基于语义分析的政策法规智能审核研究与实现*
2020-04-25衡宇峰彭望龙黄元稳房冬丽
衡宇峰,李 俊,彭望龙,黄元稳,房冬丽
(1.中国电子科技网络信息安全有限公司,四川 成都 610000;2.中国电子科技集团公司第三十研究所,四川 成都 610000)
0 引 言
随着计算机技术应用领域的不断增大,人们对其要求越来越高,不仅要求处理的准确性,而且要求处理的速度。现今最热门的计算机技术莫过于人工智能领域技术,其中自然语言处理(Natural Language Processing,NLP)及机器学习技术处于发展浪潮的最前沿,近年来在各个领域呈现爆发式进展,其研究成果应用也涉及各行各业。当然,无论是机器自动翻译、机器对话、文本智能检索还是查重系统等应用,最基础、最核心的思想是通过充足的语料数据对文本进行语义分析。
文本语义分析包括对文本相似度、不一致及冲突内容分析,现今对文本相似度算法的研究已经具备初步成果。徐浩广、王宁等人在语义信息层面和统计信息层面相似度算法基础上,提出一种综合相似度计算算法[1];晋耀红在语境框架基础上,设计实现文本相似度算法[2];Mahmood 通过归纳总结大量相关研究算法发现,字符串匹配算法是相似度算法中的一种底层实现算法[3];黄文彬、车尚锟将文本相似度算法分为基于无语义信息、基于浅层语义信息、基于深层语义信息3 个大类,以此区分不同的计算需求与应用场景的差异[4];贾惠娟提出了一种结合编辑距离、改进的空间向量模型、特征词库的文本相似度算法模型,提高了相似政务文本检测的效果和性能[5]。
目前,对于文本语义分析中不一致、冲突内容识别的研究仍然处于萌芽发展阶段,一直是当今学者研究的热点与难点。由于中文表述复杂,同一个词在不同语境下会表达出不同的语义,不同的语义之间差别巨大,且具有否定词的存在,导致文本语义不一致、冲突对比难度巨大。目前,主要是利用规则制定、知识推理的方式判断。本文基于文本语义分析,针对政策法规提出一种文本智能审核方法,并通过实验证明了此方法的正确性和有效性。
1 智能审核算法原理与流程
政策法规文本智能审核包括对法规相似度、不一致以及冲突内容的审核。由于法规内容描述一般用语规范、具有一定规律,且组成是结构化或半结构化,当出现法规语义不一致或者冲突描述时,两个法规往往具有较高的相似度。因此,本次研究所采用的智能审核算法是在法规语义相似度较高的基础上进行政策法规规则库的匹配,以此来判断政策法规的相似项、冲突项和不一致项。
1.1 政策法规语义相似度计算
语义相似度指的是文本在中文语境下语义之间的相似或者匹配程度的参数,其计算结果一般位于[0,1]区间。值越接近于1,两个文本越相似;反之,越不相似。在自然语言处理技术应用领域广泛的21世纪,相似度算法常被用于机器翻译、智能查询、机器自动问答等方面,其计算的准确性直接影响机器处理的结果。目前,对于文本相似度算法,国内外学者已有诸多研究,如表1 所示。

表1 文本相似度算法
本次研究首先选择目前计算文本相似度的常用算法,即基于向量空间模型的算法。词向量是将语言中的词语转换为数学化的一种方式[8],可以用来表征一个词语,并且经过多次试验表明,将词语转化到多维向量空间后,两个向量之间的余弦距离可以表示两个词语之间的语义相似度,公式化表达如下:

