基于FIGARCH-EVT模型的上海燃料油期货市场风险度量实证研究*
2020-04-15朱恩文李偲李今平朱安麒谭薇
朱恩文 李偲 李今平 朱安麒 谭薇
(1.长沙理工大学 数学与统计学院,湖南 长沙,410114;2.海南大学 理学院,海南 海口,570228)
1 引言
我国期货市场发展较晚,上海燃料油期货市场21世纪初才出现.然而,随着改革开放和我国工业的迅速发展,对石油进口的需求日益增加.从地域角度来看,世界两大基准油价不能体现亚太地区的需求变化,全球原油市场需要一个能够代表亚洲的期货基准价来指导当地的原油销售.此外,燃料油作为石油的一个下游产品,其期货价格走势预计会和石油期货市场价格趋同,这也就意味着我们对燃料油期货市场风险的计量,在某种程度上可以为石油期货市场提供一个回避损失的金融工具以做参考.
国外主要石油期货市场发展很成熟,石油波动率拟合模型多种多样,风险规避工具也很多[1-11].而我国石油期货品种很少,燃料油期货市场推出较晚,缺少相应的风险规避工具.国内学者在捕捉燃料油期货波动序列特征上,未考虑到燃料油的长记忆性.此外,在度量风险时,他们假定尾部服从正态分布或者t分布或者广义误差分布来计算VaR,没有考虑极端情况的发生,导致与实际情况不符[12-15].
因此,本文将考虑波动率序列中存在的异方差性、尖峰厚尾效应以及长记忆性,并结合极值理论模型,对上海燃料油期货市场风险进行度量实证研究.
2 相关理论知识
2.1 FIGARCH模型
在实践中我们发现有些金融序列过去的观测值对未来很长一段时间的观测值仍具有相依性.虽然这种相依性很小,但仍不能忽略,而且观察得到波动率序列的自相关函数呈现双曲线衰减.为了捕捉过去冲击对于波动序列长期的影响,Bollerslev和Baillie(1996)[16]提出将GARCH模型的差分阶数由正整数发展到分数阶次的FIGARCH模型:
化简后得

2.2 极值理论POT(peak-over-threshold)模型
极值理论方法只对收益序列尾部进行建模,而风险价值的估计只与分布序列的尾部有关.利用高于某个高阈值的极值行为进行建模,检验时间序列的极值通常利用POT模型.设X1,X2,…,Xn表示风险或损失的独立同分布随机变量序列且具有未知累积分布函数F,令Mn=max{X1,X2,…,Xn}.对极端事件的自然量度是:设定一个阈值u,计算超过阈值u的超出量X-u的分布函数:
根据Pickands的极限定理[17],对于足够大的阈值u,存在一个正函数β(u),使得上述超出量的分布可以很好地近似于如下的广义帕累托分布GPD(generalized Pareto distribution):
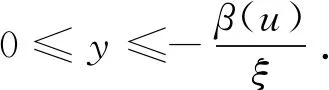
2.3 估计损失分布的尾部
对于足够高的阈值u,Fu(y)≈Gξ,β(u)(y).设x=u+y,当x>u时,尾部的损失分布F(x)近似于如下形式:
F(x)=(1-F(u))Gξ,β(u)(y)+F(u).
F(u)的分布函数由经验分布函数的非参数方法估计:
其中k表示超过阈值u的超出次数.整理得出下面的估计值:
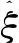
2.4 风险度量模型
风险价值(VaR)是目前资本市场上最主流的风险测度方法,是在一定的概率水平下,测度某个金融资产组合在特定时间段内最大可能的损失,其表达式为:
Pr(Δp>VaR)=1-α,
其中,Δp为持有期内资产的实际损失,α为给定的置信水平,VaR为给定置信水平下相应的风险价值.
本文把金融市场极端事件考虑其中,认为燃料油期货的日收益率序列建立GARCH族模型后的标准残差序列服从极值理论中的广义帕累托分布(GPD).我们计算得到残差序列极值理论模型对应的分位数Zα,再结合原始序列拟合GARCH族模型得到的条件标准差σt,可计算持有期内相应的VaR,如下公式所示:
VaR=Pt-1Zασt,
其中Pt-1是前一天期货的收盘价.
3 上海燃料油波动序列实证分析
3.1 燃料油期货市场日收益率走势分析
本文选取2004年8月25日到2018年11月2日间中国上海燃料油期货市场每日收盘价数据,对收集到的期货市场日收盘价进行处理,得到日对数收益率.令rt=100·ln(pt/pt-1),其中pt为第t天的收盘价数据,pt-1为第t-1天的收盘价数据,则rt即为我们的研究对象日对数收益率.除去闭市期,交易天数共3264天,总共3263个数据.我们选取2018年11月3日到2019年4月1日共100天的数据来做风险回溯检验.所有数据均来自东方财富金融choice终端.
