基于注意力机制的谣言检测算法研究
2020-04-22夏鑫林许亮
夏鑫林,许亮
(四川大学计算机学院,成都610065)
0 引言
社交媒体已经成为人们分享信息以及交流的平台,然而由于缺乏有效监管,谣言等虚假信息也的泛滥也给政治、经济、文化等领域带来威胁。研究认为互联网虚假新闻甚至影响了英国脱欧投票和2016 年美国总统大选的结果,传统的人工审核收集以及分析信息十分耗时,因此十分有必要在谣言早期进行自动化检测[1]。一方面,近年来深度学习发展迅猛,其中注意力机制在各个领域被广泛使用,具有较大的影响力。基于注意力机制的衍生模型Transformer 有研究[2]表明在一些任务上Transformer 特征抽取能力上不仅强于循环神经网络而且相比之下更易并行。另一方面,一般谣言是故意伪造来诱导大众的报道,风格迥异,主题多种多样,仅根据特定文本内容特征很难辨识是否是谣言,因此十分有必要引入传统手工构造特征,但如何对这些多模态特征进行融合也是需要解决的问题。因此本文主要工作如下:
(1)实现了基于注意力机制的谣言检测模型,实验表明能够有效检测出谣言。
(2)在工作(1)的基础上,尝试了将手工特征引入到模型中,实验表明手工特征的引入能够进一步提高模型的检测能力。
1 研究现状
谣言检测实质上是一个二分类问题,现有研究主要集中在特征构造以及模型框架的改造两方面。
(1)从特征构造角度,Ratkiewic 等人[3]提出利用内容中标签、超链接等相关特征。Takahashi 等人[4]则使用词频特征来表达谣言与非谣言文本的词频分布差异;Castillo 等人[5]、Al-Khalifa 等人[6]、Gupta 等人[7]则使用用户信息以及转发量、评论数等社交媒体交互特征。Kwon 等人[8]则对评论信息建模结合其他特征通过聚类算法得到新特征;Yang 等人[9]提出设备类型以及时间发生地点作为特征。以上特征通过具体业务可以很容易构造出来,另外也有研究者试图挖掘更深层次的特征。Sun 等人[10]引入图片等多模态数据进行特征抽取辅助进行检测;Zhang 等人[11]则利用特征组合方法抽取出可以描述传播范围的特征,包括流行度、转发率、情感记性、用户影响力等特征。Zhao 等人[12]提出通过挖掘具有疑问的关键字特征来辅助检测。
(2)从模型角度,谣言在传播过程中产生的子事件包括评论、转发等,因此这些包含时间上先后顺序的行为数据组成了时间序列数据。因此目前主流的谣言检测算法仍然是使用时间序列模型检测某些类别特征模式变化从而进行谣言检测。Ma 等人[13]首先构造统计量特征以及描述特征变化的特征,然后将特征拼接作为特征向量,博文内容以及博文评论作为输入给RNN 模型,然后进行检测;Ma 等人[14]提出了使用LSTM、GRU、tanh-RNN 模型进行自动化谣言检测。实验表明循环神经网络方法优于人工构造特征进行谣言检测方法。
2 相关工作
2.1 词向量模型