式中,A 和B 表示对比的两个词的向量,SimScore(A,B)表示两个词的相似度,Ai表示向量A的分量,Bi表示向量B 的分量,n 表示词向量的维度,一般取200 维。
前人训练的词向量模型所用语料大多来源于百度百科、维基百科、人民日报等互联网词库,涵盖各个领域,但并不适用于政策法规单一领域,故本次研究选用Word2Vec 模型训练工具针对政策法规领域文档进行训练。
根据得到的词向量模型进行文本相似度的计算。首先,利用Ansj 中文分词工具对法条进行分词,并且对每个词语进行权重标记。其次,处理法条中的重点词汇,排除无关停用词,如“你”“我”“的”等词汇。根据处理结果,最终相似度值计算步骤如下。
(1)输入分词后的法条A 与法条B,计算A句中第1 个词在B 句中最大的相似值(利用词向量余弦距离计算),再依次计算第2 个,第3 个,……,累加取算术平均值作为A →B 的单向匹配;
(2)反向依次计算B 句中词在A 句中最大的相似值,累加取算术平均值作为B →A 的单向匹配;
(3)最后取双向匹配的算术平均值作为法条A 与法条B 的法条相似度,相似度位于[0,1],具体计算公式为:
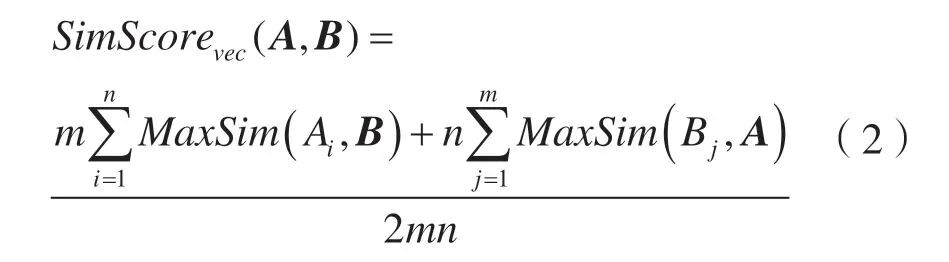
式中,SimScorevec(A,B)表示语句A、B 之间的相似度,n 表示语句A 的词语数量,m 表示语句B的词语数量,MaxSim(Ai,B)表示语句A 中第i 个词语在B 句中最大的相似值,MaxSim(Bj,A)表示语句B 中第j 个词语在A 句中最大的相似值。
经过实验证明,以上基于词向量的文本相似度计算不足之处在于并没有考虑句子中词与词的关系,而在中文语法中,句子的句法结构信息对最终的含义影响巨大,所以仅仅选用词向量的计算方式并不能有效表征文本的相似度值。因此,本次研究在Word2Vec 模型计算词语的相似度基础上,使用句法分析工具(HanLp 工具)对语句组成元素进行依存关系分析(Dependency Parsing)[9],进而确定语句的核心关键词语,将句子结构信息添加到计算中。
利用依存结构对中文语句进行相似度计算,步骤如下:
(1)对语句A、B 进行句法结构分析,分析结果parA、parB;
