企业名字与企业效益关系研究
——基于信号博弈的视角
2020-04-02傅彤
傅 彤
(中国社会科学院研究生院,北京102488)
一、引言
在企业创立之初,每个企业家都要为自己的企业命名,此后企业的经营状况、名声好坏等都伴随着该名字表达出来。企业名字作为概括企业信息和甄别不同企业的标签,自然地被视为企业名誉的载体(Wu,2010)。大量的文献从无形资产的角度研究企业名字(Cabral,2000;Mcdevitt,2011),然而一个同样重要却很少讨论的问题是,企业命名方式也会对企业效益产生影响。本文的研究聚焦于企业家将自己的姓名冠予企业的命名方式。此类名字比较特殊,但并不少见,比如李宁体育用品有限公司和羽西化妆品有限公司(下文将这类企业简称为同名企业)等。中国商务部公布的中华老字号名录中,仅以北京为例,成立于1900年以前的38家百年老店中,有11家以创始人的名字命名,所占比例接近30%。
研究同名企业问题具有现实意义。对中国企业家同名企业进行简单地观察不难发现,无论是李宁、羽西这类新兴品牌企业,还是张小泉、王致和等老牌企业,同名企业的绩效表现一般较为良好。已有的文献表明新企业或新产品进入市场时,在吸引投资和顾客方面存在困难(Shane&Cable,2002;吴小康和于津平,2018),为了能将产品质量信息传达给市场,企业可以采取广告营销、品牌战略等举措,但是往往要承担较低的利润率(Rogerson,1987;Bagwell&Riordan,1991)。如果采取同名策略可以给企业带来效益上的提升,那么弄清其作用机制可以为企业摆脱成立初期的劣势,为尽早占有市场提供借鉴。然而遗憾的是,目前为止鲜有文献对同名企业的效益问题进行理论和实证研究。
企业家将自己的名字冠予企业如何提高企业效益?部分文献肯定了企业经营状况与企业名字的联系,从而使企业名字受到推崇(Tadelis,1999,2002;谢红军等,2017)。但是这类文献仅仅将名字看作反映企业历史信息的符号,并没有涉及企业命名决策。命名行为发生在企业生命周期的起点,而刚成立的企业容易面临信息不对称的问题。有研究表明企业在成立子公司或推广新产品时,沿用原有的名称可以释放产品质量信号(Choi,1998)、提高组织认同(Glynn&Abzug,2002)和缓解可置信承诺问题(Ingram,2010)。这类研究遵循的是“子承父名”的逻辑思路,父辈公司或产品在市场上享有不错的声誉,子公司或新产品通过命名与之建立联系,以彰显自身的价值。然而该逻辑并不适用于本文的议题,因为在创办企业之前,企业家往往并不具有知名度,只有通过良好的经营,生产高质量的产品才能得到市场的认同,从中获得良好的声誉。
基于信号博弈的视角,本文认为企业家将自己的名字冠予企业,一方面相当于向外界释放信号,消费者接受该信号后形成对产品质量的预期,并根据预期购买产品,然后再参照购买产品的实际情况更新预期;另一方面,相当于建立了企业效益和企业家个人荣誉之间的纽带。当企业经营状况良好时,这种纽带关系能够增加企业家从中获得的名誉收益,反之企业经营不善时,增强企业家的失败感和名誉损失。尽管非同名企业的企业家也可能会从企业经营活动中获得名誉收益或损失,但是远没有同名企业的企业家获得的损益强烈。因此,在消费者预期和企业家与企业之间纽带的双重作用下,能力强的企业家更倾向于将自己的名字命名企业,以获得更高的名誉收益。企业名字也就成为显示企业家能力的信号。
