基于时空感知级联神经网络的视频前背景分离
2020-04-28杨敬钰宋晓林岳焕景
杨敬钰,师 雯,李 坤,宋晓林,岳焕景
基于时空感知级联神经网络的视频前背景分离
杨敬钰1,师 雯1,李 坤2,宋晓林1,岳焕景1
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 天津大学计算机科学与技术学院,天津 300350)
针对在复杂情景下视频前背景分离技术中存在的前景泄露问题,设计开发了一个端对端的二级级联深度卷积神经网络,实现了对输入视频序列进行精确的前景和背景分离.所提网络由一级前景检测子网络和二级背景重建子网络串联而成.一级网络融合时间和空间信息,其输入包含2个部分:第1个部分是3张连续的彩色RGB视频帧,分别为上一帧、当前帧和下一帧;第2个部分是3张与彩色视频帧相对应的光流图.一级前景检测子网络通过结合2部分输入对视频序列中运动的前景进行精确检测,生成二值化的前景掩膜.该部分网络是一个编码器-解码器网络:编码器采用VGG16的前5个卷积块,用来提取两部分输入的特征图,并在经过每一个卷积层后对两类特征图进行特征融合;解码器由5个反卷积模块构成,通过学习特征空间到图像空间的映射,从而生成当前帧的二值化的前景掩膜.二级网络包含3个部分:编码器、传输层和解码器.二级网络能够利用当前帧和生成的前景掩膜对缺失的背景图像进行高质量的修复重建.实验结果表明,本文所提时空感知级联卷积神经网络在公共数据集上取得了较其他方法更好的结果,能够应对各种复杂场景,具有较强的通用性和泛化能力,且前景检测和背景重建结果显著超越多种现有方法.
背景重建;运动物体检测;卷积神经网络;光流
前背景分离是视频分析技术中的一项基本任务,目的是从输入视频序列中提取出两个互补分量:静态背景分量和运动前景分量,其在计算机视觉领域中有非常广泛的应用,包括运动检测[1]、目标跟踪[2]、行为识别[3]等.前背景分离任务在真实的视频场景下面临着各种挑战,如恶劣天气、相机抖动、光照条件变化、背景移动等,在这些情况下,前景常常会泄露到背景当中,造成不准确的分离结果.
在过去的十数年间,研究者们已提出许多方法用来解决这一问题.早期的研究工作通过在各种统计模型(如高斯混合模型[4]、非参数模型等[5])下局部地估计像素强度的分布,从而将像素分类为背景成分或前景成分.这类方法计算复杂度低,分离速度快,可以很好地处理简单的视频场景.但由于其忽略了视频序列中重要的全局结构,在复杂场景下分离效果往往不尽如人意,常常丢失复杂的纹理、轮廓等细节信息.
近年来,基于鲁棒主成分分析[6](robust principal component analysis,RPCA)的方法引起了学界的广泛关注.Candès等[6]表明前背景分离可以建模成一个低秩矩阵恢复问题:将每一个视频帧拉成一列,按时间顺序组成一个二维观测矩阵.背景分量在时域上是不变的,因此其对应一个低秩矩阵分量;而前景分量在视频帧上通常只占据一小部分,可通过稀疏矩阵建模.因此,前背景分离任务则转化成了将观测矩阵分解为低秩阵和稀疏阵的问题.这种方法充分利用了视频序列的全局结构信息,许多研究工作基于这一基本原理针对特定问题做出了相应改进,极大地提高了分离的准确性.Zhou等[7]提出通过检测连续异常值来分离运动物体,前景和背景分量通过马尔科夫随机场(Markov random field,MRF)同时优化,分离结果连续平滑,具有很好的视觉效果.同时Zhou等[7]的模型中还引入了仿射变换算子,可以将相机视角不固定的视频序列配准到固定视角下,从而解决动态视频背景恢复困难的问题.但该方法仅可以处理背景的小范围移动,当背景运动相对较大时,分离结果严重失真,且分离出的前景分量的轮廓信息不精确.Cao等[8]在鲁棒主成分分析的框架基础上引入总变差正则化约束时空连续性,该方法对于一些包含不规则运动的场景能够取得不错的效果,例如当视频中含有摇晃的树枝、波动的水面等,一般的方法会将这类物体归为前景,但事实上它们是属于背景的,Cao等[8]的方法则可以很好地处理这类问题.但该方法是批处理方法,需要将所有的视频帧统一处理,计算复杂度高,程序运行较慢,对计算机硬件要求较高,且同样不能处理动态背景.
