基于机器学习的阿尔兹海默症分类预测
2020-04-06李彩范炤
李彩,范炤
1.山西医科大学基础医学院,山西太原030001;2.山西医科大学转化医学研究中心,山西太原030001
前言
阿尔兹海默病(Alzheimer′s Disease,AD)是一种以认知和智力损害、行为生活能力下降为主要特点的神经退行性脑疾病,发病原因尚不明确,且缺少有效彻底的治疗方案,是临床上导致痴呆的主要原因[1-2]。轻度认知障碍(Mild Cognitive Ⅰmpairment,MCⅠ)是介于正常衰老和痴呆之间的一种过渡状态,在6年后有80%转化为痴呆[3]。如果在AD 早期阶段对患者进行干预治疗,可延缓AD 发病时间[4]。所以,针对早期AD患者的高效诊断、识别AD的前驱阶段的研究十分有必要。目前广泛应用于AD 分类预测的办法是应用各种机器学习算法,利用单模态影像学数据或多模态影像数据,或结合人口统计学特征和遗传学资料作为特征变量,以寻求最佳分类预测解决方案。逻辑回归已经用于多种临床应用[5-7],但对AD 分类还少有研究,逻辑回归的大量应用和迅速发展为其用于AD 分类提供了良好借鉴。Challis等[8]采用贝叶斯高斯过程逻辑回归对77 例受试者分类,区分正常老年人(Normal Controls,NC)和早期轻度认知障碍(Early Mild Cognitive Ⅰmpairment,EMCⅠ)患者、EMCⅠ患者和AD 患者之间的差异,结果并不理想,且模型样本量相对特征数量较小,可能存在过拟合问题。此外,该模型没有考虑正规教育年限和性别对疾病的影响。Desikan 等[9]用逻辑回归建立自动核磁共振成像(Magnetic Resonance Ⅰmaging,MRⅠ)测量内嗅皮层厚度、海马体积和超边缘回厚度,以识别MCⅠ患者和AD 患者的模型,该模型虽然在临床诊断的AD 和MCⅠ群体得到推广,但在存在一系列认知障碍和痴呆亚型的临床环境中,这些程序可能不太准确。已有的研究要么是使用单一影像学方法,要么样本含量不大,所得出的准确率都不是很高。由于使用多模态影像学数据检测会给患者带来经济压力,应用其他模型的分类器虽然获有不错的分类精确度,但在临床实际应用中仍存在困难。本研究基于结构性MRⅠ(Structural MRⅠ,sMRⅠ)影像学资料、人口统计学特征(年龄、性别、受教育程度)和简易智力状态检查量表(Mini-Mental State Examination,MMSE),提出来一种基于L1 正则Logistic 回归(L1-Regularized Logistic Regression, L1-LR)特征选择和自动识别NC、EMCⅠ患者、晚期MCⅠ(Late MCⅠ,LMCⅠ)患者和AD 患者的辅助诊断工具,使病程分类更加细化,更清楚准确地判断病程阶段。
1 方法
1.1 预处理及特征分析
本研究把NC、EMCⅠ患者、LMCⅠ患者和AD患者这4 组作为研究对象,进行sMRⅠ,得到三维结构图像。用Freesurfer工具箱进行一系列算法,sMRⅠ图像经空间标准化、图像平滑、分割、调制等预处理,计算得到各个大脑区域的面积、体积等形态学指标。
