基于词向量的SVM集成学习社交网络抑郁倾向检测方法
2020-04-09王垚贾宝龙杜依宁张晗陈响
王垚 贾宝龙 杜依宁 张晗 陈响


摘 要:目前抑郁症的诊断手段单一、诊断率低,为此,文章提出一种基于词向量的SVM集成学习社交网络抑郁倾向检测方法。人工标注和专家校验获得训练数据,使用词向量进行文本向量化。以SVM为基分类器进行Boosting集成学习。实验结果表明,文章提出的模型可以用于抑郁倾向的检测。
关键词:抑郁检测;微博;支持向量机;词向量;集成学习
目前,国内外基于社交媒体文本内容的抑郁倾向检测主要分成两类,一类是基于统计的数据挖掘方法,另一类是基于机器学习模型的检测方法。
(1)基于统计的数据挖掘方法,主要是通过统计微博文本内容的高频词、构建情感词典等方式来评价用户的抑郁倾向。高一虹等[1]利用统计的方法对比了微博中抑郁倾向用户和现实中抑郁症患者,发现抑郁症在现实生活和社交媒体上的表现有重合也有偏差。
(2)基于机器学习模型的检测方法,主要是将微博文本或用户属性向量化,进而构建分类器进行分类。施志伟等[2-3]通过问卷调查得到有抑郁倾向的用户,并爬取其微博,使用支持向量机(Support Vector Machine,SVM)模型进行监督学习,得到了具有82.35%准确率的模型。
本研究提出了一种基于词向量的SVM集成学习社交网络抑郁倾向检测方法,通过多组对比实验验证了其有效性。
1 相关工作
1.1 数据的收集
使用的数据来自新浪微博,选择352位有明显抑郁倾向的博主的微博作为正数据,共有35 962条微博文本,323位非抑郁症患者博主的7 297条微博文本作为负数据。筛选后得到28 654条微博文本的正数据,58 569条微博文本的负数据,如表1所示。经过3位心理学系的硕士研究生进行交叉检验,仅有10位用户存在争议,数据的可信度达到了97.5%。
1.2 数据的清洗
为了保证数据的高可用性,对得到的数据进行了过滤,具体过滤方法如下:
(1)过滤掉不可用的信息,如图片、视频以及微博中有跳转链接。(2)过滤掉广告数据以及非原创数据,如文本中的投票、打榜、影响力、人气演员等。(3)正则匹配过滤部分干扰字符,如@xxx,#xxx超话#等。(4)过滤掉长度小于7个字的微博文本。
2 抑郁倾向检测方法
本文提出的抑郁倾向检测方法主要包括两部分:构建用户向量、SVM集成学习,如图1所示。
首先,文本的向量化主要包含4部分:对微博文本的分词、获取每个词语的百度词向量、将词向量进行特征加权计算句向量、根据句向量构建用户向量;其次,进行SVM有监督学习;最后,以其为基分类器进行Boosting集成学习。
2.1 构建用户向量
2.1.1 分词与词向量
由于微博文本包含大量网络用语,而百度分词比较善于针对网络文本进行分词,同时也能通过构建自定义词典提高特殊词汇的分词效果,所以先利用百度分词API进行分词,然后获得对应的百度词向量。对于百度词向量库中不存在的抑郁词,则选择词向量库中与其最相近的词作为替代。对于不在抑郁词典中且词向量未收录的词语,直接赋0,便于之后的计算。
2.1.2 词向量加权
首先,使用TF-IDF进行特征加权,特征权重的计算如式(1):
2.1.3 构建用户向量
2.2 SVM集成学习
集成学习是机器学习中一种通过多个算法或者模型来执行单个任务的技术,可以在一定程度上提升模型的性能。主要的集成学习方法包括堆叠[4](Stacking)、提升[5](Boosting)和装袋[6](Bagging)3类。为了进一步提升模型在判错样本上的分类能力,选择使用Boosting的提升方法。Boosting方法通过不断改变训练样本的权重,得到多个分类器,并将其进行线性组合,提高分类的性能。本文选择使用Boosting方法中最经典、最常用的是AdaBoost算法。
3 实验结果及分析
3.1 实验设计
实验分为4部分:(1)用原始百度词向量进行训练,用SVM表示。(2)用TF-IDF加权词向量进行训练,用SVM-T表示。(3)用TF-IDF和抑郁词加权的词向量进行训练,用SVM-TW表示。(4)用TF-IDF和抑郁词加权的词向量进行AdaBoost集成学习训练,用SVM-TW-AdaBoost表示。
3.2 评价标准
3.3 实验结果与分析
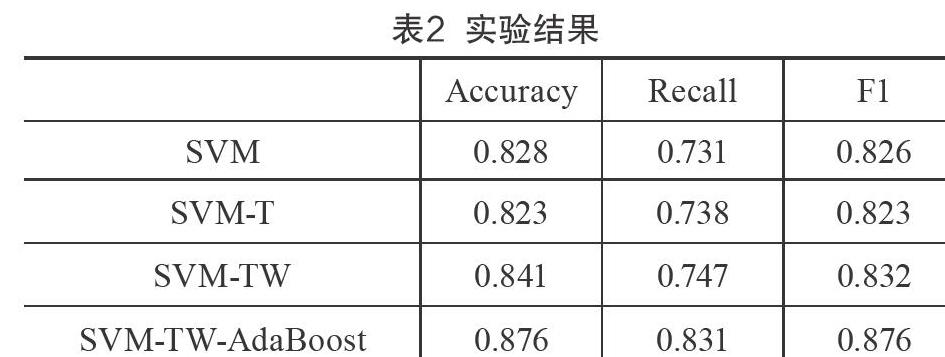
实验结果如表2所示,可以看出,SVM-T相比SVM仅召回率略有提升,而准确率和F1有所降低,说明TF-IDF加权不能较好地改善微博文本的向量表示。SVM-TW相比SVM-T有明显提升,说明抑郁词权重能够有效增强微博文本抑郁倾向的表示。SVM-TW-AdaBoost相比SVM-TW有较大提升,说明集成学习能够明显地提升微博文本的情感表示。
4 结语
本研究提出的基于词向量的SVM集成学习方法,由于将传统SVM进行集成学习,使得学习到的分类器更加准确,泛化能力更强。下一步将考虑用户其他有效特征,进一步增强模型性能。
[参考文献]
[1]高一虹,孟玲.自杀倾向的话语表述—大学生“走饭”微博分析[J].外语与外语教学,2019(1):43-55,145-146.
[2]PANG B,LEE L,VAITHYANATHAN S.Thumbs up?Sentiment classification using machine learning techniques[C].Stroudsburg:Processing.of the ACL-02 Conference on Empirical Methods In Natural Language Processing,2002.
[3]YOUN SJ,TRINH NH,SHYU I,et al.Using online social media Facebook in screening for major depressive disorder among college students[J].International Journal of Clinical and Health Psychology,2013(1):74-80.
[4]李壽山,黄居仁.基于Stacking组合分类方法的中文情感分类研究[J].中文信息学报,2010(5):56-62.
[5]黄彬.基于Boosting算法的中文情感分类研究[J].电子技术与软件工程,2017(12):190-191.
[6]FENGGANG L,JI L F,LI W,et al.A method based on manifold learning and bagging for text classification[C].Beijing:Management Science and Electronic Commerce,2011.