简而言之,这些传统方法通常依赖于很强的先验条件,所以它们可以在特定的条件下很好地处理一些场景.但是,当面对更加复杂的视频场景,约束条件不再满足时,这些方法则无法取得很好的效果.在这种情况下,迫切需要提高前背景分离方法对通用复杂视频的适用性.近年来,卷积神经网络(convolu-tional neural network,CNN)被广泛应用于计算机视觉领域,在图像和视频处理方面取得了一系列卓越成就.CNN在前背景分离方面的应用也逐渐兴起.
Xu等[9]使用一个串联网络实现背景重建和前景检测,该方法首先通过基于自动编码器的卷积神经网络恢复背景图,然后根据已生成的背景图和原始图像,使用全卷积网络生成二值化的前景图.Lim等[10]提出基于三重卷积神经网络的前景分割方法,利用多尺度特征编码实现对单个视频帧的前景检测.虽然基于深度学习的方法较传统方法相比有诸多优势,且在复杂视频的分析上取得了很大的进展,但这些方法仍存在一些缺陷.首先,大多数方法采用单张视频帧作为输入,而从单张图片上是无法捕捉运动信息的,此时前景检测的结果往往不够准确.其次,这些方法的通用性较差,一个网络模型只能处理一种场景,当换用不同场景时,就需要重新训练模型,这会导致过拟合的问题,且在实际应用中是十分不便捷的.
本文提出了一个时空感知的端对端级联深度卷积神经网络,以实现前景和背景的准确分离.它由一级前景检测子网络(FDnet)和二级背景重建子网络(BRnet)组成.一级网络的输入分为2个部分:第1个部分是作为空间信息为引导的3张连续彩色RGB视频帧(前一帧、当前帧和下一帧),以避免因单张视频帧造成的运动信息不准确的问题;第2个部分是作为时间信息引导的3张连续光流图(与3张彩色RGB视频帧相对应).由于光流图可用来表征相邻视频帧之间的移动物体的运动速度,包括速度大小和方向,所以将光流图输入到网络中有利于模型检测前景的运动信息.这部分网络的输出是当前帧的二值化前景掩膜,以指示移动对象的区域(1代表前景,0代表背景);接着,二级网络以一级网络生成的前景掩膜和当前帧作为输入,重建出完整的背景.由于背景通常具有局部相似性,因此网络能够很好地学习这种相似性并有效地恢复背景.同时,本文方法充分考虑了训练数据的多样性和复杂性,在训练网络时将不同的视频场景数据混合,保证网络具有较强的泛化 能力.
1 时空联合的级联卷积神经网络
本文提出了一种融合时空信息的级联卷积神经网络,网络架构如图1所示.具体而言,一级前景检测子网络通过融合时间和空间信息来检测前景.接着,将当前帧乘以生成的二值化前景掩膜输入到二级背景重建子网络中,对前景缺失的视频帧进行高质量的修复重构.
