基于深度强化学习算法的终端区飞机着陆调度算法研究
2020-04-22卢锐轩
卢锐轩
(四川大学视觉合成图像图形技术国防重点学科实验室,成都610065)
0 引言
随着中国空中交通运输的迅速发展,极速增长的客运、货运需求和有限的枢纽机场的终端区空域资源的矛盾日益突出,如何解决有限机场终端区里的航班调度问题是整个空中交通问题中的关键问题。
航班着陆调度问题(Aircraft Landing Scheduling,ALS)是典型的多目标优化问题,而且是多目标多约束的组合优化问题,航空界一直以来都在处理这类NP 问题(即多项式复杂程度的非确定性问题),目前尚未得出较为完善合理的解决方法,因此在这个问题存在很多研究的空间。目前中国飞机的终端区调度一般采取先来先服务(First-Come, First-Served,FCFS)的方式,这样比较稳定,计算也比较方便。近年来一直有很多专家学者在将相关智能优化算法应用到航班着陆调度应用领域,如有针对蚁群算法对飞机着陆调度的基于均衡更新蚁群算法的飞机排序调度[1],也有基于改进免疫粒子群算法的调度算法[2],其次还有基于遗传算法的着陆调度问题研究[3]。
深度强化学习算法是一种可以模拟人类学习过程的新型智能算法,其中强化学习算法通过提供一个可反复训练的环境给待训练模型,就好比提供一个学习环境给一个孩子,让他在环境中通过自学来提升自己的能力;而将深度学习的加入则提高了智能体的表达和理解环境的能力,因为环境可能会比较复杂,包含多维信息,利用传统的强化学习算法来通过表格理解环境已经不太现实。目前有很多学者和科学家在将深度强化学习应用到很多工业领域,如在移动机器人避障领域的研究[4],还有在自动驾驶方面的应用[5],也有在行人和车辆检测方向的研究[6]。ALS 问题中寻求最优解过程就是一种不断训练,不断探索,寻求最优解的过程,可以通过深度强化学习算法来去寻求最优解。
本文分析了航班着陆调度问题的问题来源和流程,建立了用来深度强化学习训练的航班着陆调度环境,通过引入深度强化学习算法,提出了一系列利用深度强化学习算法来解决航班着陆调度的新方法。通过实验表明,其算法相对于传统粒子群算法效果更好。
1 问题描述与建模
1.1 问题描述
本文采用类似滑动窗口的方式对待航班着陆问题,即在一个时间段内,只考虑固定数量的飞机,对该时间段飞机进行安全着陆后,再将时间窗口向后滑动,并对后面的飞机进行处理。一段时间内的一组飞机P={a1,a2,a3,...,an}中的每架飞机包含飞机的机型PT、最佳着陆时间MF、最早着陆时间ME、最迟着陆时间ML、实际着陆时间AL 等主要属性。
其中飞机类型包括三种:轻H、中L、重S,不同的类型的飞机的提前着陆单位时间成本和延误着陆单位时间成本,同时不同类型的飞机准备要着陆时与之前刚着陆的飞机的最小安全时间间隔不同;实际着陆时间需要满足飞机之间的最小安全时间间隔,同时还需要做到使得几架飞机的总着陆成本尽量小。具体着陆时间与费用的关系如下图1 所示,其中费用与着陆时间为线性关系,其中飞机延误相当于飞机需要在机场附近上空盘旋等待降落,提前着陆相当于飞机需要在整个航行过程中进行一定加速飞机,所以延误着陆单位时间成本会比提前着陆单位时间成本高。
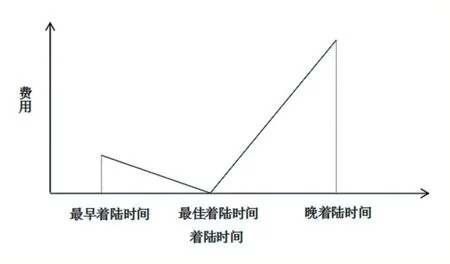
图1 着陆时间与费用关系图
1.2 优化目标
假设在某时间段内有n 架飞机需要着陆,如上所述,每架飞机都包含以下属性:飞机的机型PT、最佳着陆时间MF、最早着陆时间ME、最迟着陆时间ML、实际着陆时间AL,着陆总成本的计算方法为:每架飞机实际着陆时间AL 与最佳着陆时间MF 的差与单位时间提前着陆成本EC 或单位时间延误着陆成本LC 的乘积和。计算公式:
