基于血清四项肿瘤标志物的模式识别技术对肺癌的鉴别诊断
2020-04-18田刚张章刘靳波曾章锐舒静周明术李光荣
田刚 张章 刘靳波 曾章锐 舒静 周明术 李光荣
西南医科大学附属医院医学检验部(四川泸州646000)
肺癌是严重威胁人类健康的疾病,2018年全球新发肺癌患者近210万,其中176.6万死亡[1]。根据我国癌症中心2016年公布的数据,肺癌在我国的发病率和病死率均居首位[2]。吸烟、乙肝病毒感染,基因和环境以及衰老等因素都与肺癌的发生、发展相关[3-4]。临床上,近70%的肺癌患者确诊时已处于中、晚期,失去了最佳治疗时机,故早期诊断并及时治疗至关重要[5]。近年来,正电子发射计算机断层显像(positron emission tomogra⁃phy⁃computerized tomography,PET⁃CT)和核磁共振成像(magnetic resonance imaging,MRI)等技术也被用于肺癌的鉴别诊断,但较昂贵的检查费用限制了临床的广泛应用[5]。血清肿瘤标志物如癌胚抗原(carcino⁃embryonic antigen,CEA)、神经元特异性烯醇化酶(neuro specific enolase,NSE)、糖类抗原(carbohydrate antigen,CA125)和细胞角蛋白片段19(cyfra21⁃1)是临床常用的肺癌辅助诊断指标,但单项指标的灵敏度或特异度欠佳,而常用的串联或并联诊断模式牺牲了灵敏度或特异度,且较难对患者进行预测分析[6-7]。因此,寻找新颖的数据处理和疾病诊断、预测模型有助于挖掘更多有用的数据信息,给临床医生提供辅助诊断建议。近年来,决策树、判别分析和人工神经网络等模型已用于肺癌的鉴别诊断,为肿瘤标志物的临床应用提供了一种模式诊断新思路[8⁃10]。本研究拟采用三种模式识别技术—偏最小二乘判别分析(par⁃tial least squares⁃discrimination,PLS⁃DA),多层感知器⁃人工神经网络(multiplayer⁃artificial neural net⁃work,MPL⁃ANN)和支持向量机(support vector ma⁃chine,SVM)构建肺癌诊断和预测模型,对肺癌相关肿瘤标志物与肺癌、肺部良性疾病的相关性及诊断、预测价值进行深入研究。
1 资料与方法
1.1 一般资料 纳入2010年1月19日至2014年3月7日西南医科大学附属医院470例肺癌患者(肺癌组),其中男357例,女113例,年龄18~99岁,平均年龄(61.0±13.7)岁。其中鳞癌168例,腺癌207例,小细胞癌74例,未定型肺癌21例。本研究中肺癌患者均按照2007年世界肺癌大会“第7版肺癌患者综合分期评定标准”分类,包括Ⅰ期肺癌患者18例,Ⅱ期94例,Ⅰ-Ⅱ期140例,Ⅲ期48例,Ⅳ57例,Ⅲ-Ⅳ期50例,未知63例。早期患者(Ⅰ、Ⅱ及Ⅰ-Ⅱ期)、晚期患者(Ⅲ、Ⅳ及Ⅲ-Ⅳ)和未知分期肺癌患者的比例分别为53.6%、33.0%和13.4%。排除重复入院行放、化疗肺癌及临床资料不完整患者。肺部良性疾病患者659例(良性组),包括肺部感染102例,肺结核169例,肺炎113例,慢性阻塞性肺病170例,支气管哮喘105例,其中男453例,女206例,年龄12~94岁,平均年龄(61.4±14.7)岁。