基于大数据平台的货车位置服务应用研究
2020-04-23梁山清李恩宁葛红志王晓玲
梁山清,李恩宁,葛红志,王晓玲
(中电科卫星导航运营服务有限公司,河北 石家庄 050000)
0 引言
作为世界上最大的互联网市场,我国的大数据发展日异月新。2018年召开的全国网络安全和信息化工作会议,对包括大数据产业在内的信息化发展战略进行了全面部署,举国上下致力于构建以数据为关键要素的数字经济。在智慧交通领域,大数据技术可以改变货运车辆 “信息孤岛”现象严重、缺乏合作交流平台等难题。回顾全国范围内近年的相关研究工作可以发现,伴随着“互联网+物流”的快速发展,相关部门和货运企业正在快速推进传统业务模式向数字化、网络化和智能化转型,加速行业的服务升级[1-3]。但是,在基于货运车辆位置大数据的潜在价值挖掘方面,仍然存在巨大的探索空间。
百万级综合车辆位置服务平台结合北斗/GPS卫星导航定位技术[4-5]、无线通信技术,借助强大的数据存储、融合和分析能力,对各类交通车辆提供综合位置监控管理服务。其中,货运车辆数据是平台上的主要业务数据之一。
本文在本地服务器上搭建开源大数据平台,将综合车辆位置服务平台的货运车辆数据迁移到Hadoop分布式文件系统。然后,运用大数据分析与挖掘算法,对货运车辆数据进行了大数据应用研究,对基于时空特征的K-means聚类算法以及基于专家系统和协同过滤算法的货车未来活动区域预测方法进行设计和应用。
1 基于Hadoop2.x的大数据平台
本文采用Hadoop2.x技术体系[6]进行大数据平台的架构设计[7-9]。货运车辆大数据系统的架构如图1所示。

图1 货运车辆大数据系统架构
由图1可以看出,货运车辆大数据系统包括数据源、数据采集与存储层、大数据分析与挖掘层、数据展示层和大数据管理层共5部分。其中,数据源为存在于关系数据库PostgresSQL中的货运车辆数据;数据采集与存储层将数据源的数据迁移并存储于分布式文件系统HDFS中;数据分析与挖掘层基于YARN计算架构,协同Mahout,Avro,Ooize和Solr等组件,对货运车辆数据进行分析和挖掘;数据展示层对大数据分析结果进行图形化展现;大数据管理层负责整个系统的应用程序协调、数据安全管理和系统运行动态监控等任务。货运车辆大数据系统中各组件的功能如下:
① Sqoop:在结构化数据存储和HDFS之间高效批量传输数据,进行数据同步;
② HDFS:分布式文件系统;
③ Hive:建立在Hadoop基础上的开源数据仓库,提供基本数据分析服务;
④ YARN:资源管理系统,可以为各类应用程序进行资源管理和调度;
⑤ MapReduce:快速并行处理大量数据,是一种分布式数据处理模式和执行环境;
⑥ Avro:序列化系统,支持高效、跨语言的RPC和持久化数据存储;
⑦ Oozie:任务调度框架,提供对Hadoop MapReduce和Pig Jobs的任务调度与协调;
⑧ Solr:独立的企业级搜索应用服务器,对外提供类似于Web-service的API接口;
⑨ Mahout:数据挖掘工具库;
⑩ DataV:一站式数据可视化应用搭建工具,可实现可视化图表制作、数据连接配置和一键部署发布;
1.1 数据采集与存储
本文运用Sqoop组件将货运车辆数据从PostgreSQL数据库迁移到Hive数据库,并存储于HDFS分布式文件系统[10]。货运车辆数据信息如表1所示。
表1 货运车辆数据信息
Tab.1 Data information of trucks

