基于多源异构数据的甲骨学知识图谱构建方法研究
2020-04-21熊晶焦清局刘运通
熊晶,焦清局,刘运通
(1.安阳师范学院计算机与信息工程学院,河南安阳 455000; 2.甲骨文信息处理教育部重点实验室,河南安阳455000)
甲骨文(oracle bone inscriptions, OBI)是现今已发现的成体系的最早文字,是中华民族传统文化的瑰宝。甲骨文内容繁复,涉及3 000 年前殷商时期的政治、王室、社会、经济、天文、生态、交通、地理、战争、宗教、文化等方面,具有极高的文物、史料和研究价值。从1899 年甲骨文被发现以来,经海内外学者120 年来的研究和探索,现已成为一门举世瞩目的国际性显学——甲骨学(oracle bone studies,OBS)[1]。近年来,从事甲骨文研究的学者逐渐增多,尤其是2017 年11 月甲骨文成功入选《世界记忆名录》后,甲骨文研究迎来了新发展。 随着甲骨学研究的不断推进,甲骨文数据日益丰富,并逐渐体现出多源异构的特性。如图1 所示。

图1 甲骨文多源异构数据Fig.1 OBI multi-source heterogeneous data
日益丰富的研究数据在带来便利的同时也引发了新的问题,如数据格式不统一、数据孤岛林立、数据检索困难、数据共享程度低等。同时,甲骨学研究存在学习难度大、学习周期长、知识关联性弱、认知理解要求高等问题。在此背景下,迫切需要一种有效的甲骨学知识表示和组织方式。由于知识图谱可为认知智能提供丰富的背景知识,因此,构建甲骨学知识图谱可有效解决上述问题。
甲骨学研究需借助相关辅助学科[2],如借助考古学,解决甲骨出土问题;借助文献学,解决甲骨学中的殷商历史问题;借助语言学理论,解决甲骨学的语言文字问题;借助自然科学中的天文学、地理学、物理学和数学,解决甲骨学中的诸多问题[3]。因此,甲骨学研究涉及庞大的学科体系和知识群落。鉴于甲骨文的古籍特性,甲骨学研究必须依赖大量文献资料,并基于文献进行一系列的知识关联分析。如学者与文献的关系、学者及其合作关系、研究机构及其合作关系、文献之间引用与被引用关系,这些都属于科学知识图谱[4](mapping knowledge domains,简称MKD)的研究范畴。MKD 研究均以文献计量为主,侧重分析学科的知识结构及知识群落,研究热点及研究趋势,研究机构、学者及其合作关系等宏观知识,较少涉及领域微观知识;MKD 的分析关系大多是直接或间接的浅层关系,且在语义解释方面尚有不足[5],无法表达甲骨学领域中深层次的语义关联关系,如甲骨文著录与甲骨片的关系、甲骨片与甲骨片的关系、甲骨文异体字之间的关系、商王世系的关系、贞人与商王及卜辞的关系、祭祀、战争事件等。因此,仅仅依靠MKD 无法较好地表示甲骨学的领域知识[2]。
Knowledge graph[6](简称KG)可用统一的方式体现知识定义和知识实体两个层次共同构成的知识系统[7]。KG 通过关系连接实体后,根据连接的路径,将相关实体联系起来获取知识。KG 的构建大多基于大数据,综合维基百科等百科类数据、网络知识库、搜索日志、开放链接数据、社会网络、众包等资源实现实体抽取和实体链接,通常利用本体进行知识映射或知识融合。目前网络上有关甲骨学数据及知识描述的资源极少,绝大多数甲骨学数据均以不同的形式存储在各研究机构,因此,甲骨学领域需要重新考虑知识实体的发现及关系挖掘方法[2]。