肺癌组和良性组患者经临床、组织病理学或影像学等确诊。另选取343例健康体检者为对照(对照组),年龄12~90岁,平均年龄(60.2±13.8)岁。对照组肝、肾功能和肿瘤标志物水平未见明显异常。3组年龄比较,差异无统计学意义(F=0.846,P=0.429)。由于本研究回顾性分析2010年1月~2014年3月本院住院患者临床数据,参照《体外诊断试剂临床研究指导原则》中“客观上不可能获得受试者知情同意或该临床研究对受试者几乎没有风险,可不提交伦理委员会的审评意见及受试者的知情同意书”进行[11]。
1.2 仪器与检测方法 所有患者在诊断、放疗或化疗前空腹静脉采血3~5 mL(避免溶血),标本采集后尽快送至检验部分离血清、检测。采用Roche全自动电化学发光仪(Elecsys 2010)及配套试剂盒,按标准操作规程在质控在控下检测血清CEA、NSE、CA125和Cyfra21⁃1水平。参照分析仪及试剂盒的参考范围制定血清CEA、NSE、CA125和Cy⁃fra21⁃1的参考区间,其中NSE为0~35.0 ng/mL,CEA为0~3.4 ng/mL,CA125为0~15.2 ng/mL,Cy⁃fra21⁃1为0~3.3 ng/mL。
1.3 训练和测试数据的选择 利用SPSS 25.0软件随机抽取70%样本为训练集,建立诊断模型(729例非肺癌患者、332例肺癌患者),30%为测试集(273例非肺癌患者、138例肺癌患者)用于预测分析,分别在MPL⁃ANN、SVM和PLS⁃DA模型中验证。
1.4 数据的标准化 血清CEA、NSE、CA125和Cyfra21⁃1经归一化处理[(测定值⁃均值)/标准差],以消除测定项目数量级和单位的差异,测定结果在[⁃1~1]之间。
1.5 统计学方法 采用SPSS 25.0软件对数据进行统计分析并建立MPL⁃ANN模型。3组年龄成正态分布,用均数±标准差表示,方差齐(F=2.422,P=0.089),3组比较采用单因素方差分析。血清CEA、NSE、CA125和Cyfra21⁃1水平呈偏态分布,以中位数M(P25,P75)表示,3组间两两比较采用Mann⁃WhineyU检验,校正P值,差异有统计学意义(P<0.017)。采用受试者工作特征曲线(receiver operating characteristic curve,ROC)下面积(area un⁃der the ROC,AUC)评估各指标的诊断效能,P<0.05差异有统计学意义。采用SIMCA 13.0软件构建PLS⁃DA模型,采用MATLAB(R 2019b)建立SVM模型。
2 结果
2.1 血清CEA、NSE、CA125和Cyfra21⁃1水平比较 与对照组比较,肺癌组和良性组血清CEA、NSE、CA125和Cyfra21⁃1水平均升高,差异有统计学意义(P<0.017)。肺癌组与良性组比较,血清CEA、NSE、CA125和Cyfra21⁃1水平也显著升高(P<0.017),见表1。

表1 3组血清CEA、NSE、CA125和Cyfra21⁃1水平比较Tab.1 Comparison of CEA,NSE,CA125 and cyfra21⁃1 levels in three groups [M(P25,P75)]
