大数据评论釆集分析系统的设计与实现
2020-04-14韩帅康江涛张顺
韩帅康 江涛 张顺


摘要:该设计以机器学习为基础,通过编写爬虫程序对网上各大平台公开评论信息进行采集并根据评分同时进行数据标注,以朴素贝叶斯分类算法为基础,通过对数据的分词,拟合出文本情感与文本的关系模型,从而达到一个相较于传统情感字典更好的效果。同时以该算法为基础,设计开发一套大数据评论采集分析系统,通过分析互联网上的相关评论,将分析结果可视化展示给企业,帮助企业更好地了解产品的市场情况,定位产品的优缺点,从而帮助企业优化决策,制定合适的策略,获得更佳的市场表现。
关键词:文本采集;朴素贝叶斯;机器学习;语义分析
中国分类号:TP391.1
文献标识码:A
文章编号:1009-3044(2020)04-0035-03
Design and Implementation of Big Data Comment Collection and Analysis System
HAN Shuai-kang,JIANG Tao,ZHANG Shun
(School of Information Engineering,Zhengzhou University of Science and Technology,Zhengzhou 450054,China)
Abstract:This design is Based on machine learning,by writing crawlers of the major online platform for public comment information acquisition and according to the score data annotations at the same time,Based on the naive bayesian classification algorithm,Based on the data of participles,fitting out text emotional and relationship model of text,so as to achieve a better effect than traditional emotional dictionary.At the same time,on the basis of the algorithm,designed and developed a set of big comment on data acquisition analysis system,through the analysis of the comments of the Internet,showed the visualization analysis results to the enterprises,help enterprises to better understand the product of the market situation,the advantages and disadvantages of positioning products,thereby helping enterprise optimization decisions,formulate the right strategy,obtain a better market performance.
Key words:text collection;naive Bayes;machine learning;semantic analysis
1 概述
隨着互联网时代的发展,越来越多的传统行业诸如餐饮,酒店,旅游业,电影等逐渐由线下转移到线上。用户可以在体验过后自由地发挥评论,长期以来,散布在互联网上大量的文字信息并未受到合理的利用。而传统的情感字典在分析一段文字情感的时候仅仅是对词语进行简单的计算,在准确率和可靠性上效果往往不尽人意,而釆用朴素贝叶斯分类算法通过对文本的标注,分词,去停用词,词向量处理之后,所生成的模型往往可以应对很多复杂的文本情况,从而比传统情感字典方式不论在准确率还是可靠性上都具有明显的优势。
2 设计方案与实现
2.1 数据采集与标注处理
2.1.1 数据采集方法
通过分析相应平台网页端与移动端的请求信息,定位到请求用户评论的API接口,通过对该接口的研究,分析出来请求该接口所要求的格式,例如需要某些字段等,然后使用Python语言配合第三方Requests网络框架,使用程序模拟用户真实的请求,从而获得我们所需要的评论数据,根据评分存储到不同的文件中,方便后续的分析与处理。
2.1.2 数据标注方法
由于大多数平台用户在评论的时候都会添加相应的评分信息,而评分大多数情况都代表了用户的情感倾向,比如五星好评的评论往往代表该用户对于该产品的情感特征是较为积极正向的,而一星差评则往往代表用户对于该产品情感特征是消极负向的,所以我们根据用户评分的情况将评论主要分为两类,一类是正向评论,标记值为1,一类为负向评论,标记值为0,具体的标注工作通过爬虫程序在爬取评论信息的同时根据评分信息自动完成分类与标注。
2.2 数据分析算法与实现
2.2.1 朴素贝叶斯算法