McDevitt(2014)研究了企业家能力、企业名字和企业绩效之间的关系。客户通过一本按照名字字母顺序排列,记载本地企业名录的手册寻找合适的服务。能力低的企业家采用首字母排列靠前的字符命名企业,吸引那些为了节省搜寻成本而只翻看手册前几页的客户。McDevitt 的案例中,名字首字母成为反映企业好坏的信号,但是这种信号作用的机制与本文不同。本文中企业名字的作用是连接企业与企业家的纽带,而McDevitt研究中企业名字的排序可以节省顾客的搜寻成本。宋丽红等(2017)探讨了上市家族企业命名与企业绩效的关系,以家族命名企业有助于提高消费者对家族企业长期承诺、顾客聚焦等形象的感知,使企业家有更强的责任感保证企业行为不会损害家族声誉。然而该研究局限于上市家族企业,并不具有普遍性,同时作者也没有提出严谨的理论模型分析企业命名与企业绩效的关系。Belenzon 等(2017)分析了欧洲180 万家企业的命名策略后,发现企业家同名企业拥有更高的资本回报率,而且企业家名字越是生僻,同名企业的资本回报率越高。其研究对象是欧洲企业,并没有考察中国企业问题。由于东西方文字和语言习惯的不同,企业命名的规则也会不同,这点在相关文献中早有论及(殷志平,2009)。再者,中国产品市场的发育不如欧洲成熟,信息不对称问题在中国更为严重,企业命名作为企业减轻信息劣势的手段,其效果如何有待检验。
与已有的研究相比,本文的贡献在于以下三个方面。第一,首次从理论上和实证上,对中国企业家以自己的姓名冠予企业的命名方式作了较为严谨的考察,不仅为企业运营之初的信息不对称研究做出了边际贡献,也有助于从中国特殊的经济、文化背景理解企业的创立和成长。第二,以新颖的角度研究企业家特质与企业效益关系。一方面,同名企业将企业效益和企业家名誉绑定在一起,体现企业家同企业“荣辱与共”的责任感与上进心;另一方面,企业命名是每个企业家都要做出的选择,这种选择与今后企业的经营状况无关,而且相比于企业家的特质,名字可以直接观察到这些特点给实证研究带来便利。第三,本文的研究具有现实性。假如同名企业具有更高的效益,那么相比于广告营销、品牌战略等,同名策略是企业走出早期信息不对称困境时可以考虑的一种“廉价”手段。
二、理论分析与假设提出
本文将构建信号博弈模型以解释企业命名与企业效益之间的关系。企业家将自己的名字冠予企业,建立企业家与企业之间的纽带,消费者根据企业名和购买到实际产品的质量形成对产品的评价。在消费者和企业家的动态博弈中,同名策略可以增强经营收益,比如企业家从中获得荣誉感,企业的名誉收益得到提升;或者相反,增强经营损失,如企业家获得失败感,企业的名誉下降,因此,能力强的企业家更倾向于采用同名策略。模型参照Tadelis(1999)和Belenzon(2017)的方法,将企业的经营活动划分为两个时期:在第一时期,企业释放同名或者不同名的信号,消费者接收该信号形成信念(belief),按照产品的预期价值支付给企业;在第二时期,消费者根据第一时期产品的实现情况更新信念,并依据新的信念再次购买企业产品。具体建模过程如下:
市场中存在两种类型θ的企业,θ∈{H,L} 。其中,H代表能力高的企业家拥有的企业,或者经营状况好的企业,相反,L指代差企业。只有企业家自己知道θ的取值,而消费者仅仅知道θ的分布企业生产产品g,g∈{h,l},由于不同类型的企业生产能力不同,H企业更容易生产出质量高的产品h。为了简化分析,参照Tadelis(1999)的做法,假设Pr(g=h│θ=H)=Pr(g=l│θ=L)=p∈(1/2,1),并且高质量产品价值为h=1,低质量产品价值为l=0。概率p的存在是信号博弈的前提条件,正因为能力强的企业家不能保证每件产品是高质量的,而能力弱的企业家也有可能生产出高质量的产品,因而消费者需要根据信念购买产品。
