基于Tensorflow的Android端相册分类App设计与实现
2020-04-09
(浙江工业大学 信息工程学院,浙江 杭州 310023)
如果手机中相片数量非常庞大,那么用户寻找到一张特定的图像或者一类图像就会非常困难。自动相册分类是解决这个问题的重要途径,也是很多相册类应用的基本功能。目前,由于移动端的算力限制,相册分类的实现方式,包括iOS系统相册、腾讯相册宝等应用,大多是将相册共享到云端,由高算力服务器进行图像分类并给照片打上标签,重新下发到移动端,再由移动端根据标签完成图像分类[1-3]。这样的做法缺点非常明显,可以归纳为:1)没有连接互联网就无法进行分类,运行环境苛刻;2)用户拍照和相片分类之间存在时间差,无法实时进行图像分类;3)由于要上传用户相片,用户的隐私无法保障,存在安全隐患。采用基于移动端本地对图像进行图像分类的方案可以有效地解决上述问题。移动端进行图像分类的最大困难在于如何利用移动端有限的算力,达到和服务器类似的分类效果。2017年,谷歌针对移动端推出了TensorflowLite神经网络框架[4]。通过该框架可以在移动端运行InceptionV3[5]图像识别神经网络,并达到较高的准确率。
本研究目标是基于TensorflowLite框架和相关图像识别算法,开发一款可以由移动设备独立进行图像分类,并且兼顾时效性和有一定准确度的移动端应用软件。接下来将围绕相册分类软件App的结构设计和实现、图像识别神经网络的改进、图像识别神经网络的训练、神经网络移动端移植图像分类功能的验证四方面来论述。
1 相册分类App的总体设计
相册分类App(以下简称App)主要遵循软件工程中经典的Model-View-Presenter(MVP)模式[6-8]。视图(View)层、逻辑(Presenter)层和数据(Model)层三层彼此独立解耦,从而让软件获得较好的拓展性和鲁棒性。
App主要由图1所示的三大模块组成:主工程模块、基础层Framework模块以及图像识别模块。主工程模块负责承载App的界面显示和逻辑,并初始化图像识别模块和基础层模块。通过读取系统相册,将系统内所有的图片路径管理在一个字典(dict)中,通过图像识别模块给所有图片打上分类标签。并按标签并保存在数据库。最后通过分类标签,进行图片归类并通过视图界面呈现。基础层Framework模块向所有模块提供通用基础功能,比如数据库访问、代码编写中的工具类和网络库等。其中,工具类包括字符工具类、图像工具类和url拼接工具类等。另外,为了保证代码质量,通常会编写单元测试进行代码逻辑检查或者一些Lint静态脚本来保证代码的书写规范。图像识别模块是本文的核心功能模块,是真正进行图片识别和分类的模块。主工程会在App初始化阶段向图像识别模块注入配置参数并初始化。