车辆基础业务信息行业信息行业名称、行业描述企业信息企业编码、企业名称、企业地址、企业联系人、联系人电话和联系人邮件机构信息机构名称、联系人、联系人电话、办公地址和员工数据分组信息分组名称、包含用户数、车辆数和回传时间间隔车辆信息车牌基本信息、车辆详细信息和车机设备信息司机信息司机名称、身份证号、驾驶证号和手机号码人员信息人员名称、身份证号、人员类型和手机号码SIM信息SIM卡号、SIM类型和SIM卡关联车辆用户信息用户基本信息、用户权限信息角色信息功能权限角色信息、车辆权限角色信息入网信息入网车牌号、入网操作类型指令信息指令代码、指令名称、指令参数、指令级别、指令描述和指令操作密码日志信息系统操作日志信息、用户登录日志信息元数据信息性别、车辆颜色、车辆类型、车辆品牌、燃油类别、用户类型、围栏类型、呼叫类型、人员类型、日志类型和操作类型车辆轨迹状态信息轨迹信息经纬度、地址、时间、速度、方向、高程和油量等状态信息车辆状态信息、报警状态信息和车机状态信息等
1.2 数据分析与挖掘
数据分析与挖掘层采用MapReduce编程模型、Mahout组件[11-12]进行数据的并行化计算,主要包含数据预处理与数据分析挖掘2部分。
数据预处理[13]部分对车辆监控平台原始数据的清洗、集成、转换和规约。
数据分析与挖掘[14-15]部分对海量数据分析处理。其中,聚类算法[16-18]用于按相似性特征对数据进行分组;分类算法根据数据特征和事物分类训练分类器,并根据分类模型判别新事物归属;关联规则分析算法对海量数据中的频繁项集进行挖掘;协同过滤算法[19]通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的事物,Mahout组件中的协同过滤算法分为基于物品的推荐(Item-Based Collaborative Filtering)算法和基于用户的推荐(User-Based CollaboratIve Filtering)算法;回归分析算法用于挖掘数据仓库中数据属性值之间的依赖特性,预测事物发展趋势。
1.3 数据可视化展示
数据展示层[20]将平台分析的部分结果以直观的形式进行展示。
本文运用Hive组件[21],进行货运车辆数据的统计分析任务设计与开发,主要进行了某月份车辆超速次数、某月份车辆TopN超速次数、某月份企业超速次数、某月份企业TopN超速次数、年度车辆ACC总时长、年度车辆超速次数、年度企业超速次数、企业车辆上线率分析、某月份企业报警总时长、某月份企业在线总时长和某月份车辆总里程等任务分析。
本文综合运用DataV软件的柱状图、饼状图、折线、雷达图、地理分布图和气泡图等多种图表化元素对上述分析结果进行可视化展示。
2 大数据算法应用研究
2.1 基于时空特征的K-means聚类算法
2.1.1 数据预处理与轨迹划分
由于卫星定位终端设备故障、信号不良和冷启动等原因,采集的北斗/GPS数据会存在一定的误差。本文通过均值滤波、速度滤波和航向角检测等方法来对数据进行预处理操作,剔除无效或者冗余的数据。然后基于时间间隔对轨迹进行划分,并对轨迹进行了压缩处理,降低后续轨迹处理过程的时间复杂度。
2.1.2 基于时空相似性的轨迹相似性刻画
通过对平台货车速度进行大数据统计分析发现,货车的平均车速比较接近,这与货运车辆大多时间行驶在交通相对通畅的城际道路或者高速公路上这一事实相符。在进行轨迹相似性度量过程中,同时考虑轨迹所耗费时长的相似性和空间位置相似性,构建基于轨迹行驶时间差和轨迹距离差的轨迹相似性度量公式。轨迹L1={a1,a2,…,am}和轨迹L2={b1,b2,…,bn}之间的时空距离计算公式如下:
(1)
DF(L1,L2)min(maximax(a,b)∈Ai×BidistE(ai,bj)),
(2)
(3)
