基于社区划分的节点重要性评估方法
2020-04-24顾益军
王 安,顾益军
中国人民公安大学 信息技术与网络安全学院,北京102600
1 引言
随着复杂系统科学的研究与发展,同时受到信息技术的推动作用,人们发现了现实世界中的许多具备关系的事物或以复杂网络的形式存在、或能被转化成复杂网络。复杂网络的节点在结构和功能上承担着不同作用。复杂网络中节点重要性排序问题也吸引了越来越多的科研人员的关注。复杂网络节点重要性排序问题应用较为广泛,在特定群体内找出关键人物,进行社交推荐,甚至对一篇文章进行关键词抽取等等都或多或少涉及到节点重要性的排序。因此,对复杂网络的重要节点进行排序非常重要。
复杂网络的节点重要排序已有若干经典的算法[1-2],如复杂网络的度中心性、接近中心性、介数中心性[3-4]、PageRank[5-6]、K-shell[7]等方法。这些方法从不同角度测定了节点的重要程度。
近年来相关研究与改进有以下几类:
(1)发掘网络中新的特征
韩忠明等人[8]采用关注节点间的三角形结构,同时考虑了周边邻居节点规模方法评估节点的重要性。顾亦然等人[9]利用节点间的相似度来评估节点间的相互关系,进而得到节点的重要性表示。马润年等人[10]结合信息论的知识以节点所包含的信息量来评估节点的重要性。发掘新特征的方法还有很多,这些方法的优点是对节点的不同特征进行了探究,以新的特征作为节点重要性排序的依据。然而这样的方法或许过于关注这些单个特征,在全面性上有一定的不足。
(2)对已有方法进行结合
于会等人[11]利用TOPSIS决策方法,融合多个指标,对节点的重要性进行综合计算。Bian 等人[12]利用证据理论将多种中心性方法进行结合,有效地结合了多种算法的优点。将多种方法进行结合的方式本质上是对已有的方法进行加权,考虑得更加全面,但是如果扩充的方法过多,或者其中一些方法的排序结果存在较大的冲突,便不能很好地平衡各个算法的权重,算法的复杂度也较高,不适合于规模较大的网络。
(3)对已有方法进行改进
现有算法或多或少都存在一定的局限性,作为复杂网络节点重要性排序最经典的算法——PageRank 备受国内外研究人员的关注。Lü 等人[6]在PageRank 算法的基础之上增加了背景节点,形成了比PageRank 收敛更加迅速,抗干扰能力更强的LeaderRank算法。
以上各方法得到的重要节点都较为集中,忽略了复杂网络重要节点集合的整体的传播影响力。同时部分算法也存在时间复杂度过大的问题,无法在大规模网络上进行应用。