图像识别模块向主工程暴露自己的功能接口,App具体表现为识别某一张图片并返回该图片类别的概率数据。图像识别模块通过在Android上执行TensorflowLite框架,并在该框架上运行利用InceptionV3改进的图像分类神经网络模型来实现图像分类的主要功能。构建该功能将面临三大问题:1)选取并改进性能强大、功耗合适的卷积神经网络;2)对卷积神经网络重新训练,能够适应移动端的分类需求;3)如何进行卷积神经网络的移动端移植。接下来的内容将围绕这三个问题进行阐述。

图1 App的主要架构
2 分类神经网络的改进
图像分类是本文的核心,其中起到图像分类主要作用的是图像分类的卷积神经网络。运行在服务器端上的传统图像分类网络通常如图2所示,分为图像预处理层、特征提取层以及分类器。服务器具有强大的计算能力,为了更高的识别准确度,通常使用层数很深的卷积神经网络来提取更多的特征向量,这一类神经网络典型为VGG-16。
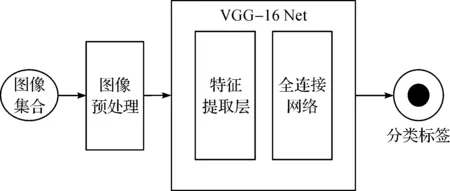
图2 传统图像分类神经网络
VGG-16共有16 个卷积层,包含1.38 亿个参数,无论是训练还是具体特征提取,对设备性能的消耗都非常高。另外,由于服务器强大的算力,最后的分类器可以设置更多的参数来精准地区分特征向量,达到更细颗粒度的图像类别划分。表1展示了VGG-16和AlexNet的计算量[9],用FLOPS(即相同时间完成神经网络计算所需要的浮点计算量)来表示,单位是Gb。AlexNet是第一代卷积神经网络,其计算量相对较小,但是精准度也随之降低。VGG-16的计算量是AlexNet的20倍左右,每秒需要16 Gb的浮点运算量,这在移动设备上运行将会非常缓慢,所以有必要对图像提取层进行改善。

表1 VGG-16和Alex-Net的计算量
最直接的改善方式就是替换特征提取层,笔者将使用适合移动设备的特征提取网络来替换VGG-16进而改进神经网络的性能。表2展示了近年经典图像分类模型的错误率[10],可以看出:自从2012年ImageNet的ILSVRC图像识别挑战赛创办以来,图像识别神经网络的准确率有了长足的进步[11-13]。
表2 历年图像分类模型Top 5错误率
Table 2 Over the years image classification model Top 5 error rate

年份模型名称Top5错误率/%2012AlexNet15.302013ZFNet14.802014GoogleNet(InceptionV1)6.672015InceptionV35.60