提取的形态学指标包括海马亚区体积(Hippocampal Subfield, HS)、皮层体积(Cortical Volume,CV)、皮层表面积(Surface Area,SA)、皮层下体积(Subcortical Volume, SV)、皮层厚度(Cortical Thicknesses,TA),作为特征选择的基础。
1.2 L1-LR方法
在特征选择和分类之前,首先要对数据进行归一化处理,把全部数据映射到0~1。转换的函数为(X - Min)/(Max - Min)。
1.2.1 L1-LR特征选择 本研究的每位研究对象均有272个形态学指标,涵盖全部大脑的皮层和海马亚区。文献[10]指出AD病变脑区并非全脑,若使用全脑特征过于冗余,影响分类效果,所以必须进行特征选择。
L1-LR是一种组合的机器学习的特征选择方法,根据每个特征的最大数似然函数(Log-Likehood,LL)值,选择对分类模型准确率的因变量的贡献率达到一定程度的指标才进入分类模型,剔除无贡献或贡献很小的特征变量。偏差值D=-2(当前模型的LL值-饱和模型的LL 值)。饱和模型指各模型参数相同,似然值等于1。D值越小代表当前特征越重要。当加入一个新特征,D值和似然比的减小等价。当样本量N足够大时,似然比呈分布,因此用似然比当作判断某一特征的依据。加入某一特征,如果前后模型偏差值的差大于或等于某一限定值,则认为此特征在类的判定中有比较大的贡献,否则认为此特征冗余。
本研究的特征选择分两部分完成特征空间维数压缩。首先,选择272 项sMRⅠ数据进行L1-LR 方法筛选,并按照贡献率大小进行排序,并组成特征数据集;然后,在272 项sMRⅠ数据的基础上引入年龄、性别、受教育程度、MMSE 量表评分,共276 项指标,再次使用L1-LR 方法筛选,组成新的特征集,得到用于训练分类器的特征集合。L1-LR特征选择的过程为:
(1)i= 1,令S=φ,R=(x1,…,xk);
(2)i=i+ 1,k*= arg minkDk,k= 1,…,‖R‖,‖R‖为集合R的势;令S=S⋃{xk},R=R{xk};
(3)对任何非负λ,正则化形式为L(λ,β) =arg min(y-X′β)2+λP(β);其中P(β)代表正则化项;
(4)若Di-1-Di<[]-1(0.01)循环结束;且S=S{xk*};否则执行(2);直至选出所有最优特征,算法结束。
A{a}代表从集合A中剔除元素a。在此算法中,两模型D值之差可近似看作自由度为DF的χ2分布。DF 大小取决于评价的特征数,限值定为0.01。当[]-1(p)为限值p时,自由度为DF的χ2分布的倒数。
1.2.2 L1-LR 分类模型 L1-LR 模型是一种稀疏的逻辑回归模型[11],模型是在广泛应用于二分类的逻辑回归模型[12]的损失函数中加入惩罚项,正则化技术[13]能解决过拟合问题,提高鲁棒性,优化模型分类能力。在样本数相对于样本特征维数有点小的数据集中,L1-LR性能优于其他模型。