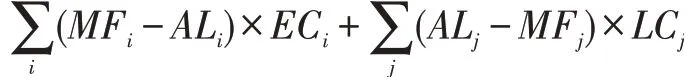
其中i 表示各架提前着陆的飞机序号,j 表示各架延误着陆飞机序号,时间的单位是分钟(min),成本的单位是元每分钟(¥/min)。
1.3 环境建模
要想将深度强化学习算法应用到航班着陆调度问题中,首先要建立一个能够让深度强化学习智能体在其中训练的环境,这个环境需要做到支持环境与智能体之间的互相交互,如图2 所示。

图2 深度强化学习方法
环境中输出用于表示状态的state 的包括的信息如表1 所示。
表1 状态信息表
环境中接收用于表示动作的action 包括的信息如表2 所示。

表2 动作信息表
其中DQN 网络训练中使用的是飞机着陆序号来进行着陆,DDPG 网络中使用的是飞机着陆时间比例进行着陆。
除此之外,环境还需要对神经网络输出的动作进行评价和打分,评价的依据就是以计算后着陆时间进行着陆后的总着陆成本,着陆成本越大说明动作方案还不够合理,这样得到的动作评价越低,相反着陆成本越低则说明动作方案比较合理,这样得到的动作评价越高。其中着陆成本取决于飞机着陆时间和最佳着陆时间的差和延误着陆或提前着陆成本单位时间系数,不同的飞机的着陆成本单位时间系数如表3 所示,单位为元每分钟。
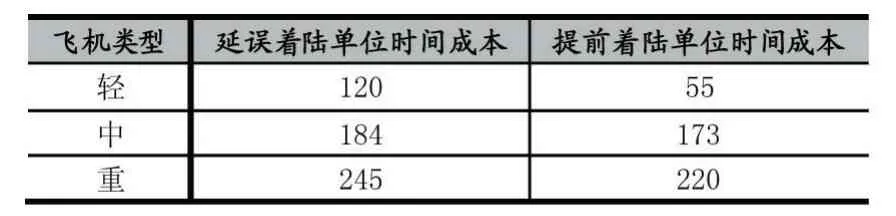
表3 单位时间成本表
着陆成本的具体计算方法为每架飞机实际着陆时间AL 与最佳着陆时间MF 的差与提前着陆成本EC 或延误着陆成本LC 的乘积和。计算公式:
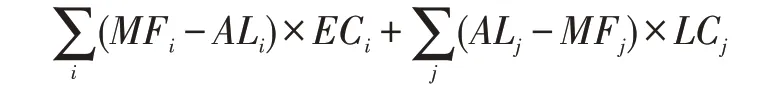
其中i 表示各架提前着陆的飞机序号,j 表示各架延误着陆飞机序号,时间的单位是分钟(min),成本的单位是元每分钟(¥/min)。
2 算法设计
2.1 深度强化学习算法
深度强化学习算法中分为基于值函数的方法和基于策略函数的方法,两种方法的区别就在于基于值函数的深度强化学习方法是用深度网络去逼近动作的奖励价值函数,而基于策略函数的深度强化学习方法是用深度网络去逼近策略函数。因此,两种深度强化学习方法的深度神经网络的输出是不同的,在基于值函数的深度强化学习方法中,深度网络输出当前状态下每个动作的动作价值大小,并由此选择动作价值最大的动作去执行;基于策略函数的深度强化学习方法中,不再用深度网络去输出每个动作的价值函数,而是输出一个具体动作值,这个动作值可以是连续的,而基于值函数的方法中最终输出的只能是离散的动作。
DQN 又称深度Q 网络,是基于值的深度强化学习算法,也是一种Q 学习与深度学习结合的创新应用,Q学习中是使用Q 表格来记录状态-动作对的值的,在DQN 算法中使用神经网络来拟合Q 函数用来代表动作价值函数。同时,DQN 还具有两大利器,其一就是使用经验池的方法来解决相关性以及非静态分布问题,其二就是使用一个主网络来生成当前Q 值,再使用目标网络生成目标Q 值,经过一定次数的迭代将主网络的参数赋值给目标网络,两个网络不同步更新,提高了训练的稳定性并且加速了收敛速度。将DQN 应用到飞机着陆算法的过程中,可以通过DQN 输出飞机的排序序号,为飞机着陆时间定好初始值,再通过粒子群算法对着陆时间进行调优。
DDPG 是基于策略的深度强化学习算法,在动作输出方面他采用一个网络来拟合策略函数,直接输出动作,可以应对连续动作的输出,在应用到飞机着陆调度中时,可以将动作空间定为[0.0,1.0]区间,代表实际着陆时间在最早着陆时间和最迟着陆时间的比例,通过该方法可以计算出具体的着陆时间。