其中InceptionV3功耗适中,图像识别的准确率高[12],在图像识别方面表现优秀。神经网络的最后一层一般为一个全连接层,在全连接层之前的神经网络被称作瓶颈层(BottleNeck),可以作为特征提取层来使用。已经通过训练的Inception-V3模型性能优秀,其瓶颈层仅仅通过一个单层的全连接网络就可以区分1 000 种类别的图像[12]。这说明InceptionV3的瓶颈层输出可以作为图像简练且表义明确的特征向量,并可以利用该特征向量进行进一步的分类。
InceptionV3通过卷积堆叠、引入Batch-Norm算法以及卷积降纬等方法,减少神经网络的深度,改善卷积核心的大小以及数量,从而改善神经网络的功耗[13]。InceptionV3神经网络的参数总量为2 400 万左右,相当于VGG-16的六分之一。改进后的图像分类神经网络如图3所示。

图3 基于IncetionV3的图像分类神经网络
在改进的神经网络模型中,使用InceptionV3的特征提取层来替换VGG-16作为整个神经网络的特征提取层,并将其输出的特征向量输入全连接层进行进一步的分类。另外,由于移动端的相册应用并不需要InceptionV3多达1 000 多种的分类能力,所以需要重新训练神经网络的分类器,即全连接层,降低分类标签的数量,来满足客户端的分类需求,这一部分内容将在第4部分进行阐述。
3 模型性能对比
神经网络的性能通常用准确率和计算量来衡量。其中,准确率指在分类的过程当中正确的预测占全部预测的比例,计算公式为
(1)
式中:TP代表正确的预测;FP代表错误的预测。准确率主要用来衡量模型对事物类别判断能力的高低。
计算量主要衡量模型对算力的要求,在实际测算当中,通常使用同一数据集合的运算时间来间接表示。本次数据集采用公开数据集Pascal VOC 2007,总计20 个大类,9 963 张被标注的图片,标注对象是常见的人、狗和汽车等。性能测试实验的设计如表3所示,加入了AlexNet作为特征提取层的神经网络作为对照组。在实验中随机抽取各个大类的200 张图片,总计4 000 张图像作为实验数据。三次图像处理过程均运行在同一台硬件平台上,Tensorflow平台均开启GPU加速。

表3 性能测试实验设计
由表4可知:VGG-16作为特征提取层的准确率最高,但是运行时间非常长,对性能的要求最高;InceptionV3模型虽然准确率相对VGG-16低,但仍在移动端相册分类可以接受的误差范围内,但是其突出特点是运行速率相对于VGG-16大幅度提升,对设备性能要求最低;AlexNet虽然速度最快,但是其精准度比较低,对用户体验存在较大影响。在不大幅损失准确率的前提下,使用InceptionV3作为特征提取层,大幅降低了计算复杂度,符合移动端图像分类的特点。

表4 性能测试实验结果
4 模型的迁移训练