在复杂网络分析中,网络中的某些节点倾向于形成一些紧密联系的小团体,即这些网络呈现了一定的社区结构特征,社区内的节点相比于社区外部的节点具有更强的相互作用[13],联系更加紧密。
社区发现有助于解决其他的复杂网络问题[14],Hu Qingcheng 等人[15]结合FN 算法对K-shell 进行了改进,解决了K-shell精度低的问题。Sheikhahmadi A等人[16]应用社区发现将用户之间的交互量作为权重,提高了在线社交网络的用户影响力识别效果。付立东等人[17]以模块密度函数来度量节点对不同社团的贡献度,对社团的贡献越大,该节点的重要性越高,然而这样的方法与K-shell类似,很多节点具有同样的重要度,差异程度较低。本文尝试从复杂网络的社区结构出发,同时考虑节点所属社区,社区间的连接关系,以及某一节点在所属社区内部的重要性,量化某一节点在整个复杂网络重要性。这种融合社区划分的节点重要性评估方法相对于其他一些方法更加准确。
2 PageRank算法
PageRank 是一种评估某一页面质量的算法,可以认为其是一种概率表示。PageRank 算法的主要思想如下:若某一网页被链入的数目越高,那么这个页面的重要性就越高;而链接到该网页的页面质量越高,则该页面的重要性同样就越高。PageRank 方法可应用至任何具备相互引用特性的实体集。在复杂网络中可以使用它对节点的重要性进行排序。该算法计算公式如下:
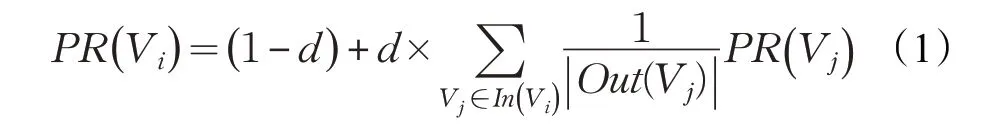
其中,PR(Vi)为待评价节点Vi的PageRank 值;d 为阻尼因子,1-d 可以理解为随机跳转到其他节点的概率,一般取d=0.85;In(Vi)表示指向节点Vi的所有节点的集合;Out(Vj)表示节点vj所有指向节点的集合。在复杂网络中,PageRank的策略是:某一个节点的邻节点越重要,则这个节点越重要。
3 LPA算法
标签传播算法LPA[18-19]的思想十分简单,与社区划分中模块度优化有关算法不同,LPA算法不需要设定目标函数,它是一种基于已有节点的社区标签信息来判定尚未标记节点的社区标签所属,通过不断地迭代计算,最终使得每个节点和其多数相邻节点所属同一个社区。
LPA算法的具体步骤为:
(1)初始化标签分配,令每个节点随机被分配唯一的社区所属标签;