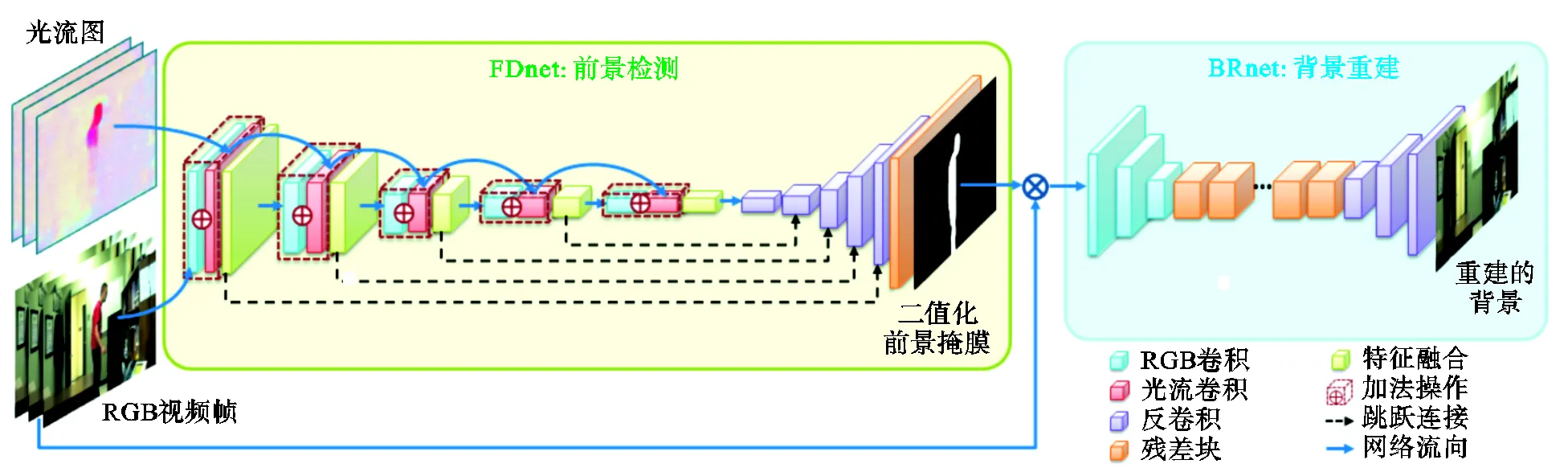
图1 本文所提的网络框架
1.1 一级前景检测子网络
本文提出了一个融合时空信息的多输入编码-解码前景检测子网络(如图1中绿色框图所示),目的是从原始的视频帧中检测出运动的物体.具体来说,采用VGG16[11]的前5个卷积块作为编码器来提取运动物体的丰富特征,并利用5个转置卷积层作为解码器将特征映射到掩膜中.准确地检测出前景的关键是识别出画面中哪些物体是运动的,因此仅从单张视频帧中检测前景是不合适的.与先前的工作不同,本方法的网络输入分为2部分.第1个部分是9通道的 3张连续的原始RGB视频帧(前一帧、当前帧和下一帧),以引入前景的空间信息,网络可以从3张不同的视频帧中学习到它们之间的差异,这种差异暗含着运动信息.第2个部分是6通道的与原始视频帧相对应的光流图,以引入前景的时域信息.注意光流图与视频帧是一一对应的关系.两个输入分别用权重不共享的卷积层提取特征,在每一个卷积层后面都增加一个特征融合层对两类特征图进行融合,即
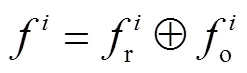
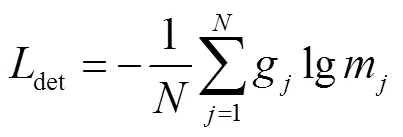
1.2 二级背景重建子网络
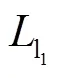
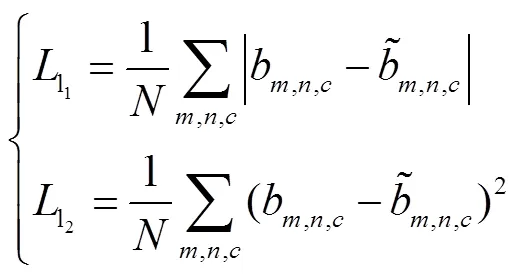
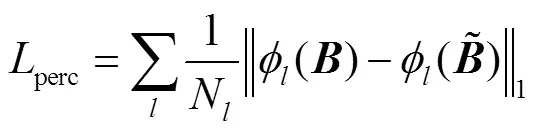
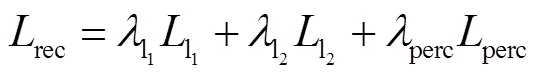

对于神经网络,选取合适的网络优化算法能够极大地提升网络训练速度.因此,本文采用均方根误差(RMSprop)优化函数来降低损失,RMSprop优化函数是很长时间以来经得住考验的优化算法,并且适用于各种不同的深度学习网络结构,收敛速度更快的同时波动幅度更小.对于两个子网络,训练时批尺寸大小设置为8,学习率设为0.001.子网络训练好后,接着训练整体网络进行微调,此时批尺寸设为4,学习率设为0.0001.在硬件条件满足的情况下,批尺寸设置越大越好.通过这种逐步训练方式,网络可以很快收敛.