训练InceptionV3图像分类的数据集有120 万被标注的图片,收集图片数据集,并且利用数据集重新训练一个模型非常费时,可能需要几天甚至几周。为了解决训练一个全新的神经网络而产生的效率问题,迁移学习应运而生。迁移学习就是将已经在某个问题上训练好的模型,通过相对简单的调整,使其能够适应新的问题。在保留已经训练好神经网络瓶颈层输出基础上,通过替换最后一层全连接层,可以让该模型解决新的图像分类问题[14-16]。从上文可知:IncetionV3的瓶颈层具有良好的性能。通过迁移训练,可以让InceptionV3瓶颈层输出和全连接层组成的神经网络获得识别特定类目的图像的能力。
全连接层的训练网络的设计如图4所示。图4中线条上的数字代表一次训练过程中神经网络中数据流向的先后顺序。相同的数字编号的数据传递过程是同时进行的。整个过程利用不断迭代前向传播,后向传播更新参数,让交叉熵收敛,最终达到神经网络训练的目标。综合神经网络训练以及前后期工作,整个迁移训练的关键步骤归纳如下:1)图像预处理和数据集获取;2)获取瓶颈层输出并缓存;3)定义全连接层;4)训练全连接层;5)模型性能数据的输出。
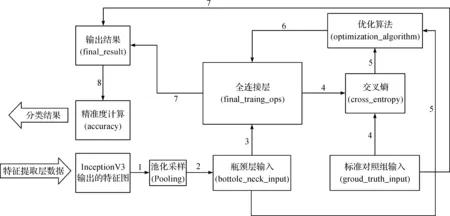
图4 全连接层训练网络
移动端的相册模型分类不同于照相时的实时场景识别,并不需要区分1 000 多个类别,这样会导致模型过于庞大以及因分类过于具体而准确率低下。对于移动端,只需要分类出“单人肖像”“多人照片”“物体”“植物”等较为抽象的词汇即可,而无需具体区分出“鼠标”“笔”等具体事物。所以,笔者的分类模型选取了13 个比较常见的分类词目。接下来将结合移动端的实际需求对模型迁移进行阐述。
4.1 图像预处理和数据集获取
相较于训练一个全新的模型,迁移学习对于图像数据集数量的要求大大降低,但是对于一个单一的类目识别,同样需要数百个样本图像。
基于python语言编写爬虫脚本是获取图片数据集的重要途径。图5展示了爬虫脚本的主要流程。整个爬虫脚本由config.py,spider.py和deal_image.py三个文件组成。其中config.py是配置文件,spider.py是爬取脚本,deal_image.py是图像处理脚本。爬虫脚本的主要原理是通过Baidu搜图等图像搜索引擎发起搜索请求,解析其搜索结果,并逐个下载图片,并对图片进行规范化裁切和格式化,最后进行部分人工筛选以保证数据的可用性。本实验共爬取了13 个图像类目,保存在13 个文件目录中,分别以类目名命名。
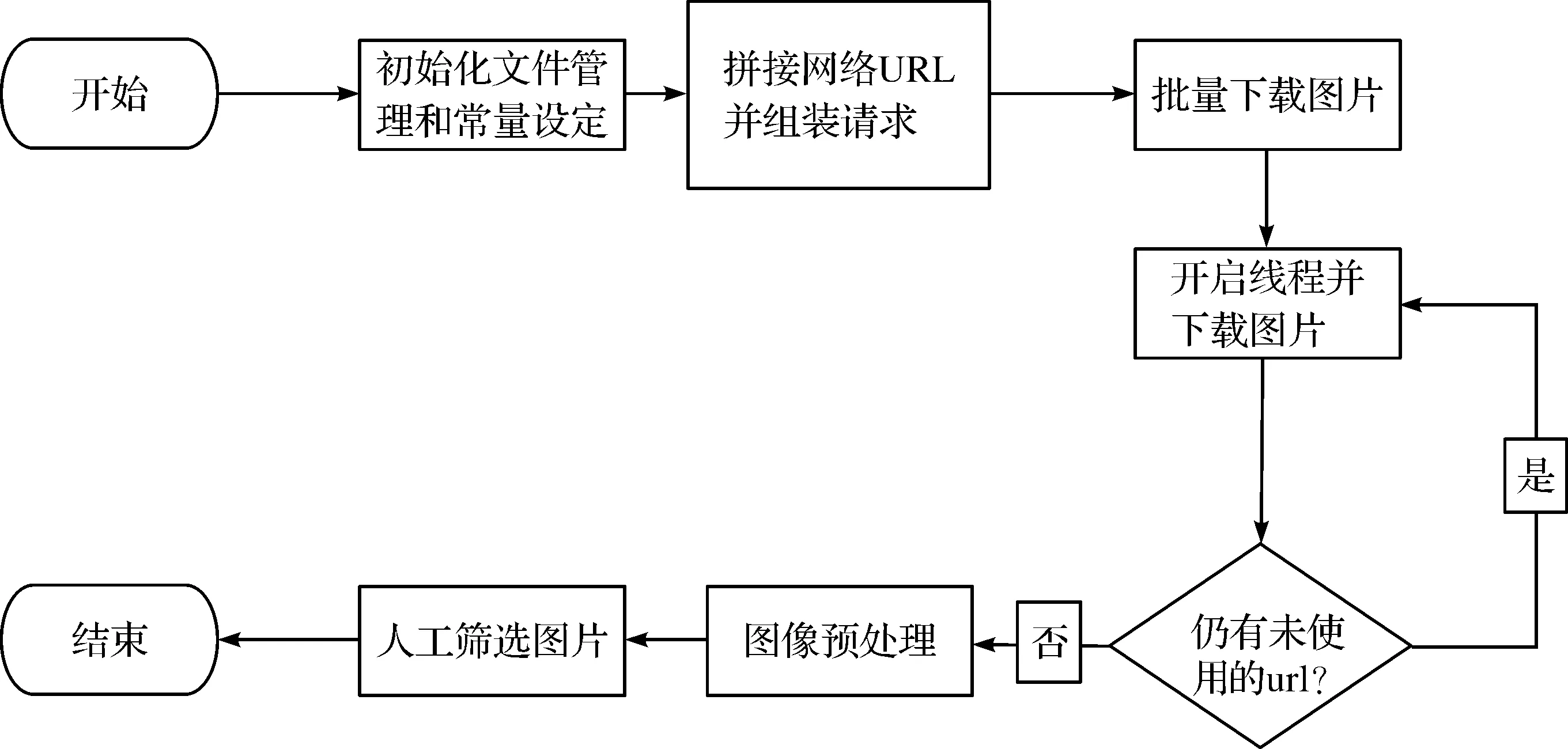
图5 图像爬虫脚本的主要流程
4.2 获取瓶颈层的输出并缓存
瓶颈层的输出是利用InceptionV3模型对图像数据集进行处理,获得每张图片的特征向量作为全连接层的输入。为了提升运行效率,需要配合缓存机制对图片进行存取。数据的流向如图6所示。