(2)更新节点的社区所属标签,令其社区所属和其多数相邻节点的社区所属相同,如果具有多个同样数量的社区所属,则对其进行随机选择。
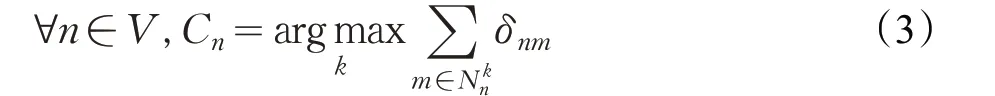
其中,Cn为社区所属标签,Nkn表示节点n 的邻居中标签为k 的所有节点构成的集合,δ 表示节点n,m 的连边权重。
(3)重复步骤(1)、(2)直到所有节点的社区所属不再发生变化。
Papadopoulos等人[20]通过大量的实验比较了现有社区发现算法的时空间复杂度以及应用社区规模大小,发现标签传播算法的时间复杂度为O(n)。相比于以优化模块度Q 为代表的优化特定函数的方式进行社区划分,标签传播算法无论是空间复杂度还是时间复杂度都不高。标签传播算法具备少量迭代计算后即可收敛、易于实现等优点。这些优点使得标签传播算法对于解决大规模网络社区发现问题有着较好的效果。
4 引入社区划分的CD-PR算法
4.1 CD-PR算法流程
按照PageRank 算法的排序过程,若某一个节点最终的PR 值越大,那么一切连接到该节点的其余节点最终的PR 值同样也会很大,同时,如果网络较大,每个节点所能分配的Rank 值会较小,这会导致使用PageRank方法进行节点重要性排序的结果较为集中。可以将PageRank 的这种特性称之为重要节点聚集效应。然而,在一些领域的研究,例如传销打击问题、犯罪团伙分析中,更加倾向于找出小团体的核心。这使得PageRank在这一问题上存在一些局限性。
基于上述想法,本文提出一种引入社区划分的节点重要性排序改进方法CD-PR(Community Detection based PageRank)。算法总体分为以下流程:预先将网络进行社区划分,将网络裁剪为多个子网络。把社区划分与选择看作是概率,在每个小的社区中分别进行PageRank排序,最后进行归一化处理,得到节点的综合排序结果。
具体而言,CD-PR算法的流程有以下步骤:
(1)对待节点排序的复杂网络进行社区划分
利用前文提到的LPA 算法对复杂网络进行社区划分,迭代至具备稳定的非重叠社区划分结果后,将复杂网络分割为若干子网络,即G={G1,G2,…,Gn},其中子图Gi=(Vi,Ei)为社区集,n 为社区数量,它们满足以下条件:
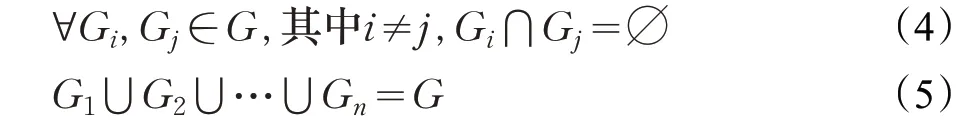
(2)求取各节点在各自社区内的PageRank值
利用PageRank算法分别计算每个子图的每一节点的PageRank值。

