基于朴素贝叶斯和word2vec的中医电子病历文本信息抽取*
2020-04-06刘一斌
刘一斌,叶 辉,易 珺,曹 东**
(1. 广州中医药大学医学信息工程学院 广州 510006;2. 广东药科大学医药信息工程学院 广州 510006)
电子病历是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录[1]。中医电子病历则是特指中医师在为患者治疗疾病时,记录诊疗过程的一种方式,主要包含了中医“望闻问切”的具体内容、治法和处方等信息。中医电子病历可供医护人员进行诊疗经验的分享,有利于中医的传承和创新,对临床决策支持、循证医学实践和个性化医疗服务等具有重要意义。在现今大数据时代背景下,中医电子病历对中医药信息的数据挖掘也起到十分重要的作用,因为它们往往是最直接的数据来源。一个完整的中医门诊电子病历通常记录了较多信息,如症状、处方、治法等,这些信息以纯文本、非结构化的形式记录在电子病历中,不利于进行专门的数据挖掘与分析。以往的医学科研人员往往是人工抽取自己需要的病历文本信息进行研究,在有效数据的抽取上耗费了大量的人力和时间,增加了科研成本。因此,研究如何通过计算机算法,把一个完整的中医电子门诊病历文本的有价值信息自动分类输出,对中医诊疗经验的传承与中医电子病历的数据挖掘,以及更有效率地进行相关领域科研工作有着十分重要的作用。
如何有效地抽取中医电子病历中的特定内容,必须先对电子病历文本中的各种医学命名实体进行有效识别。目前,医学命名实体识别的方法主要有基于字典、基于规则和基于机器学习的方法,随着人工智能时代的逐渐到来,基于机器学习甚至是深度学习的方法体现出了较大的优势,并成为当前研究方法的主流[2]。
朴素贝叶斯算法与词向量(word2vec)都是比较成熟的文本分类机器学习算法。如詹鹏伟等[3]使用朴素贝叶斯算法过滤垃圾邮件,罗杰等[4]使用朴素贝叶斯对QQ 群信息进行文本分类。朴素贝叶斯基于古典数学贝叶斯理论,假设样本各属性间相互条件独立。判断文本属于哪个类别,根据文本属于哪个类别的条件概率越大就判定为哪类,其中属于某类别的条件概率是依据贝叶斯公式计算样本的关键词属于各类别的条件概率乘积。从其原理可以看出,朴素贝叶斯算法忽视了词条间的相互依赖关系,不注重文本的上下文联系,且忽略了同义词的影响,适用于提取文本中内容较短、同义词少的字段[5],如‘舌’‘脉’信息。与之不同的是,word2vec 算法是把每个分词转化为向量[6],从而可以刻画每个分词及其上下文的分词集合。利用其上下文联系强的特点,词向量(word2vec)适合于语段较长、有强上下文关联的中文语句分类。如张谦等[7]使用word2vec 进行微博文本内容分类,陈杰等[8]利用word2vec对不同类型的文档进行分类。
在医学文本信息处理方面,杨锦峰等[9-10]基于UMLS 语义类型进行了中文电子病历命名实体和实体关系语料库的构建,并且在电子病历命名实体识别和实体关系抽取方面做了研究[11];栗伟等[12]采用CRF 与规则相结合的方法识别电子病历命名实体。但是,前人主要是在西医中文电子病历中进行探索,而在中医电子病历信息抽取领域的相关研究并不充分,有大量的中医电子病历文本数据亟待挖掘。中医电子病历与西医电子病历有着很大的不同,西医电子病历中的医学命名实体涉及很多病理生理词汇、解剖位置词汇等各种西医专有名词,中医电子病历也会包含这些信息,但是除此以外,更多的是描述中医“望闻问切”四诊相关的内容信息,而这些信息需要采取特定的算法进行识别。如中医的各种描绘脉象、舌象、苔象的词汇,以及说明中医治疗手段(疏肝健脾、疏风解表等)的词汇,这些中医的专有词汇在以往的研究中还是难以识别。本文在此方面做了初步研究,完成了一个中医电子门诊病历命名实体识别信息分类抽取过程。利用本研究所掌握的数据,识别并抽取中医电子病历文本中的10个不同类别的内容,很好地抽取了中医领域特定命名实体。对数据集进行训练集和测试集的划分,根据不同算法的特异性,运用算法进行训练形成模型。其中,朴素贝叶斯算法提取舌象、脉象、治法、诊断等信息,word2vec 算法提取处方、症状等长文本信息。经过测试集的测试,模型较好地完成了中医电子病历文本内容分类抽取任务。
1 相关理论
1.1 朴素贝叶斯分类算法
设训练样本集分为k类,记为C={C1,C2,…,Ck},则每个类的先验概率为P(Ci),i=1,2,…,k,其值为Ci类的样本数除以训练集总样本数。对于新样本d,其属于Ci类的条件概率是P(Ci|d),根据贝叶斯定理,有:

其中,P(d)对于所有类均为一个常数,可以忽略。对于待分类文本字段d,本文采用向量空间模型,其基本思想是将每一个文本字段表示为一个向量d=(w1,w2,…,wm),m是d的分词个数(去除停用词之后),wm代表分词。有:
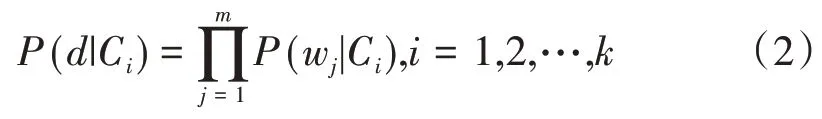
朴素贝叶斯分类器将待分类的文本样本d归于哪类,则是根据以下公式:

朴素贝叶斯算法比较成熟,是文本信息分类的一种常见算法。训练完成形成各个类别的词袋后,进行测试时该模型就会特异性地识别相关类别信息并进行分类结果输出。
1.2 词向量(word2vec)算法
word2vec 是一种浅层的神经网络算法,主要包括2 个模型,分别是连续词袋模型模型(continuous bag of words,CBOW)和连续跳跃元语法模型(continuous Skip-gram model,Skip-gram),CBOW 模型通过词的上下文对当前词预测学习词向量,而Skip-gram 是根据当前词对其上下文进行预测来学习的[12-13]。本次研究采用了CBOW模型。
word2vec 算法用来训练词向量,它将词映射到多维的向量空间中,将词表征为一组低维实数向量,被称为分布式表征(distributed representation)[6],它可以充分考虑上下文字段之间的关系,同时词义相近或者相关性大的词向量在距离上也更为接近。CBOW 模型是一个三层的网络结构,输入层(input layer)即目标词w(t)的前后各c个分词对应的词向量,这些词向量经过投射矩阵(projection matrix)映射到投影层(projection layer),输出层则是以词语在语料库中的词频作为权值构造的一棵二叉树,叶子节点对应词汇表中的所有词语。叶子节点和非叶子节点均对应一个向量,其中叶子节点对应的向量即为词向量,而非叶子节点对应的向量是一个辅助向量,两种向量都是需要通过训练学习的参数。经过一定次数的迭代训练以后,训练的词向量和辅助向量会逐渐趋于稳定,模型训练完成后,这些向量均会被保存在模型中,当进行测试时,模型就会通过这些存储的向量值对文本内容进行分类并输出分类结果。
2 基于机器学习算法的中医电子病历文本信息抽取步骤
2.1 数据准备与分词
在原始数据的基础上,进行数据预处理与清洗,得到初步加工的数据,本研究一共获得了266 个中医电子门诊病历,病历中包含了患者姓名、性别、年龄、症状、检查、处方等详细信息,这些内容均以纯文本形式存在。中医电子病历文本中有必要的换行符以进行分割。图1 为一个中医电子病历,可以看出其结构化程度很低,包含多种信息,如患者姓名、性别、年龄等,还有中医“望闻问切”的相关记录和医生所开处方的记录。值得注意的是该文本中“患者病史”下所描述的内容,其实是患者的临床表现,真正的患者病史应该是“既往史”字段下面的“胆囊炎”。最终训练得到的模型需要准确分析判断并且识别这些内容,输出真正正确的结果。
为使研究更具科学性,本研究按照测试集与训练集约为1/4 的比例,随机从所有中医电子病历中抽取50个电子病历作为测试集,其余作为训练集。
分词[15]是中文文本预处理最基础也是最重要的步骤,分词的好坏对接下来的任务处理有着直接影响。结巴分词对中文文本分词有良好的效果,利用结巴分词对训练集电子病历文本进行中文分词,并且删除可能对后续实验造成干扰的停用词,如‘,。:().’等,只选取有价值的文字信息。分词后的文本文件被保存下来,用于后续进行标签标注。
2.2 标签标注
对于有监督的机器学习来讲,标签是十分重要。将中医电子门诊病历的所有有用信息全部进行分类抽取,标签代号与其实际代表意义的对照见表1。
分词之后,对分词分属类别进行标注。当某个类别结束时,用N 标注。如分词之后的“理气健脾疏肝通络”,标注为“理气ZF 健脾ZF 疏肝ZF 通络N”。在进行标签标注时,全程由相关医学专业人员进行审核与校对,以确保其标注内容的准确性。当所有训练数据的标签标注完成后,则开始进行模型训练。
2.3 模型训练
2.3.1 朴素贝叶斯模型

图1 该门诊中医电子病历文本

表1 标签代号与所属类别的对照
如上所述,朴素贝叶斯算法适用于提取中医电子病历中字段较短、上下文联系较少的信息,主要包括了舌象、脉象、苔象、病史、中医治法、西医检查、中医诊断、西医诊断共8 个方面的内容。当训练朴素贝叶斯分类器模型时,利用已有标签的数据,进行下列流程操作,见图2。
每个类别词袋里面的分词即为该类别所含有的独立特征,有了每个类别词袋中各个独立特征的条件概率(即公式(1)中的P(d|Ci)),通过朴素贝叶斯公式(1)计算出后验概率,再通过公式(3)取概率最大值,从而给某个中医电子病历文本字段进行类别判断。
2.3.2 word2vec模型
如上所述,word2vec 算法适用于提取中医电子病历中字段较长、且上下文关联较强的文本信息,包括患者的临床症状和中医处方两方面内容。

