探究纳入文献质量评价不一致性的原因—以针灸治疗膝骨关节炎的系统评价/Meta分析为例*
2020-04-12程施瑞陈逸嘉孙睿睿李政杰梁繁荣
周 俊,程施瑞,陈逸嘉,孙睿睿,李政杰,曾 芳,梁繁荣**
(1. 成都中医药大学针灸推拿学院 成都 610075;2. 中国人民解放军空军军医大学基础医学院 西安 710032)
随着循证医学的兴起,作为“证据金字塔”顶端的系统评价/Meta 分析(systematic reviews/meta-analyses,SRs/MAs)在医学领域中受到广泛关注[1,2]。高质量的SRs/MAs 能够为临床治疗提供循证参考和决策[3-5],而纳入的原材料是影响SRs/MAs 质量和结论可靠性的决定性因素之一[6]。随机对照试验(randomized controlled trials,RCTs)是评价干预效果的最佳设计,因此常常被研究者作为SRs材料的不二选择[5,7]。目前评价RCTs质量运用较广泛的工具是“Cochrane风险偏倚评估工具”和“Jadad 量表”[7,8]。但是,即使使用的工具一样,经常也会出现不同系统评价者对同一RCT 评价不一致的情况[9-11],使得SRs/MAs 的质量及结论可信度受到严重影响。因此,探究评价不一致性的程度以及寻找可能导致不一致性的原因尤为重要。
针灸作为传统中医的一种治疗技术,可应用于许多疾病的治疗。借助循证医学的理念和方法,是现代针灸临床研究的重要方向[12]。目前针灸治疗疾病的SRs/MAs 越来越多(图1),其中以疼痛类疾病最多,例如临床常见病、多发病膝骨关节炎(knee osteoarthritis,KOA)[13]。但是目前许多针灸的SRs/MAs 存在原始纳入文献质量评价不一致性的问题,这是导致许多针灸相关SRs/MAs质量和可信度低的主要原因之一。
本文SRs/MAs 以针灸治疗KOA 为例,旨在评估国内SRs研究者使用方法质量学评价工具后做出判断的不一致性,以及探究导致不一致性的可能原因,以期为其他针灸SRs研究的类似问题提供借鉴。

图1 PubMed数据库针灸相关SRs/MAs论文数
1 资料和方法
1.1 文献检索
计算机检索中国知网、中国生物医学数据库、维普、万方等数据库,语言无限制,检索时间从建库至2019 年6月3 日。以“膝骨性关节炎”、“膝关节骨性关节炎”、“膝骨关节炎”、“退行性骨关节炎”、“骨痹”、“针刺”、“电针”、“耳针”、“温针”、“头皮针”、“腹针”、“穴位”、“灸法”、“系统评价”、“系统综述”、“荟萃分析”等为主题词和自由词。补充检索相关灰色文献及咨询相关领域的专家。以中国知网作为数据库的检索示例,检索策略如下:
主题=(‘膝骨关节炎’+‘膝骨性关节炎’+‘膝关节骨性关节炎’+‘退行性骨关节炎’+‘骨痹’)AND 主题 =(‘针灸’+‘针刺’+‘电针’+‘耳针’+‘温针’+‘头皮针’+‘腹针’+‘穴位’+‘灸法’)AND 主题=(‘系统评价’+‘系统综述’+‘荟萃分析’+‘Meta分析’)
1.2 纳入与排除标准
纳入标准:①研究类型:纳入RCTs的SRs/MAs;②研究对象:RCTs 中被明确诊断为KOA 的患者(符合公认的任一标准即可),年龄、性别、种族、国籍和病程均不限;③干预措施:与针灸相关的所有治疗方式,包括针刺、电针、温针、头针、腹针、耳针、穴位埋线、穴位敷贴、穴位注射等,并可辅以其它任何疗法;④质量评价/偏倚风险评估中至少明确包含评估中的一项内容。