响应变量y∈{0,1},每次观测的p个预测变量值表示成向量,x=[x1,x2,…,xp]对应的响应变量隶属于类别1的后验概率:
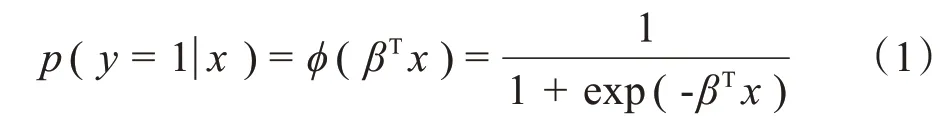
其中,β=(β1,β2,…,βp)为回归模型参数。
假定存在n个训练样本Dn={(xi,yi)}依据样本数据及隶属类别Dn去除β,优化损失函数为对数似然函数:
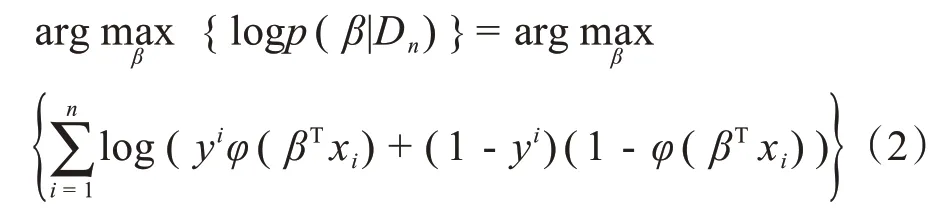
依据最小绝对收缩和选择算法的思想,在逻辑回归的损失函数中加入对模型系数的L1 范数惩罚项,得到L1-LR模型函数:
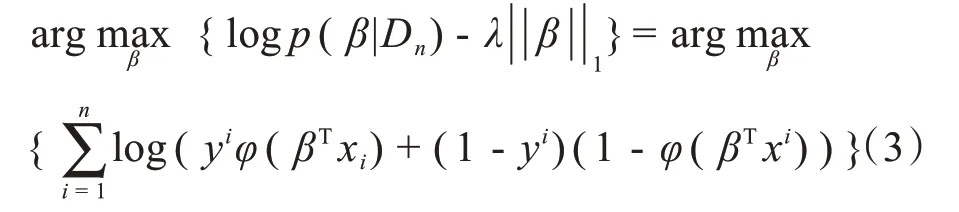
本研究比较了另外两种常用的二分类模型,一种是L1 正则支持向量机(L1-Support Vector Machine,L1-SVM),是在AD 二元分类中最常使用的支持向量机的决定函数中加入L1 惩罚项,试图找到性能更好的SVM 模型[14]。另一种是梯度提升树(Gradient Boosting Decison Tree, GBDT),是一种迭代的决策树算法,可以灵活处理各种类型的数据,鲁棒性强[15]。有研究指出该机器学习算法的预测准确率高于SVM[16]。最后选取分类效果最好的模型作为分类预测模型。
本研究选择10-折交叉验证(10-fold Cross-Validation)评价模型性能,可以确保进行小样本训练的实验结果无偏差估计,确保测试精确度。具体方法是随机将样本分为10 份,随机抽取9 份作为训练样本,剩余1 份为测试样本,每次试验L1-LR 模型后得到训练和测试正确率(或差错率),重复10次,将10次训练准确率和测试准确率的平均值作为L1-LR 模型最终的分类准确率的估计。
2 实验数据
数据由ANDⅠ数据库(Alzheimer's Disease Neuroimaging Ⅰnitiative)提供,受试者年龄选择55~90岁,能够提供独立的功能评估,排除特定的精神活性药物。数据包括543 例的sMRⅠ脑图像、MMSE 量表评分、年龄、性别、受教育程度这5 项资料。获得NC组共139 例(男65,女74);EMCⅠ组共220 例(男119,女101);LMCⅠ组共108 例(男58,女50);AD 组共76例(男44,女32)。
sMRⅠ数据统一选取场强3.0T飞利浦MRⅠ扫描仪的数据,BOLD序列:射频重复时间/回波时间(TR/TE)6.8 ms/3.1 ms,翻转角(FA)9°,视野大小(FOV)RL204 mm、AP 240 mm、FH 256 mm;分辨率(1.0×1.0×1.2)mm3,层厚1.2 mm,共170层。
3 实验结果
3.1 L1-LR特征选择结果
3.1.1 272项sMRⅠ特征组结果 首先对实验数据集预处理后,获得272 项sMRⅠ形态学指标,使用L1-LR 特征选择模型进行特征提取。在分类NC-EMCⅠ组中,272项sMRⅠ特征中有65个特征被挑选进入下一步骤的L1-LR 分类预测模型;同样的,在对NC-LMCⅠ、NC-AD、EMCⅠ-LMCⅠ、EMCⅠ-AD、LMCⅠ-AD 分类中,分别有37、22、52、38、41 个特征进入L1-LR 分类模型。特征选择结果按对分类的组别贡献由大到小依次给出,显示贡献最大的前10项特征,见表1。

