基于Haar算法的云穿衣系统研究
2020-04-08王金环徐卫军李宝敏
王金环,徐卫军,李宝敏
(1.西安培华学院 智能科学与信息工程学院 计算机系,陕西 西安 710125;2.西安工业大学图书馆,陕西 西安 710021;3.西安工业大学 计算机学院,陕西 西安 710021)
0 引 言
网购已成为当前人们生活中一种非常普遍的消费方式。然而在网购衣服的时候,当你找到了自己心仪的衣服款式,而这种款式穿在自己身上的效果却不得知。以往的做法:只能把衣服买回来试穿后才能感觉到是否美观、合身、称心。本项目解决了人们网购衣服时的困扰,从而为人们网购带来了极大的便利。
从技术层面来讲,本项目利用计算机技术和一定的算法在云网的平台下对实物进行识别的尝试,对于许多通过网购而需要尝试的物品都可以通过该技术得到验证。这一技术改变了人们身临其境试穿的感官常规习惯和对网购物品体验的尝试,给人们以全新的理念和方式,给生活带来极大的方便。它是将智能识别技术[1]在人们日常生活一些体验进行普及推广应用的一种尝试,其在社会和人们日常生活中具有很实用的意义和效应,尤其在当今信息主导社会发展,将带来一定程度的社会经济效益。
1 云穿衣系统总体设计
(1)云穿衣系统总体架构如图1所示。

图1 系统总体架构
●从摄像头获取图像;
●从采集的图像中分析出人脸、人体的几个关键识别点[2-3];
●将捕获的图像作为贴图,放置在场景的最后面一层;
●获取识别点的坐标[4-5];
●计算目标大小和位置;
●根据目标大小和位置,针对3D图元进行变换;
●渲染输出图元;
●由OM自动合并图像。
(2)实现部分详述。
●预载入分类器特征文件;
●获取图像;
●利用积分图对每个像素计算特征值;
●通过决策树筛选并得到目标物体窗口;
●计算窗口大小及位置;
●根据窗口的大小、位置改变3D模型的坐标的缩放及转换;
●将获取的图像转换为Texture2D作为背景贴图;
●渲染3D[6-7]模型;
●由DirectX 12[8]的Output Merger自动合成;
●输出图像。
2 Haar算法简介
2.1 Haar算法
Haar算法[9]特征值反映了图像的灰度变化情况。
Haar特征有边缘特征、线性特征、中心特征和对角线特征。利用这些特征组合出仅有黑色矩形和白色矩形的特征模板,文中定义此模板的特征值为:白色矩形像素的和减去黑色矩形像素的和。以下进行举例:
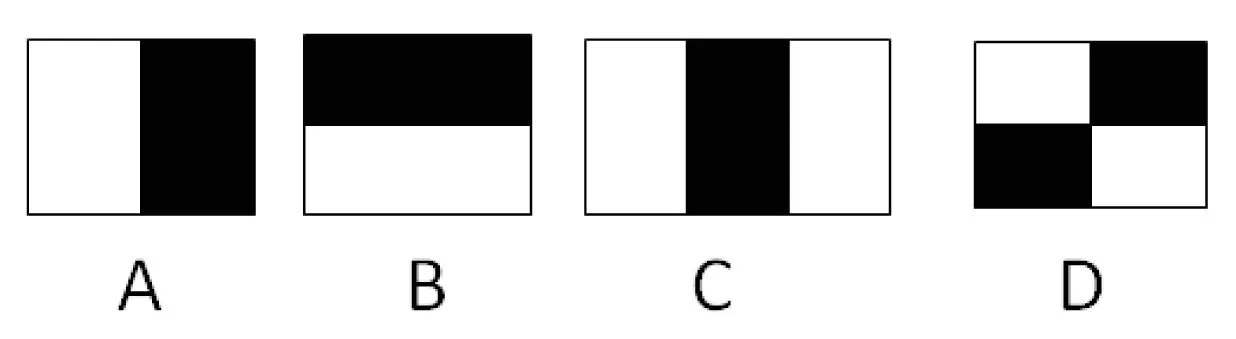
图2 Haar算法特征值图像
对于图2中A、B、D三种模型,其特征值计算公式为v=Sum白-Sum黑,而对于C模型,为了使两种矩形区域像素数目一致,需要为黑色像素和乘2,因此公式为:v=Sum白-2*Sum黑。
计算过程中,通过调整模板的大小和位置,就可以得出很多特征。这些特征的值被称为“特征值”。由于特征量过于庞大,可以利用图3积分图来进行计算。