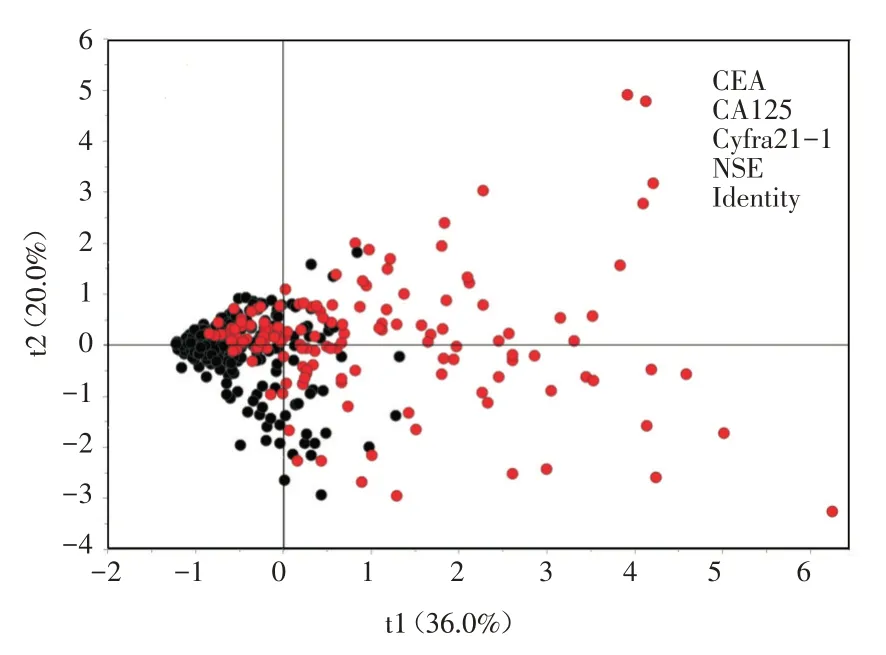
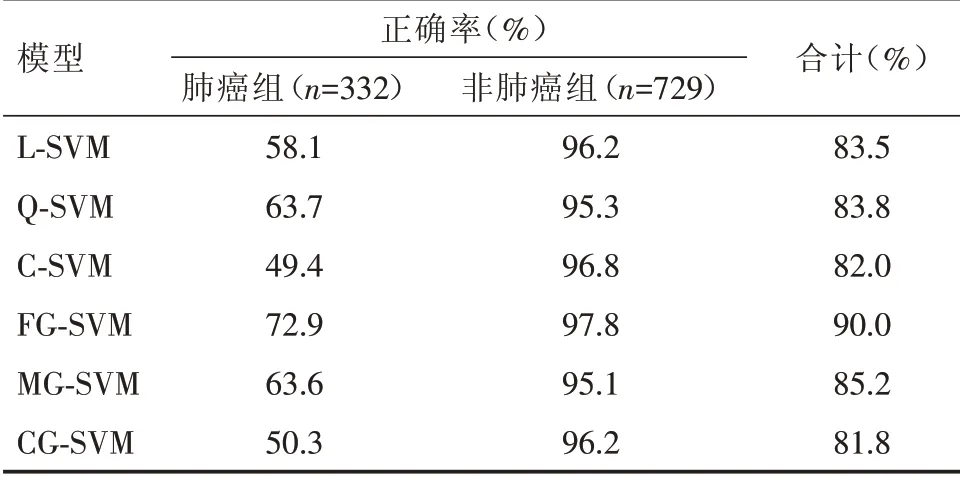
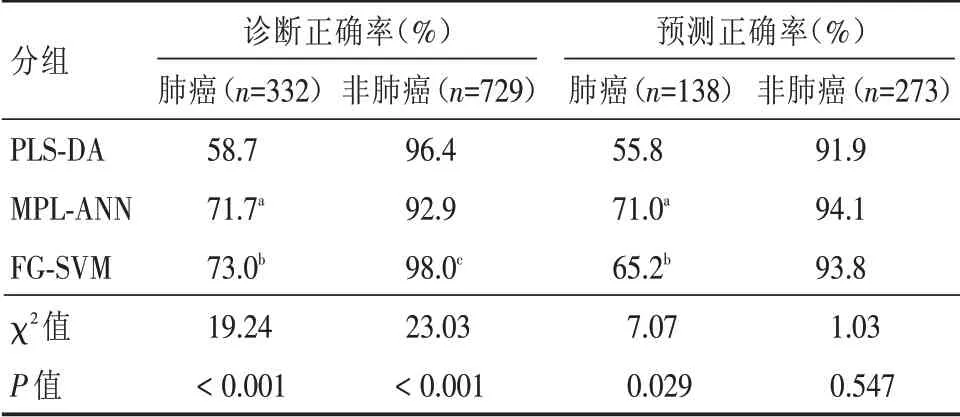
2.2 肺癌组、良性组和对照组血清四项指标的诊断效能比较 四项血清肿瘤标志物中CEA、NSE和Cyfra21⁃1对肺癌的诊断效能较高(AUC均>0.70),CA125的诊断效能较低0.50 图1 血清CEA、NSE、CA125和Cyfra21⁃1的ROC曲线Fig.1 ROC curves of CEA,NSE,CA125 and cyfra21⁃1 in serum 表2 3组血清CEA、NSE、CA125和Cyfra21⁃1的ROC曲线比较Tab.2 ROC curve comparison of serum CEA,NSE,CA125 and cyfra21⁃1 in three groups 2.3 基于血清CEA、NSE、CA125和Cyfra21⁃1的PLS⁃DA模型分析 以随机选取的70%患者的四项肿瘤标志物建立PLS⁃DA模型,并提取前两个PLS成分(即t1=29.5%和t2=14.9%),该模型对肺癌和非肺癌患者的诊断正确率分别为58.7%(195/332)和96.4%(703/729)。以另选取的273例非肺癌患者和138例肺癌患者进行预测,该模型的t1和t2分别为36.0%和20.1%,对肺癌和非肺癌患者的预测正确率分别为55.8%(77/138)和91.9%(251/273),见图2。 图2 基于血清CEA、NSE、CA125和Cyfra21⁃1的PLS⁃DA预测模型(肺癌组;非肺癌组)Fig.2 PLS⁃DA prediction model based on serum CEA,NSE,CA125 and cyfra21⁃1(lung cancer group;non⁃lung cancer group) 2.4 基于血清CEA、NSE、CA125和Cyfra21⁃1的MPL⁃ANN模型 以血清CEA、NSE、CA125和Cy⁃fra21⁃1建立MPL⁃ANN诊断模型,以概率值P>0.50判断为肺癌,反之为非肺癌。该模型的隐含层数为2,训练时间0:00:00:210,交叉熵错误率为5.90,对肺癌和非肺癌患者的诊断正确率分别为71.7%(238/332)和92.9%(677/729)。MPL⁃ANN预测模型的隐含层数2,训练时间为0:00:00:160,交叉熵错误率为4.93,对肺癌和非肺癌患者的预测正确率分别为71.0%(98/138)和94.1%(257/273),MPL⁃ANN预测模型见图3。 图3 基于血清CEA、NSE、CA125和Cyfra21⁃1的MPL⁃ANN预测模型Fig.3 MPL⁃ANN prediction model based on serum CEA,NSE,CA125 and cyfra21⁃1 2.5 基于血清CEA、NSE、CA125和Cyfra21⁃1的SVM模型分析 以血清四项肿瘤标志物依次建立线性核SVM(line SVM,L⁃SVM),二次核SVM(Quadratic SVM,Q⁃SVM),三 次 核SVM(Cubic SVM,C⁃SVM),精细高斯核SVM(Fine Gaussian SVM),中高斯核SVM(Medium Gaussian SVM,MG⁃SVM)和粗高斯核SVM(Coarse Gaussian SVM,C⁃SVM)6种模型。