我们先了解下期货收盘价日对数收益率序列有何特征.
从燃料油日对数收益率的时序图(图1)可观察到,日对数收益率序列在某一段时间内波动小(例如从第1300个观测值到第2000个观测值之间),某段时间内波动大(例如从第2300个观测值到第3000个观测值之间),具有明显的波动集群性.此外波动序列还存在极端值现象.
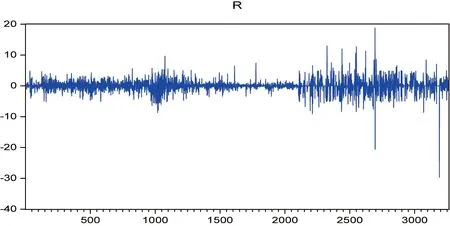
图1 燃料油日对数收益率时序图
3.2 描述性统计分析
描述性统计分析是对所收集的数据分析其内在规律的一种分析方法,主要包括数据集中趋势分析、离散程度分析等.为了对数据特征有一个大致的了解,我们对其进行描述性统计分析.
根据数据描述性统计分析表(表1)可知,序列的均值、中位数、最大值、最小值分别为0.0136,0,18.897,-29.79,其中最大值和最小值差距较大,且都不接近均值和中位数.从这几个统计量的特征看来,序列可能有极端值出现.偏度为-0.940,小于0,该序列是左偏分布.峰度值为26.108,远大于正态分布的峰度,比正态分布的峰更尖.从上述结果来看,燃料油日对数收益率序列存在极端值,且序列不服从高斯正态分布.

表1 描述性统计分析表
3.3 长记忆性检验
长记忆性通俗来讲就是今天发生的事会对将来一直产生影响.如果序列存在长期记忆性,那么认为相距较远的观测值对现在仍然产生作用,因此对金融市场收益率序列存在的长记忆性检验具有重要意义.传统的识别长记忆性方法有R/S检验法.
从长记忆检验结果来看(表2),R/S检验显示原序列具有长记忆特征,因此我们认为原序列存在长期记忆性,即相距很远的观测值之间也会存在相关性.

表2 长记忆性检验
3.4 阈值选取
通过对原始序列建立FIGARCH模型,我们过滤出近似独立同分布的残差序列,然后应用极值理论知识对提取的残差序列拟合POT模型,对其进行风险测度.
上述均值超越函数图(图2)斜率正负符号发生改变的点是我们所关注的地方.图形有向上倾斜表明序列存在厚尾现象,尤其是超过u0并且有正斜率的直线是尾部帕累托行为的标志.
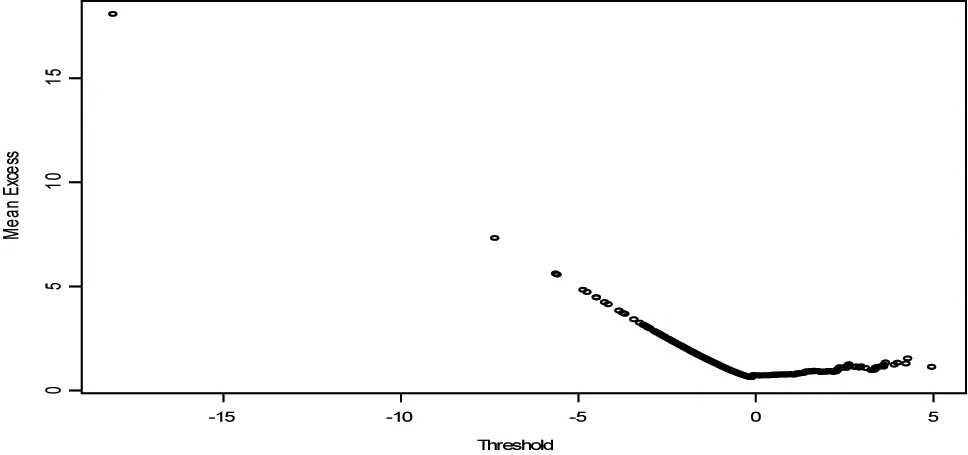
图2 均值超越函数图
从图3可知,当阈值在2以下时,选取不同的阈值对分位数的计算没有很大影响,在一定范围内,阈值的选取与分位数的值具有较好的稳定性.而传统的极值理论BMM模型,其分位数值的计算与样本子区间的划分有很大关系,这也进一步说明了POT模型的优势.