实际上由于图G(V,E)被分割为多个独立的子图G={G1,G2,…,Gn},这使得每一个社区子图的PageRank值计算都是相对独立的。在实际进行计算时可以将计算PageRank 的任务采用并行计算的方式,分摊到多个线程上并同时进行计算,提高迭代收敛的速度。
(3)对复杂网络G=(V,E)构造超节点聚合邻接矩阵
将同一社区的节点聚合为一个超节点,使每一社区Cn对应超节点sn,构造超节点聚合邻接矩阵S,S 的元素Sij表示超节点连边的权重,即Sij为连接社区i 到社区j 所有的节点对的边权重之和,由于G=(V,E)为非带权图,所以超节点聚合邻接矩阵连边的权重Sij便是两个社区的连边总数。
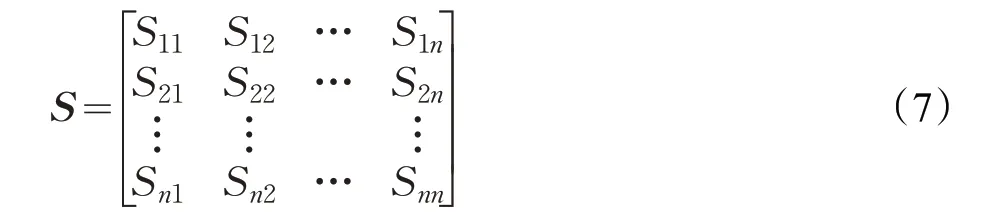

其中Tij为社区i 与社区j 的连边总数。当i=j 时为同一个社区,所以此时
(4)计算社区结构系数
受节点互信息[10]的启发,本文在衡量社区对节点重要性的影响时,主要关注了社区内的连边结构特征,被划分社区的内部连边数量与社区间的连边的数量可以表示消息在社区内外流转传播的情况,如果内部连边数量较多,则消息倾向于在社区内部传播,若与其他社区的连边数量较多,则消息倾向于向其他社区进行传播,因此本文将社区内部与社区间的连接情况看作是社区结构系数,具体计算方式由可以参照以下步骤:
记Knin为社区Cn内部度之和,Knout为社区Cn外部度之和,公式(9)(10)分别计算了社区内外度之和:

其中Aij为图G(V,E)邻接矩阵的元素,表示节点i 和节点j 之间连边的权重。对上述公式化简,则它们对于超节点聚合邻接矩阵S 有:

分别计算社区Cn的内部度和外部度,计算社区结构系数向量I=(I(1),I(2),…,I(n))T,其中每一分量I(n)为各个社区Cn社区结构系数,可按照公式(13)进行计算:
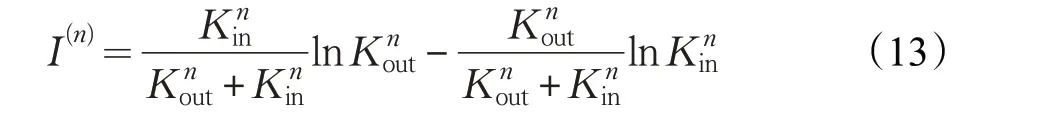
由于向量I 是由一个社区的内外连边数量计算得到,所以向量I 可以表示一个社区内部连接和外部连接的紧密程度,衡量消息在社区内外的流转情况,从而衡量某一社区的连通情况。社区的内外连接情况都会影响一个社区的传播能力。因此用这样的社区结构系数便可以衡量一个社区在复杂网络中的地位。
(5)对社区结构系数进行归一化
在步骤(4)中得到了表示每个社区内外连接情况的结构系数,然而,社区结构系数的取值存在接近零的情况,同时各个系数总和不为1,这会导致无法从各个社区分别抽取相应数量的候选节点。因此需要将社区结构系数进行归一化。