针对文本的表征从最初的one-hot 表示,到最近发展比较火热的Word2Vec 模型[15],Word2Vec 模型可以以无监督的方式进行训练,不仅可以学习到词语低维语义向量表示,而且对于经常出现在相似上下文的两个单词,该模型可以学到词语间的语义相似性。由于是无监督学习,不需要标签数据,因此网络上有很多文本可以作为预料使用,当数据量足够大时,学习出的词向量具有很好的泛化能力。然而如果应用到具体任务时,目标语料较少,此时如果直接使用该预料训练会使得词向量训练不充分,表达能力弱,因此通常在实际使用过程中,一般采用迁移学习的方法,先在大规模语料上训练得到词向量,然后交给下游任务使用。具体到本文研究中,由于谣言数据不便于采集,导致整体数据集规模较小,预料不足,因此本文算法首先使用大规模微博数据进行Word2Vec 模型的训练,然后将学习得到的词向量交给下游任务使用。
2.2 长短期记忆网络
LSTM[17]是对循环神经网络的改进,通过引入门控机制,引入了类似于残差机制,使得在反向传播过程某些路径中不出现类似于RNN 反向传播时的连乘结构,在一定程度上缓解了RNN 网络在训练过程的梯度爆炸与梯度弥散问题。LSTM[17]通过记忆单元来记忆存储句子中重要的特征信息,同时能够对不重要信息进行遗忘,在t 时刻,对于给定的输入xt,ht-1,LSTM[17]的隐藏层输出为ht,其具体的计算过程如式(1-6)所示
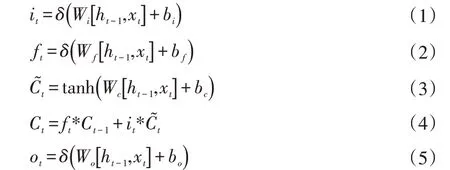

其中,W 为连接两层的权重矩阵,δ 和tanh 为激活函数,z、r 分别为更新门和重置门。
3 模型结构
3.1 注意力机制及其衍生网络
循环神经网络由于存在状态间的依赖关系,由2.2小节公式(1-6)可知,t 时刻的输入依赖t-1 时刻的输出,因此无法实现并行,模型训练时间缓慢;虽然LSTM[17]在单元中某些路径引入了残差机制一定程度缓解了梯度消失与梯度爆炸,但在一些路径在反向传播过程中依然存在连乘结构,因此还是存在梯度消失与梯度爆炸现象,限制了LSTM[17]学习长距离依赖关系以及抽取语义特征的能力。近年来,谷歌提出了Transformer 模型[2],其中论文中的注意力机制在当今研究中被普遍使用,该模型引入了多头自注意力,前馈网络以及残差机制,该模型编码层通过多头自注意力抽取语义特征,不存在时间上的依赖关系,便于并行化。实验表明,Transformer[2]以及其衍生模型Transformer-XL[16]在文本语义特征抽取能力上显著高于RNN、LSTM[17]等循环神经网络模型。
3.2 基于注意力机制的谣言检测模型
微博文本数据通过Word2Vec[15]模型,将单词映射成相应词向量转成词向量矩阵,经过一层LSTM 得到隐向量,隐向量经过加权求和得到句向量表示,权重是通过注意力机制进行隐向量间的注意力权重计算得到的,类似的,接着在句向量间进行注意力的计算,得到事件的向量表示,然后进行二分类,最终输出是否是谣言的概率。模型结构图如图1 所示。