在第一时期,企业释放信号s∈[ -s,-s],s可以是企业的广告宣传、品牌战略等宣传手段,在本文中专门指代企业命名方式。消费者观察到该信号后,将信念从μ0变更为μ1,并根据μ1形成产品预期价值支付企业。当然消费者在这一时期也可以保持信念不变,因为消费者此时可能从企业名中得不到额外的信息,这并不会影响模型后面的分析。在第一时期该企业获得的收益为V1=μ1p+(1-μ1)(1-p)。在第二时期,消费者根据第一时期产品g的实现情况,将信念从μ1更新为μ2。此时企业获得的收益为V2=s(μ2γ-(1-μ2)),其中γ>0。明显,μ2越大收益则越高。s以相乘的形式进入收益方程,表示当信号s增强时,企业家和企业之间的纽带更加紧密,从而放大企业家的名誉收益或者失败损失。而γ的设定表明企业从经营活动中获得的名誉收益和损失可以是不对称的。
根据贝叶斯法则,容易得出μ1和μ2之间的关系:忽略贴现问题,那么H企业最终获得的收益为:uH(s,μ1) =企 业 最 终收益则是该式的对称形式。uθ是μ1的严格增函数,且对任意(s,μ1)组合,均有H 企业的收益总会比L企业高。
模型的关键在于寻找完美贝叶斯均衡。由于企业命名的特殊性,不存在分离均衡(separating equilibrium)。因为假如分离均衡存在,那么消费者认为释放强信号的企业一定为H 企业,此时L企业可以不花费任何成本来模仿H企业的信号策略,以获取消费者的信任,达到“鱼目混珠”的效果,这与分离均衡矛盾。当然,也存在着许多其他类型的均衡,需要施加精炼准则(refinements)筛选出合理均衡。本模型选取D1 准则(Cho和Kreps,1987):假设均衡时企业收益为和对于偏离均衡路径的信号策略s,令当时时,μ1( )s=0。直观上讲,采取偏离均衡路径的信号策略s时,为了获得更高收益,哪类企业需求的消费者信念μ1取值范围更大,消费者就认为发送s信号的企业为该类企业。
企业选择信号-s且消费者认为是L 企业时,有μ1=μ2=0 和现在令表明在时,是否选择同名策略对L类型的企业没有区别。成为判断均衡类型的临界条件,从而提出下述命题:
命题1:对于任意μ0,在D1准则下,企业命名的信号博弈存在唯一的稳定均衡解。其中,H 企业始终选择信号。当μ0≥μ*时,L企业同样选择,与H企业的命名策略一起构成混同 均 衡(pooling equilibrium);当μ0<μ*时,L 企 业 以p*=的概率选择以1-p*的概率选择此时的均衡是半分离均衡(semi-separating equilibrium)。此外,关于消费者第一时期的信念为时
由于不存在分离均衡,至少部分L 企业会和H 企业混同,选择信号对于任意都有消费者认为这类企业是L 企业,此时L 企业的最优选择是释放信号-s,获得收益可见,L 企业面临的选择实际上只有和当μ0≥μ*时,L 企业选择此时且是混同情形。而当时且L企业不能完全选择而是以p*的概率选择可见,市场中H企业比例很高时,有利于L企业“鱼目混珠”采取和H 企业一样的同名策略;而市场中H 企业比例很低时,L 企业需要谨慎行事。
虽然以上分析中信号s的取值是区间但是当时,命题1依旧成立。在本文的背景下,指代企业家将自己的名字冠以企业,而-s则表示常规命名,企业家选择或者由于现实中同名企业的比例很低(见表1),因此μ0<μ*的情形更符合实际。μ*∈(0,1)时,H企业都会选择同名策略,同名企业的效益也更高,从而可以提出如下假设:
假设1:企业家同名企业的效益更好。
