一种针对中国移动客服文本的分词方法
2020-04-10钟建高海洋
钟建 高海洋
摘 要:为提升客户服务的效率,快速分析和解决客户问题,并将客户述求和投诉充分转换为中国移动发展的动力和资源;提出了一种针对移动客服聊天记录的数据分词框架,针对客服聊天文本的特点,制定了结合文本纠错、停用词扩充、关键词提取、词性分析这几个方面的数据预处理步骤。依靠这样的框架,提升了文本数据分词的质量,使用字典映射的方式,纠正出文本数据中存在的共性的错误。
关键词:数据预处理;停用词;关键词;纠错字典
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2020)01-0007-03
Abstract:In order to improve the efficiency of customer service,quickly analyze and solve customer problems,and fully convert customer complaints into the power and resources of China Mobiles development. We propose a data segmentation framework for mobile customer service chat record. According to the characteristics of customer service chat text,we develop the data preprocessing steps of text error correction,stop words expansion,keyword extraction,part of speech analysis. Relying on this framework,we improve the quality of text data segmentation. We use dictionary mapping to correct the common errors in the text data.
Keywords:data preprocessing;stop words;keywords;error correction dictionary
0 引 言
近幾年来,随着大数据概念以及人工智能的迅速发展,现在的各行各业都在向智能化的方法探索、发展,传统的服务行业也不例外,如何有效地使用机器学习的方法来减轻人工的工作量、提升工作效率是服务行业较为关心的问题。情感极性分析是自然语言处理中常见的任务之一,在不同的中文语料上,已有很多人进行了不同的研究[1]。通过分词工具以及人工筛选,笔者提取出了针对该文本的停用词以及关键词;通过对词性的分析,进一步对分词结果进行了筛选,得到了最终文本数据的分词结果。实验结果表明,使用上述分词框架后,对中国移动客服文本数据情感分析的二分类任务,在精确值上有2%的提升。
1 传统数据预处理
在机器学习和深度学习领域,都有很多方法来进行情感极性的分析[1]。尽管它们在对数据的数量和质量的要求上有所区别,但是在数据预处理方面,不论是传统的机器学习方法,还是深度学习模型,分词一般都是大家的首选步骤,虽然也有部分模型的研究粒度是基于字的[2],但是目前的主流方法还是基于词的。而受限于我们的数据集数量,实验中我们使用的是传统的机器学习方法来进行情感分类任务。
传统的数据预处理步骤包括分词,去除停用词两个操作。在中文语料分词方面,Jieba分词工具凭借其使用方便、分词高效的特点,备受大家的青睐,是最常用的分词工具。在将长文分数据为多个词之后,我们通常还会去除分词结果中的停用词。通常停用词会单独作为一个停用词词表,常用的中文词表有“哈工大停用词表”“百度停用词表”等。通过去除分词结果中的停用词,我们可以去除结果中的噪声词,这样做的好处是不仅可以降低分词结果的长度,也可以去除停用词对下游任务的影响。