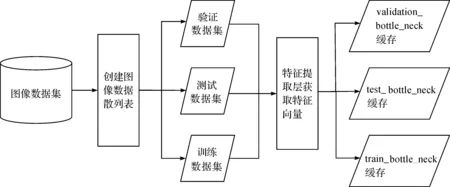
图6 瓶颈层数据的获取
在代码中,通过create_image_lists方法创建数据集列表,将上一小节爬取的图像按照预先设定的分类比例,将每个图像类目随机分为验证、测试和训练三个字数据集,并通过InceptionV3模型提取特征向量并缓存。通过get_image_path()方法来获取对应的某一张图像的文件绝对路径。随后加载已经训练好的InceptionV3模型,对训练数据集和特征向量进行提取并缓存。其中train_bottle_neck缓存将作为图4中瓶颈层输入,validate_bottle_neck作为标准答案输入,test_bottle_neck作为最后计算准确率的输入。
4.3 全联接层的定义
根据图4,并利用Tensorflow框架的函数接口可以很方便地定义整个神经网络当中的元素。首先定义全联接层的两个输入,分别为输入数据集和标准答案。定义一个输入数据集,命名为bottoleneck_input,顾名思义是将瓶颈层输出的特征向量作为输入。再定义标准答案用于反向传递和计算交叉熵,命名为groud_truth_input。这两个输入的实质是特征向量,即浮点数组。全连接层的定义需要设定一系列的参数。其初始的weights(权重分布)由tf.trucated_normal(shape,mean,stddev)输出一个正态分布的矩阵产生,大小(shape)由瓶颈层输出的矩阵大小(bottleneck_tensor_size)决定,均值(mean)默认为0,标准差(stddev)为0.1。bias(偏置)默认为一个长度为训练类目个数的全零向量。另外,需要定义交叉熵损失函数(cross_entropy),命名为cross_reduce_mean。交叉熵计算公式为
(2)
损失函数用于描述预测的概率分布p来表达正确概率分布q的困难程度。神经网络通过不断调整参数,将损失函数收敛到预定程度。
每次递归的对神经网络参数的优化策略即优化器(train_step),会在每次递归时调整神经网络的参数矩阵。其过程可以表示为
(3)
式中:θn+1表示新的参数;θn表示更新前的参数。本次实验采用梯度下降优化器(GradientDescentOptimizer),每次调整的幅度,即学习率η为0.01。
最终神经网络的性能需要通过准确率来表征,准确率命名为accuracy。通过比较最终输出和验证数据集是否正确,得到准确率,准确率用于描述模型的识别能力。
4.4 全连接层的训练