这里通过图像大小一样的一个二维数组来表示积分图,在该二维数组中,(x,y)位置的值是在原始图像中从(0,0)到(x,y)处的像素值的和。
对应图3中的a、c图所示的haar特征,计算公式如下:
SAT(x,y)=SAT(x,y-1)+SAT(x-1,y)+
I(x,y)-SAT(x-1,y-1)
RecSum(r)=SAT(x-1,y-1)+SAT(x+w-1,
y+h-1)-SAT(x-1,y+h-1)-SAT(x+w-1,y-1)
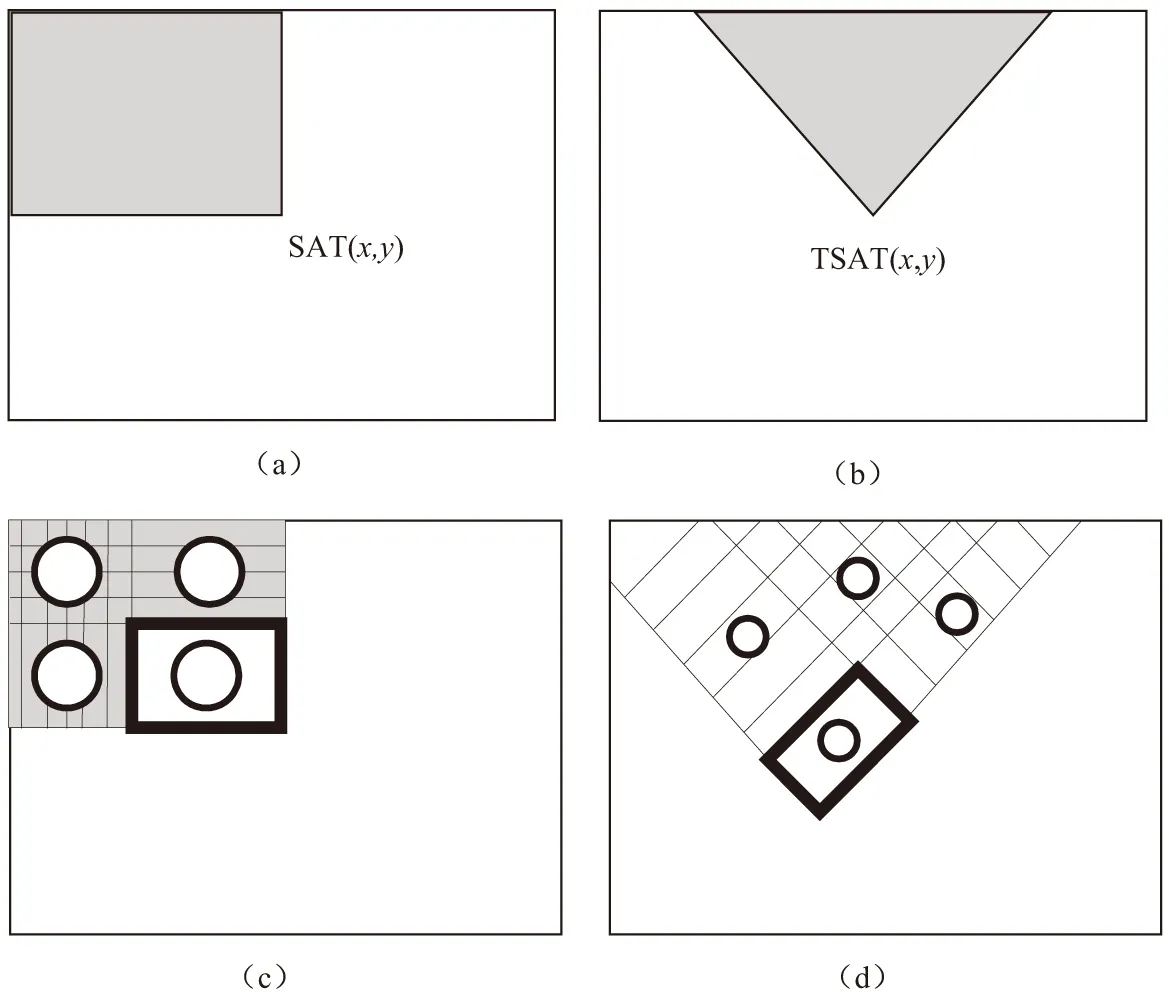
图3 积分图
其中,SAT表示积分图中的值,RecSum表示(x,y)处的长宽为(w,h)的区域的和。以RecSum为基础来计算haar特征。同理,对b图和d图对应的haar特征计算公式如下:
RSAT(x,y)=RSAT(x-1,y-1)+RSAT(x+1,
y-1)+I(x,y)-RSAT(x,y-2)+I(x,y)+I(x,y-1)
RecSum(r)=RSAT(x-h+w,y+w+h-1)+
RSAT(x,y-1)-RSAT(x-h,y+
h-1)-RSAT(x+w,y+w-1)
2.2 级联分类器(CASCADE)实现概述
2.2.1 弱分类器
弱分类器用来表示一个最基本的Haar-like[10]特征,通过对输入图像计算得到的Haar-like特征值与最初的弱分类器的特征值进行比较,来判断所输入的图像是否为目标物体。弱分类器通过孵化训练就成为最优弱分类器。
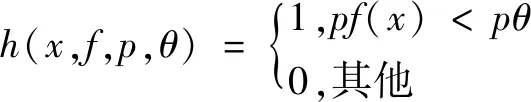
一个弱分类器h是由x、f、p、θ(x:子窗口图像,f:一个特征,θ:阈值)四部分组成。p的作用是控制不等式的方向,使得不等式都是<号,形式方便。这里是通过分类和回归树进行识别,如图4所示。
在分类的应用中,每一个非叶子节点都表示一种判断,每一条路径都代表一种判断的输出,每一个叶子节点代表一种类别,并作为最终判断的结果。
一个弱分类器就是图4类似的决策树,最基本的弱分类器只包含一个Haar-like特征,也就是说它的决策树只有一层,被称为树桩(stump)。
要注意的是如何来确定每一个节点判断的输出,在对输入图像的特征值与弱分类器中的特征进行比较时,需要有一个阈值才可以。判定其为人脸的条件是:只有当输入图像的特征值大于该阈值时才成立。对最优弱分类器的训练过程就是在寻找一个合适的分类器的阈值,使得该分类器对所有现有的样本的判读误差降为最低。获得阈值的操作过程如下:
(1)对于每个特征f,计算所有训练样本的特征值,并将其排序。

图4 回归树
(2)对排好序的特征值扫描一遍,对每个元素,计算求得以下四个值:
(a)全部人脸样本的权重的和t1;
(b)全部非人脸样本的权重的和t0;
(c)在此元素之前的人脸样本的权重的和s1;
(d)在此元素之前的非人脸样本的权重的和s0。
(3)最终在获得每个元素的分类误差对应表中寻找r值最小的元素,并将该元素作为最优阈值。