(2)取parA、parB 中的关系对,保存为三元组depA、depB,dep[0]、dep[2]为依存词语,dep[1]为依存关系;
(3)将语句A、B 依存结构集合SetA、SetB,具有相同依存关系的依存对词语分别计算词向量相似度,取算术平均值,最终把相似度最大的一组作为依存对的相似度;
(4)将符合条件的依存对进行相似度计算,并乘以依存关系权重,累加得出两个语句相似度值,具体计算公式为:
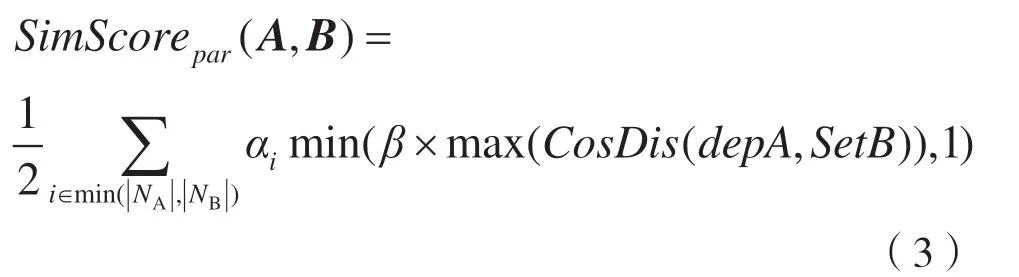
式中,NA表示语句A 中依存对数,NB表示语句B 中依存对数,α 表示依存关系权重,β 表示放大系数,SimScorepar(A,B)表示语句A、B 之间的相似度。
当然,单纯使用句子中出现词语的向量和句法分析进行文本相似度计算虽然简单,但缺点也比较明显,如词序考虑不全、词向量的区别不明确,因此本次研究继续使用长短期记忆人工神经网络(Long Short Term Memory networks,LSTM)模型训练对句子进行重新表示,并计算相似度。
LSTM 神经单元可以长期保存输入,可以用来解决传统的RNN 神经网络训练中经常出现的梯度消失问题,其构造的神经网络模型也被证明比传统的RNN 模型更加有效[10]。LSTM 模型是通过扩展时间维深度来达到保存时序信息的目的,即可以将中文语句中词语出现的先后顺序信息反映到模型计算中。本次研究参考文献[11]方法并加之改进,在进行一定量的数据标注后,构造垂直领域政策法规的LSTM 文本相似度计算模型,如图1 所示。它的训练语料是经过人工标注过相似标签,相似度在[0,1]之间的训练集对(xa,xb,y),训练得到可以计算相似度得分的神经网络模型。其中xa、xb为语句的分词结果向量表示,y 为相似度值。
综上所述,单一的文本相似度的算法都只能表现文本的某一部分特征,并不能真实反映文本语义相似度。因此,本次研究综合上述实验的词向量、依存句法分析和LSTM 模型相似度算法,最终确定本文结合多特征融合的相似度算法公式为:
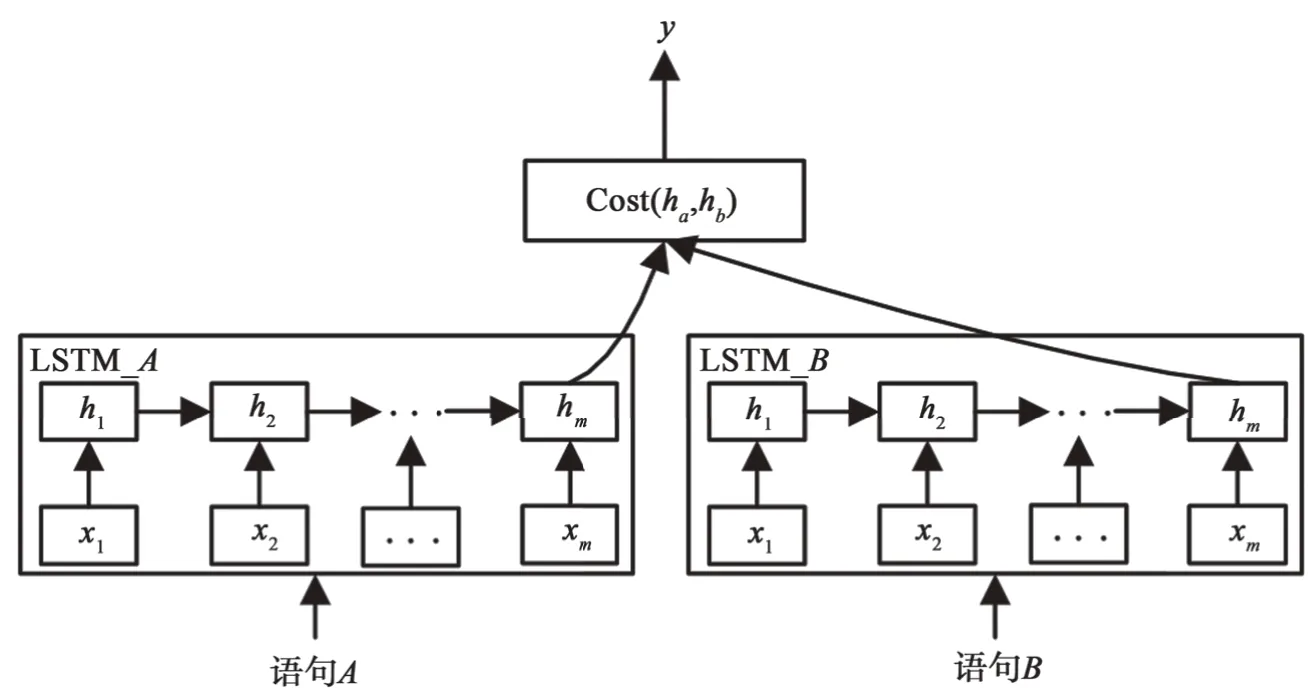
图1 LSTM 语句相似度模型