针对我们的数据,在使用上述的分词步骤后,我们发现,由于我们领域的特定性,直接使用Jieba分词得到的结果并没有满足我们的需要,会出现我们关注的一些关键词被分为了多个词或某些词没有被切分成功的情况,这就直接影响了后面的特征构造以及文本表示。所以,在中国移动客服对话文本数据中,直接使用Jieba进行分词显然是不合理的。因为客服聊天内容的有限性和重复性,我们关心的词的数量也是有限的,所以,针对这个不足,我们提出了领域的关键词表,这样的好处是,所有我们关心的词都可以被正确的切分,因此,文本中的关键特征得以保存。同时,我们也维护了一份领域的停用词词表。除了去除通用领域的停用词之外,针对我们的数据,我们除去了针对客服文本数据的一些停用词。这些词大多属于客服代表的规范用语,如“客服代表”“网络专席”“您好”一类的词汇,这样的词汇广泛的出现在客服聊天文本中,但是对我们的任务分析没有作用,不需要作为我们的特征,因此需要去掉,然而在常用的停用词表中,无法将这些词有效地去除,因此我们更新了停用词表,得到我们针对中国移动客服聊天记录的停用词表。
由于我们数据的特殊性,在进行以上分词过程前,我们还需要进行一项任务,那就是文本纠错。由于我们的文本数据是由客服聊天录音通过翻译软件翻译而来,而录音本身并不是十分标准的普通话,导致聊天语音中有着大量的方言。受限于当前机器翻译软件的翻译质量,我们得到的翻译文本中,存在相当一部分的翻译错误文本。此类句子表现出无语法结构,无语序结构等等问题,多数句子直接无法判断其意思,属于无效的句子。当前的中文纠错研究,主要都是针对某些公开数据集上的某种问题,如语法、错别字等等[3]。对我们这样综合多种错误的文本来说,文本纠错是一个很难的问题。为了减轻这样的影响,针对我们的文本数据,我们采用的字典映射的方式来处理一部分文本错误。在简单处理后,使用我们的分词方法,再进行分词。
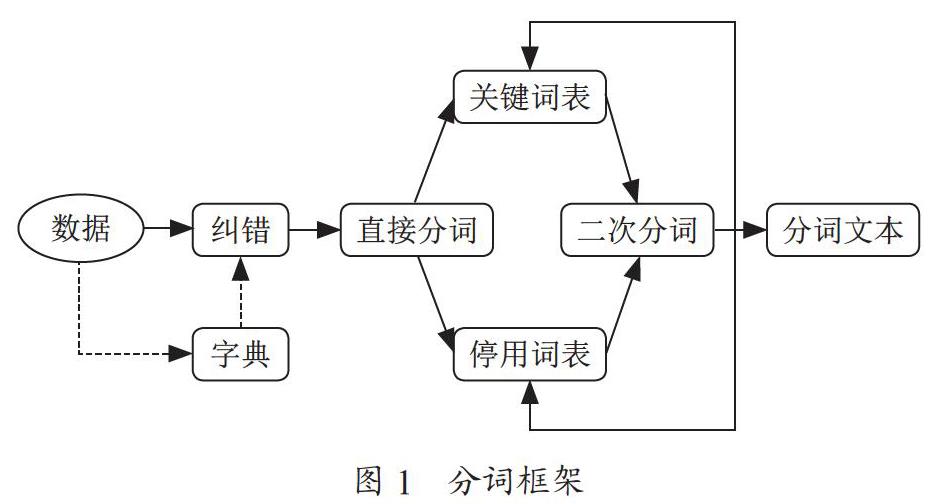
下面笔者将从纠错字典的构造、停用词表与关键词表的构造、实验方法以及实验结果及分析这几个方面介绍我们的工作。分词框架如图1所示。
2 纠错字典的构造
从上述的介绍中,我们已经得知,我们的文本数据中存在着一部分由于语音翻译带来的错误,使得文本数据无法理解。一方面,混合错误的文本数据纠错问题现在还缺乏一定的研究,我们尝试过使用百度AILab的纠错API,但是毫无效果;另一方面,我们没有缺乏有效的训练数据,即我们无法识别错误文本的真正意思是什么。以上原因使得我们无法使用机器学习的方法来纠正文本数据中的错误。由于我们的原始音频数据都是来自于同一个地区的客服聊天记录,即便是口音问题导致的翻译出错,它们的错也具有一定的相似性,因此,我们采用字典映射的方式来处理那些普遍存在于翻译文本中的具有一定共性的错误。通过人工识别的方式,我们总结出可以纠正的多音字或错别字错误,将其与普通话的字进行一一对应,形成了纠错字表。使用纠错字表,我们将文本中的这些字一一修改成普通话中对应的字,达到简单的纠错效果。
3 停用词表与关键词表构造
在进行简单的文本纠错后,我们需要构造停用词表以及关键词表,这两个词表的构造对我们的分词以及文本筛选的准确性有着很大的影响。因为这两个词表的功能具有一定的相反性,因此我们是同时构造这两个词表的,下面是我们构造这两个词表的过程。首先我们使用Jieba分词工具,将纠错后的文本进行直接的分词,使用通用领域的停用词表去除停用词,得到分词后的文本。这时候,每一条原始数据都由一系列的词表示。接着,我们抽样出部分原始文本与其分词数据,人工观察识别分词结果,对比原始的文本,提取出错分的词,构造成我们的关键词表。然后对分词文本进行数值上的统计,由于我们的数据具有领域特性,所以对于高频词,我们需要额外的关注。对于出现次数高于100次或出现次数在前100~200的词,直接人工判断是否需要重点关注这些词,如果需要,则将它们加入到关键词表中,如果不需要,则把它们加入到停用词表中。最后,在完成一次关键词表与停用词表的更新后,我们重新使用Jieba进行分词,加入关键词表,保证词表中的词都能被正确分类,加入停用词词表,保证词表中的词都被去除。迭代進行2~3次关键词表与停用词表的更新。由于我们数据的特点,一方面领域特点保证了我们关键词和停用词的有限性;另一方面,我们使用分词工具去辅助人工发现关键词与停用词,这两点保证了人工筛选词汇的可行性和高效性。