贝叶斯分析来源于18世纪的英国数学家托马斯贝叶斯所提出的一个数学领域可行性分析理论,即我们常说的贝叶斯理论,贝叶斯理论是统计学中的一个重要定理,其原理主要是根据已经发生的事件来推断尚未发生的事件的可能性。
同时贝叶斯理论在垃圾邮件过滤等领域已经得到了充足的验证和广泛的使用,而基于朴素贝叶斯的文本情感分类,则是通过学习已经标注过情感倾向的文本信息,来分析一个新的未标注的文本情感为正向或者负向的概率。
朴素贝叶斯算法则是在贝叶斯算法的基础上进行了相应的简化,也就是在所有给定的目标值中,属性之间是相互独立的,同时属性变量对于最后的决策结果影响所占的比重较小,虽然该方法在一定程度上有可能降低传统贝叶斯算法在文本分类上的分类表现,但是由于做了简化操作,使得朴素贝叶斯算法相较于贝叶斯算法在方法的复杂性上有所降低。
通过朴素贝叶斯算法在分析的过程中不断地添加新的训练集,理论上来说,朴素贝叶斯算法所学习的文本数据越多,那么对于一个新文本的分类结果就会越准确O
2.2.2 数据预处理
由于文本信息是没有办法直接当作朴素贝叶斯算法的输入,所以在正式的拟合模型之前需要对数据进行一定的预处理,首先使用Python的中文分词框架Jieba对数据集进行整体的分词操作,这一步的目的是便于后续对数据集的去停用词处理以及词向量的计算工作。
数据的处理和展示则使用了Python语言的Pandas库和Jupyter开发环境,首先打开之前爬虫自动化程序从网络上抓取并标注处理的程序,数据已经随机打乱,其中评论数据总数为5176条,其中情感为正向的评论(sentiment=1)为3733条,情感为负向的评论(sentiment=0)为1433条。
第二步是使用Jieba分词库对数据集进行分词,并使用Sklearn库对数据集进行随机拆分,这一步分别将数据拆分成两个部分,训练集和测试集,其中训练集和测试集根据标签分别分为数据集和标签集,分詞处理之后的数据如下:
如图2所示,comment为评论数据,cutted_comment为分词之后的评论数据,每组词之间用空格作为分隔符。
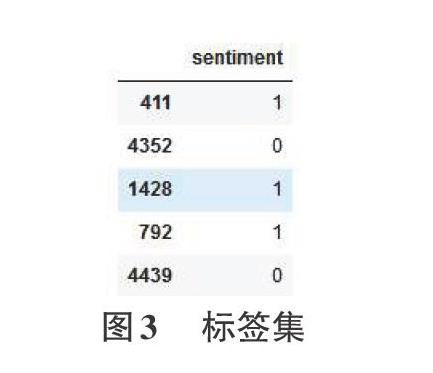
数据集对应的标签集如图3所示。
由于计算机本身并不能直接识别文本数据,所以最后一步则是对文本信息进行词向量化处理,本例中则选用bag of words模型,即不考虑词语的出现顺序,也不考虑词语和前后词语之间的连接,每个词都被当作一个独立的特征来看待。同时去掉之前评论数据中的停用词,停用词是在计算机在处理文本数据时用于提高搜索效率会选择过滤掉的特殊文本。比如中文中的“的”“这个”“吧”以及一些常见的标点符号都属于停用词。词向量处理过之后的数据如下:
2.2.3 模型的生成与测试
经过数据预处理,下一步就可以将数据放入我们预先选择好的算法之中了,在这里我们选择的是Python语言Sklearn库中的MultinomialNB,MultinomialNB是Sklearn库提供的基于先验为多项式分布的朴素贝叶斯算法。
将之前处理过的词向量数据与训练集中的标签集作为输入运行程序,利用Sklearn库中的joblib类将模型保存为model,pkl文件,这样在之后的预测计算中便无须每次进行训练,即可直接使用,模型训练出来之后便是测试模型的准确率,使用测试集进行测试之后,情感倾向分析的准确率为86.5%O
3 数据可视化展示
3.1 系统设计
模型构建好之后,下一步便是开发相应的可视化展示界面,即大数据评论采集分析系统的最后一个环节。整体的流程如下图所示,用户在客户端输入相应平台的网址,爬虫程序则根据网址去抓取相关的评论数据并进行数据清洗,标注等处理,之后将数据输入到上文所构建的模型之中进行分析,最后将数据分析结果通过情感倾向分析、词云展示、词频分析三个维度展示出来。
词云制作使用Python词云制作库WordCloud库,WordCloud是一款开源的基于Python语言的词云制作框架,词频相关的分析则使用Matplotlib以及PIL库。配合词频统计,最终将岀现频率前十的词汇,通过直方图直观地展示出来。
4 结束语
本文利用Python与Web自动化工具批量抓取互联网各大平台的评论数据依据评分策略进行数据的清洗和标注,并使用Jieba,Pandas,Numpy等数据分析工具将评论数据分词,向量化,利用skleam中基于先验为多项式分布的朴素贝叶斯算法以处理过的数据为输入生成的机器学习模型并且保存到本地,并以此模型为基础,使用Web开发技术完成大数据评论釆集分析系统的设计与实现,不论是企业或者个人,都可以通过在客户端中输入特定的链接,获取到相关评论经过分析之后的情感倾向分析结果、词云和词频分析的可视化展示,从而更好地挖掘评论数据中隐藏的信息,同时,该模型也可以用在互联网舆情监控,非法言论拦截与检测,用户个性化推荐等领域。在今后的研究及实践中,我们将加入更多例如影师评论,电商评论等行业数据,从而让我们的系统获得更高的准确率以及适用于更多的场景中。
参考文献:
[1] 王龙龙.基于贝叶斯算法的垃圾邮件过滤系统设计与实现[D].长春:吉林大学,2014.
[2] 高雅,苏艳,席方园.基于Python的新浪微博用户数据采集与分析[J].电子设计工程,2019,27(20):157-160,165.
[3] 孟天乐.朴素贝叶斯在文本分类上的应用[J].通讯世界,2019(1):244-245.
[通联编辑:谢媛媛]