基于多视角二分k-means的高校图书馆用户画像研究
2020-04-09
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
高校图书馆是学校办学的三大支柱之一,图书馆建设的优劣从一个侧面反映出学校教育科研水平的高低,高校每年对图书馆的投入都很巨大。随着互联网技术的发展,传统图书馆逐渐往数字化图书馆转型,然而随着图书馆资源的逐年增加,读者寻找到自己感兴趣的资源越来越困难。随着大数据时代的到来,读者阅读的需求、行为、方式和途径与传统阅读方式相比都发生了巨大改变。此外,图书馆员无法直接接触到读者并获取读者真实的阅读需求和个人兴趣,因此不能实现以读者为中心的个性化服务和精准推荐,导致读者在图书馆的愉悦度较低,从而对图书馆的需求逐渐降低。用户画像作为大数据时代实现精准推荐的方法之一[1],可以真实地勾画出目标用户群体的特征。利用用户画像可以帮助图书馆实现精准读者推荐和服务。用户画像又被称为用户角色,用来描述目标群体用户、反应用户诉求。目前,用户画像技术正逐渐被应用到社交媒体、电商等领域。Rosenthal等[2]利用文本特征和社交特征构造博主用户画像来进行年龄分类;Wu等[3]结合用户社交关系和用户兴趣提出一种共同演化模型,从而更好地描述了在社交元素下的用户画像;Mueller等[4]通过对Twitter用户的用户名构建词语结构特征,并结合性别构建了Twitter用户画像;李恒超等[5]基于用户的查询记录提出了一种用于预测用户多维度标签的二级融合框架。虽然用户画像已成为当前的热门话题,但是目前针对图书馆读者的用户画像研究还很缺乏。姚远等[6]利用向量空间模型融合用户画像层次模型和时间上下文因素来构建读者的学术画像,但是只考虑了检索和学术论文检索,对用户的画像不够全面;胡昌平等[7]结合用户基本信息和在共享空间的行为信息,运用结构方程模型方法构建读者画像;Kovacevic等[8]通过对读者的资料和搜索记录进行挖掘分析,提出数字图书馆推荐服务,同时使用预测分类将相同兴趣爱好的读者聚在一起,从而形成读者画像,并以此为读者提供个性化服务。综上所述,现有用户画像技术还是偏单一属性为主,往往形成的用户画像不能够全面地描述用户,同时图书馆领域对读者进行用户画像的研究以理论研究为主。