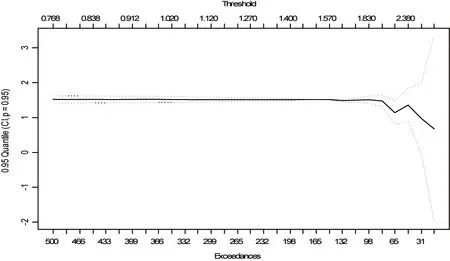
图3 阈值与分位数关系图
3.5 参数估计结果
本小节选取FIGARCH和GARCH模型来拟合燃料油波动序列,并提取拟合模型的残差序列,对其进行极值理论分析,得到相应拟合参数估计结果.
上小节我们知道极值理论POT模型在一定区间范围内,选取不同阈值对分位数影响不太大.这里我们对两个模型选取一样的阈值.
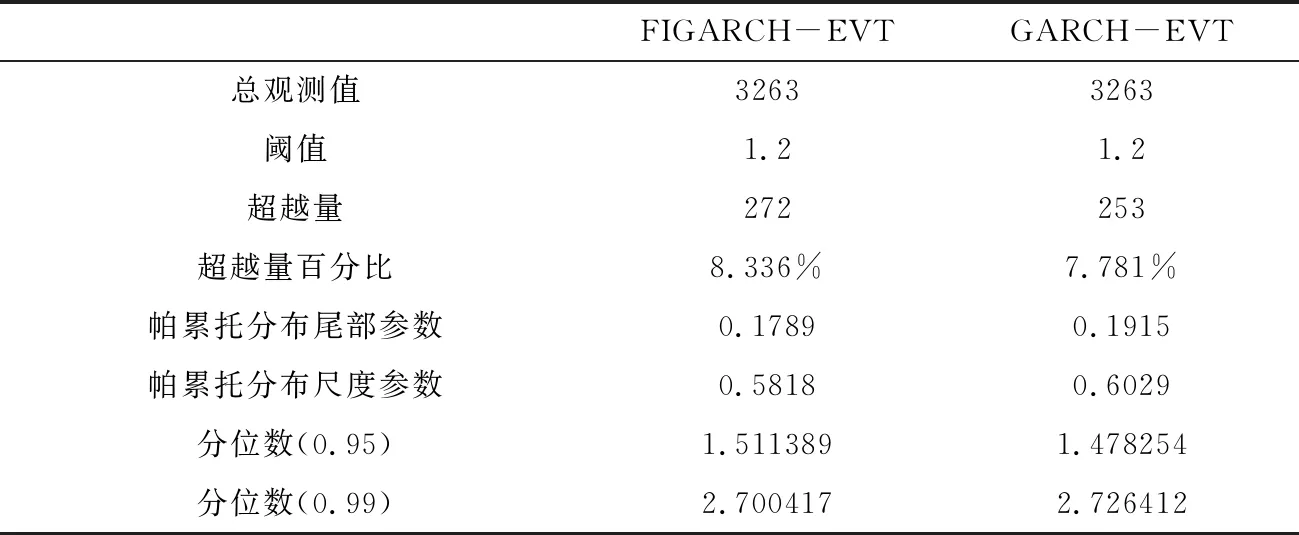
表3 参数估计结果
运用极值理论计算分位数时,是用经验分布去估计总体分布,从而不需要对总体分布做出任何假设,这也是极值理论的一大优势.如果假定的总体分布有误,会影响模型拟合精度.在这一小节我们将基于给定模型来预测样本外100天的VaR值,将计算得到的样本外100个观测值的每日VaR值与实际损益进行比较,然后通过Kupiec(1995)风险回溯检验方法[18],来对各模型预测风险的准确性做一个评估,看哪一个模型在度量燃料油期货市场的风险价值方面表现更好.
3.6 回溯检验
Kupiec回溯检验的主要思想是估计观测到的损失大于VaR值的概率, 这可用来检验基于模型的VaR估计的准确性.我们对以下两种模型进行失败率回溯检验.
从Kupiec回溯检验结果可知,FIGARCH-EVT比GARCH-EVT模型在5%,1%的置信水平更接近于实际失败天数,且失败天数更少.故能捕捉长记忆性的FIGARCH-EVT模型在度量上海然燃料油期货市场的风险上表现更佳.

表4 失败率检验
4 结论
本文就上海燃料油期货市场的价格波动进行研究,考虑了价格波动对我国燃料油期货市场带来的风险,并通过将时间序列模型与极值理论分析相结合的规范方法对价格波动风险进行度量.金融序列常用GARCH模型捕捉序列波动,本文通过对数据进行长记忆性检验得知,燃料油期货市场具有长记忆性.对比结果发现,引入能捕捉长记忆性的FIGARCH模型后能更好地度量风险.此外,本文结合了能考虑极端情况发生的极值理论模型,与传统风险度量模型不同的是,极值理论不需要对原始序列分布做出任何假设.实证结果表明本文选取的模型有效,能很好地规避风险,这可为那些金融市场参与者提供一种规避风险的工具,以便更好地辨识和预防损失的发生.