表1 272项sMRI特征中最重要的前10项特征Tab.1 Top 10 important features of 272 sMRI features
3.1.2 276项特征结果 为进一步增强分类准确率,本研究在272项形态学指标的基础上,再引入不同模态的3项人口学指标和1项MMSE量表评分。在NC-EMCⅠ、NC-LMCⅠ、NC-AD、EMCⅠ-LMCⅠ、EMCⅠ-AD、LMCⅠ-AD分类中,分别有67、42、11、56、21、20个特征进入L1-LR分类模型。这里同样显示前10贡献率的指标,见表2。

表2 276项特征中最重要的前10项特征Tab.2 Top 10 important features of 276 features
3.1.3 特征选择结果分析 272项结果中,只测试形态学指标sMRⅠ时,在识别NC-EMCⅠ、NC-AD、EMCⅠ-AD、LMCⅠ-AD 分组时,TA-左颞横回对判断处于哪个病程阶段最为重要,颞横回为听觉皮质区,在AD 疾病进程中,听觉的不断弱化是判断病程的重要依据。NC-LMCⅠ组中,SA-左颞下回占分类决策的权重最大,颞下回负责学习和记忆,在进展为LMCⅠ的时候,病人的学习记忆表现出更多差异;在EMCⅠ-LMCⅠ病程很接近难以区分的组中,CV-左扣带回后部起最重要的作用,后扣带回参与情感和自我评价功能,说明在EMCⅠ进化为LMCⅠ的过程中,病人的情感和自我评价功能有较明显的差别。值得注意的是,除了EMCⅠ-LMCⅠ组,其余组HS-左右海马前下托都可作为一个很重要特征去识别分类,尤其是HS-右海马前下托贡献更大,而海马与近期记忆有关,海马体积变化发生在疾病进展全程,说明记忆障碍体现在从发病开始持续到AD阶段。
276项结果中,在引入MMSE量表评分、年龄、性别、受教育程度后,特征选择结果改变,特征贡献率也发生变化,其中MMSE 量表评分作为非常重要的特征用于识别各阶段的疾病,临床上可将MMSE 视为必不可少的依据,以提高诊断准确率。年龄和受教育程度是影响NC-EMCⅠ、NC-LMCⅠ、EMCⅠ-LMCⅠ、EMCⅠ-AD、LMCⅠ-AD 疾病进展的重要因素。在NCAD 识别中,性别因素占很大比重,但年龄因素被剔除,说明性别差异导致男女患AD 的可能性不同,在决定一个人患AD 可能性大小的时候,性别比年龄因素更重要。
3.2 不同机器学习分类结果
比较L1-LR、L1-SVM、GBDT的分类准确率,分别是(85.93±2.53)%、(80.73±4.89)%、(71.77±6.79)%。结果显示L1-LR 具有更好的分类效果。本研究选择L1-LR作为分类预测AD病程的模型。
为了进一步提高分类准确率,本研究在272 项sMRⅠ特征的基础上引入年龄、性别、受教育年限、MMSE 评分;经特征选择后,构建另一个L1-LR 分类预测模型。比较两种不同特征集合的分类效果,结果如表3、表4所示。