排除标准:①重复发表文献;②与作者联系后仍无法获取全文;③未含有重复的RCTs 的SRs/MAs;④无法提取质量评价记录。
1.3 文献筛选
将检索出的文献导入Endnote去重后,由2名研究员独立完成初筛,排除明显不符合纳入标准的研究后,对余下研究进行全文阅读,各自完成之后进行交叉核对,若有争议讨论协商解决。
1.4 资料提取
①2 名研究员独立将纳入的SRs/MAs 相关信息提取至预先设计的表格中,包括SRs/MAs 的作者、年份、质量评价方法、是否至少由2人独立完成质量评价,以及SRs/MAs 中纳入RCTs 的作者姓名、发表时间等;②提取所纳入SRs/MAs 中对每个RCT 的质量评价/偏倚风险的判断和依据,包括随机序列生成、分配隐藏、对研究者和受试者施盲、对结局评价使用盲法、结果数据的完整性、选择性报告以及Jadad 量表评分结果等。③分别提取报告中由2 名以上研究人员独立评价与1人独自完成质量评价/偏倚风险评估的记录(未报道则默认为1人独自完成评价)。小组成员(周俊、陈逸嘉)各自独立完成信息提取整理后再行交叉核对,若有争议及时讨论协商解决。
1.5 质量评价工具
1.5.1 Cochrane偏倚风险评估工具[14]
目前循证医学领域中普遍推荐用于RCTs 研究偏倚风险评估的工具之一。于2005 年Cochrane 协作网组织研发,2008年公布第一版,2011年进行更新,并在2016 年项目网站上发布了第二版。该工具主要从选择偏倚(包括随机序列的产生和分配隐藏)、实施偏倚(包括对研究者和受试者施盲)、检测偏倚(研究结局盲法评价)、失访偏倚(结局数据的完整性)、报告偏倚(选择性报告)及其他偏倚这6 个方面7 个领域来对偏倚风险进行评估。评价者针对每个领域根据具体偏倚风险评估条目做出“high、low、unclear”3 种判断,以表示其对应“高风险偏倚、低风险偏倚、不清楚”的判断结果。
“造势”是指企业有目的地主动创造事件,利用新闻媒体进行传播,使之成为公众所关注的热点话题。同样,想实现好的效果就要遵循创新性、公共性及互惠性的原则。“造势”的营销操作要诀在于:
1.5.2 Jadad量表[15]
由Jadad 等1996 年发布,主要从随机、盲法、失访/退出3 个方面进行评价,采用0-5 分计分方式,≤2 分者为低质量研究,≥3 分为高质量研究。具体评价内容如下:①随机:采用“随机”并描述了正确的随机方法(2 分);提及应用随机方法,但未具体描述随机方法(1 分);未随机/假随机/不清楚(0 分)。②盲法:采用“双盲”并描述了正确的施盲方法(2 分);仅提及采用双盲法(1 分);未实行双盲/假双盲(0 分)。③失访/退出:对退出与失访的例数和理由进行了详细描述(1分);未提及退出与失访(0分)。
1.6 质量评价一致性的标准
不同SRs/MAs 的研究者对相同RCTs 偏倚风险的判断相同或Jadad 评分一致,若提供判断依据,则需判断依据大致相同。2 名成员独立完成评价后交叉核对,若有分歧讨论协商解决。
2 结果
2.1 检索和数据提取结果
检索结果:根据检索策略,共检索出93 篇可能与针灸治疗KOA的SRs/MAs相关文献,去掉重复文献50篇,阅读题目及摘要后排除文献9篇,阅读全文后最终纳入文献34篇,详见图2。