企业家将自己的名字冠以企业,建立起企业和企业家之间的纽带,企业经营状况的好坏与企业家个人的荣辱紧密相连,增强企业的名誉收入或者损失。当该命名更容易识别时,这种增强作用更加显著,直接表现为保持消费者第二期信念不变,增加的取值,第二期收益则更大(或更小)。容易证明,当0<μ0<μ*时越大,信念μ*也越大,p*则越小,L企业更不愿意采取同名信号结果为,H企业的效益更高,L企业的效益保持不变,两类企业间的差距扩大。因此可以提出:
假设2:企业家人名越罕见,以自己名字冠以企业的可能性越低,而对应同名企业的效益则越好;非同名企业的效益与企业家名字的罕见度无关。
三、数据描述和回归设定
本文使用1998-2007年中国规模以上工业企业数据,参照Brandt等(2012)的序贯识别法,整理出包括52万家企业的非平衡面板数据。在数据处理过程中,对四位数国民经济行业分类进行了统一。同时,考虑到数据错报等问题,参考以往文献做法去除异常样本:剔除缺乏重要财务指标的样本,例如企业总资产、工业总产值、雇佣劳动力、固定资产净值等;剔除与一般公认会计准则(GAAP)不一致的样本,例如,资产总计小于流动资产,利润率大于1 的样本;剔除就业人数少于10 人的企业。
企业全称的基本格式是“企业所在地行政区划+企业字号+行业经营特点+组织形式”,其中企业字号是本文所关心的,即通常所指的企业名字。根据企业全称和法人代表两项指标,构建出企业是否同名的虚拟变量nameit,只要法人代表名中有一个字出现在企业名中,取值就为1,否则0。为了在实证中能够区分信号的强弱,进一步构造强命名变量nameQit,假如出现以下三类情况,那么取值为1,否则0:法人代表名完整出现在企业名中;法人代表人的姓出现在企业名中,且姓后面跟随“记”、“氏”两字,比如“李氏”、“李记”;名字有三个以上字符的,两个字符的名完整出现在企业名中,如“李小明”的“小明”出现在企业名中。本文最终匹配出18 万家同名企业样本,占全样本的9%,去除国有、集体和外资企业,剩余的样本中同名企业有15.4万,占比为11.1%,其中强命名企业有24458家(见表1)。Belenzon等(2017)按照欧洲企业主的姓氏(last name)是否出现在企业名中作为判断同名企业的标准,得出同名企业的比例为19%,与本文相差8个百分点。根据理论分析,造成这种差距的可能原因除了东西方语言、文化不同之外,也包括企业家能力分布的差异,欧洲能力强的企业家比例可能更高。
回归模型使用企业的利润率profitit作为衡量企业效益的被解释变量。企业利润率应该为产品销售利润与产品销售收入之比。然而,中国工业企业数据库中企业的产品销售利润数据只提供到2002 年。本文参照余淼杰和智琨(2016)的做法,将企业利润率定义为营业利润与产品销售收入之比。由于产品销售利润是企业营业利润的最重要的组成部分,这种替代不会对文章结论造成明显的影响。考虑到异常值问题,对profitit做0.5%缩尾处理。表1的统计结果表明,同名企业的平均利润率远远超出全样本,而且标准差也更小。其中强命名企业的平均利润最高(4.55%),数值上超过全样本平均利润率的两倍有余。
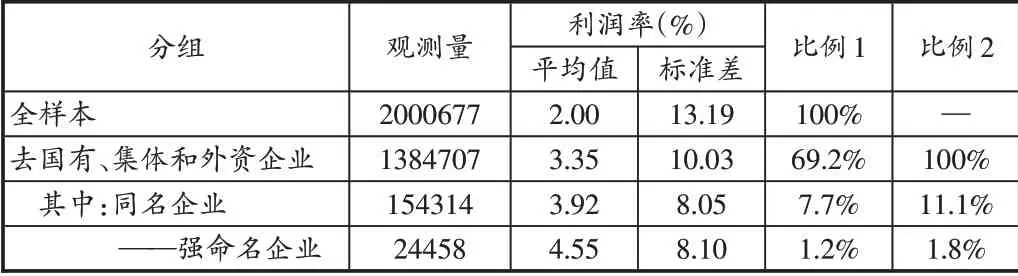
表1 强命名和弱命名样本的统计结果
实证部分的回归方程为:
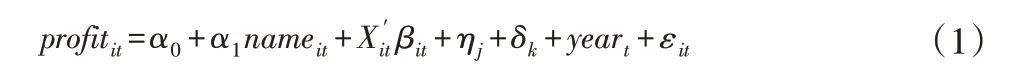
其中,Xit表示一系列控制变量,ηj是企业i所在行业j的固定效应,δk是企业i所在地区k的固定效应,yeart是年份变量,εit是随机误差项。