综上所述,构建甲骨学知识图谱面临以下挑战:(1) MKD 在表达微观层面的甲骨学知识关联方面存在不足,需要KG 来弥补;(2)从多源异构的数据源中进行知识抽取尚无通用方法,需要结合甲骨学数据特征进行;(3) 利用MKD 研究甲骨文文献是必由之路,同时,在为构建甲骨学知识图谱而引入新的数据模式时需考虑图谱的融合问题;(4)研究甲骨学知识图谱的文献非常少,可用的开放链接资源稀缺,无法直接套用通用知识图谱或其他领域知识图谱的构建方法,需要专门研究面向甲骨学的知识图谱构建方法。因此,本文融合MKD 和KG 两类知识图谱来构建甲骨学知识图谱,以期解决甲骨学研究中存在的知识获取、管理和共享问题。
1 知识图谱研究现状
知识图谱的研究主要有两种类型[2]:以文献计量为主的科学知识图谱(MKD)和以Google 知识图谱为代表的KG。
1.1 MKD 研究现状
MKD 是一种融合数学、信息科学、计算机图形学等多学科理论和技术进行科技文献计量和分析的可视化研究方法,可运用图谱展示学科知识分布、发展趋势和研究热点等[8]。MKD 从最初的文献计量学及情报学迅速扩展到其他学科,在社会科学、自然科学领域有着越来越广泛的应用[9]。研究表明,MKD 既可以通过纵向比较来分析学科领域不同子领域的相互关系和演化历程;也可以通过横向比较来分析学科领域的研究热点和发展趋势[5]。刘则渊等[10]研究指出,德莱克斯大学、布鲁内尔大学、圣蒂亚国家实验室、伊拉兹马斯大学等是国外MKD 较有影响力的研究机构。值得一提的是德莱克斯大学的陈超美教授,其开发的知识图谱分析软件CiteSpace[11-12]已被广泛应用。汤建民等[13]认为,大连理工大学、武汉大学、中国科学院、浙江树人大学、南京大学等机构在MKD 研究方面表现突出,其中,大连理工大学[4]最早从科学计量学的视角引进科学知识图谱方法,极大地推动了国内MKD 的研究和发展[13]。
1.2 KG 研究现状
KG 自2012 年由Google 提出以来,迅速成为人工智能的研究热点,并涌现出一大批令人瞩目的成果。如YAGO[14]、NELL[15]、DBpedia[16]、Freebase[17]、Knowledge Vault[18]、Zhishi.me[19]、XLore[20]、OpenKG.CN[21]等。
KG 是一个多关系图,其结点表示实体或概念,连接结点的边表示实体与概念之间的关系。因此,构建KG 的关键是实体抽取和关系抽取。目前,大量的知识图谱研究是利用网络资源尤其是Wiki 类资源和链接开放数据(linked open data, LOD)实现实体抽取和关系抽取。 ABHISHEK 等[22]基于Wikipedia 实现了社交媒体的实体抽取、链接、分类及标注。DESHPANDE 等[23]利用Wikipedia 进行知识概念、实体及关系的抽取。DONG 等[18]构建了网络级的概率知识库knowledge vault,其实现方法是融合网页文本、表格数据、网页结构和人工标注信息。中文通用知识图谱Zhishi.me 是通过从百度百科、互动百科、维基百科等开放百科数据中抽取结构化数据后进行知识融合实现的;WANG 等[20]构建的跨语言知识图谱XLore 是基于百度百科、互动百科和中英文维基百科实现的;XU 等[24]研究了维基百科中实体间缺失语义关系的发现算法;WANG 等[25]基于跨语言知识库,实现了知识图谱的扩展;LIN 等[26]提出了一种新的KG 构建模型TransR,分别在实体空间和关系空间进行实体的学习和关系的建立;复旦大学研发的CN-DBpedia[27]开放百科中文知识图谱,涵盖数千万实体和数亿级的关系,相关知识服务API 累计调用量已达6 亿次。