基于专家动态生成的协同过滤推荐算法
2020-04-09贾彭慧刘鑫一孔亚斌郗佳林
贾彭慧,刘鑫一,孔亚斌,郗佳林
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
信息技术和互联网的高速发展使人们逐渐进入了信息过载的时代[1]。推荐系统[2]因其可以根据用户需求和历史行为主动为用户提供个性化服务而成为解决这一问题的有效手段。
按照组成部分,推荐系统可分为三大类:基于内容的推荐系统、协同过滤(collaborative filtering,CF)推荐系统和混合推荐系统[3]。在推荐系统中,协同过滤[4]的应用最为广泛,在商业中取得了巨大的成就,其中包括著名的电子商务网站Amazon.com[5]。协同过滤可分为基于用户的协同过滤推荐算法(user-based collaborative filtering,UBCF)[6]和基于物品的协同过滤推荐算法[7]。文中以UBCF算法为基础展开研究。
虽然上述文献提到的方法在一定程度上提高了推荐系统的精确性,但仍然存在一些不足之处:(1)某些领域的专家用户匮乏,在数据稀缺的情况下无法直接形成专家数据集;(2)在用户中挖掘的专家数据集是固定的,并没有为每个用户建立个性化的专家数据集;(3)现有的专家用户评估模型只考虑了用户自身的因素,并没有对用户之间的关系进行考量。
针对上述问题,文中提出了一种基于专家动态生成的协同过滤推荐算法(dynamically generated expert-based collaborative filtering,DGECF)。该算法通过计算用户之间的交叉性、信任性以及趋同性三项指标值和专家因子值动态地为每个用户挖掘出特定的专家数据集,然后通过计算用户与所挖掘专家数据集之间的相似度来预测评分,最终完成推荐。实验结果表明,该算法可以提高推荐系统的精确性。
1 DGECF算法
在实际生活中,每个领域都有专业知识较为全面的人,称这些人为专家。通常对用户而言,专家的意见有较高的参考价值。为了提高推荐系统的精确性,DGECF算法为每个训练用户(训练集中的用户,简称训练用户)动态地挖掘专家数据集,再通过计算测试用户(测试集中的用户,简称测试用户)与他所对应专家数据集的相似度进行预测评分。图1给出了DGECF算法的概述图,其中包括4部分:

图1 DGECF算法概述图
(1)动态专家挖掘方法:该方法分为三部分,首先计算训练用户的指标值;其次计算专家因子值;最后根据近邻算法为每个用户建立特定的专家数据集。这部分内容将在第三节中给出详细介绍。
(2)计算测试用户与专家的相似度:文中采用一种改进的余弦相似度计算方法[13],该方法在计算用户u和专家e之间的相似度Sim(u,e)时,考虑了两个用户共同评定的物品数量,即调整因子,计算公式如下:
(1)
其中,Sue表示用户u和专家e共同评价物品的集合,Nu∩e表示用户u和专家e共同评定物品的数量,Nu表示用户u评定物品的数量,Ne表示专家e评定物品的数量。
(3)预测测试用户评分:采用Resnick公式[12]的变形,用户u对物品i的预测评分如下:
边坡稳定性影响因素选取应遵循独立性原则,防止各因素之间存在交叉情况,以避免造成指标隶属度的“冗余值”,导致评价结果的不准确。笔者结合众多文献研究,现将各影响因素分为三类两级指标:(1)自然因素:年均降雨量C11、地下水影响C12、植被覆盖现状C13、(2)设计因素:坡高C21、坡角C22、排水条件C23、加固强度C24和(3)地质因素:岩体类型C31、风化程度C32、不利结构面影响C33、坡体结构C34、黏聚力C35、摩擦角C36。
(2)
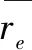
(4)精确性评估:通过计算测试用户的预测评分与实际评分的平均绝对误差(MAE)和均方根误差(RMSE),评估算法的精确性。
2 动态专家挖掘方法
在动态专家挖掘方法中,指标值的选择关系到整个算法的优劣。文中针对目前专家用户评估模型没有对用户之间的关系进行考量的情况,通过实验和数据分析,确定选择用户之间的交叉性、信任性以及趋同性这三项作为动态专家挖掘的指标值。根据计算得到的指标值,计算专家因子值,最后将专家因子值从小到大进行排序挑选出近邻专家数据集。
2.1 指标值计算
2.1.1 交叉性指标
两个用户共同评价物品的数量越多,表示用户之间的交叉性越强,用户交叉性指标值的计算如下:
(3)
其中,A(u)表示用户u与其他用户之间的交叉性指标,Nu∩v表示用户u和v共同评价物品的数量,max(N)表示用户之间共同评价物品数量的最大值。
2.1.2 信任性指标
信任因素在推荐中起到了关键作用[15-16],专家通常拥有更多的信任人数,用户信任性指标值的计算如下:
(4)
其中,T(u)表示用户u与其他用户之间的信任性指标,Mu∩v表示用户u与用户v共同拥有信任者的数量,max(M)表示用户之间共同拥有信任者数量的最大值。
2.1.3 趋同性指标
用户对相同物品的评分越接近,用户之间的差异性越小。通过计算评分差异的平均值并对其归一化,进而求得用户之间的趋同性指标值,公式如下:
(5)
其中,O(u)表示用户u与其他用户之间的趋同性指标,rui表示用户u对物品i的评分值。
2.2 专家因子计算
对于用户而言,专家因子的值越大,专家也就越专业。综合用户的交叉性指标、信任性指标、趋同性指标,定义专家因子的计算公式,如下:
Exp(e)=α*A(u)+β*T(u)+γ*O(u)
(6)
其中,α,β,γ表示各部分所占权重,α+β+γ=1。
2.3 专家数据集选取
在推荐系统领域中,基于近邻的方法[17]是最早使用的方法之一,不同的专家会产生不同的推荐效果,根据为每个用户建立的专家数据集中的专家因子挑选k位近邻专家作为该用户的专家数据集。
3 实 验
3.1 实验数据集
实验使用来自基于社交网络的电影推荐系统FilmTrust数据集(https://www.librec.net/datasets.html)[18]对算法进行验证。该数据集由两部分组成,即用户评分集和信任集。
用户评分集中包括1 508位用户对2 071部电影的35 494条评分数据,评分值的范围是[0.5,4.0],分值的高低代表了用户对电影的偏好程度。信任集中包括用户之间的1 853条信任关系评分数据,评分值为1或者空,1代表用户之间存在信任关系,空值代表用户之间不信任。
3.2 评估标准
精确性是评估推荐系统过程中最基本的指标之一[19]。文中分别采用MAE和RMSE作为精确性度量标准[20]。
MAE越小,推荐越准确。假设预测用户评分集合为{p1,p2,…,pn},与之相对应的实际用户评分集合为{q1,q2,…,qn},n为所有预测评分商品的数目,则MAE的计算公式如下:
(7)
RMSE越小,推荐质量越高,RMSE的计算公式如下:
(8)
3.3 实验设计与结果分析
文中分别对UBCF算法、RUBCF算法和DGECF算法进行了实验,通过计算实验结果的MAE和RMSE对算法的精确性进行评估。为了提高仿真结果的真实性,实验将FilmTrust数据集中的评分集按照8∶2的比例随机分成训练集和测试集。测试用户中有一些用户属于新用户,即从未有过历史记录的用户。对于新用户,DGECF算法的实验处理方法是:首先在测试集中确定新用户所预测的物品,然后在训练集中找出对该物品已进行过评分的用户,最后将这些用户对该物品评分的均值作为新用户的评分。在专家因子的公式中,通过枚举法改变权重值来观察MAE和RMSE的变化,最终发现当α=0.3,β=0.4,γ=0.3时,精确性最高。
(1)不同算法下MAE和RMSE的比较分析。
UBCF和RUBCF算法都使用余弦相似度作为相似性的度量方法,所不同的是RUBCF算法在UBCF算法的基础上使用了Resnick公式。为了便于比较,文中提出的DGECF算法选取与UBCF和RUBCF算法相同的近邻值(50,100,150,200,300,400,500,600,700和全部邻居)进行预测评分,并计算MAE和RMSE。实验结果如表1所示。

表1 MAE和RMSE
由表1可以看出,在UBCF算法中,随着近邻值k的增加,MAE和RMSE都略微下降,当近邻值取全部邻居时,MAE和RMSE最低,分别为:2.122 5和2.334 2;在RUBCF算法中,MAE和RMSE均随着k的增加呈现出先微量下降后微量上升的趋势,当k取400时,MAE和RMSE最低,分别为:0.671 6和0.874 3;在DGECF算法中,MAE和RMSE均随着k的增加先微量下降再微量上升最后趋于平缓,并且当近邻值k取400时,MAE和RMSE最低,分别为:0.625 8和0.816 0。
(2)不同算法下MAE和RMSE平均值的比较分析。
由表2可以看出,文中提出的DGECF算法的MAE和RMSE平均值最低,分别为:0.627 4和0.818 8,相对于UBCF算法和RUBCF算法,MAE分别降低了75.18%和6.90%,RMSE分别降低了69.73%和6.54%,说明DGECF算法具有更高的精确性。

表2 MAE和RMSE的平均值
4 结束语
传统协同过滤推荐算法中数据稀疏性严重影响推荐精确性的问题,提出了一种基于专家动态生成的协同过滤推荐算法(DGECF),并通过在FilmTrust数据集上的实验结果验证了该算法的有效性。下一步将在新用户与DGECF算法的结合、指标值的选取策略、相似度的计算方法等方面继续进行研究和完善。