根据现今图书馆领域用户画像的局限性,设计了一种基于多视角聚类的用户画像框架,该框架以读者在图书馆产生的行为数据为基础,首先,从多个业务系统中通过ETL等数据清理工具将数据汇总,利用处理及汇总后数据构建多维度多视角的读者特征体系;然后,通过基于马氏距离的多视角二分k-means算法进行多视角聚类得出若干个读者群体,根据读者群体的特征提取用户特征;最后,利用可视化工具构建读者用户画像,并根据用户画像实现对读者的精准推荐和服务。
1 一种基于多视角聚类的用户画像框架
构建用户画像的流程主要包括数据收集处理、构建多维度多视角的读者特征体系、根据不同维度组合或单一维度的用户群体进行多视角聚类、群体特征分析及用户画像这五个过程。具体如图1所示。
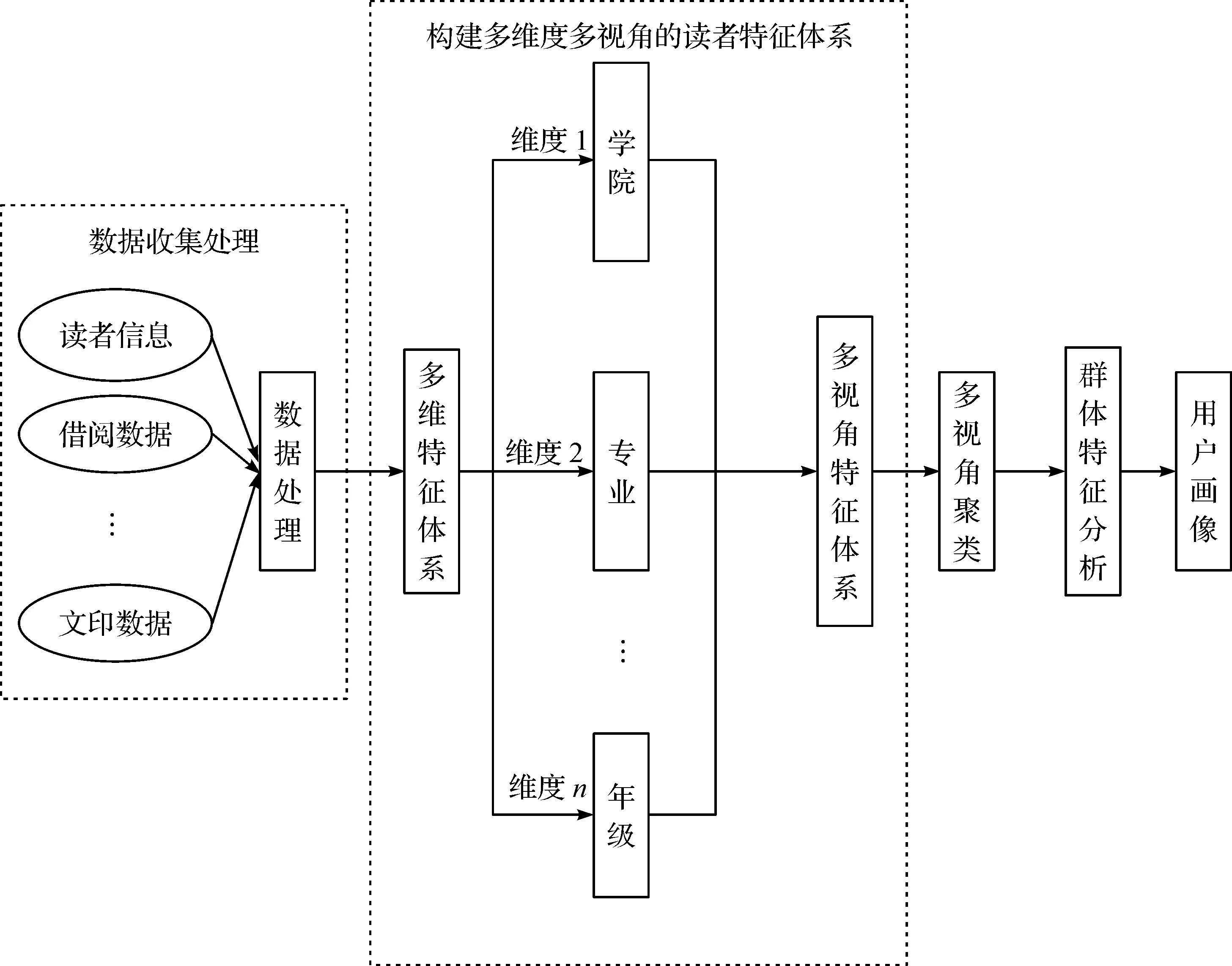
图1 用户画像流程
1.1 原始数据收集处理
图书馆用户画像,是尽可能地从海量的行为数据中挖掘出隐藏的信息,从而勾画出用户的信息全貌。在高校图书馆中的用户行为数据来自于许多不同的数据库。本研究所取到的数据为读者信息表(reader_info)、电子资源使用表(electronic_resources)、图书借阅表(book_lend)、图书馆馆藏表(book_info)、进馆数据表(gate_info)、IC空间使用数据(IC_use_info)、自助文印使用数据(print_info)。由于收集来的原始数据来自于各个不同的库,所以通过etl工具对数据进行清洗后,整合成统一规范的数据格式,最后得到的关系如图2所示。
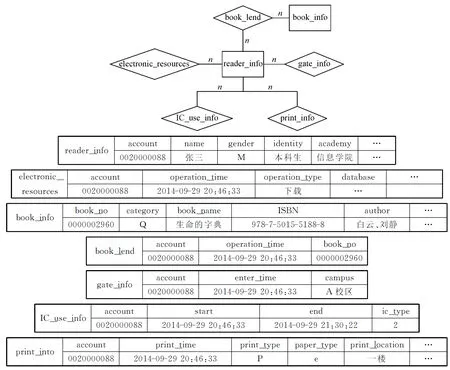
图2 表关系及结构
Fig.2 Table relationship and structure
1.2 构建多维度多视角的读者特征体系
从数据中提取用户的行为轨迹,将用户信息标签化是构建用户画像的必经过程。用户特征包含显性特征和隐性特征。在图书馆用户画像中,显性特征即读者的基本信息,如学院、专业、年级和性别等,由读者的显性特征可以构建读者特征维度,从某个维度或多个维度结合对读者进行划分;读者的隐性特征能够更好地反映读者需求,读者的隐性特征包括读者活跃度、读者借阅率、电子资源使用率、公共资源使用率和读者借阅书籍文本特征这五个不同的视角特征。
1.2.1 读者活跃度