r=min(s1+(t0-s0),(s0+(t1-s1)))
2.2.2 强分类器
强分类器需要T轮的迭代,具体操作如下:
(1)给定训练样本集S(共N个样本),其中X和Y分别对应于正样本和负样本,T为训练的最大循环次数;
(2)初始化样本权重为1/N,即为训练样本的初始概率分布;
(3)第一次迭代训练N个样本,得到第一个最优弱分类器,步骤见2.2.1节
(4)提高上一轮中被误判的样本的权重;
(5)将新的样本和上次被误判的样本放在一起进行新一轮的训练。
(6)循环执行步骤4-步骤5,T轮后得到T个最优弱分类器。
(7)对T个最优弱分类器组合得到强分类器。
组合方式如下:
强分类器的结果就是由所有弱分类器加权求和的结果与其分类结果平均值进行比较得到最终结果。
2.2.3 目标Haar分类器
为了使得检测的结果更加准确,需要进行级联分类器训练。这涉及到Haar分类器的另一个体系—检测体系。检测体系是以现实中的一幅大图像作为输入,然后对图像进行多区域、多尺度的检测。由于训练的时候用的照片一般都是20*20 mm左右的小图片,所以对于大的目标物体,还需要进行多尺度的检测。在区域放大的过程中会出现同一个人脸被多次检测,这还需要进行区域的合并。
无论哪一种搜索方法,都会为输入的图像输出大量的子窗口图像,这些子窗口图像,经过筛选式级联分类器多次地被每一个节点筛选、抛弃或通过。它的结构如图5所示。

图5 Haar分类器结构
级联强分类器的策略一般是:将若干个强分类器由简单到复杂排列,经过训练使得每个强分类器获得较高检测率和低的误识率,比如几乎99%的目标物体可以通过,但50%的非目标物体也可以通过,这样如果有20个强分类器级联,那么它们的总识别率为0.99^20,约为98%,错误接受率也仅为0.5^20,约为0.000 1%。这样的效果就可以满足现实的需要。
设K是一个级联检测器的层数,D是该级联分类器的检测率,F是该级联分类器的误识率,di是第i层强分类器的检测率,fi是第i层强分类器的误识率。如果要训练一个级联分类器,达到给定的F值和D值,只需要训练出每层的d值和f值:
dk=D,fk=F
级联分类器的要点就是如何训练每层强分类器的d值和f值使其达到指定要求。级联分类器在训练时要考虑弱分类器的个数和计算时间的平衡,以及强分类器检测率和误识率之间的平衡。
3 云穿衣系统3D模型
3D模型:通过调用DirectX3D[11]接口实现对3D模型的渲染。
3.1 图形管线综述
图形管线是运行在图形硬件上处理流程中的一部分,叫做Stages。将数据推入图形管线就可以获取3D场景的2D图像。还可以利用Stream Output Stage来流式输出处理后的集合体。某些图形管线可以被编程,可以被编程的图形管线被称作Shaders,编程图形管线使用高级着色语言(HLSL)。
3.1.1 图形管线中的着色器
图形管线中的着色器如图6所示。
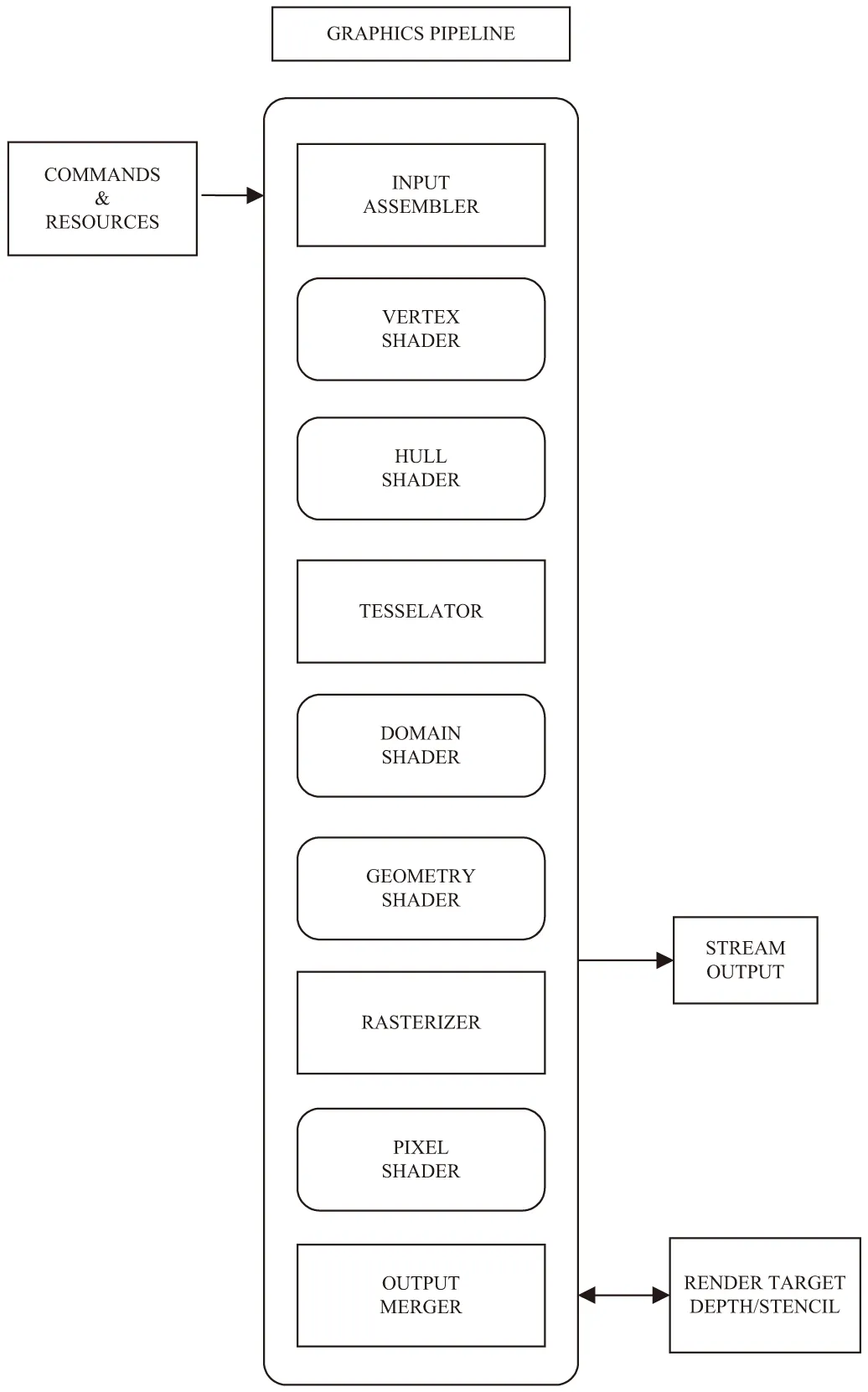
图6 图形管线着色图