2.2 粒子群算法
粒子群优化算法(PSO)是由Kennedy 和Eberhart在1995 年提出的群体演化算法,是通过模拟鸟群捕食行为设计的。PSO 算法中首先初始化一波粒子群,其中每颗粒子代表着每个初始化的解,每颗粒子通过不断探索和信息交互来向最优解靠近,最终每颗粒子都能聚集在最优解的周围。
将粒子群算法应用在飞机着陆问题中时,每个粒子的位置向量就代表着每架飞机的具体着陆时间,粒子群算法可以把飞机着陆成本当做每个粒子的个体值的评价标准,并让粒子群不断向着陆成本更低的方向移动。但在将传统粒子群算法应用到飞机着陆调度问题中的时候,在面对优化难度较大的问题时,粒子群算法很容易陷入局部最优解,由局部最优解再向全局最优解探索的过程会消耗更大计算时间,由此本文引入了深度强化学习算法来先为粒子群算法制定好初始解,先通过深度强化学习算法的探索能力和学习能力来对最优解进行探索,但深度强化学习算法得出的解可能不够精确,所以可以再借助粒子群算法进行调优处理。
3 实验过程及结论
3.1 实验过程
本文在CPU 为1.7GHz,内存为4GB 的计算机及Windows 7 环境下,采用Python 编程运行上述算法。算法参数如下:仿真实例共4 架飞机,即每次一共为4架飞机进行着陆调度,每架飞机的最佳着陆时间都集中在随机的3 分钟范围内,以保证飞机无法都按照最佳时间进行着陆,即飞机需要进行着陆时间的调整。总共包含两次实验:
实验一:将DDPG 应用到飞机着陆调度问题中,首先将DDPG 的输出的动作action 的范围调整为[0,1],假设输出的动作为a,待调整飞机的最早着陆时间为me,最迟着陆时间为ml,则计算出的实际着陆时间为me+a*(ml-me),然后将几架飞机的着陆时间按顺序排列,如果后着陆的飞机不满足最小安全时间间隔原则,则将后着陆飞机以此向后延误,进过调整后得到最终飞机实际着陆时间。作为对比的算法为先来先服务算法(FCFS),即让飞机按照到达机场的顺序进行以此着陆,如果飞机不满足最小安全时间间隔则直接按着陆顺序向后延迟。实验结果如下图3 所示,其中实验数据取没100 次试验的平均值,横轴代表实验次数,单位为每100 次,纵轴为着陆成本,单位为元。

图3 实验一
实验二:将DQN 结合粒子群算法应用到飞机着陆调度中,首先在DQN 的每步动作中,让动作网络输出的不是具体着陆时间而是着陆顺序,现根据飞机的先后顺序,依次为飞机计算着陆时间,而不是按照初始的先后顺序来计算着陆时间。计算好的时间作为初始化时间再利用粒子群算法进行微调和优化,从而计算出确切的着陆时间。对照实验依然为先来先服务(FCFS),实验结果如下所示,其中实验数据取没100 次试验的平均值,横轴代表实验次数,单位为每100 次,纵轴为着陆成本,单位为元。
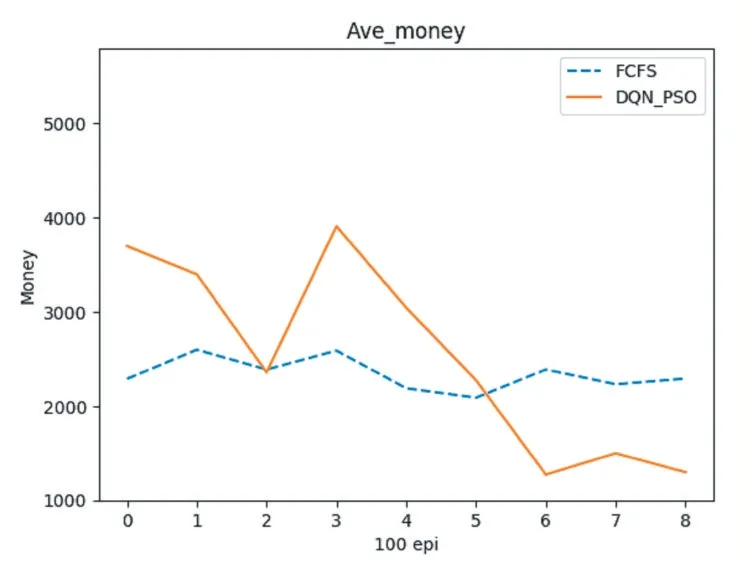
图4 实验二
3.2 实验结论
通过以上实验的对照,可以发现经过一段时间的训练,两种深度强化学习算法在飞机着陆调度的应用结果都好于现在主流的先来先服务FCFS 算法,同时经过粒子群算法优化的实验二的数据要更好一些。在将粒子群算法与深度强化学习DQN 算法结合来解决飞机着陆调度问题中时,将深度强化学习这种反复训练不断逐优的特性和超强的学习能力加入飞机着陆调度过程,提升了粒子群算法的探索能力并且解决了直接将深度强化学习算法应用到飞机着陆调度算法中时,最终计算结果优化不够的问题。同时将深度强化学习算法与群计算智能算法结合的这种思路也为避免深度强化学习算法和群智能算法陷入最优解提供了新的解决方案。