读者活跃度最直观地表现了读者对图书馆的需求,但是不同年级、不同身份的读者在统计的时间区间内有效天数均不同。为了避免有效时间带来的影响,通过进馆次数除以有效天数来表示读者活跃度,有效天数由年级和身份决定。读者活跃度计算公式为
(1)
式中:RA代表读者活跃度;T为在时间区间内的进馆次数;D为读者在数据集时间区间内在图书馆的有效天数。
1.2.2 读者借阅率
馆藏是图书馆最重要的资源之一,读者在图书馆的主要活动也是以书籍借阅为主,因此,根据读者的借阅次数和进馆次数可以得出读者借阅率的计算公式为
(2)
式中:LR为读者借阅率;L为读者借阅次数;T为进馆次数。
1.2.3 电子资源使用率
电子资源是图书馆除馆藏资源外每年的主要投入之一,也是读者的主要活动之一,因此,有效地计算和利用电子资源的使用率能更好地反映读者的需求,计算公式为
(3)
式中:IR为电子资源使用率;E为电子资源数据库集合;dx为在x库中的下载量;sx为在x库中的搜索量;T为进馆次数。
1.2.4 公共资源使用率
除了馆藏资源和电子资源外,图书馆越来越重视公共资源对读者的吸引程度,公共资源包括阅读空间、座位和自助文印的使用,计算公式为
(4)
式中:PR为公共资源使用率;pt为自助文印使用次数;st为座位预约使用次数;rt为阅读空间使用次数,以上使用次数均为该资源预约使用次数,从预约记录和使用记录中获取;T为进馆次数。
1.2.5 读者借阅书籍文本特征
读者借阅的书籍信息最能体现读者的需求,书籍信息包括书名、中图分类、作者、出版社和出版年份。对书籍信息进行向量化表示,向量的每一维由特征项及其权重组成,权重用TF-IDF[9]的方法来计算,计算公式为
(5)
式中:w(ti,d)为特征项ti在所有信息文本中的权重;d为所有信息文本的集合;tf(ti,d)为特征项ti在所有信息本文中的词频;N为信息文本的总数;ni为文本集中出现特征项ti的文本数;分母为归一化因子。
2 基于马式距离的多视角二分k-means算法
针对多个维度结合或某一维度的读者使用多视角聚类算法进行聚类,可以得到若干个读者用户群体。利用k-means聚类算法来进行聚类,但经典k-means聚类算法随机初始化聚类中心,使得经典k-means聚类算法不能确保得到全局最优解,同时经典k-means算法基于欧式距离来定义两个个体的相似性,在多视角聚类中受属性纲量影响。基于此提出了一种基于马氏距离的多视角二分k-means算法,改进后的算法提高了运算效率,鲁棒性好。