3.1.2 着色器各部分的功能
(1)The Compute Shader(CS)。
CS专门用来进行任何类型的计算,CS利用CPU平行计算的优势,可以处理很多对性能要求较高的计算,如碰撞检测等。
(2)Input Assembler (IA) Stage。
这是图形管线中的第一个Stage,这个Stage是静态的,不可编程的。用D3D Device配置IA,以便IA可以理解如何创建图元。需要提供输入布局给IA,以便IA了解如何读取顶点数据。IA还有一个功能,就是将图元放到一起,并附加到系统根据图元生成的数据上。这些数据被称为“语义”。例如输入布局可以是这样的:
D 3D11_INPUT_ELEMENT_DESC layout[]=
{
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0,
D 3D11_INPUT_PER_VERTEX_DATA, 0},
};
这个输入布局告诉IA,每个顶点缓冲区有一个元素,语义为“Position”。它还说明了这个元素从第一个顶点字节包括了3个浮点数,每一个是32位,4个字节。
(3)Vertex Shader (VS) Stage。
VS是第一个可编程Stage (Shader),必须为这个Stage编写独立的程序。VS Stage用来处理所有图元的顶点数据。VS可以处理顶点的变换、缩放、光照、置换贴图等。
最简单的VS程序如下所示,它直接将输入的顶点输出。
float4 main(float4 pos:POSITION) : SV_POSITION
{
return pos;
}
Vertex shader直接返回了输入的位置。注意参数中的POSITION在Pos的后面,这是语义的简单的例子。在输入给IA的顶点缓冲区布局中说明了数据的语义为POSITION,于是在这里通过POSITION获取。
(4)Hull Shader (HS) Stage。
这是三个可选着色器中的第一个着色器。三个可选着色器统称为Tesslation Stages,包含了Hull Stage、Tessellator、Domain Shader,它们一起工作并实现了如何进行曲面细分。
曲面细分取出一个图元对象,然后划分成多个小部分,以便增加模型的细节。它可以以极快的速度在图元出现在屏幕之前在GPU上创建新的图元。
Hull Shader是一个可编程的Stage,Hull Shader可以为曲面细分后的图元添加细节,它会将数据发送给Tessellator Stage和Domain Shader Stage。
(5)Tessellator (TS) Stage。
Tessellator Stage是曲面细分的第二Tessllator Stage不可编程。它从HullShader中获取数据,然后将图元进行细分,最后将数据输出给Domain Shader。
(6)Domain Shader (DS) Stage。