企业命名发生在企业创立之前,因此,企业是否同名与企业成立之后的经营状况无关,实证中不会出现严重的逆向因果问题。选择同名策略与否是每个企业家都要面临的抉择,因此也不会出现严重的样本选择偏差。当然本文不可避免地存在遗漏变量问题,比如命名策略可能受到当地宏观环境的影响,而宏观环境会影响之后企业的运营。辛宇等(2016)的研究表明,地区宗教传统可以影响民营企业的创立资金来源。企业的创立资金影响企业初期的经营绩效,而受到宗教传统洗礼的企业主可能会对企业命名有某种倾向,因此,地区宗教和文化的差异也是造成内生性的原因之一。鉴于此,本文控制了行业、地区固定效应,同时也控制了产品销售收入saleit、固定资产合计assetit、企业年龄ageit、全部就业人员workerit和企业所有制类型。这些控制变量既包含投入变量,也包括产出变量,总体上可以概括一家企业运营的基本面。在稳健性检验部分,本文特别对遗漏变量问题进行了考察。
四、回归结果分析
对全样本进行混合OLS(pooled OLS)回归,结果如表2的回归1 所示。变量nameit的系数显著为正,平均而言,同名企业的利润率比普通企业高出0.43个百分点,数值上相当于全样本平均利润率(2%)的21.5%。显然,由同名效应带来的利润增幅十分可观,从而验证了假设1,同名企业的效益更好。考虑到样本包括国有、集体和外资企业,这三类企业的命名方式比较特殊,国有企业和集体企业分别为国家和集体所有,即使法人代表名字出现在企业名内,也仅是巧合,而外资企业命名规则涉及中外语言文化的差异(殷志平,2009)。因此,回归2 中去掉国有、集体和外资企业样本,得到的结果与回归1 基本一致,nameit的系数估计值略微下降。在下文的实证检验中,如未作特别说明,均不考虑国有、集体和外资企业。
为了进一步检验企业同名的作用机制,本文尝试构造企业家人名的常见度指标。将企业家人名拆成单个字,并按企业家所在城市归类,计算出这几个字在城市中出现的比例,然后取平均值得到该名字常见度指标freq1it。考虑到人们的思维容易被特殊的事物左右,例如给定一个人名,人们往往容易记住其中特殊的那个字,因此,再根据企业家名字中最不常见的字出现的比例构建变量freq2it。freq1it和freq2it数值越大,说明企业家的名字越是常见。以企业是否同名的虚拟变量nameit作为被解释变量,分别以freq1it和freq2it作为解释变量,Probit 模型回归的结果表明(回归3和回归4),企业家人名越常见,对应企业越可能是同名企业。反过来则验证了假设2的部分论述,企业家人名越罕见,以自己名字冠以企业的可能性越低。
假设2同时指出,企业家人名越是罕见,同名企业的效益越高。为了验证这一点,分别将nameit与freq1it、freq2it的交互项代入方程(1)中进行回归,结果如回归5和回归6所示,交互项的系数估计值均显著为负,同名效应的作用强弱受到企业家名字罕见度的影响,名字越罕见,同名效应的作用越强。而在回归7 和回归8 中剔除同名企业样本,分别考察变量freq1it和freq2it对非同名企业利润率的影响,两者的系数并不显著,可见对于非同名企业而言,企业家人名是否罕见并不会决定利润率的高低。回归3至回归8的结果共同验证了假设2。
此外,企业家人名中字与字之间的常见度也存在差异。为了分析这种差异对命名的影响,将每个人名的汉字进行常见度排序,构造排序变量rankit,当汉字的常见度最低时,rankit取值为1,第二低时,rankit取值为2,以此类推。明显rankit的最大值不超过该人名包含的汉字数。同时构造二元匹配变量matchit,当汉字出现在企业名中时取值为1,否则0。以matchit为被解释变量,rankit为解释变量,对同名企业样本进行Probit回归,并控制企业固定效应。结果如回归9所示,rankit的系数显著为负,人名中的某个字越常见,企业家越不愿将其冠予企业。一方面,既然企业家选择同名策略,那么当然会倾向于使用信号更强的字;另一方面也表明,在变量freq2it的选取中,使用人名中最不常见字出现的比例是合乎逻辑的。