2 实验验证与结果分析
2.1 数据集
为了保证训练好的网络能够有效地应对各种不同的场景,在选取训练集时应尽量确保训练数据集的多样化和合理性.本方法采用CDnet2014异常物检测公开数据集[13]作为训练数据.该数据集包含11种场景类别,53个不同的视频序列,但其中有些视频序列的前景真值掩膜不完整,因此,本文从中选出了30个具有合适标签的视频序列.训练数据充分考虑了场景和运动物体的多样性,例如冰雪天气、相机抖动、运动遮挡、光照变化等真实场景,场景中包含人、汽车、船、动物等各种运动目标.训练数据的多样性能够保证网络具有较强的通用性和泛化能力.
考虑到训练数据的均衡性,对于每一个场景,随机选取500帧.有一些场景的视频帧数比较少,不足500帧,则需要进行数据增广.具体的做法是:首先用前景的二值化真值掩膜将前景从原始视频帧中分割出来,然后将分割出来的前景图进行水平翻转,最后将翻转后的前景图贴到背景的真值图上.保证训练数据的均衡性有助于提高网络的泛化能力,避免网络过度拟合某一种特定类型的场景,而对其他场景欠拟合.在全部的15000帧训练数据中,随机划分80%的数据作为训练集,其他20%作为测试集.值得一提的是,由于各个场景图像的尺寸大小不一,在训练网络之前需要将所有的训练数据统一调整为256× 256的大小.
2.2 前景检测实验结果分析
为了合理评估所提网络在前景检测方面的有效性,本文从测试数据集中选取了4个有代表性的数据:办公室(office)、林荫道(boulevard)、滑冰(skating)、落叶(fall).它们分别代表不同类型的复杂场景:运动遮挡、相机抖动、恶劣冰雪天气、动态背景.为了客观准确地评估所提方法的有效性,采用测度值(-measure)作为量化指标,测度值是前景检测方向被广泛使用的一种测量指标,值越大代表效果越好.本文方法与现有8种具有代表性的算法的量化比较结果如表1所示.第1~5行代表传统方法,第6~9行代表深度学习方法.从表中可以看出,本文方法除落叶(fall)场景较DeepBS[16]方法稍低外,在其他3个场景上都达到了最好结果,平均指标超过次优方法DeepBS[16]4.53%.
表1 9种方法的前景检测结果的测度值比较

Tab.1 F-measure comparison of nine methods of foreground detection
除了数值上的客观比较,前景检测结果还需要满足视觉上的可观性.图2显示了本方法与其他5种方法的视觉质量比较结果.从对比图中可以看出,本方法在视觉上更加接近真值图,检测出来的前景掩膜更加准确,能够保持物体边缘的轮廓信息,同时结果图像中的噪声更低.而其他方法则出现了不同程度的噪声.例如在落叶(fall)场景中,由于该场景的背景包含摇摆的树枝,RPCA[6]、TVRPCA[8]和CL_ VID[17]错误地把树枝当成了前景,导致结果图中出现了严重的噪声.而DECOLOR[7]和CascadeCNN[15]方法的结果图中虽然噪声并不明显,但检测出来的车的轮廓信息与真值图相比有较大差距.在包含相机抖动问题的林荫道(boulevard)场景中,所有的对比方法均出现了不同程度的噪声,尤其是CL_VID[17]方法.而在相对简单的办公室(office)场景中,RPCA[6]方法和TVRPCA[8]方法都出现了非常明显的空洞,这些空洞是由运动遮挡造成的,人物在同一个位置停留时间较长,这两种方法将空洞部分的前景像素误当成背景像素.

图2 前景检测结果的视觉质量比较
综合客观上的量化结果以及主观上的视觉质量结果,本文所提方法可以应对各种复杂的视频场景,实现准确的前景检测,通用性和可扩展性较强,具有一定实际意义.
