基于深度学习与稀疏光流的人群异常行为识别
2020-04-20罗凡波梁思源徐桂菲
罗凡波,王 平,梁思源,徐桂菲,王 伟
(西华大学 电气与电子信息学院,成都 610039)
0 概述
目前,国内外学者在人群异常行为检测方面做了许多研究工作,其大致可分为基于低级视觉物征和基于粒子流两个方面[1]。基于低级视觉特征提取的方法先使用计算机视觉领域的技术提取人群图像的低级特征,再利用分类器进行异常检测[2]。文献[3]提出基于全局光流法获取方向直方图,通过直方图来表现人群异常,文献[4]提出使用Lucas-Kanande光流法计算人群速度与运动方向特征,通过SVM进行训练分类判断异常行为;也有学者使用基于光流和灰度值的协方差矩阵进行异常行为检测[5]。基于低级视觉进行的特征提取能从数据上直观反映人群的运动状态,但是所提取的运动信息单一,提取特征的过程耗时较多,使得实时性与准确性不高,传统的支持向量机同样具有训练效率低、耗时、数据处理能力有限等问题[6]。基于粒子流方法分析人群行为,假定人受长期外作用力进行运动,再计算相互作用力,设定阈值来检测类似人群异常,其中的典型代表是社会力模型(SFM)[7],文献[8]提出融合显著性信息和社会力模型获得相互作用力直方图进行异常判断。但社会力模型建立较复杂,计算量较大,对监控实时性要求无法满足。
近年来,深度学习的快速发展使机器学习取得了长足进步,具有代表性的模型有卷积神经网络(CNN)与YOLO;CNN与YOLO在图像检测与识别领域已经取得了明显的效果。文献[9]利用卷积神经网络进行车牌图像超分辨率识别;文献[10]使用选择性数据采样快速卷积神经网络训练,进行彩色眼底图像出血检测;文献[11]提出基于YOLO网络的行人检测方法;文献[12]提出基于YOLO模型的车辆实时检测。
现有的人群异常检测方法多数是检测人群突然奔跑的大规模异常,但未考虑引起这种群体异常的诱因。为此,本文提出一种基于YOLO_v3与稀疏光流的人群异常行为识别与定位方法。将监控图像划分为多个子图像,以便于异常定位,对引起群体异常的诱因进行检测,通过改进YOLO_v3神经网络搭建适用于检测此类异常的模型。针对突散异常,使用稀疏光流法获取人群平均动能以及人群运动方向熵,将得到的特征数据输入PSO-ELM进行分类,区分正常行为与突散异常行为。
1 基于YOLO_v3的诱因检测模型
本文人群异常行为检测流程如图1所示。在YOLO之前的物体检测方法主要是通过候选区域产生的大量可能包含待检测物体的potentialboundingbox,接着使用分类器去判断每个potentialboundingbox是否包含物体,以及物体所属类别的probability或confidence。YOLO不同于这些网络的方法,它将物体检测当做一个回归问题来处理,使用一个神经网络,将整张图作为网络的输入,直接在输出层回归boundingbox的位置和boundingbox所属的类别。YOLO作为当前最优秀的目标检测网络之一,其实时处理图像速度可达到45 frame/s。

图1 异常检测流程Fig.1 Anomaly detection procedure
1.1 YOLO_v3网络
YOLO_v3[13]将输入图像划分为S×S的栅格,每个栅格负责落在该栅格中的物体。每一个栅格预测B个boundingbox及其置信分数(confidencescore),置信分数反映了模型对于这个栅格的预测,即该栅格是否含有物体以及这个box预测的准确性。confidence定义如下:
(1)
(2)