表3 基于两种特征数据集的分类准确率(%)Tab.3 Classification accuracy based on two different feature datasets(%)

表4 基于两种特征数据集的敏感度、特异性、AUC值Tab.4 Sensitivity,specificity and AUC values based on two different feature datasets
相比272 项特征组模型,276 项特征组L1-LR 分类模型在识别NC-EMCⅠ、NC-LMCⅠ、NC-AD、EMCⅠ-LMCⅠ、EMCⅠ-AD、LMCⅠ-AD 组分类准确率依次提高2.92%、3.14%、11.42%、0.89%、6.07%、4.91%。尤其在早期识别EMCⅠ、LMCⅠ和AD 时,准确率高达94.28%、91.24%,同时在区分难以鉴别的EMCⅠ和LMCⅠ时也可以达到82.93%的准确率。结合引入的4 项特征后,特征选择中年龄、性别、受教育年限、MMSE 量表评分占很大贡献率,分类预测准确率的提高,说明在实际临床诊断时这几项指标可以看作很重要的辅助诊断病程阶段因素,尤其是MMSE 量表评分的评价。
用受试者工作特征(Receiver Operating Characteristic,ROC)曲线下面积(AUC)评估两种特征集的分类性能,AUC值越大,分类性能越好。图1为两种特征集的ROC曲线图(0、1、2、3分别代表NC组、EMCⅠ组、LMCⅠ组、AD组)。图1a为基于L1-LR的272项特征集的ROC曲线下面积,为0.925 9±0.386 2;图1b为基于L1-LR的276项特征集的ROC曲线下面积,为0.953 2±0.475 4,从图中看出后者有更好的分类性能。
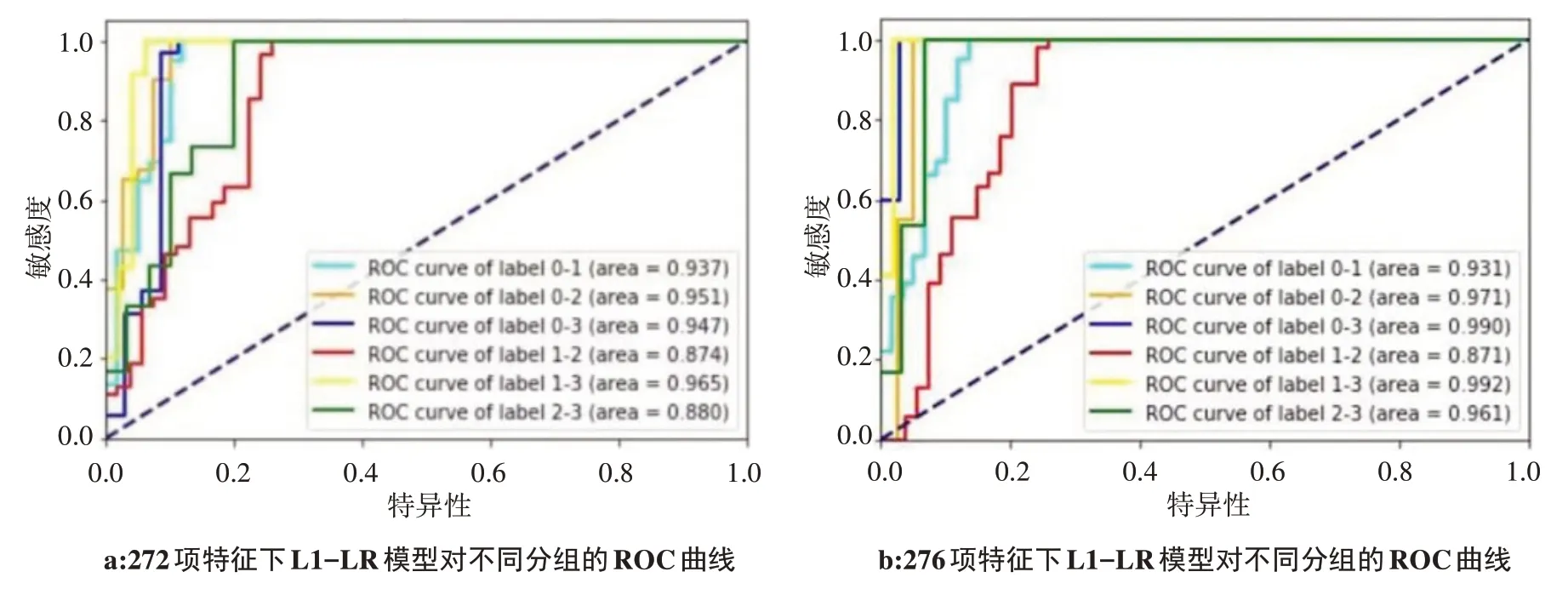
图1 两种特征数据集的ROC曲线Fig.1 Receiver operating characteristic curves of two different feature datasets
4 结论
以往AD分类研究一般只指出大脑哪些区域发生病变,本研究不仅发现识别分组时的关键特征,还发现关键病变部位是体积或面积的变化,更有助于预测病程进展方向。本研究发现识别各组的特征集中在海马体、海马旁回、扣带回、大部分颞叶、岛叶、梭状回。其中NC-MCⅠ变化集中发生在海马下托、海马旁回、海马前下托、上中下颞回、杏仁核、扣带回、梭状回、岛叶;MCⅠ-AD变化主要集中在海马体、海马旁回、前扣带回,其中左右海马体积变化和海马亚区体积变化更为明显。已有研究发现在NC发展为MCⅠ的过程,主要是负责认知功能的海马体和颞叶的萎缩,MCⅠ发展为AD的过程,认知进一步下降,同时负责行为障碍和生活能力的前扣带回萎缩更严重[17-18]。本研究的研究重点是对NC-EMCⅠ、EMCⅠ-LMCⅠ和LMCⅠ-AD组的识别,除了与已有研究一致的脑部形态学变化之外,本研究还发现仅在某个分组中的特征变化有助于预测病程判断,在临床判断该组分类时评价这些指标更有识别度和价值。