4 实验设计
本次实验采用了三个传统的机器学习模型:支持向量机、XGBoost、logistics回归[4]。在传统的机器学习模型中,对于分类任务,以上三种方法是最常使用的模型,之前很多的研究已经证明了在分类任务上以上三种模型的优秀表现。实验文本特征的构造使用自然语言处理中较为常见的one-hot表示以及TF-IDF表示,分别构造文本数据的特征,使文本数据向量化。在文本向量化之后,我们将数据分别使用不同的模型进行分类,得到实验结果。对比实验,我们使用控制变量的方法,使用本文的分词方法对数据进行预处理,对比不使用该方法的普通的分词方法,使用同样的实验方法、实验参数,对比实验的结果。实验结果的衡量指标为F1值。
5 实验结果及分析
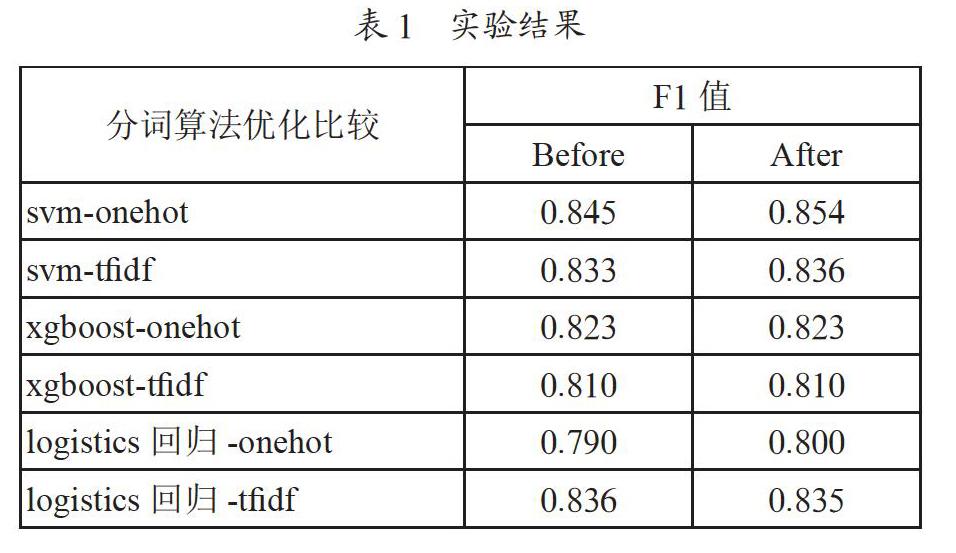
各方法实验的结果如表1所示,Before列代表未使用上述分词方法的实验结果,After列代表使用上述分词方法的实验结果。
从实验中我们可以看出,在不同的方法以及不同的特征构造上,使用本文提出的分词方法后,部分模型的表现都有了效果上的提升。主要原因一方面是我们减少了文本中的错误,减少了很多干扰词,另一方面是因为我们使用了领域的停用词表和关键词表,更多重要的词被保留,在构造文本特征的时候,与直接分词相比保留了更多的特征,因此在分类的结果上,使用本文的方法后,分类的效果有了提升。
6 结 论
本文提出的这种针对中国移动客服文本的分词方法经实验验证是有效的。针对中国移动客服文本的预处理问题,在经过我们的文本纠错,结合本领域的关键词表和停用词表的辅助分词后,文本的特征得到了很好的保留,从而在下游的情感分析任务上,与单纯的分词相比,在不同模型上都有了效果上的提升,充分说明了本文提出的分词方法的有效性。
参考文献:
[1] WANG Y,ZHENG X,HOU D,et al. Short text sentiment classification of high dimensional hybrid feature based on SVM [J].Computer Technology and Development,2018,28(2):88-93.
[2] DEVLIN J,CHANG M,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].[2019-11-20].https://arxiv.org/abs/1810.04805?context=cs.
[3] YANG Y,XIE P,TAO J,et alAlibaba at IJCNLP-2017 Task 1:Embedding Grammatical Features into LSTMs for Chinese Grammatical Error Diagnosis Task [C]//Proceedings of the IJCNLP 2017,Shared Tasks,2017:41-46.
[4] WRIGHT R E. Logistic regression [J].Reading & Unders-tanding Multivariate Statistics,1995,68(3):497-507.
作者简介:钟建(1969-),男,汉族,四川成都人,高级工
程师,硕士研究生,研究方向:移动网络的建设维护和优化。