在预测时,每个候选框的分类置信分数为预测目标的类别概率和boundingbox预测的confidence相乘,即:
(3)
得到每个分类置信分数之后,设置阈值将得分低的boxes筛除掉,即得到最终的检测结果。
YOLO_v3的boundingbox的坐标预测方式延续了YOLO_v2的做法,坐标的损失采用的是平方误差损失。其类别预测方面主要是将原来的单标签分类改为多标签分类,因此网络结构上就将原来用于单标签多分类的softmax层换成用于多标签多分类的逻辑回归层。
YOLO_v3采用多个scale融合的方式预测,在多个scale的feature map上进行检测,对于小目标的检测效果提升比较明显。
YOLO_v3的boundingbox初始尺寸采用YOLO_v2中的k-means聚类方式,这种先验知识对于boundingbox的初始化有较多优点,对算法的速度有一定提高。
YOLO_v3的网络结构是darknet-53,一方面基本采用全卷积,另一方面引入了residual结构,得益于此结构,训练网络难度大大减小,因此YOLO_v3将网络进行到53层,精度提升较为明显。
1.2 基于YOLO_v3小团体异常检测框架
基于YOLO_v3的小团体异常行为检测网络框架如图2所示。首先将数据集中训练集图片调整为416×416×3的标准jpg图片,将darknet-53中53个卷积层和21个池化层作为YOLO_v3进行行人行为特征提取的主要网络结构,75层到105层作为网络的特征交互层,输出featuremap,在此进行行人异常种类分类和位置回归。YOLO_v3行人异常行为检测的基本流程如下:
1)将待检测图像输入检测模型,得到13像素×13像素×30像素行为特征点的特征图。
2)13像素×13像素一共形成169个网格,每个网格预测6个边框,每个边框共有6类信息,其中1维图像类别信息(持械与否、面部遮挡与否),1维边框置信度和4维坐标信息,获得1个36维向量,即为最后得到的36个通道。
3)将前面预测到的13×13×6个目标边框,先通过预先设定的阈值去除掉小概率的目标边框,再使用非极大值抑制去除多余的预测边框。该步骤预测边框的选取主要通过式(1)~式(3)来进行计算,并获得最优的预测边框。
从整个行人异常行为的检测过程中可以看出,本文使用的YOLO_v3行人异常行为检测框架不再需要通过候选区域寻找指定的目标,而是直接使用回归思想来进行位置确定与异常行为类别的判断。也正是这一原因,使得其检测速度获得了极大提高,能满足当前监控系统的实时性要求。

图2 YOLO_v3异常行为检测框架Fig.2 YOLO_v3 abnormal behavior detection framework
2 训练阶段
在训练阶段,由于电脑显卡内存与电脑内存都较小,因此采用小批量随机梯度下降法,每64个样本更新一次权重参数。为防止训练过程中产生数据量过大,内存不足,经多次实验后得到每个batch=64,subdivision=16,即每次训练4张图片,总共迭代次数为20 000次。
2.1 YOLO_v3异常检测模型的训练参数
为使本文YOLO_v3检测网络对不同尺寸的图像始终有较好的适应性,在训练方法上使用多图像尺寸进行训练,在训练中每隔5轮随机抽取新的图像尺寸送入网络进行训练,使得该网络对不同分辨率的人群图像具有较好的适应性,能维持一个较高水平的检测准确率。本文训练类别为五类,分别为行人(person)、持棍(club)、面部遮挡(shelter)、持枪(gun)、持刀(knife)等5个类别,训练参数设置如表1所示。

表1 训练参数设置Table 1 Training parameter settings
2.2 数据扩充
在大多数情况下人群行为都是正常的,异常行为较少发生,且发生时间较短,故异常行为的训练数据较少,但对于深度神经网络来说需要大量的训练数据支持,在现有的公开数据集中,异常行为的样本数据较少,所以需要使用数据扩充方法来增加异常行为的数据量。
图像的二维特征[14],如亮度、对比度、噪声等对于人群的行为是没有影响的,因此针对本文训练数据不足的问题,通过增加亮度、降低亮度、提高对比度、降低对比度、添加椒盐噪声、添加高斯噪声等手段,对训练样本进行数据扩充,使目前异常行为的数据量变为原来的数倍。利用上述手段改变每一帧图像信息,既增加了样本多样性,也保留了原图像中行人的行为特征,减小了正常样本与异常样本的数量差异。
3 改进的稀疏光流法
本文通过改进的稀疏光流法获取光流信息,得到速度大小、加速度大小、运动方向等特征值,进而计算人群平均动能与人群运动方向熵。
3.1 稀疏光流原理
光流法[15]的使用要具备一定的条件,一是在监控视频中,相邻帧之间的亮度保持一致,二是前景运动速度相较帧速率不能过快,三是相邻点某一邻域内所有像素点的速度相等,即:
F(x,y,t)=F(x+Δx,y+Δy,t+Δt)
(4)
由泰勒函数展开F(x,y,t)得到:
fxu+fyv+ft=0
(5)
对于v的估计,在邻域Ω内求取加权平方和最小化得到:
(6)
其中,W(x)是一种权重函数,该函数使Ω邻域中心像素点的加权比周围的像素点大,本文权重函数使用平滑高斯核函数。
根据L-K的使用条件,定义Ec为光流约束因子,Es为平滑约束因子:

(7)
(8)
求解的目标光流即是使式(7)和式(8)中因子最小,即目标函数E最小化:
(9)
其中,λ是Es、Ec的相对权重,其与噪声强度有关,本文选取一个适中值λ=0.5,设:
w=(u,v,1)T
JP(3p)=W(x)·(3p·3pT)
(10)
其中,w表示在t时刻像素(x,y)处的速度梯度,3p表示强度梯度。
故式(6)可转化为:
Emin=wT·Jp(3p)·w
(11)
得出改进光流模型:
(12)
接下来可求出:
(13)
θ=arctan(vy/vx)
(14)
3.2 动能与方向熵计算
平均动能定义如下:
(15)
其中,N表示在一帧图像中所有的运动矢量,即特征点个数,mi表示质量权重,为方便计算,设定每个个体质量权重都为1,vi表示运动矢量的速度大小。
运动方向熵的计算如下:
1)运动方向角度:
Di=arctan(y/x)+π
(16)
将运动方向在[0,2π]上划分为8个运动区间方向,每间隔π/4作为一个运动区间,定义方向直方图:
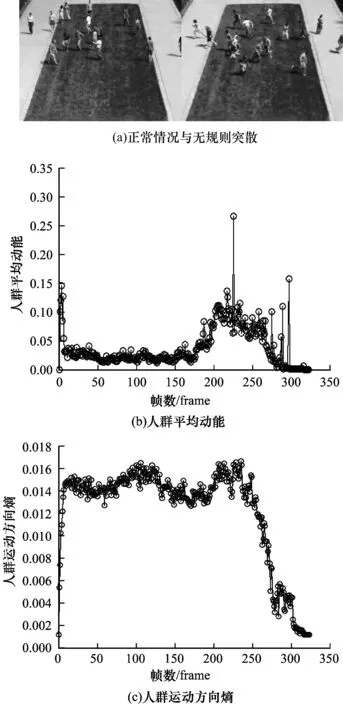
hi={ki;0 (17) 其中,ki表示每一帧第i区间所包含的运动矢量数目。 2)概率分布计算: Pi=h(i)/N;0 (18) 3)方向熵计算: (19) 由于行人特征点较多,为降低运算复杂度,本文采用等距采样法进行特征点的选取,在计算过程中不用逐帧进行计算,本文借鉴帧差法思想,使用间隔5 frame计算一次,实验结果证明,该方法提高了运行速度,且也不会对异常分类造成影响。 极限学习机(ELM)是由文献[16]提出的求解单隐层神经网络的算法。ELM最显著的优点是求解单隐层前馈神经网络时,在保证学习精度的前提下其学习速度比传统方法快得多;在算法中,输入层与隐含层的连接权值与隐含层神经元阈值使用rand函数生成,训练过程中无需人为手动调整,只需进行隐含层神经元个数设置就能获得唯一最优解。本文针对两组测试数据,选取的隐含层神经元个数分别为315个和305个。为能更好更快地找到最优的连接权值与神经元阈值,使用粒子群优化算法(PSO)进行参数寻优。 粒子群算法[17]思想来源于鸟群的捕食行为,鸟群中的个体用无质量的粒子模拟,粒子具有速度V和位置X两个属性,速度代表搜索参数的快慢,位置代表搜索参数移动的方向。粒子在规定的区间内单独进行最优解搜寻,并将获得的最优解记为当前个体极值Pbest,并将其分享给其他粒子,找到最优个体极值作为当前整个粒子群体全局最优解Gbest;将所有粒子与全局最优解进行比较,进而调整自己的V和X。使用PSO优化ELM[19]后能得到更好的分类效果。本文使用的速度V的初始化范围为(-1,1);位置X的初始化范围为(-1,1);粒子群个数N为100。对于PSO-ELM通过下面步骤训练测试。 1)训练集:给定Q个不同样本(xi,ti)。其中,xi=[xi1,xi2,…,xin]T,ti=[ti1]。xi为上述特征组合;ti为一个标签,表示目标属于哪一类人群,即正常或异常。 3)将提取的测试集特征送入训练好的模型中,实现突散异常检测。 算法步骤如下: 1)针对两组测试集,本文隐含层神经元个数设置为315个和305个,对ELM分类器使用PSO进行连接权值与神经元阈值寻优。 2)本文激活函数选取S函数,计算隐含层输出矩阵H。 相关实验结果表明[18],在激活函数选取中,不仅可使用非线性激活函数分类非线性样本,还可用线性激活函数分类非线性样本,能够获得较好的效果。根据多次实验,本文使用S型函数作为激活函数能获得较好的分类效果,隐含层神经元个数根据样本集的变化而做出改变,能获得较好的分类精度。 本文监控系统是在普通PC机(CPU为8700K,3.70 GHz,8.00 GB内存,显卡为GTX1080,8 GB)上搭建,YOLO_v3部分在Windows CMD环境下进行训练与测试,对稀疏光流与PSO-ELM部分是在MATLAB2014a编程环境下完成的;在数据集方面对持械异常使用INRIA,UCF101进行可行性实验,然后在拍摄的视频数据集中仿真,对突散异常使用UMN的数据集。在实验前先将视频分为多个子区域进行测试,方便对异常进行定位。 YOLO_v3检测模型仿真结果如图3所示,从图中可以看出,通过本文的人群异常检测模型能很准确检测出人群中持棍斗殴伤人异常、面部遮挡异常、持枪异常、持刀斗殴伤人异常。