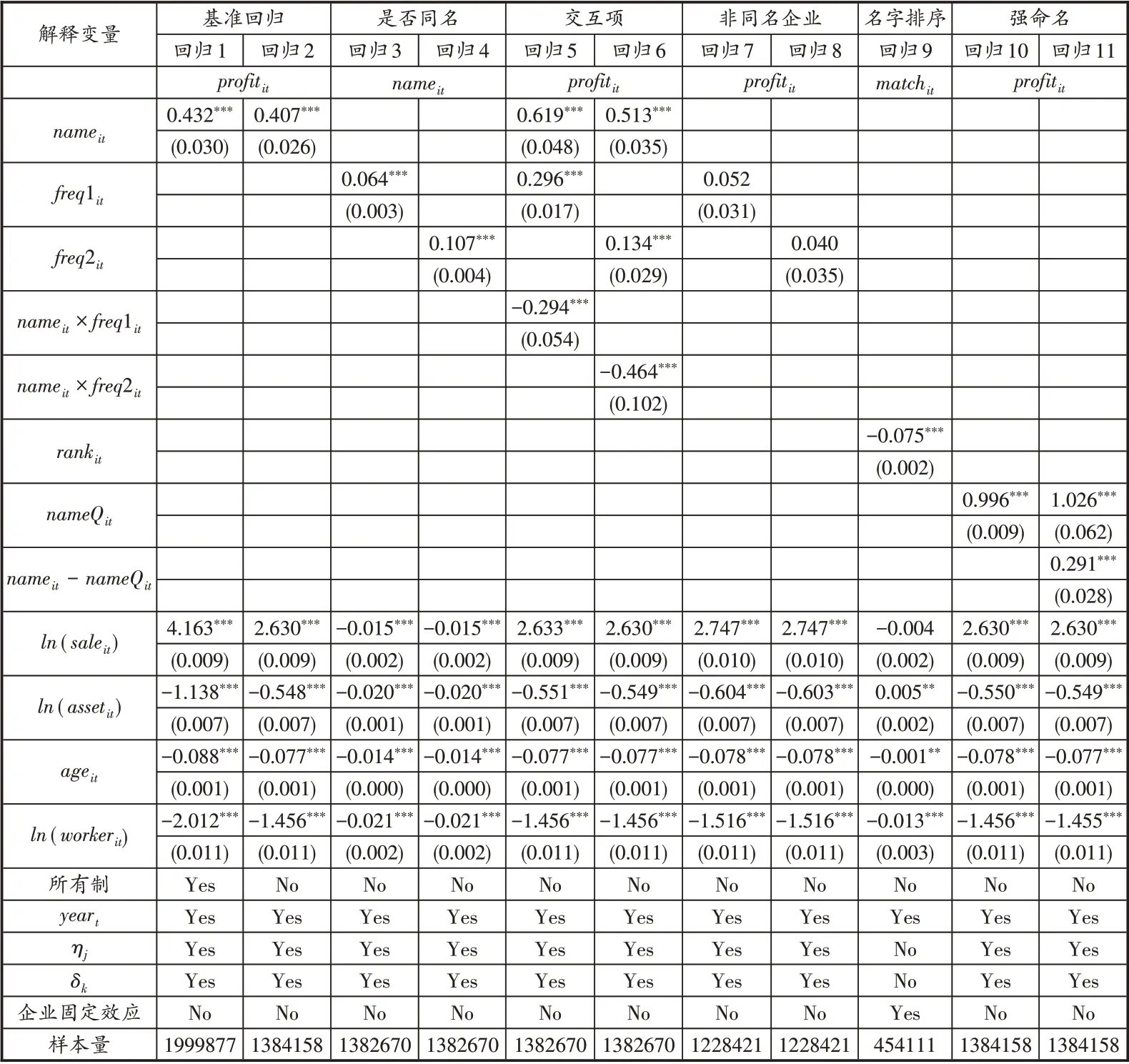
表2 同名企业的利润优势
最后,不同于西方单词,由多个字母构成且容易识别,中国汉字是象形文字,一个字可以包含多种含义,但是在信号强度上却弱于西方单词。例如英语系国家往往仅靠姓氏(last name)就可以将两人区分开,而在中国则需要全称。在建立与企业的纽带时,单个汉字给企业家带来的荣誉收益也不像单词一样强烈。结合中国语言习惯,本文特别地考虑多字同名的情况,并将多字同名和以姓氏命名划分为一类,构造了强命名变量nameQit。相比于单字同名,强命名的纽带关系更加紧密,能给企业家带来更高的名誉收益或者成本,因此能力强的企业家倾向于选择强命名策略,企业的效益也会更好。回归10 和回归11的结果佐证了这一点。在回归10中,nameQit的系数显著为正,平均而言,强命名企业的利润率比其余企业高出1个百分点,相当于全样本平均利润率(2%)的50%,数值上远高于回归2中nameit的系数估计值。回归11增加单字同名解释变量nameit-nameQit,此时nameit-nameQit系数的估计值(0.291)明显小于nameQit的估计值(1.026),且两者的95%置信区间并不重叠(前者[0.236,0.350],后者[0.904,1.148])。鉴于上述分析,在本文的稳健性检验部分,将同时考察同名和强命名的情形。
五、稳健性检验
1.更名、兼营和变更所有者
首先,考虑企业异质性问题,筛选出发生过名字变更的同名企业,即同一人经营同一家企业,企业名从非同名变为同名,或者相反。这样做的目的是为了考察对于同一家企业而言,选择同名策略与否对企业效益的影响。面板回归的结果如表3的回归1和回归2,命名变量nameit和nameQit的 系 数 均 显著为正,同名策略对这类企业利润率有显著的正影响。然而,与命名不同的是,更名发生在企业生产经营之后,此时名字还概括了企业的历史状况,更名则是切断这一历史的手段(Tsai et al.,2015;谢红军等,2017)。假如某种因素损害了企业声誉,企业主通过更名摆脱原有的声誉来提高企业效益,那么此时会对估计结果造成偏差,回归3和回归4说明了这一观点。名字从非同名变为同名时(回归3),nameit的系数显著为正,从同名变为非同名时(回归4),系数虽然不显著,但是符号为负。可能的原因在于,企业从非同名变为同名,nameit的系数体现了同名效应加更名效应,表现为回归3中nameit的系数大于回归1;从同名变为非同名则体现了更名效应减同名效应,两种效应相互抵消从而估计结果不显著。去掉同名企业样本,分析一般企业的更名行为发现(回归5),更名效应changeit的系数(0.280)显著为正,但是却远小于回归3 中的nameit系数(0.677)。Chow test 表明两类系数存在显著的差异。因此,有理由认为在企业的更名行为中,同名效应起到了作用。