2.1 二分k-means算法
聚类分析是数据挖掘领域最重要的研究方向之一[10],聚类分析的目标是把相同类型的数据聚到一起[11-12]。聚类算法主要被分为划分方法、层次方法、基于密度的方法、基于网格的方法和基于模型的方法这五类[13-14]。k-means算法是基于划分的方法进行聚类分析。k-means算法收敛快、易于实现[15]且对于高校图书馆的数据量比较适用,所以笔者在研究群体画像时采用此种算法进行分析。然而经典k-means算法是收敛到了局部最小值,而非全局最小值[16]。针对k-means这一局限性,国内外很多学者都做了研究。左进等[17]等通过计算数据点的紧密型排除掉离群点,使得初始聚类中心不会为离群点,从而使得聚类效果全局最优;Lasheng等[18]采用最大-最小准则算法初步确定初始聚类中心,然后通过快速近邻搜索库将聚类中心偏移到尽可能靠近实际的聚类中心。笔者引入二分k-means算法对经典k-means算法进行优化。
二分k-means算法是基于k-means算法的变种,其基本思想:首先,将所有数据集作为一个簇,放到簇集合中;然后,循环从簇集合中取出一个簇,对其进行簇数为2的k-means聚类,选择距离簇中心总和最小的两个簇放回簇集合中,直到簇集合中的簇总数达到k为止。通过二分k-means算法能有效避免经典k-means算法收敛到局部最优这一缺陷。但不管是二分k-means算法还是经典k-means算法都是利用欧式距离来计算两个个体之间的距离,欧式距离在多视角距离中受属性量纲影响,因此引入马氏距离[19]来改进二分k-means算法。
2.2 马氏距离
经典k-means算法通过计算个体间的欧式距离来表示个体的相似度,但是当属性间相关时,通过欧式距离来计算会产生重复数据,从而影响了聚类效果。同时,欧式距离受到属性量纲的影响,在多视角处理中是不利的。基于欧式距离的限制,引入马氏距离来取代欧式距离,能有效解决上述困扰。马氏距离考虑了样本不同特征之间的关系,因此可以避免数据相关特性的影响,同时两个个体之间的马氏距离与原始数据的测量单位无关,有效的避免了属性量纲的影响[20]。
对于样本矩阵X可以得到样本的均值、自相关矩阵和协方差矩阵计算公式为
(6)
(7)
(8)