清华大学和微软在KDD 上 联 合 发 布 的Open Academic Graph[28],包 含Microsoft Academic Graph (MAG)的1.6 亿篇论文和AMiner[29]的1.55 亿篇论文,生成了2 个学术图谱的6 463 万个链接关系。中国科学院自动化所研发的Belief Engine[30]是一个中英文双语的跨领域知识图谱,在百度、互动、维基百科的陈述性知识基础上通过概念化产生概念层面的常识性知识,并为每一条常识性知识赋予一个信念值(belief value)。北京大学中文百科知识图谱PKU-PIE[31]是从维基百科、DBpedia、百度百科等处自动收集而成的知识库,有自己的类别体系和谓词体系,并且和DBpedia 等常用的知识库进行关联。
1.3 MKD 与KG 的 区 别 和 联 系
冯新翎等[32]从理论渊源、知识管理视角、适用研究领域等方面研究了MKD 和KG 的区别和联系,指出,MKD 和KG 都属于知识管理范畴,在知识管理过程中不同阶段扮演不同角色,完成各自功能。两者之间既有区别又紧密联系,在知识创新方面的融合和发展将带来知识管理领域科学范式的变革。MKD 和KG 都是以图为基础构建的网络模型,在网络分析的基础上服务于知识管理,所有网络分析的理论和方法都可应用于MKD 和KG 知识图谱的分析。大数据时代,MKD 和KG 可相互借鉴、相互促进,通过融合可以完成特定领域的知识图谱构建。一方面,MKD 可以集成机器学习中的聚类和关联挖掘等方法,提高算法和工具分析性能;另一方面,KG 可以借鉴MKD 中的可视化算法和工具展现大规模语义网络,清晰显示海量知识实体之间的复杂关系。
2 甲骨学知识图谱构建
甲骨学知识图谱的构建基于海量的多源异构甲骨文研究数据,通过融合MKD 和KG 两类知识图谱实现。其中MKD 以甲骨学文献为主要数据来源,KG 以甲骨文文本、语料库和数据库为主要数据来源。甲骨学知识图谱的构建流程如图2 所示。

图2 甲骨学知识图谱构建框架Fig.2 The construction framework of OBS knowledge graph
由图2 可知,构建甲骨学知识图谱的数据源包括甲骨文文献、数据库、文本、语料库等。首先,基于甲骨文文献,利用MKD 表示甲骨学知识关联、知识演化及知识群结构。同时,MKD 可作为一种新生成的数据来源,利用共引、共词、聚类分析等方法从MKD 中提取实体(如研究机构、学者、地点、人物、事件等)和实体之间的关系(如合作、被引、共现、为…提供依据、主题、分期、类组、材质、祭祀对象、继承等)。
甲骨文本体可为知识图谱提供概念模型和逻辑基础。基于已构建的甲骨文文献本体、甲骨文内容本体和甲骨文常识本体3 个本体[33],可以实现实体抽取和关系抽取。其中,甲骨文文献本体是依据甲骨文研究论文及专著建立的资源本体;甲骨文内容本体是描述经甲骨文专家及历史学家考释得到,描述了商代社会的家庭关系、生活、农作、天气、战争、狩猎等事件及其相互关系;甲骨文常识本体描述的是甲骨文的基本知识,如甲骨文的材料选择、占卜祭祀过程,以及甲骨文的发现历史、专家名录、考古记录、文字特征、语法知识等。