其次,考察兼营问题,即企业家同时经营多家企业,其中至少一家以企业家名字命名,一家是普通企业。企业家特质是内生性问题的重要来源,比较同一人经营的两家企业,可以减轻遗漏企业家特质带来的估计偏差。然而存在另一个问题,除了人名外,很难识别两家企业是否属于同一人经营。汉字的使用方式与西方文字不同,人名相同的情况更容易出现,以至于可能使属于不同企业家的企业由于人名的巧合被归纳为同一个所有者。统计发现,有十个人名在样本中至少出现了400次以上,而样本时间跨度为10 年,意味着这十个人名每个至少对应了40 家不同企业。鉴于此,考虑仅有两家企业识别为同属一人的情形,且两家企业来自同一个县级行政单位,一方面这样可以减少人名出现巧合的概率,另一方面假如企业之间距离太大,企业家往来奔波的高成本会导致精力侧重于一家企业。回归结果如回归6所示,同一个企业家的不同企业中,同名企业一般有更高的利润率。考虑强命名情况时,进一步将样本限制在1998年后成立的企业,得到回归7的结果,虽然此时的样本量已经很小(265对企业),但是强命名企业的利润率显著高于其他企业。当放松以上约束条件时,回归结果在数值上有所差异,但总体上显著。
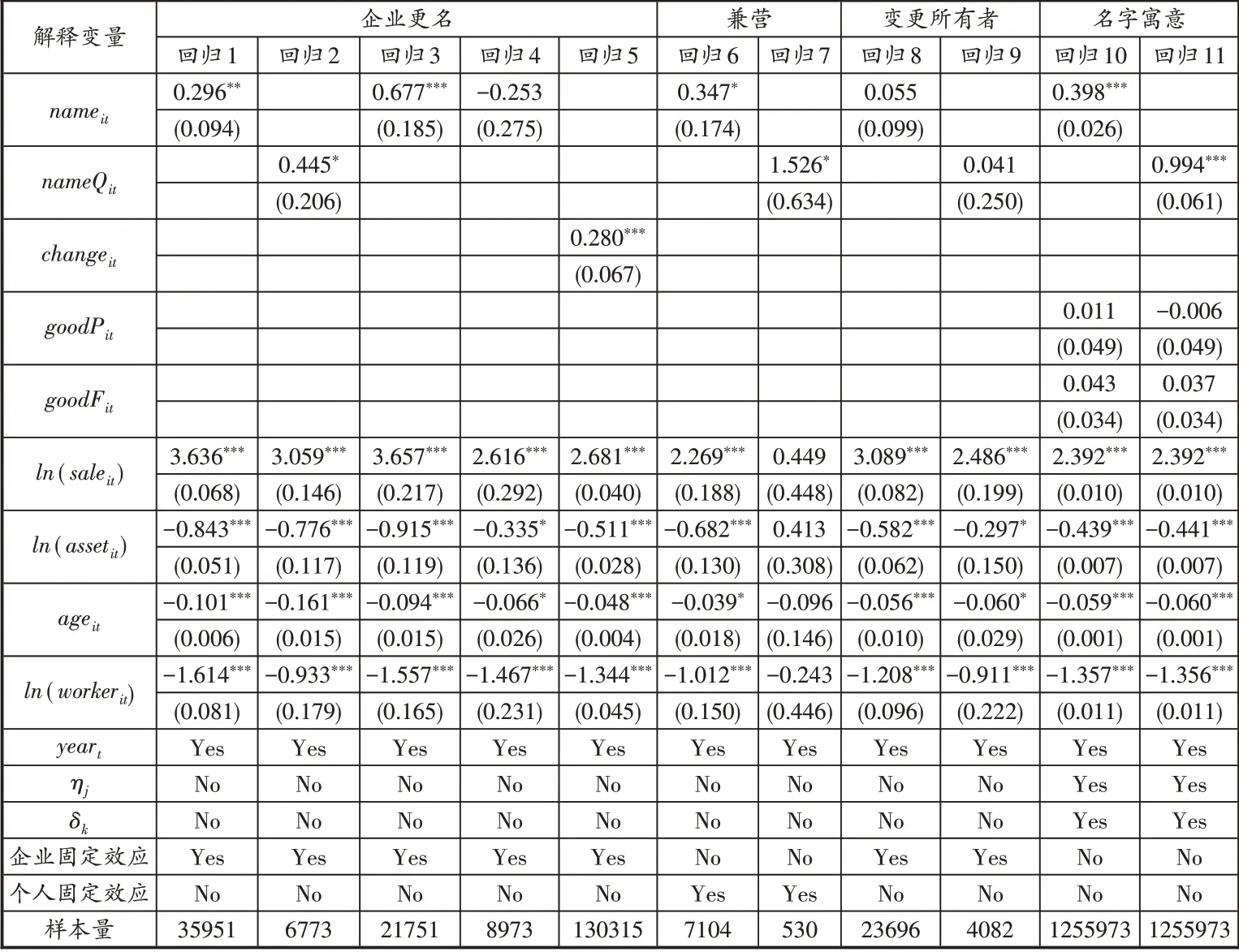
表3 更名、兼营、变更所有者和名字寓意
最后值得注意的是,当同名企业更换所有者时,企业名不变,表面上消费者认为该企业还是“那家”同名企业,但是nameit的取值改变,此时该变量的系数估计值应该显著为正。然而回归8 和回归9 的结果表明,nameit和nameQit的系数估计值并不显著。其原因可能为,一方面,消费者并没有及时观察到所有者变更,对于企业同名信号持有的信念不变;另一方面,继任者继承企业时,企业的经营状况已经固化,继任者需要足够的时间来改变企业效益。可见,虽然实际并没有观察到nameit和nameQit的系数估计值在更换所有者时依旧保持显著,但是不会从根本上动摇理论分析。此外,回归的结果印证了Tadelis(1999,2002)提出的理论假设,即当消费者观察不到企业经营者的变更时,企业名所承载的企业价值保持不变。
2.名字的寓意
当人名表达出一种好的寓意时,企业家可能更倾向于使用同名策略,同时有研究表明好的企业名更容易吸引消费者(Jacoby et al.,1971;Keller et al.,1998),因此,遗漏名字的好坏可能会给回归结果带来偏差。为了解决这个问题,使用清华大学自然语言处理与社会人文计算实验室公布的中文贬褒义词典,构造人名虚拟变量goodPit,当企业家名字中有褒义词时,goodPit取值为1,否则为0;同理,构造企业名虚拟变量goodFit,当企业名包含褒义词时,goodFit的取值为1,否则为0。将两变量带入方程(1)中,表3 回归10 和回归11 的结果显示同名效应依旧显著为正,且goodPit和goodFit的系数估计值均不显著,说明好名字并不会给企业利润率带来明显的提高。一种解释是,父母给孩子取名时一般都会考虑寓意好的字,使得企业家人名反而由于表达了相似的寓意而显得普通。此外,使用知网Hownet 情感词典做相同的检验,结果保持一致。
3.企业所有制
企业所有制不同会对同名策略的效果产生影响。首先,国有企业由于其特殊性,企业经营者不能将自己的名字冠予企业,即使出现同名,也只是巧合。单独抽取国有企业样本发现,nameit=1的企业占比极小,不到1%。将nameit作为解释变量,回归的结果见表4 的回归1,国有企业的“同名效应”并不显著。其次,1991年起施行的《企业名称登记管理规定》第十条规定“私营企业可以使用投资人姓名作字号”,但是没有明令禁止其他类型企业使用同名策略。而在2004 年修订颁布的《企业名称登记管理实施办法》第十五条规定“企业名称可以使用自然人、投资人的姓名作字号”,已经去除了私营企业的限制。样本统计表明,除国企和私营企业外,其它所有制企业也有同名现象,比如法人企业中弱命名企业比例为10%,强命名企业为1.6%,略微小于平均水平。鉴于此,分别考察私营企业(回归1 和3)和除国有、私营外其他企业(回归12 和13),结果表明同名效应均十分显著。