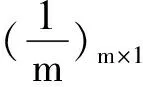
(9)
2.3 算法思想及流程
基于k-means算法容易陷入局部最优和欧式距离在多视角聚类的局限,对算法加以改进。当聚类簇数k为2时,局部最小值达到最小时全局最小值也是最小。利用这一特性引入二分思想来优化k-means算法,使得全局最小值能达到最优。同时通过马氏距离来判断聚类结果的优劣。
改进后的算法基本思想为先将全体数据集作为一个簇,计算每一个簇一分为二后的马氏距离总和,选择总和最小的那个簇进行划分。不断循环,直到达到k值后结束聚类。
基于马氏距离的多视角二分k-means算法流程:
输入多视角数据集D,聚类簇数k
过程1)将所有数据看作一个簇,计算簇中心。
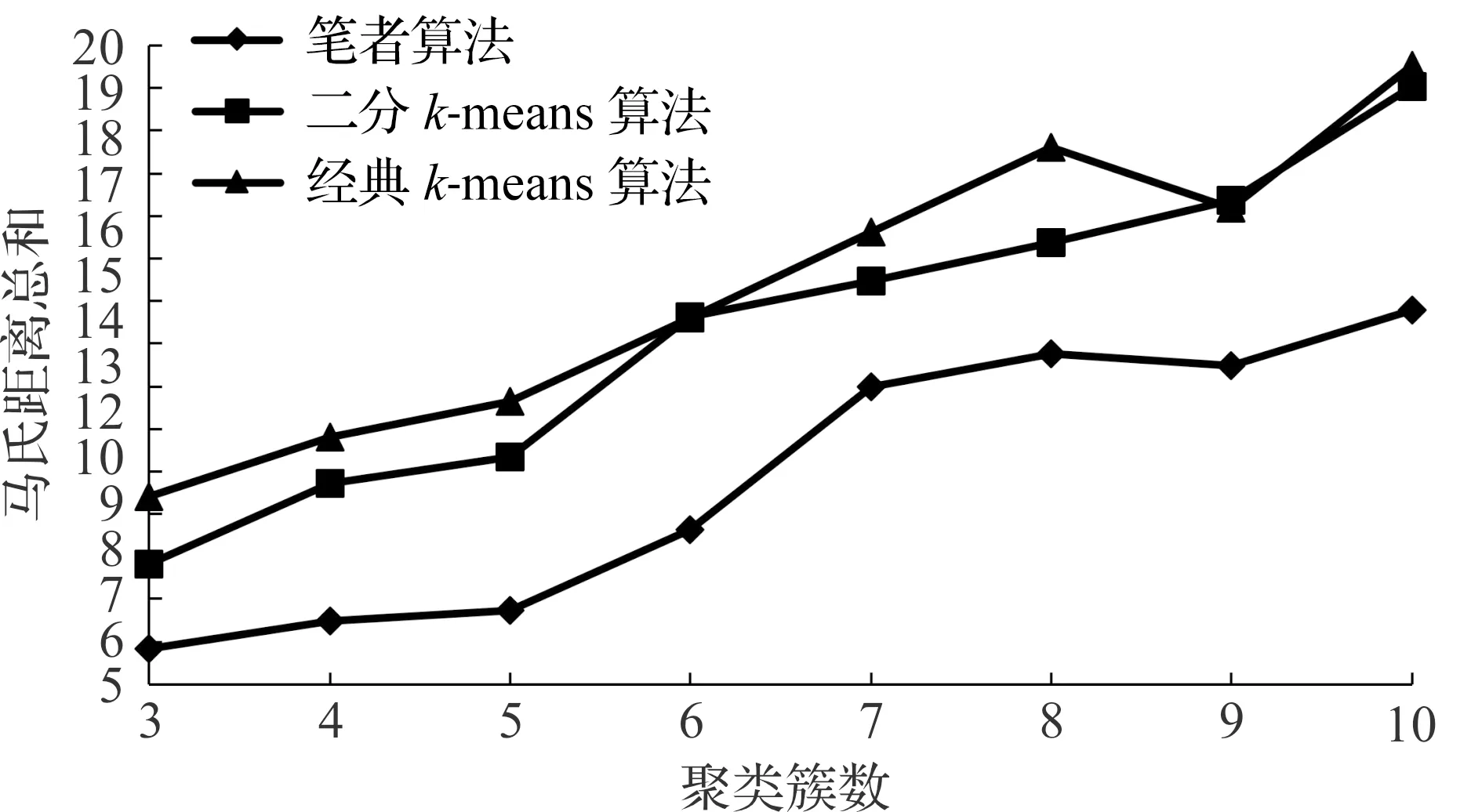
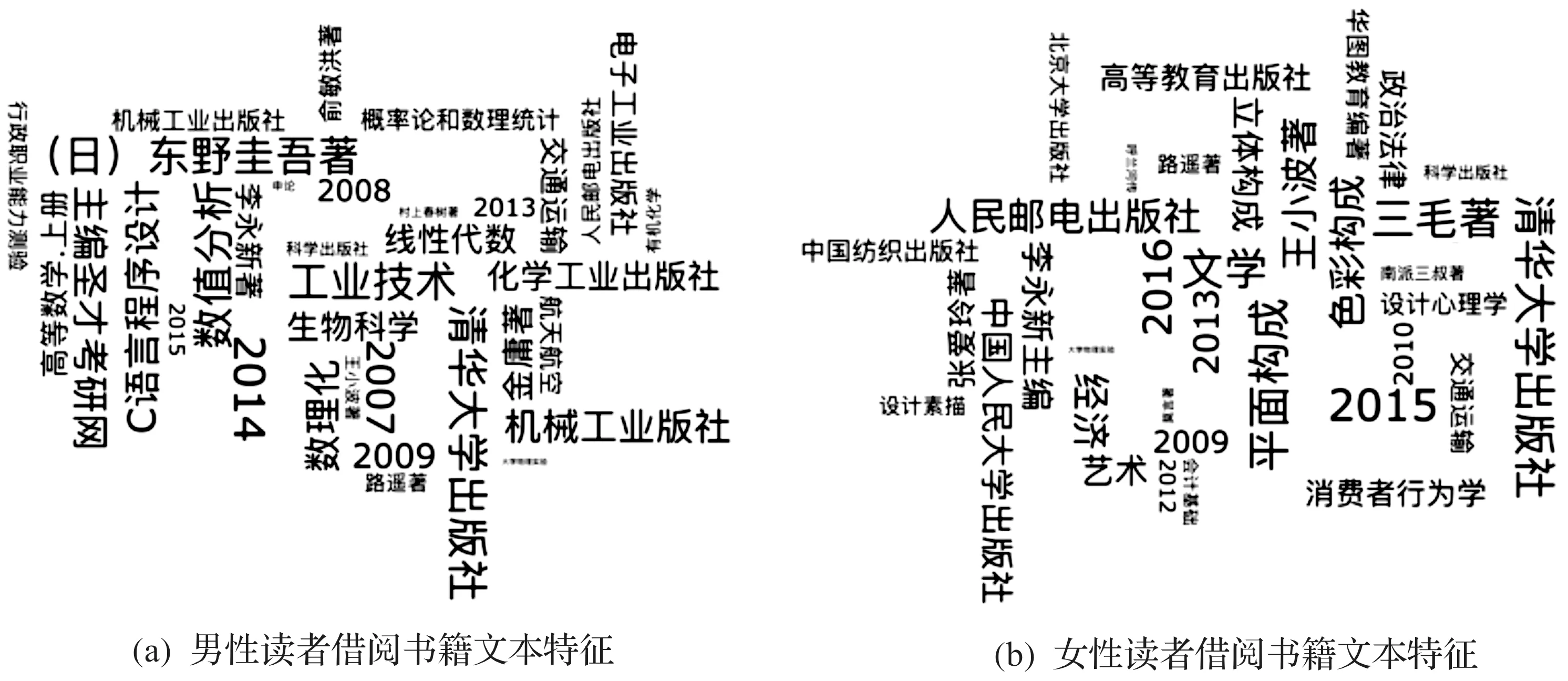
2)while 簇中心个数h 3)fori=1,2,…,hdo。 4)将第i个簇使用k-means算法进行k为2的划分。 5)计算划分后马氏距离总和。 6)比较h种划分后的马氏距离总和,选择马氏距离总和最小的划分方式。 7)更新簇的分配方式。 8)添加新的簇中心。 9)untill簇中心个数达到k。 输出簇划分C=C1,C2,C3,…,Ck。 实验选取的数据是某大学图书馆2014年9月—2017年9月的读者进馆数据共3 375 105条、图书借阅数据共691 766条、IC空间使用数据共148 145条、自助文印数据共294 969条、电子资源使用数据共8 778 776条,基于前述的数据处理方法处理后得到19 256名读者的数据。 采用本文改进后的算法与二分k-means算法和经典k-means算法对上述实验样本集针对不同的聚类簇数进行对比,计算聚类结果的马氏距离总和,总和越小代表聚类结果全局最优,聚类效果越好,对比结果如图3所示。 图3 不同算法在不同聚类簇数下马氏距离总和的变化情况 从图3可以看出:笔者算法在不同聚类簇数下的马氏距离总和均小于二分k-means算法和经典k-means算法,说明笔者算法能有效地避免局部最优,聚类效果好。除此之外,又对比了三种算法在不同聚类簇数下的效率,每个簇数下同一算法均做5 次实验取平均耗时,得到的对比结果如图4所示。 