数据提取结果:34 篇SRs/MAs 中共有541 个RCT的基本信息被提取,经过多次查重,最终确定28 篇SRs/MAs 含有 205 个重复的 RCT 研究,提取重复 RCTs质量评价记录及判断依据等(图2)。
2.2 统计结果
含有重复RCTs 质量评价记录的28 篇SRs/MAs 中12 篇采用Cocharne 风险偏倚评估工具,7 篇应用Jadad量表,6篇应用改良Jadad量表,3篇使用Cocharne风险偏倚评估工具联合Jadad量表。另外,纳入的SRs/MAs中61%(17 篇)都未提及质量评价由2 名人员独立完成(表1)。
2.2.1 随机、分配隐藏
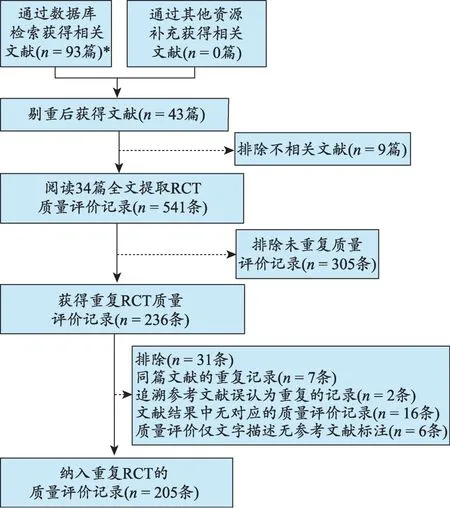
图2 检索及数据提取流程图
随机序列生成:180 个重复RCT 在多个SRs/MAs中存在评价判断。68%的评价结果一致,其中52%被评为“低风险”,48%被评为“不清楚”。另外,32%的不一致评价结果较为复杂:对同一个RCT 有相同的判断,但提供的判断依据不同;相同的判断依据却做出不同的判断;对同一个RCT 有多种不同的判断或描述等,详见表2。
2.2.2 盲法
对研究者和受试者施盲:在纳入的205 个重复研究中,188 个(92%)包含研究设计是否运用盲法的判断。该领域125 个(66%)意见一致,63 个(34%)意见不一致。在不一致中,有60 个(95%)被归类为“不清楚”或“高风险”。另外5%是在同一个RCT 的3 个判断中存在差异,其中1 个描述为“提及单盲”,另2 个在“低风险”和“不清楚”判断之间存在分歧。而在68%判断一致中均判断为“不清楚”,详见表2。
对结局评价是否采用盲法:仅有50个重复研究对结局评价者是否采用盲法进行评估,其中18 个(36%)存在判断不一致,且歧义均在“高风险”与“不清楚”之间。其余32 个(64%)一致性判断均为“不清楚”,详见表2。

表1 纳入SRs/MAs质量评价基本特征

表2 SRs/MAs中重复RCTs质量评价记录统计
2.2.3 结果数据的完整性、选择性报告、其他偏倚
结果数据的完整性:28 篇 SRs/MAs,共计 205 个(100%)重复研究均涉及该领域。其中118 个(58%)对失访或退出的判断结果不一致。在不一致中80 个(68%)判断偏倚出现在“低风险”与“不清楚”间(表2)。
选择性报告:有80 个重复研究对此做出明确判断,其中38 个(47.5%)研究的判断结果不一致。而出现不一致的情况均在“不清楚”和“低风险”之间。在42 个(52.5%)一致性判断中,“低风险”与“不清楚”各占一半,详见表2。
其他偏倚:56 个判断中,有44 个(79%)重复研究存在判断不同且这44 个都是在“低风险”和“不清楚”间出现判断不一致。剩余12 个(21%)判断结果一致中有8 个(67%)“低风险”判断,4 个(33%)“不清楚”判断,详见表2。
2.2.4 Jadad量表评分
在方法学质量评估工具中共有59个重复RCTs选用Jadad 量表,其中有30 个(51%)存在评分不一致:12组(80%)相差1分,2组(13%)相差2分,1组(7%)相差3分,详见表2。
2.3 2人独立完成评价的不一致性