2.3 多输入对网络性能的影响分析
为了验证多输入的方法对前景检测的有效性,同时测试以连续的3个视频帧作为输入是否会损失长程信息,本小节设置了对比实验:分别以1帧、3帧、5帧作为网络输入,采用在VGG16[11]上预训练好的参数作为初始化权重,比较它们的前景检测结果.图3给出了不同的输入分别在3种场景下的视觉质量结果.从结果图中可以看出,多帧输入(图3(d)和(e))的前景检测结果更加接近真值图,能够保持较为准确的轮廓信息.单帧输入的结果则较为逊色,甚至在highway这个场景下没有检测出右上角运动的汽车,这是因为将多种视频场景混合在一起训练时,网络无法从一张图像中准确地判断出哪个物体是运动的,哪个物体是静止的,所以网络只能大致判断出图像中的显著性物体.从图中还可以看出,3帧输入和5帧输入的结果差别并不明显,但是在office这个场景中,5帧输入的结果没有3帧的好,这是因为增加的视频帧与当前帧相关性并不大,从而引入了一些不必要的误差,由此可以得出,网络的输入并不是越多越好.对比实验的量化结果如表2所示,多输入的测度值十分接近,而3帧输入的平均测度值最高,从而进一步验证了本文所提方法的有效性.
表2 不同输入下的前景检测结果的测度值比较
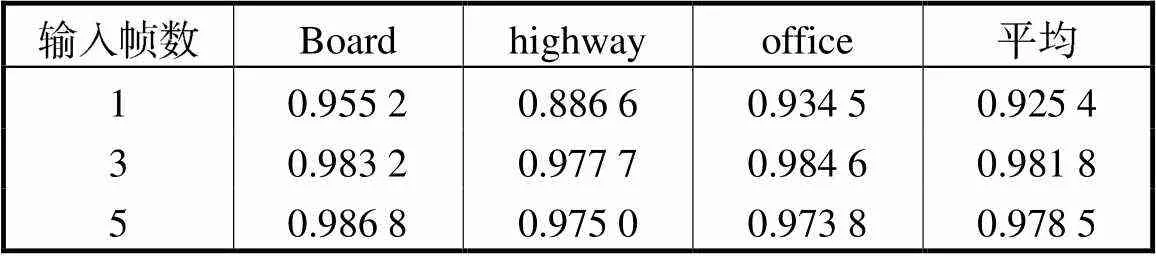
Tab.2 F-measure comparison on different inputs for foreground detection
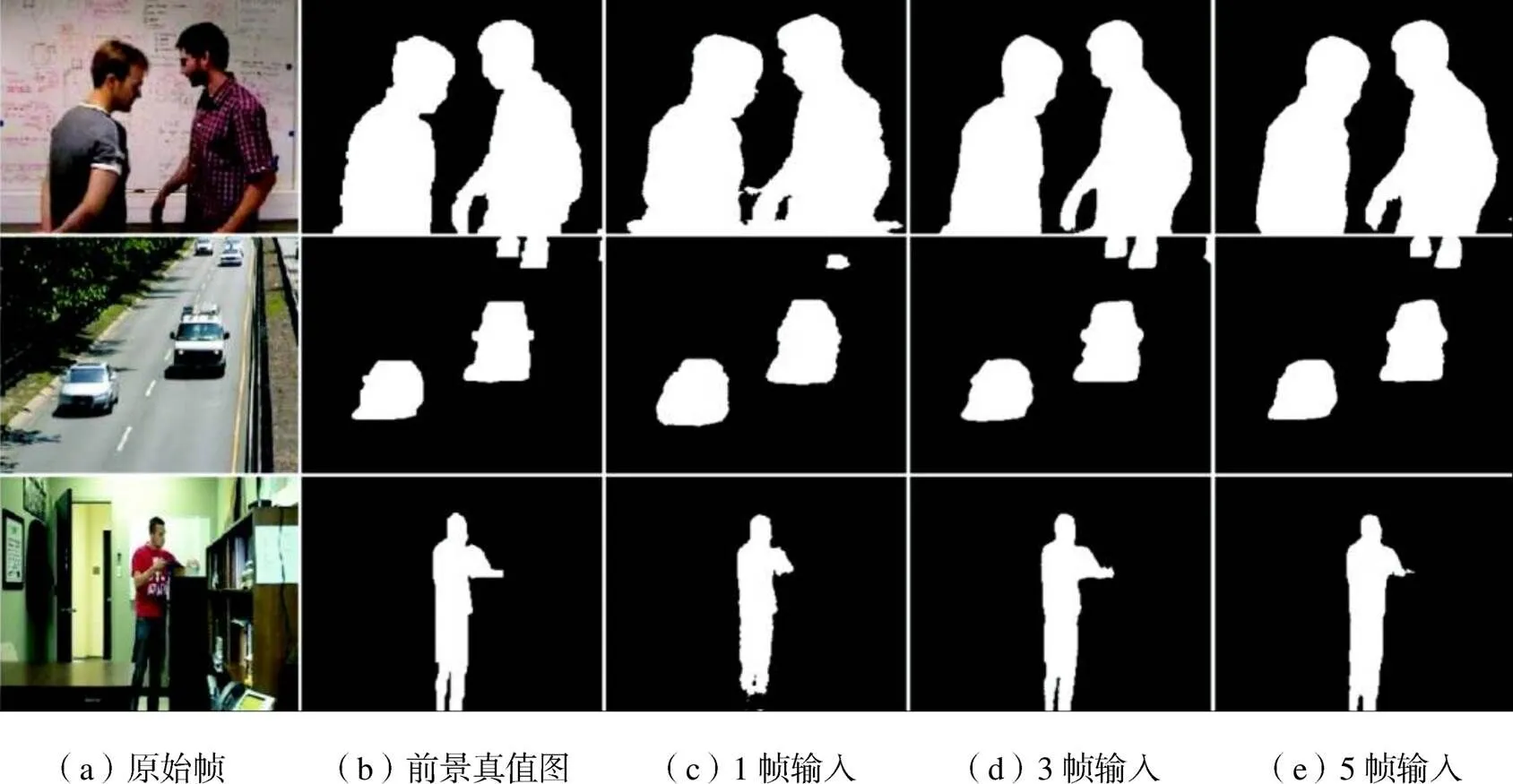
图3 不同输入下前景检测视觉质量结果
通过以上的对比实验证明了所提方法的有效性,但在一些情况下也存在一些局限性.例如当视频中存在伪装物,即前景物体在视频中静止了一段时间,那么该前景物体在一些连续的视频帧中始终处在同一位置,这时网络输入3个视频帧与输入1个视频帧的效果是一样的.另外网络对视频的时间信息的利用还不够充分,在视频帧输入到网络中后,时间信息在第1个卷积层后就消失了.针对这个问题,笔者将在日后的工作中努力克服改进,通过3D卷积神经网络探求更加丰富的时间信息.