图4 不同算法在不同聚类簇数下耗时的变化情况 从图4可以看出:笔者算法处理时间远低于二分k-means算法和经典k-means算法,且耗时比较稳定。从上述两个实验结果可以看出:改进后的算法在全局最优、稳定性、效率三方面都优于二分k-means算法和经典k-means算法。 利用笔者算法对实验样本集针对学校维度将19 256名读者作为一个群体进行k为5的聚类,得到5 个读者用户群体,各群体人数、占比及各视角值范围如表1所示,其中文本特征为文本向量,无法体现范围。 表1 各群体人数、占比及各指标范围 取5个群体中人数最多且最具代表性的群体1进行分析。输出其借阅书籍文本特征,如图5所示,文本字体越大、字体越粗表示重要性越高。 根据图5所得出的文本特征结合表1以及读者个人信息得出群体的分组特征、读者分析和服务策略,如表2所示。 根据不同的维度对读者群体进行多视角聚类,可得到读者群体借阅书籍文本特征,因篇幅限制,对读者在年级和性别维度分别作多视角聚类,得到如图6,7所示的借阅书籍文本特征对比。从图6可看出:对2014级读者而言,数理化类、工业技术类和出版年份较早的权威图书比较受欢迎,其中高等数学和平面构成最受欢迎;而对2015级读者而言,经济类、艺术类和出版年份较近的图书比较受欢迎,其中自然辩证法概论和知识产权法最受欢迎。 图6 年级维度读者借阅书籍文本特征对比 图7 性别维度读者借阅书籍文本特征对比 从图7可看出:对于男性读者而言,工业技术类图书比较受欢迎,其中数值分析和线性代数最受欢迎,而对女性读者而言,文学类和经济类图书比较受欢迎,其中平面构成和色彩构成最受欢迎。 设计了一种基于多视角聚类的高校图书馆用户画像方法,包括数据处理、构建多维度多视角读者特征体系、多视角聚类、群体特征分析及用户画像五个过程;针对传统k-means算法容易陷入局部最优值的缺陷以及欧式距离在多视角聚类中的局限,提出了基于马氏距离的多视角二分k-means算法;最后根据得到的群体特征实现精确服务和推荐。实验证明:基于多视角聚类的高校图书馆用户画像方法科学有效。但是由于数据集缺少学生成绩和搜索记录,不能够更加全面地绘制用户画像,后续工作可以根据搜索记录挖掘读者随时间变化的兴趣并结合用户画像,使得用户画像更精准、有效。3 实验及分析
3.1 聚类效果和算法效率对比实验

3.2 用户画像及分析

3.3 多维度用户画像对比

4 结 论