在纳入的205 个重复研究中,SRs/MAs 中提及“由2 名成员独立评价”的质量评价记录有87 个(42%),1人独自完成评价的记录118个(58%)。提及“由2名成员独立评价”的质量评价的不一致性在各领域的占比为(括号内为所有项重复研究在各领域判断不一致性占比):随机序列的产生42%(32%)、分配隐藏4%(8%)、盲法36%(34%)、对结局评价使用盲法100%(36%)、结果数据的完整性60%(58%)、选择性报道66%(47.5%)、其他偏倚82%(79%)、Jadad 评分48%(51%),详见表3。
3 讨论
本文聚焦SRs/MAs 中纳入文献质量评价的不一致性,为如何提高一致性提供方向。通过以针灸治疗KOA 为例,首次探讨国内针灸相关SRs/MAs 对纳入RCTs 质量评价的不一致性,同时关注由2 名成员独立评价与1人独自完成质量评价的不一致性差异。结果显示无论何种情况在较多领域中均存在较大的不一致性。

表3 2人独立评价与1人独自评价不一致性记录统计
3.1 对质量评价结果较高一致性领域的原因分析
在结果中随机和盲法领域的评价一致性较高,其中分配隐藏方案评价一致性最高,随机方案产生、对研究者和受试者施盲、对结局评价使用盲法评价次之。进一步观察一致性的情况,大都是因为在纳入材料的原文中未提及这一领域的内容,缺少足够的信息最后做出“不清楚”的判断。随机是RCTs 最基本的条件之一,虽然文中报告纳入的研究类型均为RCTs,但对其具体的随机方法却很少描述,这不排除系统评价者纳入假随机研究的可能性,使纳入的研究失去同质性,影响SRs/MAs 的整体质量。另外,如果不进行分配隐藏,即使随机完成得很好,也可能夸大治疗结果[16]。据调查显示,不实施或不充分实施分配隐藏,结果会被夸大42%以上[17,18]。可见随机方案产生与分配隐藏所带来的选择偏倚对评价结果的内部真实效应尤为重要。盲法的必要性,主要体现在减少研究当中出现的实施偏倚和测量偏倚,但并不是所有研究都能够实现双盲或者三盲,比如针灸[16],这也可能是许多国内文献不愿报道盲法的主要原因。但这种情况下对盲法的风险偏倚判定则需要一分为二的看待:若采用客观评价指标,则不太会对结果产生影响;若采用主观评价指标,则有可能对结果产生影响。但在主观评价指标中,如果是未参与治疗全过程的第三方评价,则不太可能对结果产生影响[19]。因此现代针灸相关的研究大多遵守实施者、受试者、评价者三分离的原则,但很多研究却未在文中报告说明,这使得评价者很难通过有限的文本信息去评判偏倚风险或质量。目前缺乏统一的定量的盲法质量评价方法,盲法的评价主要是通过研究者报告的盲法实施过程来评价[20-22],因此报告原文细节使评价过程透明化显得尤为关键。推荐使用健康公平相关随机对照试验的报告规范(CONSORT-Equity)扩展声明[23]联合针刺临床试验干预措施报告标准(缩写为STRICTA[24])对针灸相关RCTs进行规范化报告,以减少报告不规范带来的评价不一致以及产生的偏倚。
3.2 质量评价工具的应用存在较大不一致性的原因
在评价结果不一致性中其他偏倚最高,其次是结果数据的完整性、Jadad 评分、选择性报道。观察这些领域出现较大不一致性的情况:其他偏倚的判断主观性较强,对评价人员要求较高,需要评价人员全面评估可能产生风险偏倚的来源后,排除前面已经评价过的偏倚风险,做出判断。结果数据完整性的不一致中68%都是对“不清楚”和“低风险”的界限不明。而Jadad评分不一致中80%仅相差1分。另外,有研究表明选择性报道是一致性最差的领域,并被证明会引起混淆[25,26],这与我们的研究具有一定的重合。下面进一步讨论不一致性的可能原因。
3.2.1 未遵循2人独立评价交叉核对
