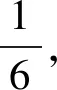基于DCNN的证件照人脸验证及应用研究
2020-04-02卞青山刘传文刘鸣涛张林涛
李 硕,卞青山,刘传文,刘鸣涛,张林涛
(1.临沂大学信息科学与工程学院,山东 临沂 276000; 2.临沂大学教务处,山东 临沂 276000)
0 引 言
近年来,人脸识别作为一种高效的特征识别技术,已经广泛应用到多个领域并且发挥了关键作用[1-2]。在不同证件审核应用场景中,对人脸识别验证技术也有着迫切的需求。目前,高校教务工作中,毕业照片的信息审核一直是一项人力成本较高的工作。该工作需要验证学生入学和毕业时采集的证件照片是否属于同一身份,由于该场景下需要验证的照片具有一定的时间跨度且该时期内部分学生的容貌发生较大变化,另外加上装扮等因素影响,导致具有同一身份的证件图像较难分辨,而不同身份的证件图像又极具相似性,从而使人工分辨较为困难、效率低下[3]。
随着深度学习的不断发展,基于深度卷积神经网络(Deep Convolutional Neural Networks, DCNN)的人脸识别技术对于解决上述毕业信息审核中证件照验证问题提供了一种非常好的解决方法和途径。通过算法的自动识别,可以大大减少人的冗余劳动。目前基于深度学习的人脸识别研究摆脱了传统上基于经验的人工设计特征与分类识别方式,DCNN通过构建多层非线性映射关系,拥有强大的特征学习能力,能够从大量样本中自动学习高维特征[4]。2014年,Taigman等人[5]提出DeepFace,首次将卷积神经网络运用于人脸识别,使用通过网络得到的人脸高维特征,计算余弦相似度来比较人脸是否相似。论文中指出,通过在Social Face Classification (SFC) dataset数据集的4030个用户的440万幅有标签的脸部图像训练后,在LFW数据集[6]上平均分类精度达到97.35%,同时在YouTube Faces (YTF) dataset[7]也达到较高的精度;2014年,Simonyan等人[8]提出的VGGNet,通过加深网络层数来提高性能,在ImageNet[9]数据集上训练后,LFW数据集上匹配精度为98.95%;2015年,Schroff等人[10]提出FaceNet,通过采用inception局部多分支网络结构并融入多尺度特征,通过采用三元组损失(triplet loss)进行网络训练,同时采用1×1的卷积核减少可训练参数,并在LFW数据集上获得了99.63%的精度。
综上,基于DCNN的人脸识别算法已经在人脸识别任务中取得了较高的准确率,但上述研究通过堆叠更深的网络层数来提取有效的人脸特征,然而较大的网络尺寸导致参数过多,计算复杂度增加,同时容易出现梯度弥散现象[11],导致网络模型参数难以被优化,增加了训练难度。同时上述网络的训练集数目均为百万级别,而实际应用场景中的样本数较少。所以若直接应用上述网络进行模型训练和验证,对于在年龄跨度、装扮及样本缺乏等因素影响的不同证件照人脸识别上的应用效果较差,无法满足实际应用需求[12]。同时VGG网络结构简单,且改进后的网络对于人脸的年龄属性有较好的识别效果[13]。因此本文对VGG16做出适应于证件照识别的改进,提出一个对不同证件审核场景下的人脸验证方法,通过对样本数量有限的CAS-PEAL-R1数据集[14]和自建的学生数据集训练后,能够有效地提高人脸验证准确率。同时改进后的网络模型能够快速收敛,实现了高校毕业照片验证工作的自动化进行,大大提高了审核效率,满足了实际应用要求,且对其他证件审核场景也有极大的参考作用。
1 基于DCNN的系统设计
本文所述的不同证件审核验证方法由数据预处理、人脸检测、模型训练、人脸验证等部分组成。在数据预处理部分,因通常证件审核场景下的数据集样本数目不充足,所以一方面根据人脸具有左右对称性,进行水平翻转等数据扩充操作[15];另一方面,通过交叉验证方法[16]进行反复训练测试,选择测试误差最小的模型,从而提高训练后模型的泛化能力。在人脸检测部分中,将预处理后的数据集通过MTCNN[17]进行人脸检测,裁剪出统一的人脸区域并去除背景干扰,生成标准统一的人脸标准化图像进行后续的人脸特征提取。在模型训练部分中,通过基于VGG-16改进的深度卷积神经网络,提取人脸特征,并且由于证件数据集的小样本数据属性,摒弃了Facenet中提出的三元组损失函数,而采用中心损失函数(Center Loss)[18]和Softmax损失进行联合训练。经实验表明,联合损失函数能够在证件审核场景中,保持较高准确率且网络模型能够快速收敛,避免了因三元组选择不当而产生的网络收敛较慢的情况,同时网络采用GPU加速训练。在模型测试和验证部分,将待识别的人脸图像通过训练好的网络模型映射为128维的特征向量,最后再将其进行相似性度量[19],通过比较阈值判断2幅图像是否具有同一身份。另外,本文使用的自建数据集已进行匿名处理不涉及个人隐私。整个系统的设计框图如图1所示。