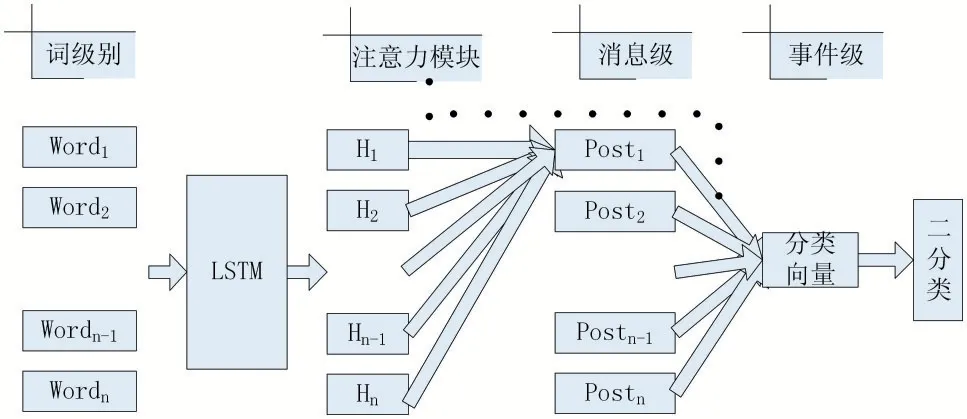
图1 基于注意力机制的谣言检测模型
3.3 基于多模态特征融合的谣言检测模型
传统的文本谣言检测模型仅仅是考虑文本内容特征,然而在实际情况中,谣言是往往经过精心设计、层层包装地诱导群众的报道,主题多种多样,而且风格迥异,仅仅考虑文本特征,会使得检测算法非常受限。例如根据先验知识,例如用户的身份信息,以及用户的点赞以及评论等行为特征在一定程度上能够判别是否是造谣者,那么对于判断该用户发出来新闻是否是谣言非常有用。因此本文在原有3.2 小节模型基础上,手工构造了评论数目,以及评论的平均长度、最大长度、最小长度等特征,输入到模型中,实验证明加入这些特征后对模型效果提升明显,而且针对不同模态的特征融合方式具体操作方式如下:微博文本数据通过3.2 小节描述的方式得到事件的语义表示后,以及通过评论数据抽取得到行为特征,两种特征向量进行直接拼接得到特征向量,然后进行二分类。如图2 所示。
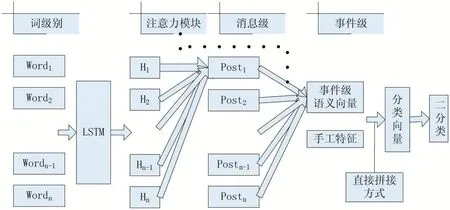
图2 不同模态特征直接拼接特征融合方式
4 实验对比
本文模型为了便于与Ma 等人[14]的工作进行对比,基于相同数据集以及相同训练集与验证集划分方式,与tanh-RNN、LSTM、GRU 算法进行对比。
4.1 评价指标
本文评价指标采用准确率(accuracy)、召回率(recall)、精确率(precision),以及Fl 值,它们针对谣言的定义如下:
准确率=系统正确识别谣言与非谣言样本数目/系统判别样本数目
召回率=系统正确识别谣言样本数目/谣言样本数目
精确率=系统正确识别谣言样本数目/系统判别为谣言数目
F1=2×精确率×召回率/(精确率+召回率)
4.2 实验结果
本文算法与其他作者论文算法的实验结果如表1所示。其中,“-1”“-2”表示隐含层层数。
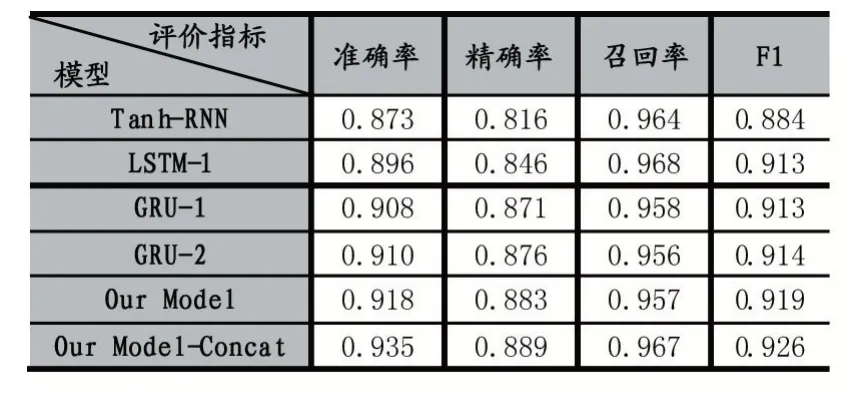
表1 本文算法与原算法对比结果
从表1 中可以看出:
(1)本文的基于注意力机制的模型与GRU-2 模型相比,准确率提高了0.8%,精确率提高了0.7%,而与LSTM-1 模型相比在召回率下降了1.1%,F1 值提高了0.5%。F1 值可以综合衡量模型的性能,从表中可以看到,本文算法在F1 值上都高于原论文算法。从而证明本文模型优于基于回复式神经网络检测模型,能够有效检测出谣言。
(2)融入了人工特征后的模型,对比没有添加人工特征的模型在精度上有了更多的提升,证实了手工构造特征的有效性。
5 结语
本文算法通过在模型的各个阶段引入注意力机制进行特征的抽取,使得语义特征表达更丰富,有效提升了模型的性能,在此基础上,本文算法还尝试将手工构造特征引入模型中,进一步地提升了模型对于谣言的识别率。针对于谣言识别场景、数据量较少、类别不平衡等问题,如何对数据进行处理或修改模型架构进一步提升算法性能将是未来的研究方向。