对于这样的问题,在归一化处理时应用归一化指数函数SOFTMAX是最为合适的,SOFTMAX可以将任意实数值映射到(0,1)的区间,使其和为1,方便从各个社区抽取相应比例的重要节点。

其中,N 为社区数量,z 为n 维向量。 I͂为社区选择概率向量,每一分量为社区Cn的社区选择概率。
图1 展示了社区内外连接情况转化为概率表示的过程,在使用SOFTMAX 函数后,社区的内外连接情况便转化为概率的表示,从而可以按照社区选择概率分别贡献出相应比例的候选节点,使得重要节点的获取更加分散。这种方式得到的重要节点更利于复杂网络中信息的传播。
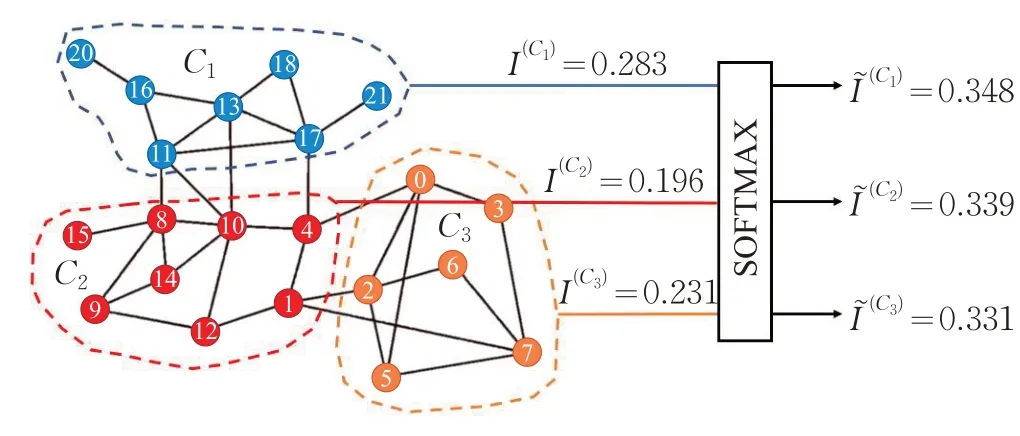
图1 社区选择概率向量计算示意图
(6)各社区分别贡献相应比例的候选节点
根据排序节点总数在各自社区内利用PR抽取到相应比例的节点数量。每一社区按照公式(16)分别抽取相应数量的节点,组成候选节点集。

(7)重新将节点进行排序,得到最终结果
将候选节点集利用公式计算综合Rank值后再进行排序:
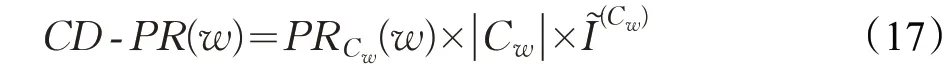
其中,PRCw(w)为节点w 在其社区Cw内的PageRank值, ||Cw为w 所在社区规模,这里指社区内节点的数量,为节点所在社区Cw对应的社区选择概率向量的分量。
通过以上步骤便可以到Top-K 个重要节点的排序。
4.2 时间复杂度分析
令复杂网络G(V,E)的节点数为n,连边数为m 。划分平均社区数为k,每个社区平均所具有的节点数记为n′,每个社区平均所具有的内部连边数记为m′。
CD-PR 首先通过标签传播算法得到网络的社区划分,此时所产生的时间复杂度为O(n),随后分别计算每个社区内每个节点的PageRank 值,这一阶段需要的时间复杂度为O(km′l),其中l 是平均迭代次数。而计算社区选择概率,贡献相应比例的候选节点,以及对结果的重新排序相比于计算PageRank 来说都是极小的数,因此可以忽略不计,所以最终CD-PR 算法的时间复杂度为O(n+km′l)。
5 实验及分析
考虑到不同网络具有不同结构与特征,为了评估算法的有效性,本文采用多种方式对不同网络进行仿真实验,所实验网络均为开源数据,统计数据如表1所示。
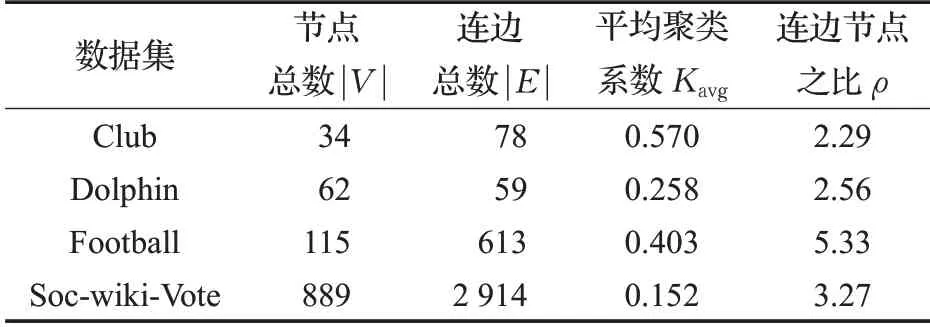