式中,T1,T2分别为轨迹L1和轨迹L2的从轨迹起点行驶到终点所耗费的小时数;Ls1,Ls2分别表示轨迹L1和轨迹L2的起始点和终点之间的直线距离;DF(L1,L2)为轨迹L1和轨迹L2的离散弗雷歇距离[22];distE(ai,bj)为经纬度点ai和bj之间的欧氏距离。
根据平台货车轨迹实际情况,本文取权重参数α=0.22,β=0.78。
2.1.3 聚类结果分析
根据以上距离,通过K-means聚类算法对大数据平台上某月份的货运车辆轨迹进行了处理,并对包含轨迹数量最多的10个轨迹类进行展示,轨迹聚类结果如表2所示。
表2 货物运输热门线路聚类结果表
Tab.2 Clustering results of hot freight transport lines
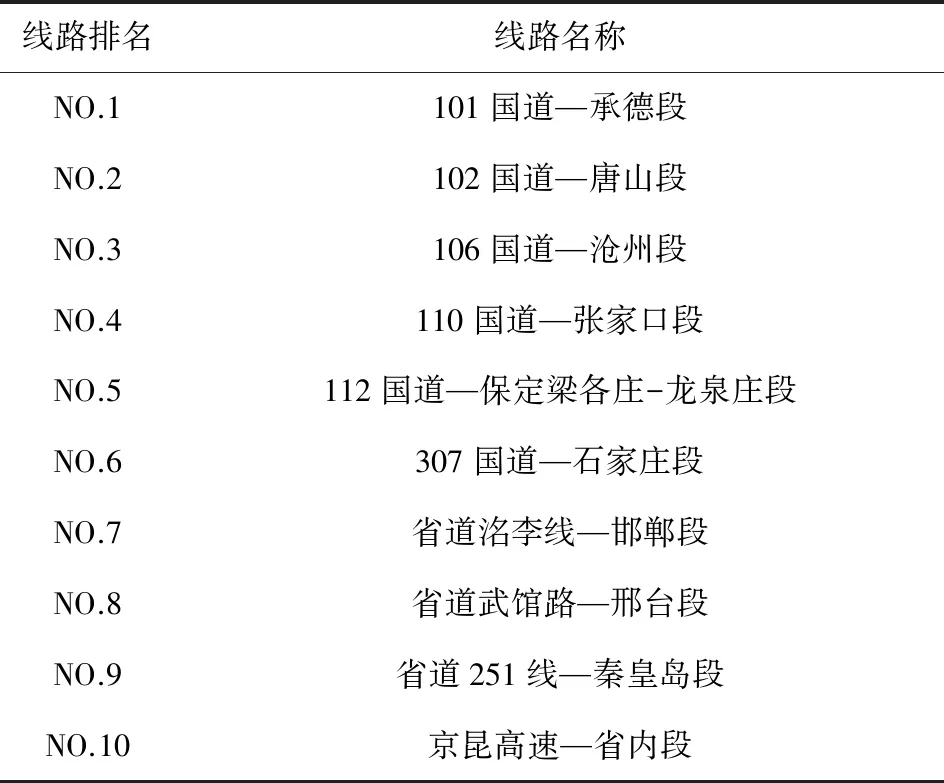
线路排名线路名称NO.1101国道—承德段NO.2102国道—唐山段NO.3106国道—沧州段NO.4110国道—张家口段NO.5112国道—保定梁各庄-龙泉庄段NO.6307国道—石家庄段NO.7省道洺李线—邯郸段NO.8省道武馆路—邢台段NO.9省道251线—秦皇岛段NO.10京昆高速—省内段
2.2 基于专家系统和协同过滤算法的货车未来活动区域预测
2.2.1 预测步骤
步骤1:根据上节中的轨迹聚类处理结果,假设有n个轨迹类簇,对第i(i=1,2,…,n)个聚类类簇Ci取其所有轨迹点的经纬度坐标均值分别作为该轨迹类簇中心点的经纬度坐标,取所有轨迹起始点直线长度均值的1/2作为轨迹类簇的半径。
步骤2:根据每个聚类类簇中轨迹的数量,对轨迹类簇进行活跃度评分,通过对大数据平台轨迹数量分布情况的大量经验总结,采用专家系统法[23-24]对轨迹类簇的活跃度进行评分,具体评分规则为:
IFnum≥5 000,THENScore=5;
IFnum≥4 000 andnum<5 000,THEN
Score=4;
IFnum≥2 500 andnum<4 000,THEN
Score=3;
IFnum≥1 500 andnum<2 500,THEN
Score=2;
IFnum<1 500,THENScore=1。
其中,num为某轨迹类簇中轨迹的条数;Score为该轨迹类簇的活跃度评分。
步骤3:根据步骤2的评分,以某一辆车的最近一年的轨迹作为历史数据,进行基于物品的协同过滤算法处理,计算出该车辆未来业务活动区域预测。
步骤4:根据步骤2的评分,以不同车辆的轨迹相似性为基础,为某一车辆进行基于用户的协同过滤算法处理,计算出该车辆未来业务活动区域预测。
步骤5:根据步骤3和步骤4的处理结果,计算预测结果的轨迹类簇的并集,对轨迹类簇按所包含的轨迹条数进行降序排序。
步骤6:选取轨迹条数最多的5个轨迹类簇,以轨迹聚类类簇的中心点和半径,作为该车辆的未来轨迹活动区域预测结果。
2.2.2 预测结果分析
选取平台上业务活跃的500辆货运车辆一年的历史轨迹数据进行轨迹预测分析,并以之后半年的轨迹数据作为预测结果比对标准。
经验证,该预测方法准确率达到60%以上,预测方法具备一定的可行性。
3 结束语
本文搭建了基于Hadoop2.x技术体系的大数据平台,将存储于百万级综合车辆位置服务平台传统数据库的货运车辆数据批量迁移到分布式文件系统,并进行了货车数据的分析和挖掘;设计并实现了基于时空特征的K-means聚类算法,对货运车辆热门区域进行分析;将专家系统的思路和协同过滤算法进行融合,对货车未来一段时间轨迹的范围进行了预测,挖掘货车的轨迹规律和业务发展特征。本文所做工作对于挖掘热门运输线路和分析货运车辆行为特征具有一定的实用价值和借鉴意义。