全连接层的训练网络定义完成之后将进行全连接层的训练。训练的实质是通过反向传播算法,不断调整预定义神经网络参数,让交叉熵收敛到预定程度的过程,其主要流程如图7所示。在初始化阶段完成后,每次随机取两个train_bottle_neck固定数量的子集(batch)分别作为训练数据集和标准答案。每次训练都将数据集数据填入用于可视化的Summary数据集,用于实验结果的可视化。在每次训练次数达到准确率输出常量时,取validation_bottle_neck数据集的一个随机子集(batch)计算一次准确率。在训练完成后,使用test_bottle_neck数据集进行一次精准度计算。

图7 神经网络训练流程
4.5 模型性能
在迁移训练完成之后,在TensorBoard(Tensorflow的训练可视化工具)当中可视化训练过程。之前在Summary数据集中保存的节点数据,将会以Json格式的数据包保存。而TensorBoard将会解析这个数据包,并绘制模型的训练图表。TensorBoard的输出表格数据较为繁复,笔者将其简化后重新绘制为图8,9。
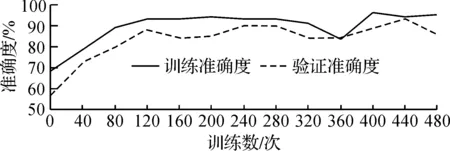
图8 准确率变化曲线

图9 交叉熵变化曲线
图8是模型的准确率变化曲线。100 次左右训练后,准确率在90%附近波动,并逐渐上升。图9表示交叉熵随着训练进行的变化曲线。前100 次训练,交叉熵下降明显,之后趋于稳定。
通过tf.savemodel()方法在指定的文件目录下,保存整个神经网络模型的节点数据文件(以*.pb格式保存)和分类标签(以*.txt格式保存)文件。
5 分类模型在Android端的移植
在第3部分当中训练的模型,可以在PC端对图像进行分类。但是,如果需要将该模型运行在Android端,由于性能和兼容性原因,需要进行移植操作。移动工作主要解决两个问题:即Tensorflow框架在移动端的运行和分类模型针对移动端Tensorflow的文件结构优化。
Tensorflow框架对于移动端十分友好,其后续针对移动端的TensorflowLite框架可以在移动端非常轻松地运行。通过在Android编译配置文件build.gradle当中添加TensorflowLite的Android Archive(即AAR,Android系统中用于取代传统Java第三方库Jar格式压缩包的数据包格式),就可以通过谷歌Jcenter服务器的Maven代码仓库引入TensorflowLite的Android版,可以省去很多兼容性的配置。在此之后,Tensorflow框架可以在Android工程中被开发者调用。