这是曲面细分的第三步。这是一个可编程的Stage。这个Stage从Hull Shader中取出顶点位置,然后变换从Tessllator Stage中取出顶点来为图元添加细节。
(7)Geometry Shader (GS) Stage。
这是另一个可选的可编程Shader。它接受图元作为输入,然后输出另一个图元,与Vertex Shader不同的地方在于,这个Shader可以利用一个图元创建另一个图元,而Vertex Shader不能创建新的图元。这个Shader常常用来创建粒子特效。
(8)Stream Output (SO) Stage。
这个Stage用来从管线中获得顶点数据。
(9)Rasterizer Stage (RS)。
光栅器输入向量信息(图形或图元),然后将它们转换为像素。它还将不出现在视口中的图元裁剪掉。
(10)Pixel Shader (PS) Stage。
这个Stage计算和修改每个将会在屏幕上出现的像素,比如光照信息等,这是一个可编程Shader。
PS的功能在于,计算每个Pixel Fragment的最终颜色,Pixel Fragment是每个可能被显示在屏幕上的像素。举个例子,有一个单面的矩形在一个单面的圆后面,矩形的像素和圆的像素都是Pixel Fragments,它们都有机会被写入屏幕,它发现圆的深度数据小于矩形的,于是只有圆的像素会被显示到屏幕上。PS将会输出一个4D的颜色数据。举一个简单的例子:
float4 main():SV_TARGET
{
return float4(1.0f,1.0f,1.0f,1.0f);
}
这个像素着色器直接将每个将会出现在屏幕上的像素设置为白色。
(11)Output Merger (OM) Stage。
这是渲染管线的最后一个部分。这个Stage将会获取每个Pixel Fragment的深度、镂空信息,来决定最终哪些像素可以被渲染到渲染目标上。
3.2 Direct X12工作
DirectX12工作主要包括以下四个方面:
(1)Pipeline State Objects (PSO)。
PSO指的是ID3D12PipelineState这个接口,利用Device的CreateGraphics Pipeline State()方法来创建。这个结构体将会决定渲染管线的状态。
(2)The Device。
Device指的是ID3D12Device接口。Device是一个用来创建CL,PSO,Root Signatures,CA,Command Queues,Fences,Resources,Descriptors以及Descriptor Heaps的虚拟适配器。通过D3D12CreateDevice()函数来创建Device。
(3)Command Lists (CL)。
CL指的是ID3D12CommandList接口,使用CL来分配需要在GPU上执行的命令。
(4)Bundles。