2.4 不同方法的运动目标检测效果对比
光流法也常常被用作运动物体的检测,光流是一种反映空间运动物体在成像平面上的像素运动的方法[18].传统的光流算法是利用图像序列中像素在时域上的变化以及相邻帧之间的相关性来找到两帧之间存在的对应关系,从而计算出物体的运动信息.光流图是一种两通道的特殊运动场,其中一个通道能够反映图像像素的水平运动场,另一个通道反映垂直运动场.但是,光流法通常具有较强的约束条件,需要假设参与运算的两帧之间的亮度恒定,且物体的运动比较微小.在实际情况下,受到运动模糊、图像分辨率不足等各种因素的影响,通过光流法检测出的运动物体往往是不精确的.如图4所示,光流图只能大致检测出视频帧中的运动区域,其轮廓是粗糙的,而通过本文所提方法得到的前景图则更加准确.本文引入光流图作为网络输入,目的是强化网络的注意力机制,使前景检测子网络更加关注运动物体.

图4 光流图与前景图对比
2.5 背景重建实验结果分析
图5显示了本文所提方法与其他5种方法(RPCA[6]、TVRPCA[8]、DECOLOR[7]、ORPCA[19]和OMoGMF[20])的视觉质量对比结果,使用了5个具有挑战性的视频序列:办公室(office)、沙发(sofa)和公交车站(bus station).由于前文提到的深度学习方法(CascadeCNN[15]和CL_VID[17])没有进行背景重建实验,本文选取了另外两种传统算法(ORPCA[19]和OMoGMF[20])进行对比.如图5中红框框出的局部图所示,其他方法的结果均出现了严重的噪声,这是由于前背景分离不准确,导致前景像素泄漏到了背景图中.而本文所提算法可以重建出令人满意的背景图像,没有明显的噪声存在.由于背景重建子网络的性能依赖于前景检测子网络的结果,所以本文方法在背景重建方面的表现出色,同时也可以证明本文所提方法的前景检测结果是准确的.