6种SVM模型对肺癌和非肺癌的总诊断正确率依次为FG⁃SVM(90.0%)>MG⁃SVM(85.2%)>L⁃SVM(84.8%)>Q⁃SVM(83.7%)>C⁃SVM(82.0%)>CG⁃SVM(81.8%),结果见表3。以诊断正确率最高的FG⁃SVM建立诊断模型,该模型对肺癌和非肺癌组的诊断正确率依次为72.9%(242/332)和97.8%(713/729)。以另选取138例肺癌和273例非肺癌患者进行预测,该模型对肺癌和非肺癌组的预测正确率分别为65.2%(90/138)和93.8%(256/273)。 2.6 MPL⁃ANN、PLS⁃DA和FG⁃SVM模型比较 基于血清CEA、NSE、CA125和Cyfra21⁃1的FG⁃SVM和MPL⁃ANN模型诊断肺癌患者的正确率均高于PLS⁃DA模型(P<0.05)。FG⁃SVM模型正确率最高,MPL⁃ANN模型最低,差异有统计学意义(P<0.05)。3种模型中MPL⁃ANN模型预测肺癌组和非肺癌组患者的准确率均最高,分别为71.0%和94.1%,MPL⁃ANN和FG⁃SVM模型预测肺癌患者的准确率均高于PLS⁃DA模型(P<0.05),见表4。 表3 基于血清CEA、NSE、CA125和Cyfra21⁃1的六种SVM模型比较Tab.3 Comparison of six SVM models based on serum CEA,NSE,CA125 and cyfra21⁃1 表4 基于血清CEA、NSE、CA125和Cyfra21⁃1的3种模型诊断和预测正确率比较Tab.4 Comparison of diagnosis and prediction accuracy of three models based on serum CEA,NSE,CA125 and cyfra21⁃1 血清肿瘤标志物是早期诊断肺癌的有效手段,具有简单、快速、创伤小且成本较低等优点,但目前尚无理想的肺癌标志物[12]。CEA是肺癌常用的肿瘤标志物,在肺癌的筛查、诊断、转移和疗效监测中扮演着重要角色[6]。Cyfra21⁃1是细胞角蛋白19片段,与鳞状细胞癌抗原、硫氧还蛋白联合检测有助于肺癌的诊断、转归和病理组织分型[13]。NSE是公认的小细胞肺癌较特异的标志物,有助于评估抗肿瘤药物对小细胞肺癌的治疗效果[14]。CA125在肺腺癌中的含量和阳性率均显著高于小细胞肺癌和肺鳞癌,有助于肺癌的病理分型和指导治疗[10,15]。本研究中,肺癌组患者血清CEA、NSE、CA125和Cyfra21⁃1水平均显著高于良性组和对照组,表明四项肿瘤标志物有助于肺癌的鉴别诊断,与马志红等[16]报道一致。本研究中,四项标志物的AUC均较低(0.578~0.796)且诊断肺癌的灵敏度也不理想(42.1%~61.5%),可能与研究中有较多早期肺癌患者(53.6%)有关。四项标志物的诊断效能均较低也提示单项指标辅助诊断肺癌效果较差,需联合检测提高肺癌诊断的正确率。 