Bundles指的是ID3D12CommandList接口,Bundles是一组经常被重用的命令,因为CPU在创建命令的时候很浪费时间,因此命令的重用对提升效率很有作用。
3.3 Command Queues (CQ)
CQ指的是ID3D12CommandQueue接口,CQ还用来更新资源映射。
3.3.1 Command Allocators (CA)
CA指的是D3D12CommandALlocator接口,是显存中CL和Bundles所储存的空间。
3.3.2 Resource
Resource包括在构造场景时需要用到的数据。它是储存了几何体、贴图、着色器数据的可以被图形管线访问的大块内存。
3.4 资源类型
资源类型是指资源所保存的数据的类型。包括:Texture1D、Texture1DArray、Texture2D、Texture2DArray、Texture2DMS、Texture2DMSArray、Texture3D、Buffers (ID3D12Resource)。
3.5 Descriptors (Resource Views)
Descriptors是一个结构体,用来告诉Shaders哪里可以找到资源,以及如何解释资源数据。可以为同一个资源创建多个描述符,用来以不同的方式传递给不同的Stage。
举个例子,可以创建一个Texture2D资源,然后创建一个渲染目标视图以便使用资源作为输出缓存的管线。描述符只能被放置在描述符堆中,不能储存在内存中。
3.5.1 Descriptor Tables (DT)
Descriptor Tables是一个描述符数组。Shader可以从描述符堆中访问描述符,通过Root Signature的Descriptor Tables的索引。为了从Shader中访问描述符,应该给Root Signatures的Descritpro Tables进行索引。
3.5.2 Descriptor Heaps (DH)
描述符堆表示的是ID3D12 Descriptor Heap接口,是一个占用大段内存的描述符列表。
3.6 Root Signatures (RS)
Root Signatures定义了Shader访问的数据(资源)。Root Signatures类似于一个函数的参数列表,函数就是Shader,参数列表就是Shader访问的数据的类型。
(1)Root Constants是一个内联的32位数据(DWORD)。这些数据直接储存在Root Signature中,因为内存限制了Root Signature,所以把Shader可以访问的经常改变的数值放置到这里。
(2)Root Descriptors是可以被Shader经常访问的内联的Descriptors。占用64位虚拟地址(2 DWORDS)。
(3)Descriptor Tables由偏移量和长度组成,位于Descriptor Heap中,Descriptor Tables只有32位。不限制其中保存的Descriptor数量。