在完成质量评价的过程中,Prisma 条目[27]以及Cochrane 风险偏倚工具中要求至少有2 名成员分别对纳入的每一项研究的偏倚风险领域进行独立评估,如遇分歧则2 人协商讨论解决或由第三方裁决,最终使判断达成一致。这个过程是为了减少个人判断的主观性,降低偏倚风险的可能,提高结果的可重复性及可靠性[3]。然而本文纳入的研究一半以上都未遵循该条目,这也可能是导致不一致性较高的重要原因之一。另外有趣的是,我们发现在纳入研究中提及“由2名成员独立评价”的质量评价在多个领域的不一致性反而更高,剩下领域也与1 名人员独自完成评价基本持平。这个结果可能与实际设想的情况不太相符,我们猜想这可能与我们纳入的研究范围局限有关,同时也不排除提及由2 名及2 名以上完成质量评价的研究者并未真正按照报告的标准去实施的可能。这也提示我们不能仅仅从随机试验的报告去直接判断整个试验的方法学质量,因为随机对照试验报告的好坏并不一定反映试验设计、实施或分析的方法质量好坏。因此我们应从试验中获取更多的信息和数据以确保评估的准确性[28,29],这个问题可能需要在更广泛的领域中深入探讨。
3.2.2 研究者对质量评价工具的掌握程度参差不齐
在统计多个领域不一致性的过程中发现,绝大多数情况都是在“不清楚”与“低风险”、“不清楚”与“高风险”的判断间出现偏差,进一步发现有较多的研究者是在找到相同的报告信息后,做出了不同的判断。比如来自2个不同的SRs/MAs在对同一个RCT结果数据的完整性判断中都描述了“2 名患者拒绝随访而脱落”,然而其中1 个做出了“低风险”判断,另1 个做出了“不清楚”判断。我们猜想可能是有研究者在评价过程中从结果数据或是联系作者或是其他方面搜集到了额外的证据,但并未在文中呈现。此外,还有一些个例出现自身矛盾的情况:描述为“风险未知”、“仅提及随机”,却做出“低风险”判断;文中风险偏倚图与文字描述不一致等。上述出现的一系列问题都与研究者对质量评价工具的掌握程度参差不齐有关,希望通过Cochrane 协作网专业评价小组学习或是专业机构统一组织培训,能够提高评价者对质量评价工具使用的准确性和一致性。
3.3 问题和展望
本研究仅局限于国内针灸治疗KOA 这一较狭窄的领域里,并且未严格区分Cochrane 风险偏倚工具和Jadad 量表的不同,风险偏倚评估与方法学质量评价的界限,这可能会在一定程度上影响结论的可靠性。但就本研究探讨的一致性而言,仍有较多的问题值得我们关注。第一,加强报告规范:尽量呈现判断结果的原文支撑材料细节,使得评价过程更加透明化;第二,严谨实施:我们应当严格按照PRISMA 条目及Cochrane Handbook 的建议——至少由2 名人员独立完成质量评价,如遇分歧可协商讨论解决或寻求第三方裁决;第三,全面掌握质量评价工具的运用:报告规范固然重要,但不应以文献报告为质量评价的唯一依据,应当在此基础上,结合自身对该研究领域的经验和认知,对原始文献的报告以及呈现的数据进行综合判断。相信通过对质量评价工具应用的改进,评价结果的不一致性问题能够得到较好的解决,为RCTs 及SRs/MAs 的证据质量提供有力保障,进一步促进高质量证据的产生和转化,更好的为临床治疗提供参考和循证决策。随着人工智能的高度发展,或许日后我们可以依靠设计完善的人工智能程序自动搜寻并提取原始文献报告,并结合数据分析作出客观判断,避免人为评价所带来的偏倚和低级错误,使评价结果一致性达到新高度。