与TensorflowLite同时发布的还有TensorflowLiteConverter模块(简称TOCO)。该模块用于普通的Tensorflow计算图向TensorflowLite计算图的转换。对于开发者而言,计算图级别的模型转化已经可以极大地提高模型在移动端的运行效率。通过该模块,可以将Tensorflow模型转换压缩成TensorflowLite模型。TensorflowLite模型由一个*.pb文件和一个名为label.txt的标签文件组成。将这两个模型文件加入Android工程的资源文件包Assets当中,就可以在Android工程中通过TensorflowLite框架动态加载神经网络,并作为Java接口使用。
6 相册分类App的分类效果
相册分类App使用的分类模型总共训练了13 个类别的识别来满足日常的图像分类需求。在应用开启后会通过Android的系统相册对象扫描手机中所有的图像,并对所有图像进行分类。每一张图片的分类过程在一个独立线程中,线程资源通过线程池进行管理和分配。每个图像分类线程会在后台通过图片识别模块给图片打上分类标签。整个图像分类的时间控制在合理范围内。相册分类App安装在相对比较过时落后的摩托罗拉Nexus 6平台,相册分类应用仍然能够在4 min内完成对总计72 张图片的分类,在较新的小米5平台上,同样数量的照片分类需要2 min左右。
如图10所示,多线程处理进行图像识别并不会阻塞视图主线程而造成页面卡顿。在相册分类页面中,将会逐渐将已经分类好的图片依次加入。图像分类的进度会通过Android的“通知”(Notification)显示(图10a);和市面上大多相册App一样,在照片页面展示手机存储的所有图片(图10b);在相册页会将图片归纳到不同类别的相册中,比如动物、文字和人物等(图10c)。同一张照片可能会有多个分类。点击相应相册可以查看该类目下的所有图片,点击图片可以查看图片的大图。
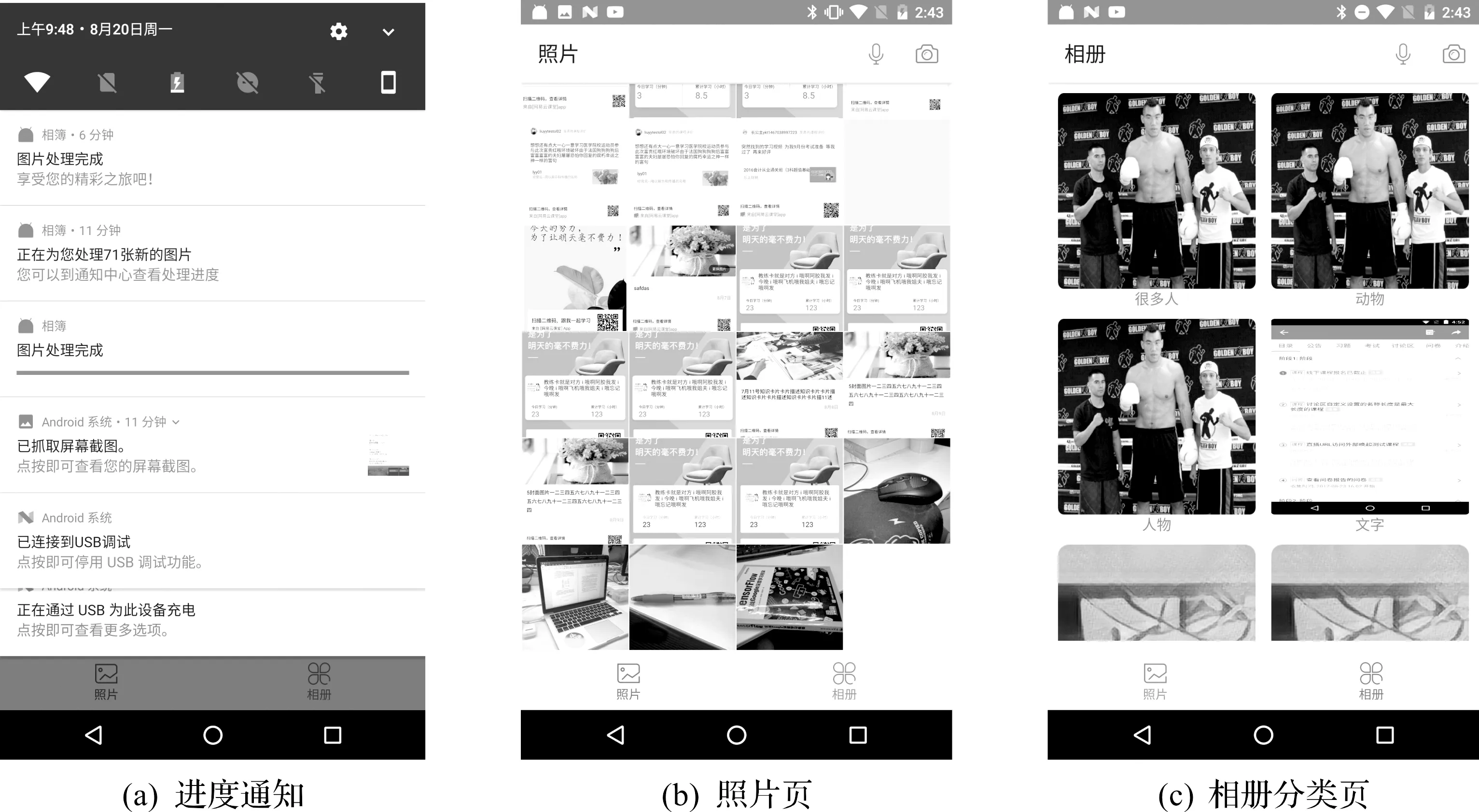
图10 照片页和相册页
如图11所示,在“物品”类目和“文字”类目当中的图片,图像主体识别已经相当准确,但对一些场景非常复杂的情况,会存在主体判别错误或者类别识别错误的情况。

图11 “物品”与“文字”类目
7 结 论
虽然以往的相册类App普遍都有照片分类功能,但普遍会将图像识别分类的过程在服务器端完成,导致图像分类实时性不足,并且必须有良好的网络环境。所以,用户需要更智能、使用条件更友好的相册App。结合图像识别模型和TensorflowLite框架,尝试将图像识别分类的过程在移动端本地进行,并在较短时间内完成,可以很好地满足用户的需求。通过迁移学习成熟的图像识别框架,可以让新的模型满足不同的图像分类需求。将训练好的模型运行在移动端的TensorflowLite框架,可以让Android应用程序能够使用该模型进行图像分类,从而实现相册分类App的主要功能。在实验的过程中,除了模型训练、Android程序编写等主要步骤外,针对训练数据集不足和图像分类模型移动端移植等困难,提供了相应的解决方法。