3.7 Resource Barriers
Resource Barriers被用来改变资源的状态或者资源的子资源的使用。
有三种资源的种类:
(1)Transition Barrier用来转换资源以及子资源的状态。
(2)Aliasing Barriers与Tiled Resources一起使用。
(3)UAV Barriers用来确保读写操作已经完成。
3.8 Fences与Fence Events
Fences与Fence Events会指示GPU是否在执行CQ。Fences指的是ID3D12Fence接口,通过Device的CreateFence()来创建,Fence Events通过CreateEvent()方法来创建。
4 关键技术实现
通过计算机软件建立人体以及人脸的模型,利用Haar算法对采集到的数据进行匹配,匹配成功后则判定该物体为人体,通过硬件发射激光测量出深度场,并结合光源方向、物体明暗情况、人体模型的匹配结果,综合判定人体的旋转角度,然后将旋转角度赋予衣服的模型,将渲染获得的图像与采集到的图像[12]叠加,最后显示到显示屏上,就得到了穿上衣服的效果。
通过网格平均采样的方式,获得图像中部分点的亮度,根据亮度判断物体明暗情况,并结合图像背景,判断出光源位置。
云服务器负责接收商户提交的关于衣服的数据(照片、尺寸等),建立出衣服的3D模型,并输出一些有关衣服与人体适配的参数,提供给客户端进行下载,客户端需要结合参数合成衣服的动画并渲染模型以及合成。
具体要解决的技术问题:(1)首先解决采集物的信息,采集手段与信息的处理;(2)对采集到的人与物等信息进行识别;(3)在云平台上[13]进行人与衣服匹配的信息处理;(4)将处理后的信息提交给人去鉴赏。
5 实验效果
从摄像头或客户端捕获图像,见图7。

图7 捕获图像
从收到的图像中识别出人脸、肩膀部位,见图8。
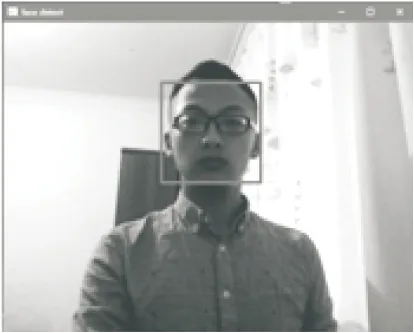
图8 识别图像
基于机器学习[14]以及Haar算法识别出特定的物体,如人脸,调用DirectX进行渲染,通过DirectX 12用显卡,进行图元的渲染。
由DirectX 12渲染管线中的OM直接合成图像,然后绘制到hwnd上或输出图片,见图9。

图9 合并图像
6 结束语
本项目在实践初期经常遇到识别不准的问题。经过研究发现,是由于样本数量不足导致的,后期将精力放在了样本的采集上,使得识别精确度大幅提高。
(1)利用物体识别算法对物体大小的侦测并不完全靠谱,应当对物体的某些小区域进行识别,根据多个小区域之间的距离计算出物体的大小,这才是合适的做法。
(2)在物体识别的过程中,摄像头扮演的角色十分重要,因此,需要高精度摄像头,摄像头产生的杂色会严重影响到物体识别的精确度。
(3)这是智能识别技术在网购衣物方面的一次尝试,尚存在许多不尽人意的地方,有待今后更进一步的研究和学习,使其更加趋于完善和成熟。