其中:δ1+δ2+δ3=1,δ1、δ2、δ3位于(0,1)区间。
1.2 政策法规规则库制定
对政策法规语料进行人工标注后,总结归纳冲突项、不一致项规则,形成政策法规规则库。大致可以分为数值冲突(日期、年龄大小等)、专有名称冲突、符号(书名号、顿号等)内容描述不一致等(表2),匹配规则检测步骤如下:
(1)当两个法条相似度大于阈值时(根据多次试验,阈值取0.85)进行冲突项计算,否则计算下一组法条相似度;
(2)匹配规则,利用正则表达式截取冲突关键词语,判断截取的关键词是否一致或相似度很大,当两个法条关键词不一致时疑似冲突项,反之不是冲突项;
(3)对检测出来的冲突项分类保存。

表2 政策法规规则示例
1.3 政策法规智能审核流程
根据训练得出的词向量模型、LSTM 模型结合规则库对政策法规文本进行智能审核。对政策法规进行法条划分,对划分好的法条分词后分别进行词向量相似度计算、依存句法相似度计算、LSTM 模型相似度计算,综合得出法条之间的相似度值。当大于阈值时进行规则库的规则匹配,判断法条语义是否冲突,将符合要求的结果保存,整体流程如图2 所示。
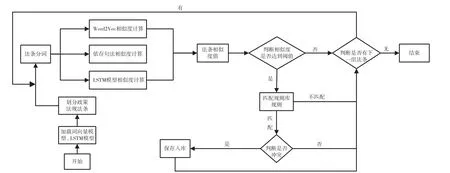
图2 政策法规智能审核程序流程
2 实验例证及分析
2.1 实验测试语料
本次研究所用于训练的政策法规语料56 347篇,涉及国防、民政、军事、外交等多个领域,利用人工标注方式构建相似语句对15 646 条,作为神经网络LSTM 模型训练语料,冲突、不一致语句对12 528 条,作为规则库制定语料,对结果测试语料共计35 289 条。
2.2 实验结果及分析
本次研究首先根据语料进行相似度模型的训练,词向量训练使用Word2Vec 工具,LSTM 模型训练使用TensorFlow 平台,随后根据人工标注方式总结归纳不一致、冲突法条规则形成规则库。
对试验结果采取两个评价指标:
(1)准确率:对比正确数与样本总数比值;
(2)召回率:对比正确数与样本总正确数比值。
实验中,取相似度阈值为0.85,放大系数取值为1.5,通过调整相似度算法参数δ1、δ2、δ3的值,不断优化比对效果,实验结果如表3 所示。
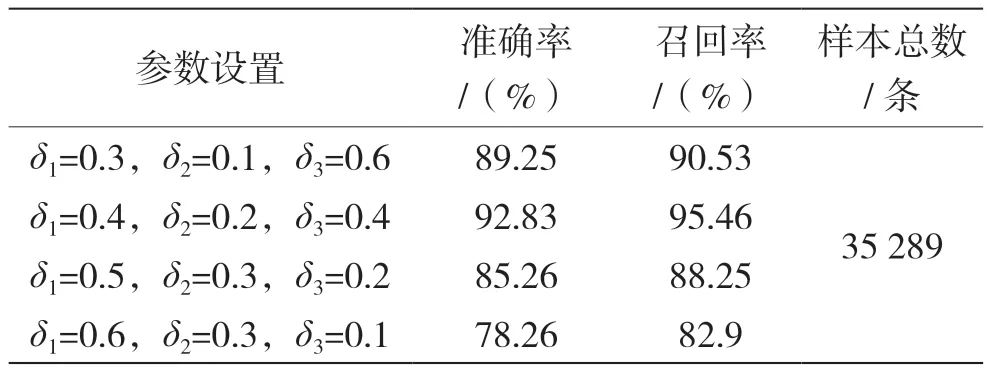
表3 不同参数设置的实验结果
从表3 可知,当δ1=0.4,δ2=0.2,δ3=0.4 时,效果表现最好,所以选定δ1=0.4,δ2=0.2,δ3=0.4 作为本文相似度算法的最终参数,应用到本系统中进行政策法规的智能审核。
采用真实政策法规文本进行测试,效果如图3 ~图5 所示。可见,应用此方法对政策法规进行智能审核准确度较高。

图3 法条年龄数值描述冲突

图4 法条专有名称描述冲突

图5 法条符号内容描述不一致
3 结 语
本文分析了现有文本相似度计算方法,最终选择综合词向量、依存句法分析、深度神经网络LSTM 模型3 种算法的多特征融合算法,并结合政策法规规则库进行政策法规智能审核对比。通过实验测试结果证明,本文利用相似度算法结合规则库的方式进行文本语义对比是一种行之有效的方法,基本可以满足特定领域文本语义对比检测的工程化实施。
目前,总结的政策法规规则并不能囊括全部领域,但是所采用的原理不仅仅局限于政策法规,还可以扩展到其他领域,如经济、文学领域等。随着人工智能技术的不断发展,后续结合知识图谱技术构建知识体系进行知识推理,可以不断完善文本语义对比的设计与实施。