分别从MKD 和甲骨学数据源获取实体和关系后,需要将两者进行融合,构建MKD-KG 融合图谱。融合时考虑实体对齐和关系融合,而且本体有助于实现实体对齐和关系融合。同时,利用本体的语义关系和本体推理,可发现潜在的实体和隐含的语义关系,从而扩展和丰富MKD-KG 融合图谱。由于甲骨学领域专业程度高,因此,需要在甲骨文专家的指导下书写相应的规则,实现基于规则的知识推理。
2.1 甲骨学MKD 构建
MKD 构建方法较多,有共引分析法、共词分析法、聚类分析法、社会网络分析法,以及融合了其他文献特征的综合分析方法等[5]。其中,共词分析方法是通过分析同一个文本主体中的关键词,由其共同出现的形式来挖掘学科领域中主题间的关系,从而分析该领域的学科发展[34]。词作为知识继承与发展的最小功能单元,有利于明确分析知识之间的关联关系[5]。因此,本文选择共词分析法描述知识之间的联系。
共词分析,即分析词和词之间的知识关联。由于词代表着领域的知识概念,相较共引分析方法,共词分析更有利于揭示领域微观知识之间的联系。共词分析的功能大致分为[5]:从学科内部角度看,可以区分学科子领域,确定学科知识结构;从学科之间角度看,可以揭示研究主题之间的关联、特点和差异;从时间维度看,可以揭示学科领域中,不同子领域的研究发展、演化规律和相互作用关系;从横向的主题比较角度看,可以揭示学科研究主题与研究热点的接近程度,从而对知识发展趋势进行合理预测。
本文选择Cosine 函数法作为共词关系计算方法。设存在关键词Di=(d1i,d2i,…,dni)T和Dj=(d1j,,d2j,,…,dnj)T,则Di,Dj的Cosine 函 数 计 算 公式为
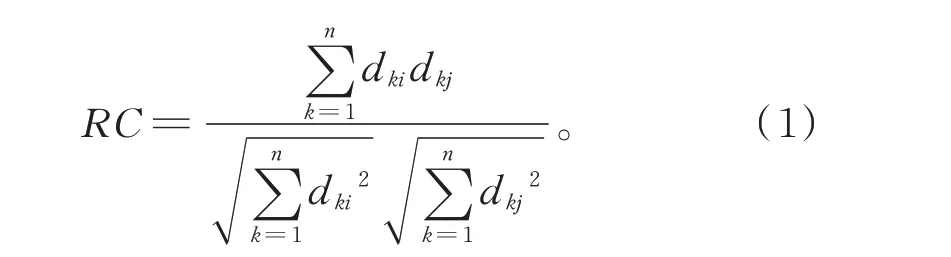
以CNKI 为数据来源,用“甲骨文”作为主题词检索1927 年5 月至2019 年1 月的文献,共筛选到5 971 篇。由于文献的标题、关键词和摘要已经能反映甲骨文知识的大部分内容,因此,构建过程中,只取文献的标题、关键词和摘要进行共词分析。利用CiteSpace 工具,采用余弦函数进行共词分析,得到的甲骨学MKD 图谱片段如图3 所示。
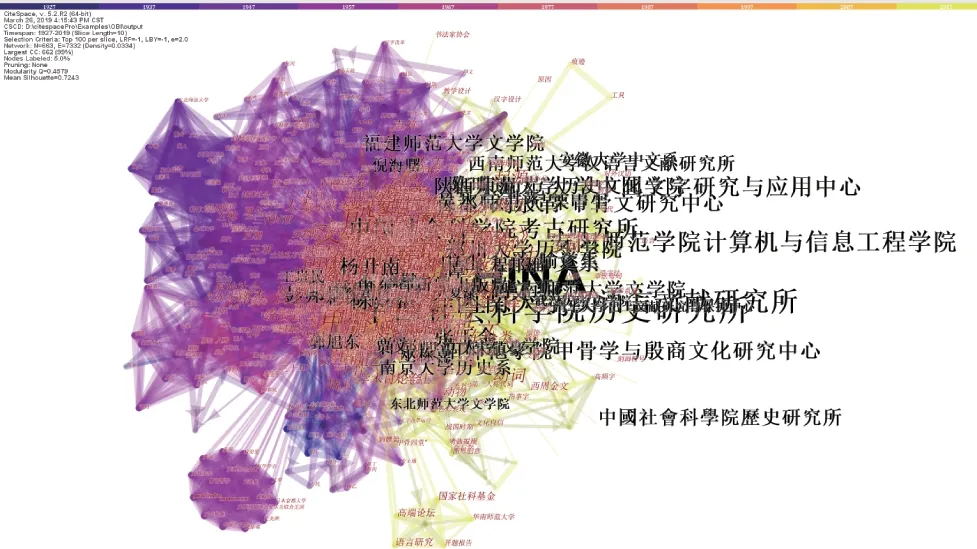
图3 甲骨学MKD 片段Fig.3 The fragment of OBS MKD
从图3 中可看出,甲骨学MKD 可以显示其知识结构及其分布。节点类型涵盖了人物、机构、时间、事件等实体,节点和字体的相对大小体现了词频,连线表明了知识节点之间的关系,颜色对应文献发表年份。图3 显示结果存在的最大问题是未考虑语义关系对实体的优化,如“高端论坛”“字符”“字频”等对甲骨文知识的意义不大,应该剔除;相反,有助于表示甲骨文知识的同义词、上位词、下位词等关系则没有体现。可见,单用MKD 无法较好地表示甲骨学知识体系。
2.2 甲骨学KG 构建
构建甲骨学KG 的关键是实体发现和关系抽取。甲骨学基础数据是多源异构的,这些数据中存在各种各样的实体,由图2 所示的甲骨学知识图谱构建框架可知,实体可以从甲骨学MKD、甲骨学数据库、甲骨文文本、甲骨学图文资料库等多源数据集中获取。而且,甲骨文本体中已经创建了大量较高质量的实例,这些实例可以直接作为甲骨学知识图谱中的实体。
2.2.1 基于甲骨学MKD 的实体发现与关系抽取
利用CiteSpace 构建了甲骨学MKD,其存储格式为*.graphml 文件,通过该文件中的〈node〉标记可以直接获取实体,文件中的〈edge〉标记可以直接获取实体及实体间的关系。在图3 所示的甲骨学MKD 中,〈node〉及〈edge〉对应的节点及关系如图4 所示。