这几类异常是传统异常检测模型无法准确检测到的,传统模型大多只能检测单一的人群突然奔跑异常,且一旦监控场景改变,对检测结果具有较大影响,造成极高的漏检率,本文的模型对各个监控场景都具有很强的鲁棒性,能很好地适用于多监控环境。本文模型的实时性完全能满足社会生活监控的需要,在硬件设备达到要求时,能实时处理45 frame/s,随着时间的推移,还会进一步上升。 图3 异常检测效果Fig.3 Effect of anomaly detection 本文仿真每轮迭代从处理后的训练集中随机抽batch=64个样本进行训练,由于本次实验采用的显卡为8 GB显存,为了减轻内存占用压力,每轮的64个样本又被均分为subdivision=16次送入网络参与训练。最终经过20 000次的迭代,损失值最后保持在0.078 4左右,平均交并比达到85%左右,如图4所示。 图4 训练20 000次的loss值变化示意图Fig.4 Loss value change diagram of 20 000 training times 对UMN数据集进行无规则突散分析,视频共323 frame,隐含层神经元个数为315个,分类结果显示从193 frame开始,群体由无规则行走变为无规则突散,仿真结果如图5所示。 图5 无规则突散仿真效果Fig.5 Simulation effect of irregular spur 在突散异常发生之前,人群为正常行走,如图5(a)所示,其平均动能都较小,但到190多帧时,人群平均动能突然增大,然后到260多帧急剧下降。如图5(b)所示,说明在190多帧时发生了突散奔跑异常,随着人群不断跑出监控区域,人群动能不断下降,直到所有人都走出监控区域,动能变为0;对于运动方向,如图5(c)所示,由于异常发生之前人群就在无规则行走,异常发生后也是无规则突散,因此异常前后人群运动方向熵变化不明显,直到所有人走出监控区域,方向熵降为0。 对于UMN数据集进行同方向突散分析,视频共338 frame,设置隐含层神经元个数为305,分类结果显示在270 frame左右发生同向突散异常,仿真结果如图6所示。 图6 同向突散仿真效果Fig.6 Simulating effect of co-directional spur 在突散异常发生之前,人群正常无规则行走,如图6(a)所示,其平均动能有一些波动是因为人群遮挡引起的,检测出的人数变化对其有一定影响,但到270 frame左右时,人群平均动能突然增大,然后到290 frame左右急剧下降,如6(b)所示,说明在270多帧时发生了突散奔跑异常,随着人群不断跑出监控区域,人群动能不断下降,直到所有人都走出监控区域,动能变为0;对于运动方向,如图6(c)所示,由于异常发生之前人群就在无规则行走,异常发生后发生的是同方向突散,因此异常前后人群运动方向熵变化较为明显,直到所有人走出监控区域,方向熵急剧下降,但后面有回升是因为监控区域又有人进入。 PSO-ELM分类结果如图7所示,其与传统异常行为检测方法准确率比较见表2。其中,图7(a)对应315个隐藏层神经元,图7(b)对应305个隐藏层神经元。 图7 PSO-ELM分类效果Fig.7 PSO-ELM classification effect 表2 PSO-ELM突散异常分类准确率Table 2 Classification accuracy rate of PSO-ELM spuranomalies 本文提出一种基于YOLO_v3与稀疏光流的人群异常行为识别与定位方法。首先将监控图像划分为多个子图像,以便于异常定位,然后对引起群体异常的诱因进行检测,并针对训练数据不足的问题,采用数据扩充的方法增加训练数据。使用稀疏光流法获取人群平均动能与人群运动方向熵,将得到的特征数据送入PSO-ELM进行分类,区分正常行为与突散异常行为。实验结果表明,本文方法能够为应对人群异常采取相应应急措施提供更多时间,可有效检测持械异常与面部遮挡异常,并且能准确定位异常区域,具有较高的检测准确率。下一步研究将增加一些异常种类[19],将突散异常检测功能整合到YOLO_v3异常检测模型中,使修改后的网络能较好地检测突散等异常行为。4 粒子群优化极限学习机算法
4.1 PSO-ELM算法

4.2 算法步骤
5 实验结果与分析
5.1 YOLO_v3异常行为检测模型仿真结果


5.2 MATLAB仿真结果



6 结束语