表1 数据集相关统计情况说明
5.1 各方法排序结果对比
本文将CD-PR方法与PageRank方法、基于互信息[10](MI)的方法,以及复杂网络中常用的中心性方法[1]、度中心性(DC)、接近中心性(CC)、介数中心性(BC),分别对Club、Dolphin、Football、Soc-wiki-Vote网络进行对比实验,应用这些算法分别取前10个重要节点,结果如表2(a)与(b)所示。
5.2 调节因子的确定
在对各社区分别贡献相应比例的候选节点的步骤中,为了进一步确定调节因子的取值对重要节点排序影响,本文对调节因子不同取值进行了对比。结果如表3所示。
在使用LPA对网络进行划分时,会产生一些规模较小的社区,而CD-PR 的策略是分别从每个社区抽取一定比例的候选节点,候选节点数目应大于最终需求的数量topk,λ 不宜过小或者过大,因此本文将λ 定为0.5以确保足够数量的候选节点被抽取出。
5.3 排序结果相关性分析
为了进一步评测本文算法和其他算法排序结果的相似程度,本文采用了肯德尔相关系数对相关算法进行两两对比,肯德尔相关系数可以测量两个随机序列的相关性,其值域为-1 到1之间。当τ=1 时,表示两个序列具有完全一致的相关性;当τ=-1 时,表示两个序列拥有完全相反的相关性;当τ=0 时,表示这对序列组是不相关的,而τ ≠0 则可以认为两个序列具有一定的相关性。形成肯德尔相关系数τ 矩阵,这里以Club网络排序结果为例,计算各个方法肯德尔系数,各方法结果序列相关性热力图如图2所示。
图2显示,CD-PR与PageRank的结果具有一定相似性,这是因为本文所提出的CD-PR算法改进自PageRank算法,在PageRank的基础之上加入了社区的约束,存在一定的衍生关系。

表2(a)Club与Dolphin网络各方法排序结果
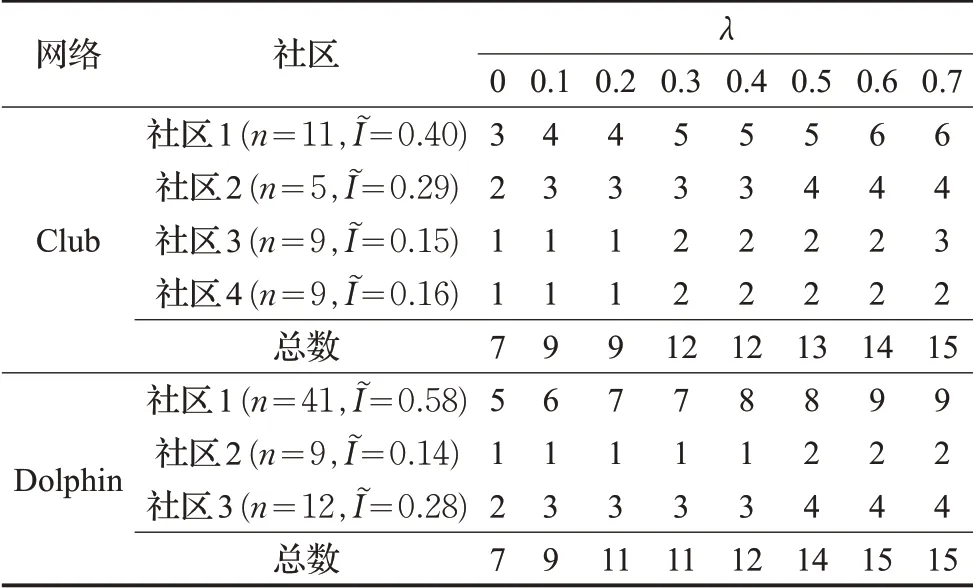
表3 λ=0~0.7,topk=10 时各社区贡献节点数量对比
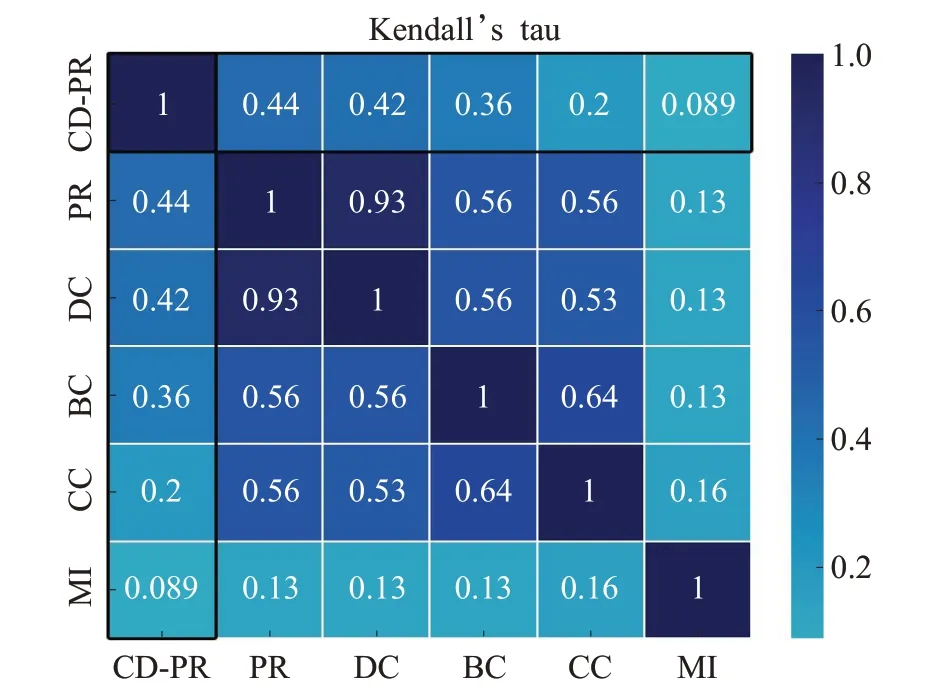
图2 各方法肯德尔相关系数矩阵热力图
5.4 SIR传播性能实验
为了进一步评测CD-PR方法的有效性,比较CD-PR方法与PageRank 方法的差异,本文采用对排序结果的节点做传播性能情况的分析。这里使用SIR 传染病模型进行传播性能的实验。SIR 传染病模型可以有效地对某些节点的传播性能进行评估。本文对不同的复杂网络,分别做单节点与多节点的传播性能实验,选取感染源,以固定概率α 感染传播,而被感染的节点以恢复概率β 还原到未受感染的初始状态;如此下去,当不再有未感染者的时候停止。