为了进一步对背景重建结果进行定量比较,本文选取图像处理中使用较为广泛的峰值信噪比(PSNR)和结构相似性(SSIM)作为质量评估指标.从表3中可以看出,在多个场景中,本文所提方法的PSNR和SSIM值普遍高于其他方法,平均PSNR值超过次优方法5.52dB.综合以上对比结果,本方法可以有效地实现前景检测和背景重建.

图5 背景重建结果的视觉质量比较
表3 6种方法的前景检测结果的测度值比较
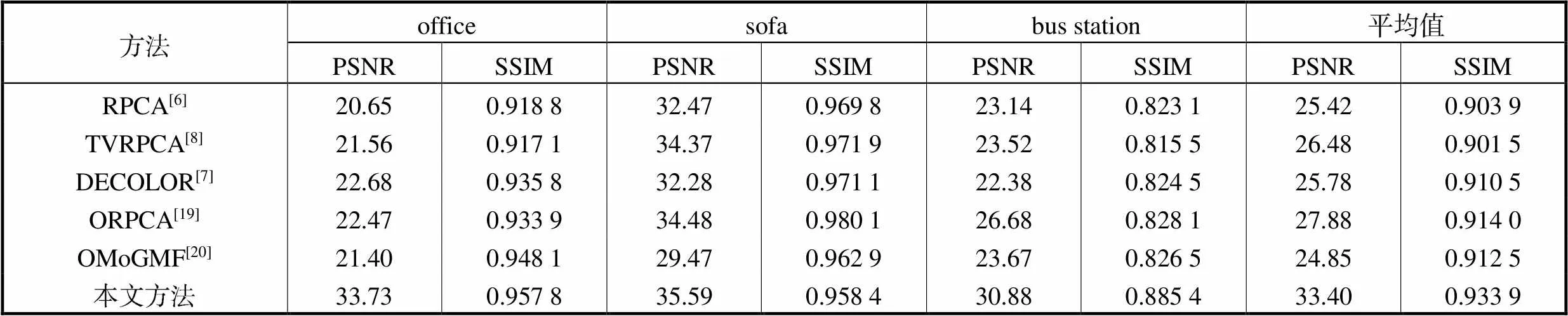
Tab.3 F-measure comparison of six different methods of foreground detection
3 结 语
本文提出了一个用于前背景分离的时空感知的级联卷积神经网络;网络分为两个部分,通过端对端的方式实现;第一级的前景检测子网络能够在一些具有挑战性的场景中准确地检测出移动物体;接着,第二级的背景重建子网络利用一级网络的结果对背景进行高质量重建;最后,通过将两个子网络组合在一起,可获得更准确的前背景分离结果.
在未来的工作中,希望在本文方法的基础上进行扩展,致力于重建纹理更加丰富的背景图,并尝试利用更多的时域信息,借助3D卷积神经网络生成更加准确的前景图.
[1] Klein L,Schlunzen H,von S K. An advanced motion detection algorithm with video quality analysis for video surveillance systems[J]. IEEE Transactions on Circuits and Systems for Video Technology,2011,21(1):1-14.
[2] Yilmaz A,Javed O,Shah M. Object tracking:A survey[J]. Acm Computing Surveys,2006,38(4):13-13.
[3] Tsaig Y. Automatic segmentation of moving objects in video sequences[J]. IEEE Transactions on Circuits and Systems for Video Technology,2002,12(7):597- 612.
[4] Zivkovic Z. Improved adaptive gaussian mixture model for background subtraction[C]// Proceedings of the 17th International Conference on Pattern Recognition. Cambridge,UK,2004:28-31.
[5] Elgammal A,Harwood D,Davis L. Non-parametric model for background subtraction[C]//European Conference on Computer Vision. Heidelberg,Berlin,2000:751-767.
[6] Candès E J,Li X,Ma Y,et al. Robust principal component analysis?[J] Journal of the ACM,2011,58(3):1-37.
[7] Zhou X,Yang C,Yu W. Moving object detection by detecting contiguous outliers in the low-rank representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(3):597-610.
[8] Cao X,Yang L,Guo X. Total variation regularized RPCA for irregularly moving object detection under dynamic background[J]. IEEE Transactions Cybernetics,2016,46(4):1014-1027.
[9] Xu Z,Chen Y,Ming T,et al. Joint background reconstruction and foreground segmentation via a two-stage convolutional neural network[C]//IEEE International Conference on Multimedia and Expo. Ypsilanti,Michigan,USA,2017:343-348.