SA-左岛叶、SA-左额上回、TA-右额中回下部、TA-左中央后回、TA-右扣带回后部、CV-右眶回、TA-右眶回、SA-右额眶回外侧、SA-左额中回后部、CV-左海马旁回、CV-左岛叶、SV-右脉络丛、SA-右额上回、CV-右枕叶外侧部、CV-左眶回、TA-左扣带回峡部、SA-左海马旁回部位的变化仅在判断NC-EMCⅠ分类时占有较大贡献率;而CV-左扣带回后部、CV-左额上回、SV-左侧小脑白质、SA-左中央旁小叶、CV-右中央后回、SV-幕上、TA-左额中回后部、CV-右扣带回后部、CV-右三角部、SA-右颞上回、TA-左额上回、CV-右额中回下部、CV-左额中回后部、TA-右楔前叶的变化只发生在EMCⅠ与LMCⅠ的分类中。CV-颞极、CV-右岛盖、TA-左右中央前回、CV-右楔前叶、SV-右丘脑、SA-右中央前回、TA-左额眶回外侧的变化在EMCⅠ到AD的过程中发生得更明显。MMSE量表评分是很重要的影响诊断的因素,临床工作务必认真准确测评量表;另外,年龄和受教育年限、性别也作为重要影响因素影响疾病进展。
本研究比较了3种常用机器学习方法,提出了一种基于sMRⅠ图像的AD及前驱阶段的自动识别分类模式,结果证明L1-LR分类器可以作为临床辅助诊断AD病程的有效工具。实验采用sMRⅠ数据+年龄+性别+受教育年限+MMSE量表评分特征集实现最优分类精度,能实现早期识别,起到阻碍病程进展的作用,提高辅助诊断系统的准确率。本研究在NC-AD组中达到97.66%的准确率,明显高于Bi 等[14]利用支持向量机得到的94.44%的准确率和杨晨晖[19]应用随机森林得到的93%的准确率。在MCⅠ-AD的识别中平均准确率为92.76%,高于Ardekani等[20]基于多模态随机森林获得的82.3%的准确率,Bi等[14]的研究也仅达88.73%。NC-MCⅠ组中,本实验达到89.38%的平均准确率,Bi等[14]的研究仅有81.45%。在与本文数据类型相似的研究中,齐雪丹[21]比较了支持向量机、随机森林、决策树、K近邻对AD做分类预测,NC-EMCⅠ、NC-LMCⅠ、NC-AD、EMCⅠ-LMCⅠ、EMCⅠ-AD、LMCⅠ-AD 组识别最高准确率为77.78%、88.00%、96.45%、81.82%、90.00%、84.21%,本研究中使用的L1-LR模型准确率在各分组分别提高9.16%、3.87%、1.21%、1.11%、4.28%、7.06%,且与之不同的是,本研究还将人口学指标和MMSE量表评分引入模型。并且本研究提出的L1-LR分类器仅需检测sMRⅠ,获取人口统计学指标和测评MMSE量表即可,具有经济实惠的社会效益。
sMRⅠ是AD进行分类研究的基础,本研究的后续将通过增加认知评价、人口统计学资料、正电子发射型计算机断层显像、功能性磁共振成像、脑脊液检查等数据类型形成多模态数据,同时加大实验数据量,以获得更高精度、更稳定的分类器用于预测AD病程分类,以期达到延缓疾病进展、提高生活质量、减轻国家和个人负担的目标。