鉴于企业所有者和经营者不一定是同一人,单独考察私营企业命名问题。按照登记注册类型将私营企业细分为私营独资企业、私营合伙企业、私营有限责任公司和私营股份有限公司,分别进行回归,得到表4中回归4到回归11的结果。其中私营合伙企业nameit和nameQit的系数估计值均不显著,该类企业由两人以上出资成立,单个所有者对企业命名不一定有完全的决策权,并且命名决策者和企业经营者有时也不是同一个人,因此企业名字和经营者之间的纽带关系相对较弱。与此相比,私营独资企业和私营有限责任公司的企业家自主性有了很大提高,同名策略的作用开始显现,特别在后者中,无论是同名企业(回归8)还是强命名企业(回归9),同名效应均显著为正。私营股份有限公司与私营合伙企业类似,然而其强命名效应也在5%水平显著(回归11)。

表4 企业所有制类型
4.其他稳健性检验
首先,在数据清理中我们发现存在名字拼写错误的现象,少数企业由于人名或企业名的拼写错误,导致由原本的同名(nameit=1)变为不同名(nameit=0),或者相反。为了克服这类数据缺陷,保留那些观察期内nameit变量没有发生改变的企业样本,得到的回归结果基本不变。其次,考虑到地区语言习惯、文化传统的不同,去掉属于自治区、州、县的企业,同时去掉港澳台企业,结果保持与前文一致。第三,分年的截面回归,或者保留每年均出现在样本中的企业,得到的回归结果没有发生实质的变化。第四,为了排除异常值问题,我们分别在利润率profitit的1%和0.1%处做缩尾处理,重复前文的回归分析,结果依旧稳健。最后,使用倾向值匹配(PSM)的方法,筛选出同名企业的对照组,回归的结果同样基本不变。
六、结论
企业的名字由于承载了企业信誉,往往被视为企业无形资产的重要组成部分,学术界对此进行了大量的研究。然而鲜有文献涉及企业的命名问题。本文从信息传递的角度出发,研究了企业主以自己的名字为企业命名的方式。企业主采取该方式向外界释放自己经营能力、管理技能的信号,从而在某种程度上改善企业成立初期的信息劣势。本文的理论部分通过信号博弈模型解释了企业名字和企业效益的关系,实证部分利用1998-2007年中国规模以上工业企业数据对此进行检验。
理论上,本文将消费者购买决策分为两个时期,第一时期消费者根据产品的预期价值进行购买,第二时期消费者根据第一时期产品的实现情况改变预期,并根据新的预期再次购买。一方面,消费者的预期受到企业名字的影响;另一方面,企业家将自己的名字冠予企业,建立了企业效益和企业家个人荣誉之间的纽带。当企业经营状况良好时,这种纽带关系能够增强企业家从中获得的名誉收益,反之企业经营不善时,增强企业家的失败感。其结果是,能力强的企业家更倾向于采取同名策略。实证研究显示:平均而言,同名企业拥有更高的利润率;企业家人名越罕见,以自己名字冠以企业的可能性越低,而同名企业的利润率则越高;非同名企业的利润率与企业家名字的罕见度无关,最终随着企业家人名罕见度加深,同名企业与非同名企业间的利润率差距扩大。
本文的研究具有理论价值和现实意义。国内学术界严谨地研究企业命名的文献很少。在控制了企业特征等变量后,同名企业的利润率平均高出其他企业约0.4 到1 个百分点(详见表2的回归2和回归10)。考虑到全样本2%的平均利润率,这种由同名策略带来的利润率增幅不应该被学术界所忽视。相比于广告营销、品牌战略等,同名策略是企业家走出早期信息不对称困境时,可以采用的一种“廉价”手段。本文的研究为企业摆脱成立初期的信息劣势提供了借鉴,也为企业家特质与企业效益关系的研究提供了一个新颖且易于操作的角度。