图1 系统整体实现模型
1.1 人脸检测及提取
本文通过MTCNN进行人脸检测和提取工作。MTCNN是一种多任务级联卷积网络,通过3个级联的卷积网络,从粗略到精细地检测和对齐人脸图像。开始前,为在统一尺度下检测人脸,先将人脸图像缩放到不同尺度,分别通过网络进行计算。第一级P-Net网络主要对不同尺度下的图像进行粗略判断,大致确定人脸候选框位置,然后通过NMS(非极大值抑制)合并高度重合的候选框。第二级R-Net依然通过边框回归和NMS进行筛选人脸区域,最后通过精确度最高的O-Net网络输出精确的人脸框和特征点位置。MTCNN级联网络结构如图2所示。
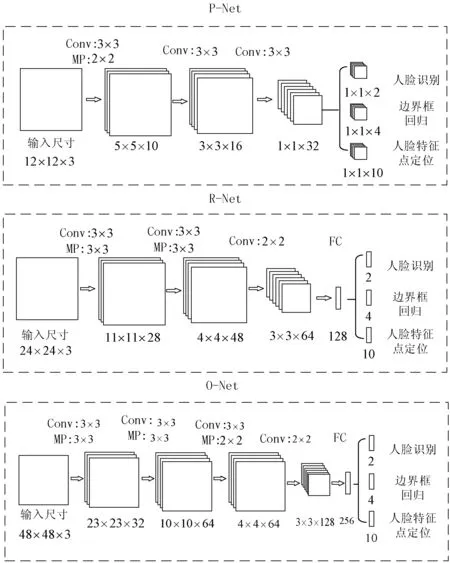
图2 MTCNN级联网络结构图
最后,将人脸图像通过MTCNN检测网络剪裁到96×96,去除背景干扰并将像素值减去127.5后除以128进行归一化处理。人脸检测提取的过程如图3所示。