图2 朴素贝叶斯模型训练

图3 CBOW模型网络结构
在训练word2vec 模型时,使用CBOW 模型(通过上下文预测中心词)。比如当以“柴胡CF 黄芩”为语料训练时,根据word2vec 的CBOW 模型,经过多次迭代训练,即可从上下文语境“柴胡”“黄芩”预测出中间的标签词“CF”(实际代表含义为“处方”)。图3 为CBOW 模型具体的网络结构,模型中一共有n个分词,输出层V(叶子节点)为词向量,P(非叶子节点)为辅助向量。通过训练这两种向量,使模型可以通过输入的“柴胡”、“黄芩”最终得到并且输出一个正确的标签词“CF”。在模型训练的过程中,设置了一个较小的学习率,alpha = 0.001。此外,由于数据较少,设置参数最小词频min_count = 0,使模型不丢掉任何一个分词。最终生成的模型文件以.bin二进制文件存储。在接下来的模型调用和分类结果测试工作中,则可在python程序中直接利用该模型,输入需要进行分类的中文电子病历文本语句,分析该模型的输出结果,从而进行该输入文本类别的判断。
3 测试集测试与结果分析
3.1 分类过程
训练好模型并保存以后,则需要进行测试集的测试。在进行测试时,首先读入一个完整的中医电子病历文本文档,然后依次读入文本中的每一行内容,进入模型进行判断。分别计算属于每个类别的权重,选择最大的作为类别输出,并且写入至Excel 文件中相的应位置。其中朴素贝叶斯算法会特异性地识别舌象、脉象、治法等八个方面信息,word2vec 算法会针对性地识别处方和临床症状两个方面内容。
测试集进行测试的具体流程见图4。这里需要指出的是,中医电子病历文本中有包含病人的相关个人数据,如姓名、性别、年龄等信息,这些信息也需要提取,因为这些数据也是医学科研中不容忽视的信息,尤其是性别和年龄信息。对此,本研究采用了正则表达式进行抽取。
3.2 模型测试
对图1所示中医电子病历利用模型分类提取部分信息的结果见表2。
由表2 可知,模型将图1 所示的病历内容进行了较好地相关医学命名实体识别及分类抽取,但仍存在一定的误差。用正则表达式抽取的患者姓名、性别、年龄等信息均正确,既往史中的“1 型糖尿病”属于模型误判内容。舌象、脉象、苔象信息抽取良好,症状中的“初步诊断(或诊断)”属于误判内容。西医检查、中医治法与中医处方内容识别良好。
3.3 结果与分析
一般的文本内容信息抽取常见的评价标准有查准率(Precision)、召回率(Recall)以及F1测量值。查准率是模型实际抽取到的文本信息中的真正抽取正确的比例;召回率是模型应当抽取到的文本信息中的真正抽取正确的比例。考虑到查准率P与召回率R是相互影响的关系,F1测量值可以通过公式(4)求得。

经过统计分析,最终测试生成的结果见表3。
经测得精度P= 501/601 = 83.36%,召回率R=501/640 = 78.28%,并由公式(4)得到F1测量值为80.74%。经过相关医学专业人员的分析与验证,模型较好地完成了信息提取分类的任务,但是准确率和F1测量值与其他相关西医医学命名实体信息抽取[16]的准确率和F1测量值相比偏低,因此仍需要在跟进学术前沿的同时,探索出适合中医电子病历文本信息抽取的有效方法。在本研究中,可利用数据量偏少是其中的一个缺陷,除此以外,中医有大量术语缺少统一的语义类型界定,如“咳嗽”一词,既可以是临床表现的某个症状,也可是一种中医病名,这一问题也导致了中医电子病历信息分类提取的不准确性。这些都是今后亟需解决的问题。

图4 测试集测试流程图

表2 中医电子病历模型分类抽取结果

表3 模型测试结果
4 总结
本文为了实现对中医电子病历相关命名实体与信息的分类提取,利用了朴素贝叶斯和word2vec 两种机器学习算法。先是通过对训练集的数据进行训练,得到最终的模型,然后通过测试集进行生成模型的测试。经过对测试结果的分析,得到了一个较好的中医电子门诊病历命名实体与信息抽取结果。不足之处在于总体数据有限,且可供训练的中医电子病历文本格式相对单一,造成了最终训练得到的模型对该种中医电子病历文本格式产生了一定的特异性。希望今后可用更为广泛和多样的数据来不断完善模型,取得业内更为广泛和深层次的认可。本研究为提取中医电子病历文本信息,从而进行更深一步的数据挖掘和科研任务做了基础性工作,提出了一种值得推广的方法。