PLS⁃DA、MPL⁃ANN和SVM模型是多维数据分析中常用的有监督模式识别技术。该技术与多指标联合检测的主成分分析或因子分析相比,最大的优点是能综合多指标进行诊断和预测分析,避免单一指标绝对值增加或降低对临床的误导、使结论更科学、合理[15]。ANN以大脑神经元的活动规律为背景,通过抽象、简化和模仿人脑的某些特征提高分析、处理数据信息的效率,有助于解决肺癌精准医学发展遇到的问题[18]。MPL⁃ANN相对于单层感知器不仅能很好地处理线性问题,还能处理非线性可分离问题,在肺癌的鉴别诊断中显示了一定的应用潜力。前期研究表明,MPL⁃ANN模型对肺癌有较好的诊断准确率(80.7%,100/124)和预测准确率(82.3%,102/124)[19]。NARESH等[20]采用ANN模型实现了92.7%肺癌患者的鉴别诊断和95.1%患者的预后分析。FENG等[21]联合CEA、NSE等六种肿瘤标志物建立ANN模型,能有效鉴别诊断肺癌、肺良性疾病和三种胃肠肿瘤。本研究中MPL⁃ANN对肺癌的诊断和预测准确率分别为73.0%(336/460)和93.2%(934/1002),诊断和预测结果与以上报道相似。PLS⁃DA是代谢组学中常用的数据处理模型,该模型可以减少变量间多重共线性,在样本数目小于测量指标时仍有很好的分类效果。课题组前期研究发现,基于血清中CEA、NSE、CA125和Cyfra21⁃1的PLS⁃DA模型对肺癌和肺良性疾病均有较好的鉴别诊断价值[19]。本研究中PLS⁃DA模型的诊断正确率低于前期小样本探索研究,可能与增大样本量和纳入更多早期肺癌患者和对照人群有关。 SVM使用核函数将输入特征从低维空间映射到高维空间,实现比传统线性分类方法更好的分类能力,已用于医学领域。王洪凯等[22]利用SVM模型,实现了PET⁃CT影像中非小细胞肺癌纵膈淋巴结良、恶性分类。纪鹏慧等[23]建立血清10项指标的SVM模型并通过内代法验证,该模型的预测正确率为90.3%,优于Fisher线性判别分析模型。本研究发现,利用不同核函数建立SVM模型对肺癌的诊断正确率均有差异,基于非线性核函数建立5种SVM模型中有3种的诊断正确率均高于线性核函数模型(L⁃SVM)。此外,基于FG⁃SVM模型和MPL⁃ANN的非线性模型的诊断准确率也优于PLS⁃DA线性模型。以上结果表明,模式识别技术的应用效果与数据类型密切相关,寻找最优的模型才能挖掘更多有价值的数据信息,提高诊断和预测的正确率。 大数据时代,由于海量数据不断产生,采用多种模型对比分析更有助于数据的合理利用和临床精准诊断。本研究基于血清CEA、NSE、CA125和Cyfra21⁃1构建了3种数据挖掘模型,其中FG⁃SVM和MPL⁃ANN模型在诊断和预测中显示了更优的效果,为模型识别技术在肺癌的鉴别诊断和预测分析提供了参考依据。但是,本研究也有一定的应用局限性。由于本研究采用临床上常见的肿瘤标志物且类型偏少,3种模型对肺癌诊断的正确率最高仅有73%。因此,本实验室在后续肺癌的数据挖掘和构建诊断、预测模型时需要考虑增加新检测指标及样本量,提高肺癌诊断的正确率和实用性。此外,本研究中研究对象主要为肺癌患者,未能纳入其它肿瘤患者进行对比研究,还需后续需增加非肺癌患者进行对比研究,使结论更严谨、准确可靠。


3 讨论