图3 人脸检测提取示意图
1.2 改进的DCNN网络结构
本文的人脸特征提取网络基于VGG16做出适用于证件照识别的结构改进。VGG16采用直线型网络结构,通过堆叠3×3的小卷积核和2×2的最大池化层构建16层深度的卷积网络,减少计算并充分发掘网络性能,具有良好的特征提取效果,且在LFW数据集上的识别率也达到了98.95%的精度。但该网络直接应用于证件照人脸验证时效果表现差,准确率低,不能够满足证件照审核的要求。同时,原始网络结构可训练的参数量非常大,共包含1.38亿个参数,模型训练时间较长。所以本文基于VGG-16网络做出以下改进:首先实际的证件照样本尺寸较小,所以本文采用96×96×3大小的输入图像。保留原网络主体5段卷积部分和最大池化层、全连接层。网络中的卷积部分由多个卷积层串联而成并且每层卷积核数相等,不同卷积部分的卷积核数分别为64、128、256、512、512,多层卷积层串联能较好地拥有非线性变换能力。更改的网络模型参数如图4所示,为简洁显示,Dropout层和ReLU激活层已省略。图中,Conv表示为卷积层,且后面所显示数字为卷积核的大小,×2或×3表示为串联卷积层的数目,MP为最大池化层,且stride为2。由于可训练参数的增加基本由最后3层全连接层引入,所以本文采用3级全连接层节点数递减的方式,较原网络显著减少可训练参数。同时去掉原网络中的Softmax层,最后将输出的128维向量作为人脸特征值,同时在全连接层后加入Dropout层和ReLU激活层,防止由于可训练参数量过大导致模型出现过拟合的现象。
图4 人脸验证网络结构图
1.3 基于中心损失的联合监督函数
本文采用基于中心损失的度量学习方法进行模型监督训练,该方法可以有效地反映不同数据之间的特征分布,使得同一类别样本在特征空间中更加紧凑,同时不同类别的样本在特征空间中尽量远离[20]。度量学习方法通过在卷积神经网络之间共享参数,将最后全连接层输出的128维特征向量作为人脸特征值并计算欧氏距离来度量其相似性。
不同证件审核场景下的人脸图像数据一般类内样本数目较少,且由于年龄跨度、装扮等因素影响,使得类内距离通常大于类间距离。所以虽然SphereFace提出的A-Softmax[21]损失函数能够通过基于边界分类的方法训练网络模型,且在LFW取得了99.42%的准确率,但在证件审核场景中,由于直接训练上述损失很难收敛,增大了训练难度。Triplet Loss中三元组的构造方式需要特殊的采样方法,增加了资源的消耗和网络训练的难度,同时对该损失函数进行训练需要较大的样本数据集。与同样基于度量学习的Triplet Loss相比,基于中心损失的联合监督函数不需要采用特殊的三元组采样方法,就能提取到区分能力更强的人脸特征且对于缩小类内距离具有一定的约束,采用较少的样本数据即可达到相似的效果。所以本文采用联合监督函数进行模型训练。
中心损失为每个类别学习一个中心,并且将每个类别的所有特征向量拉向对应的类别中心,在人脸识别场景中,Center Loss在Softmax Loss的基础上,显式约束了类内紧凑,即使训练的特征更具内聚性。中心损失定义为:
(1)
其中,xi为人脸输入图像,yi为人脸图像所对应类别,cyi为每个类别的中心,从理论上说,类别yi的最佳中心为每类所有人脸图像特征的平均值,但这样计算复杂度较高。针对这个问题,先在初始阶段随机确定cyi,接着在每个batch内对cyi计算梯度,从而更新cyi。每个batch中的中心损失为:
(2)
其中,N为每个batch的大小。基于中心损失的联合损失函数为:
(3)
其中,λ为平衡Center Loss权重值的超参数。在训练的初始阶段,随机确定cyi,接着在每个batch内,使用中心损失Li对cyi也计算梯度,并对其进行更新。联合损失函数在网络中的连接方式如图5所示。

图5 联合损失函数在网络中的连接
2 数据准备及训练
2.1 数据集
本文所用数据集为CAS-PEAL-R1数据集和实际自建的证件照数据集。CAS-PEAL-R1人脸数据集由国家高技术研究发展计划和Is’vision Technologies Co., Ltd公司赞助收集。本文使用该数据集下的除去表情变化条件的正面子库,包括标准、光照、饰物、背景、距离、时间6种变化条件,能够全面包含不同证件审核下的人脸验证场景,该数据集下的部分样本图像如图6所示,共包含1040人的共7176幅图像,具体信息如表1所示。自建的证件数据集由学生入学和毕业时所采集的正面照片组成,部分样本图像如图7所示,共包括9732人的19464幅人脸图像。
另外,由于CAS-PEAL-R1数据集为处理后格式为BMP位图的灰度图像,所以在后文模型训练开始,先将其转化为JPG格式的RGB图像。
表1 CAS-PEAL-R1的正面图像子库及自建的证件数据集

照片类型变化种类人数图像数目标准110401040光照≧92332450饰物64382646背景2-4297650距离1-2296324时间16666自建数据集—973219464

图6 CAS-PEAL-R1数据集部分样本对

图7 自建数据集部分样本对
由于本文采用的数据集与上述文献中相比,训练数据不充足,所以本文采用交叉验证的方法,随机按照7:3分为训练集和测试集2个部分。选择不同情况下测试误差最小的模型作为最终模型。并为检验模型的泛化能力预留1000对自建数据集中的人脸数据,人为设置500对负样本以便后续进行模型验证。
2.2 模型训练
在模型训练过程中,由于训练复杂的卷积神经网络需要足够大的样本数据,且计算机硬件要求较高。考虑到本文数据样本量有限,全部重新开始学习容易出现过拟合现象,因此使用在MS-Celeb-1M数据集[22]上已经训练一段时间的模型参数作为网络的初始权值。在MS-Celeb-1M数据集上训练约30个小时且在LFW数据集上验证准确率为84%时停止训练,再通过标记好的自建数据集和CAS-PEAL-R1数据集继续训练。训练学习率设为0.001,batch size为128,采用梯度下降算法进行参数优化。
文献[23]中,对λ的选取进行了实验,并且得出当λ为0.003时可训练出最优模型,且在LFW、YouTube Faces测试集上分别取得了98.27%和91.1%的准确率。所以本文在模型训练初,将λ的值设为0.003,以便达到最优效果。
3 实验验证分析
本文采用了深度学习框架TensorFlow进行模型训练和测试,硬件配置CPU为Inter(R)CoreTMi3-2120,主频3.30 GHz,运行内存为12 GB,系统环境为Window7 64位操作系统,同时采用了GPU加速训练,型号为Nvidia GeForce GTX 1060,显存为6 GB。
3.1 不同方法的训练分析
按照上述模型训练的方式,对不同方法在不同数据集上进行训练,得到的不同损失曲线如图8所示。