[10] Lim L A,Keles H. Foreground segmentation using a triplet convolutional neural network for multiscale feature encoding[J]. Pattern Recognition Letters,2018,112:256-262.
[11] Simonyan K,Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL]. http://arxiv.org/abs/1801.02225,2014-01-07.
[12] He K,Zhang X,Ren S,et al. Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:770-778.
[13] Goyette N,Jodoin P M,Porikli F,et al. Changedetection. net:A new change detection benchmark dataset[C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Providence Rhode Island,USA,2012:1-8.
[14] Chen Y,Wang J,Lu H. Learning sharable models for robust background subtraction[C]// IEEE International Conference on Multimedia and Expo. Providence Rhode Island,USA,2015:1-6.
[15] Wang Y,Luo Z,Jodoin P M. Interactive deep learning method for segmenting moving objects[J]. Pattern Recognition Letters,2017,96:66-75.
[16] Babaee M,Dinh D T,Rigoll G. A deep convolutional neural network for video sequence background subtraction[J]. Pattern Recognition,2018,76:635-649.
[17] López-Rubio E,Molina-Cabello M A,Luque-Baena R M,et al. Foreground detection by competitive learning for varying input distributions[J]. International Journal of Neural Systems,2018,28(5):1750056.
[18] 袁 猛. 基于变分理论的光流计算技术研究[D]. 南昌:南昌航空大学信息工程学院,2010.
Yuan Meng. A Study of Optical Flow Computation Technology Based on Variational Theory[D]. Nanchang:School of Measuring and Optical Engineering,Nanchang Hangkong University,2010(in Chinese).
[19] Feng J,Xu H,Yan S. Online robust PCA via stochastic optimization[C]//Advances in Neural Information Processing Systems. Lake Tahoe,USA,2013:404-412.
[20] Yong H,Meng D,Zuo W,et al,Robust online matrix factorization for dynamic background subtraction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,40(7):1726-1740.
Fusing Spatiotemporal Clues with Cascading Neural Networks for Foreground-Background Separation
Yang Jingyu1,Shi Wen1,Li Kun2,Song Xiaolin1,Yue Huanjing1
(1. School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China;2. School of Computer Science and Technology,Tianjin University,Tianjin 300350,China)
Separation of foreground and background in video clips presented various problems,such as foreground leakage.To solve these problems,this paper proposed an end-to-end cascading deep convolutional neural network,which can accurately separate foreground and background in video clips.The proposed method included foreground detection and background reconstruction sub-network,and they were cascaded.The first network fused time and space information,and its input consisted of two parts:the first part included three consecutive RGB video frames,the previous,current and next frames;the second part included three optical flow maps corresponding to RGB video frames.These two inputs were combined by the first sub-network in order to detect moving objects and generate a binary foreground mask.The foreground detection sub-network was a multi-input encoder-decoder network:the encoder was the first five convolution blocks of VGG16 to extract the feature maps of two inputs.These two types of feature maps were fused after each convolution layer.The decoder consisted of five transpose convolution layers that could generate a binary mask for the current frame through learning a projection from the feature space to the image space.The background reconstruction sub-network contained three parts:the encoder,the transmitter and the decoder,which took the generated mask and the current frame to reconstruct the background pixels occluded by the foreground.Experimental results showed that the proposed spatiotemporal fused cascade convolutional neural network has achieved better performance on the public dataset than other methods and can handle various complex scenarios.Foreground detection and background reconstruction results greatly outperformed the existing state-of-the-art methods.
background reconstruction;moving objects detection;convolutional neural network;optical flow
TP391
A
0493-2137(2020)06-0633-08
10.11784/tdxbz201905029
2019-05-09;
2019-07-28.
杨敬钰(1982— ),男,博士,教授,yjy@tju.edu.cn.
师 雯,wenshi@tju.edu.cn.
国家自然科学基金资助项目(61571322,61771339,61672378);天津市科学技术计划资助项目(17ZXRGGX00160,18JCYBJC19200).
Supported bythe National Natural Science Foundation of China(No.61571322,No.61771339,No.61672378);Tianjin Science and Technology Program(No.17ZXRGGX00160,No.18JCYBJC19200).
(责任编辑:王晓燕)