具体实验分为以下两个方面:(1)单节点的传播性能实验,即分别选取CD-PR 方法与PageRank 方法首次排序结果出现差异的节点作为感染源,取感染概率α=0.3,恢复概率β=0.000 1,即被感染节点几乎不会恢复。(2)多节点的传播性能实验,即将两种方法挑选出的节点集合都作为感染源,在多节点的传播实验中,取感染概率α=0.2,防止曲线过于陡峭。
表2 给出了CD-PR 与PageRank 方法排序前十名的节点序列。可以看出有着不同的排序结果,本文对两种方法中排序不同的节点的传播影响力进行了比较,结果如图3 到图6 所示,由于SIR 传播实验具有一定的随机性,因此每个结果都进行了多次实验。
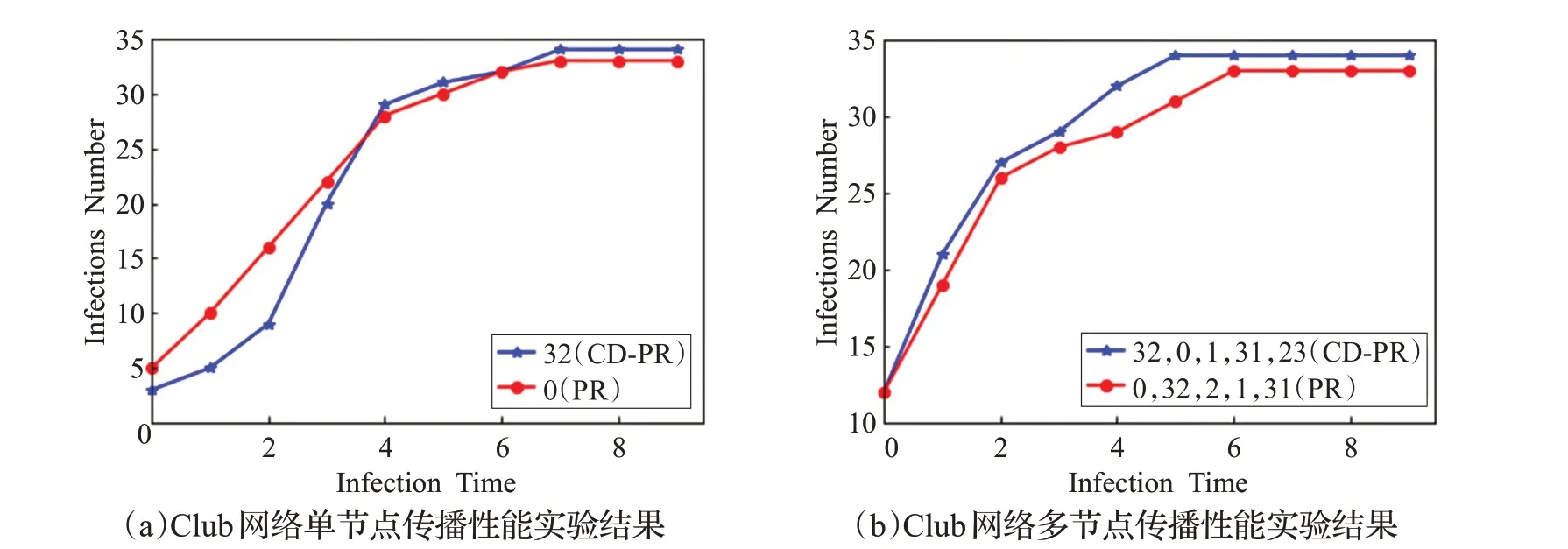
图3 Club网络SIR传播实验结果
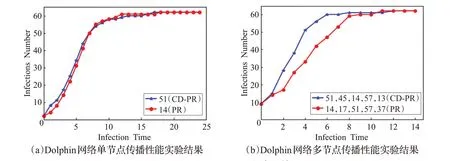
图4 Dolphin网络SIR传播实验结果
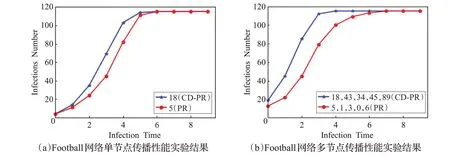
图5 Football网络SIR传播实验结果
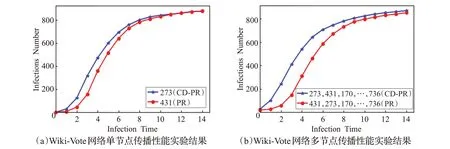
图6 Wiki-Vote网络SIR传播实验结果
单节点传播性能实验结果如图3(a)到图6(a)所示,在Club 网络中,在重要性排第二的节点出现了不同,CD-PR 给出的排序为32 而PageRank 给出的排序为0。对比两者的SIR 传播曲线可以看出在传播前期CD-PR得到的结果比PageRank 略差,而在传播后期则与PageRank相接近。在Dolphin网络上,节点51和节点14排序有差异,使用本文提出的CD-PR 方法给出的排序分别为第一和第三,与PageRank算法相反,这里对它们进行SIR传播性能实验,可以发现本文给出排名第一的节点51 在传播初期略优于节点14,由于网络规模比较小,所以在传播一定轮数之后两者传播性能差异不大。两者的传播性能几乎一致。在Football 网络上,本文CD-PR方法给出的排序与其他方法给出的排序都有较大的差异。可以看出,本文给出的排名第一的节点18在传播性能上略优于PageRank给出的节点5。