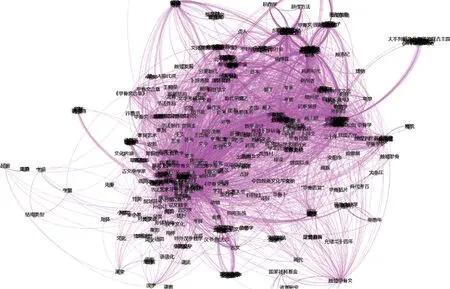
图4 基于MKD 的实体和关系抽取Fig.4 Entity and relation extraction based on MKD
2.2.2 基于甲骨学数据库的实体发现与关系抽取
甲骨学研究过程中建立了多种类型的数据库,如甲骨文词典数据库、甲骨文著录数据库、甲骨文文献数据库、甲骨语法库等。实际上,在构建数据库时就已经对数据对象进行了分析和设计,并定义了数据库模式。
定义1数据库的关系模式可以定义为一个五元 组R(U, D, DOM, F)[35],其 中R 为 关 系 名,U 为组成该关系的属性名集合,D 为U 中属性来自的域,DOM 为属性向域的映像集合,F 为属性间数据的依赖关系集合。
定义2本体可定义为一个五元组O = {C,A, R, I, Ao}[36],其 中C 是 概 念 集 合,A 是 属 性 集 合,R 表示概念间的相互关系,I 是实例集合,Ao是利用某种逻辑语言表示的公理集合。
由定义1 和定义2 知,数据库模式已成为本体开发中知识获取的重要方法。数据库模式中的关系、关系属性、属性的原子数据类型、属性约束、主键/外键等为本体构建提供了概念或类及其关系的描述[37]。所以,基于数据库可以实现实体发现和关系抽取。本文采用直接映射的方法,将关系数据库的表结构和数据转化为RDF 形式,具体操作如图5所示。
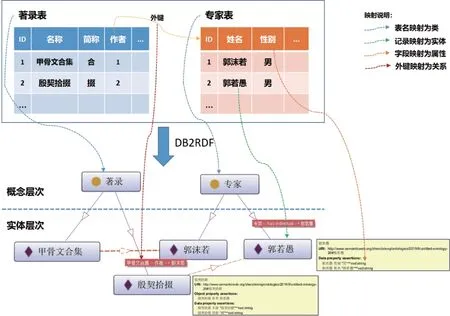
图5 数据库到RDF 的映射Fig.5 DB2RDF mapping
基于图5 的映射思路,以甲骨文著录数据库为例,获取的实体和关系如图6 所示。
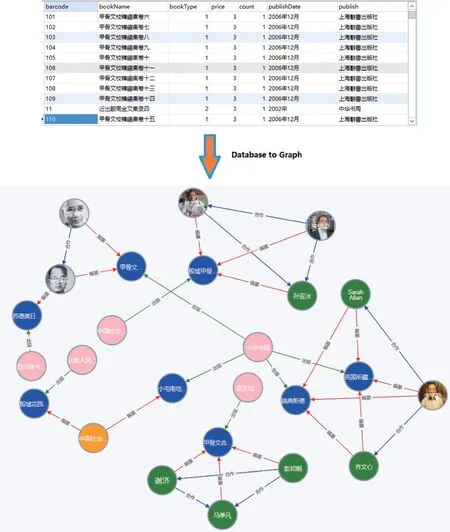
图6 基于数据库的实体和关系抽取Fig.6 Entity and relation extraction based on database
图6 中,绿色节点表示甲骨文专家(若有专家头像,则以头像方式显示),蓝色节点表示甲骨文著录,粉色节点表示出版机构,节点之间的连线表示关系。可以看出,该图谱可以完整地展示著录数据库所描述的信息。通过数据库模式,可得到实体和实体之间的关系,如〈专家,编纂,著录〉〈研究机构,编纂,著录〉〈出版社,出版,著录〉〈专家,合作,专家〉等。而且,相较针对关联关系复杂的查询,基于知识图谱的查询效率要远高于关系数据库查询。
2.2.3 基于文本的实体发现与关系抽取
这里的甲骨文文本是指除甲骨文文献、甲骨文语料库之外的涉及甲骨文知识的文本,如网页文本、电子版笔记等。从这些非结构化文本中抽取关系具有极大的挑战性。目前,基于深度学习的实体关系抽取技术超过了传统的基于特征和核函数的方法[38],并涌现出一批重要成果。如基于递归神经网络的关系抽取[39]、基于卷积神经网络的关系抽取[40-42]、基于端到端神经网络的关系抽取[43]、基于注意力机制的关系抽取[44-45]、弱监督残差网络关系抽取[46]等。但是,目前甲骨学研究尚需强依赖于专家知识,且缺乏可行的标注语料或数据集,深度学习的优势无法凸显。因此,利用依存句法分析结合甲骨学领域知识实现基于文本的实体发现和关系抽取,并采用哈工大社会计算与信息检索研究中心研制的语言技术平台(LTP[47])作为依存句法分析工具,将依存句法分析与甲骨学领域知识相结合,抽取出三元组。例如,由文本“对商代甲骨的分期断代研究,有多种说法,如今主要采用的是董作宾依据世系、称谓、贞人等十项标准划分的五期说,即第一期:盘庚、小辛、小乙、武丁,第二期:祖庚、祖甲,第三期:廪辛、康丁,第四期:武乙、文丁,第五期:帝乙、帝辛。”得到的依存句法树片段及抽取的实体和关系如图7所示。
