuber J,et al. Deep watershed detector for music object recognition[C]// Inter-
national Society for Music Information Retrieval Conference. Paris,France,2018:23-27.
[11] Tuggener L,Elezi I,Schmidhuber J,et al. DeepScores:A dataset for segmentation,detection and classification of tiny objects[C]// International Conference on Pattern Recognition. Beijing,China,2018:20-28.
[12] Hajic J,Pecina P. The MUSCIMA++ dataset for handwritten optical music recognition[C]// International Conference on Document Analysis and Recognition (ICDAR). Kyoto,Japan,2017:39-46.
[13] Van der Wel E,Ullrich K. Optical music recognition with convolutional sequence-to-sequence models[C]// The International Society for Music Information Retrieval. Suzhou,China,2017:731-737.
[14] MuseScore. The Free and Open-Source Score Writer[EB/OL]. http://musescore.org,2018-08-28.
[15] Redmon J,Farhadi A. YOLOv3[EB/OL]. https://avxiv. org/abs/1804.02767,2018-04-08.
[16] Pacha A,Calvo-Zaragoza J. Optical music recognition in mensural notation with region-based convolutional neural networks[C]//The International Society for Music Information Retrieval. Paris,France,2018:240-247.
[17] Donald B,Jakob G S. Towards a standard testbed for optical music recognition:Definitions,metrics,and page images[J]. Journal of New Music Research,2015,44(3):169-195.
[18] Christian F,Meinard M,Frank K,et al. Automatic mapping of scanned sheet music to audio recordings[C]// Proceedings of the International Conference on Music Information Retrieval. Philadelphia,USA,2008:413-418.
End-to-End Music Note Recognition Based on Deep Learning
Huang Zhiqing,Jia Xiang,Guo Yifan,Zhang Jing
(Faculty of Information Science,Beijing University of Technology,Beijing 100022,China)
Optical music recognition(OMR)is an important technology in music information retrieval.Note recognition is the key part of music score recognition.In view of the low accuracy of notes recognition and the cumbersome steps of the recognition of music score image,an end-to-end note recognition model based on deep learning is designed.The model uses the deep convolutional neural network to input the whole score image as the input,and directly outputs the duration and pitch of the note.In data preprocessing,the music image and the corresponding tag data required for model training were obtained by parsing the MusicXML file,the label data was a vector composed of note pitch,note duration and note coordinates,therefore,the model learned the label vector through training to transform the note recognition task into detection and classification tasks.Data enhancement methods such as noise and random cropping were added to increase the diversity of data,which made the trained model more robust.In the model design,based on the darknet53 basic network and feature fusion technology,an end-to-end target detection model was designed to recognize the notes.The deep neural network darknet53 was used to extract the feature image of the music image,so that the notes on the feature map had a large enough receptive field,and then the upper layer feature map of the neural network and the feature map were spliced,and the feature fusion is completed to make the note have more obvious feature and texture,allowing the model to detect small objects such as notes.The model adopted multi-task learning,and learned the pitch and duration classification task and note coordinates task,which improved the generalization ability of the model.Finally,the model was tested on the test set generated by MuseScore.The note recognition accuracy is high,and the duration accuracy of 0.96 and the pitch accuracy of 0.98 can be achieved.
optical music recognition;note recognition;deep learning;end-to-end;object detection
TP18
A
0493-2137(2020)06-0653-08
10.11784/tdxbz201904072
2019-04-27;
2019-07-06.
黄志清(1970— ),男,博士,副教授.
黄志清,zqhuang@bjut.edu.cn.
北京市自然科学基金-市教委联合资助项目(KZ201910005007).
Supported by theBeijing Natural Science Foundation-Municipal Education Committee Co-Sponsored Project(No.KZ201910005007).
(责任编辑:王晓燕)