在实验中,发现排名二三的节点与其他方法给出的节点传播性能差异不大。究其原因,如表1,此网络节点连边之比较高,平均聚类系数也较大,更利于传播,在这样的网络中,各个排名靠前的节点传播性能差异不大。在Wiki-Vote网络上,本文CD-PR 方法与其他方法在节点重要性排首位的节点出现了不同,对比PageRank算法,本文给出的节点273排名第一,而PageRank则认为431排第一。对比其SIR传播性能可以发现,节点273具有更好的传播能力。
多节点传播性能实验结果如图3(b)到图6(b)所示,在进行实验时,Club、Dolphin、Football 网络都取前5 个的感染源,考虑到Wiki-Vote 网络节点数量比较多,这里将排序前10的节点都作为感染源,进行多次实验,测试节点序列整体的传播能力。可以看出本文提出的CD-PR 方法在多个节点同时作为感染源时传播性能在不同网络均优于PageRank 算法。原因在于,本文所提出的方法排序的结果更加倾向于各个社区内部排名较高的节点,同时也关注了多个社区,而PageRank产生部分排名较高的节点会出现在一个社区的内部的结果。导致其社区间的传播影响力较低。
上述实验表明,针对Club、Dolphin、Football、Wiki-Vote 四个规模不一、参数差异较大的实际复杂网络,本文提出的CD-PR方法在单节点和多节点传播影响力上都比PageRank 方法挑选出的节点具有更好的传播性能,特别是规模越大的网络,CD-PR 的多节点传播性能越好,反映了使用CD-PR方法,更加适合于对规模较大的复杂网络进行节点重要性排序,得到的结果在多个节点整体的传播性能要优于PageRank 方法。此外,由于SIR传播性能实验具有一定的随机性,以上实验均为多次实验的平均结果。
6 结束语
本文主要的贡献是在求取节点重要性算法的基础上引入了社区划分的方法,综合考虑节点的社区结构特征和其节点连接特征,提出了一种基于社区划分的节点重要性排序算法CD-PR。本文对多种开源的真实复杂网络进行了节点重要性的排序,利用SIR传播模型对单一节点以及全部节点进行了实验,验证了CD-PR 方法对重要节点排序的有效性。
本文提出的方法还有一定的不足之处。应用的标签传播算法虽然速度较快,但是对社区划分存在一定的随机性,这样的随机性会使节点重要性具有一些不稳定性。今后的工作将包括如何减少不稳定性,更加高效准确地对复杂网络的节点的排序重要性进行排序。