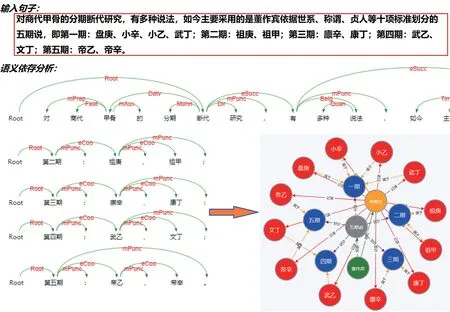
图7 基于依存句法和领域知识的实体和关系抽取Fig.7 Entity and relation extraction based on dependency syntax and domain knowledge
2.2.4 基于语料库的实体发现与关系抽取
甲骨学的研究对象以甲骨文为主,因此分析甲骨文语料库相关元素之间的关系显得尤为重要。本文从甲骨文的研究需求角度进行分析,基于甲骨文语料库实现甲骨学KG 的实体发现与关系抽取。
甲骨学研究的基本要求是释读甲骨片,因此,甲骨学著录是第一手资料。甲骨片的著录形式一般有照片、拓片、摹本,其中以甲骨拓片为主要形式,而且,同一张甲骨片可能会在不同的著录中收录,其收录编号也不一致。所以,明确某一张拓片出自何种著录至关重要。于是,甲骨片与著录之间的关系可以表示为〈甲骨片,收录于,著录〉,见图8(a)。
构建甲骨字网络可以为甲骨学中的语义挖掘及考释线索找寻提供有益的帮助,因此,需要将甲骨片上的单个甲骨字分离出来,从而获得甲骨字和甲骨片的关系,表示为〈甲骨字,出现于,甲骨片〉。见图8(b)。
异体字多是甲骨文的一个突出的特点。异体字对甲骨文字识别、考释、分期断代、字库建设、图像检索、数字化出版等有较大影响。从众多的异体字中找出一个代表字(作为“字头”)可以方便后续的甲骨学研究。因此,甲骨字之间存在异体字关系,表示为〈甲骨字(字头),异体字,甲骨字〉,见图8(c)。
可见,甲骨字(字头)与甲骨字之间存在异体字关系,而该关系指向的甲骨字节点又是截取自某一甲骨片,因此,该甲骨字与甲骨片间必然存在“出现于”关系。多方结合可得到“甲骨字-甲骨片-著录综合图谱”,见图8(d)。

图8 基于语料库的实体和关系抽取Fig.8 Entity and relation extraction based on corpus
从8(d)中可以看出,同一片甲骨上某个甲骨字可能以异体字形式出现多次,这也体现了甲骨文异体字繁多、出现频率高的特点。因此,知识图谱可以很好地表示甲骨学领域知识。
基于语料库进行实体和关系抽取的一个关键问题是如何从海量的甲骨图片中自动检测出甲骨字。笔者利用深度学习方法,基于9 500 张定位标注的甲骨片,参考YOLOv3 方法实现了甲骨片上甲骨字的自动检测,其准确率、召回率和F 值分别为77.6%,78.4%,78%,检测效果如图9 所示。

图9 甲骨字的自动检测Fig.9 Automatic detection of OBI characters
2.3 MKD 和KG 知 识 图 谱 融 合
构建甲骨学MKD 和KG 时,分别从异构数据源中获取了大量实体和关系,将这两种知识图谱进行融合,需要考虑实体对齐和关系融合两个关键问题。
2.3.1 实体对齐
实体对齐也称为实体匹配或实体解析,是判断相同或不同数据集中的两个实体是否指向真实世界同一对象的过程[48]。甲骨学中存在各类等价实体。如“文武丁”和“文丁”指的是同一位商王;“艾兰”和“Sarah Allan”指的是同一学者;当某一甲骨片被收录进不同的著录时,其甲骨片编号往往是不同的,如《甲骨文合集补编》中第b00008 片与《东京大学东洋文化研究所藏甲骨文字》中第d00123 片是同一片甲骨;“Oracle Bone Collections in the United States”与“美国所藏甲骨录”指的是同一著录。
由于甲骨学的专业性很强,甲骨学知识图谱中等价实体大部分需要利用甲骨学知识进行判定。如果实体对〈e1,e2〉在甲骨文文本中被记录为“=”(如图10(a)所示[49]),或在数据库中有相应字段(如图10(b)所示),或在本体中标记为“isSame”关系(如图10(c)所示),则这些实体对在相同或不同数据集中出现时,直接判定为等价实体。
对无法直接判定为等价实体的,需要通过实体相似度计算来判定。本文采用文献[50]的方法,通过综合HowNet 与同义词词林的词语语义相似度计算方法实现等价实体的判定。针对甲骨学领域的专业知识,还需要基于“甲骨文知网(OBIHowNet)[33]”进行语义相似度计算。
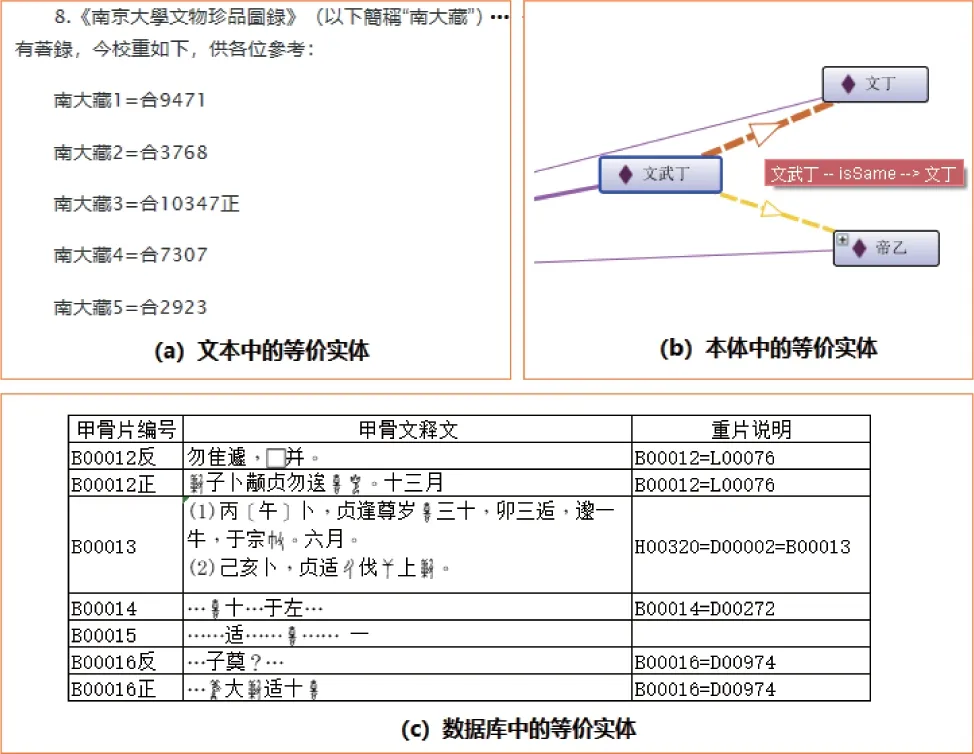
图10 各类数据源中的等价实体Fig.10 Equivalent entities in various data sources
2.3.2 关系融合
关系融合的关键在于确定两个实体是否表达同一种关系,是否是包含关系等[51]。甲骨学知识图谱的关系融合主要考虑等价类关系和subClassOf 关系。关系融合示例如表1 所示。
同时,也要优化投入要素的比例,根据城市的具体状况、旅游资源、适当的调整资金、劳动力、基础建设、交通建设等要素的投入比例,进而实现城市旅游的高效发展、协调发展以及可持续发展。

表1 关系融合示例Table 1 Examples of relation fusion
经过实体对齐和关系融合后,得到的甲骨学融合知识图谱如图11 所示。该融合知识图谱包括甲骨文专家学者、著录、研究机构、出版机构、甲骨片、甲骨字、甲骨文常识等知识实体和关联关系。
3 基于知识推理的甲骨学知识图谱扩展
将MKD 和KG 两类知识图谱进行融合得到的MKD-KG 融合图谱包含大量实体和关系,已经构成一个庞大的知识网络。但这些实体和关系均是从各种知识源中直接获取的显式元素,无法较好地满足甲骨学研究的知识推理需求。因此,挖掘显式的实体和关系背后隐藏的潜在实体和关系,对甲骨学知识图谱进行扩展是一项重要工作。本文从本体推理和规则推理两方面实现隐含语义关系的挖掘,从而丰富甲骨学知识图谱。
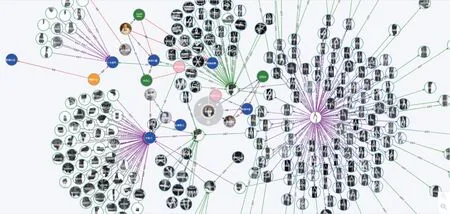
图11 甲骨学MKD-KG 融合图谱Fig.11 OBS fusion knowledge graph based on MKD and KG
3.1 基于本体的推理
利用甲骨文本体中已定义的关系(既有kindof,instance-of,property-of,part-of,equivalence 等通用关系,也有甲骨学领域涉及的商王世系、占卜事件、地理位置、时间空间等复杂的语义关系)和公理进行推理,还可充分利用关系的传递性、自反性等进行推理[2]。基于本体关系的推理可参见文献[52]。将本体关系与甲骨学MKD 共词关系进行融合,可发现新的实体和关系,相关内容可参见文献[2]。
3.2 基于规则的推理
基于规则的推理需要在甲骨文专家的指导下书写相应的规则来弥补本体无法直接完成的推理,如甲骨学领域涉及的因果关系、甲骨字考释、甲骨文分期断代、残辞拟补等。现以一则简单示例说明基于规则的推理。
定义以下2 条规则:
规则1贞人为商王占卜(用divinateFor 表示占卜关系),因此是商王的臣子(用serveFor 表示臣子关系)。
上述规则形式化表示为:
Rule1:OBI:serveFor(X,Y) :- OBI:divinateFor(X,Y)。
Rule2:OBI:colleague(X,Z) :- OBI:serveFor(X,Y), OBI:serveFor(Z,Y)。
假设存在3 条事实:“内”是商王“武丁”的贞人;“师般”是商王“武丁”的近臣;“禽”是商王“武丁”的大将。基于上述规则可以推理出更多的事实,如“内”与“师般”“禽”是同僚关系等。其推理前后统计对比如图12 所示。
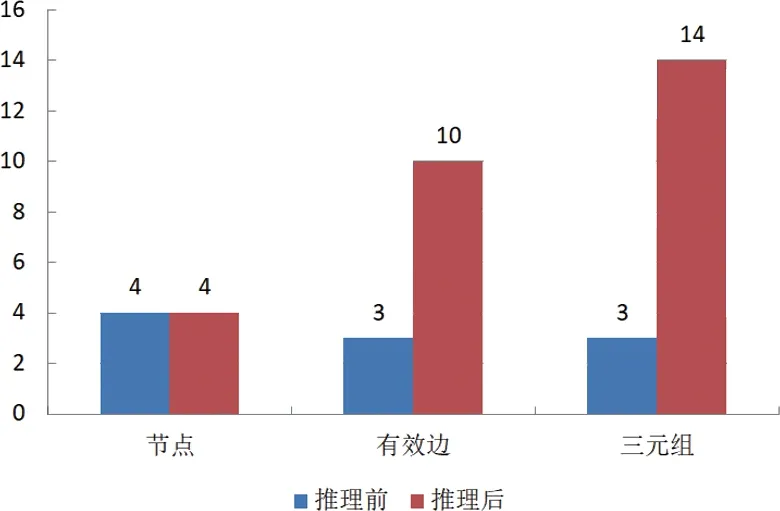
图12 推理前后统计对比Fig.12 Comparison of rule-based knowledge reasoning
推理前后的关系对比如图13 所示(图中去除了节点的自身关联,即只保留图12 中所述的有效边)。
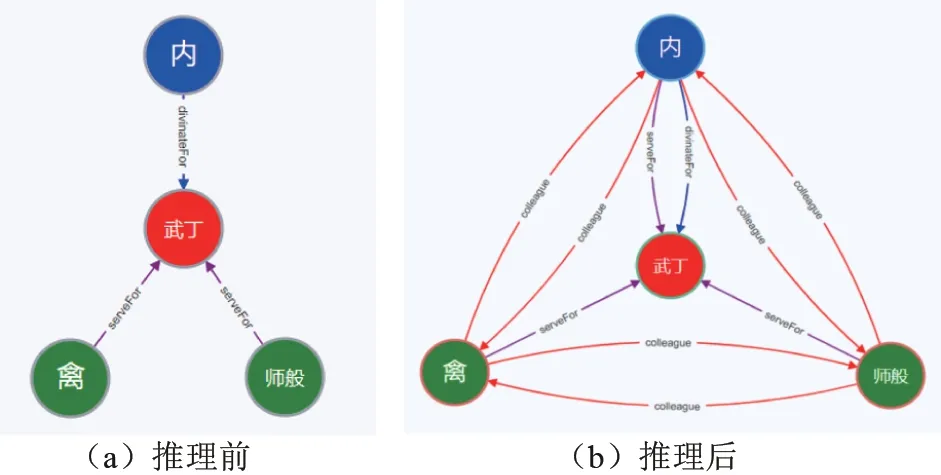
图13 推理前后的关系对比Fig.13 The relation comparison before and after knowledge reasoning
经过知识推理获取的隐含的语义关系以及新发现的实体,可以扩充和丰富MKD-KG 融合图谱,从而形成最终的甲骨学知识图谱。目前构建的甲骨学知识图谱规模包含实体148 305 个,关系434 032条,可满足甲骨学研究的基本要求。
4 实验及分析
为验证上述实体及关系抽取方法,笔者进行了相关实验。实验分别针对各类甲骨文数据源,采取准确率(precision)、召回率(recall)、F 值(f-measure)进行评价。由于缺乏甲骨文领域的评价数据集,因此,实体抽取及关系抽取的正确性由人工确定,实验结果如表2 所示。
表2 中,基于甲骨语料的关系抽取达到最高评价值,其原因是在该关系抽取过程中必须依赖甲骨文专家人工干预,如异体字的识别与归类、异体字与字头的关系等。实验分析如下:
(1)关系抽取的难度大于实体抽取;
(2)基于结构化数据的实体抽取和关系抽取质量明显高于非结构化数据;
(3)基于文本的甲骨文实体抽取和关系抽取依赖于依存句法的分析质量。因此,有必要开展针对甲骨文领域的依存句法分析的专门研究;
(4)甲骨文字的检测与识别效果直接影响甲骨语料的信息抽取质量。

表2 实验结果Table 2 The experimental results
5 结 论
甲骨学知识图谱是由MKD 和KG 两类图谱融合而成的。在分别介绍甲骨学MKD 和甲骨学KG的构建方法基础上,通过实体对齐、关系融合和知识推理得到最终的甲骨学知识图谱。尽管目前构建的甲骨学知识图谱已初具规模,但仍面临一些问题。如甲骨学MKD 是基于文献元数据信息构建的,并没有考虑文献全文,因此,文本中的大量实体和关系并没有抽取出来;甲骨学文献中存在较多图文混编情况,目前还无法实现甲骨字的有效图像检索;甲骨学文献还存在大量的手写版本,对这些手写文献尚缺乏准确率高的识别方法。这些均影响实体的抽取和关系的挖掘。针对甲骨学KG,目前仅关注与甲骨文字有关的知识实体和实体关系,尚未对金文、战国文字、简帛文字等相关古文字进行较大规模的知识图谱构建;另外,甲骨文考古知识和甲骨文缀合方面的知识也未系统加入目前的知识图谱中;甲骨文依存句法分析工作也有待研究。下一步,将针对这些问题进行更加深入的研究。