图8 不同方法在训练中的损失曲线
当训练损失值为0.3时,记录不同方法训练下的耗时等信息,其中,由于基于原始网络模型进行训练时,损失最终收敛于0.65便不再继续下降,所以记录其损失值为0.7时的详细信息。具体如表2所示。另外,训练耗时与计算硬件有较大关系。
表2 不同方法训练下的详细数据
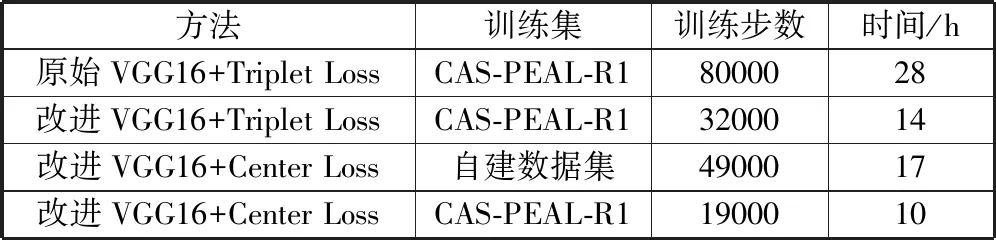
方法训练集训练步数时间/h原始VGG16+Triplet LossCAS-PEAL-R18000028改进VGG16+Triplet LossCAS-PEAL-R13200014改进VGG16+Center Loss自建数据集4900017改进VGG16+Center LossCAS-PEAL-R11900010

同时,对比同一改进网络在不同损失函数下的监督训练,可以看出,对于证件审核场景下的数据特点,基于中心损失的联合监督函数可以更好地进行训练。因为该场景下的类内样本数目较少,尽管通过数据扩充后,仍然需要进行特殊的采样来组成三元组进行模型训练,耗时严重,同时三元组的选择不当易导致模型收敛困难;而基于中心损失的不需特殊的采样,所以收敛较快。
另外由于自建数据集每人只有2幅图片,进行相同的数据扩充后,类内样本数目依然少于CAS-PEAL-R1数据集。所以与之相比,虽然最后的损失阶段下降较慢,但初始均能较快收敛。所以本文方法在训练时间和收敛速度方面均显著优于原始方法。
3.2 最佳阈值及不同方法下的准确率分析
对自建数据集中预留出的1000对人脸数据进行测试实验,包含500对相同人脸对和500对不同人脸对。本文采用的距离度量方式为欧氏距离,选用上述基于中心联合损失和改进网络结构并在CAS-PEAL-R1数据集上训练的模型,验证其在不同阈值下的准确率,详细如图9所示。

图9 最优阈值判定结果
由图9可知,当阈值为0.64时,人脸验证准确率达到最高,为95.49%。同时在不同方法各自的最佳阈值下,测试其在自建数据集上的准确率和召回率。实验结果如表3所示。
表3 不同模型下的实验结果
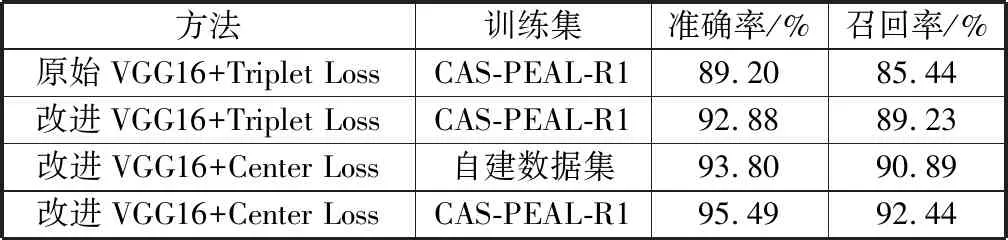
方法训练集准确率/%召回率/%原始VGG16+Triplet LossCAS-PEAL-R189.2085.44改进VGG16+Triplet LossCAS-PEAL-R192.8889.23改进VGG16+Center Loss自建数据集93.8090.89改进VGG16+Center LossCAS-PEAL-R195.4992.44
由表3及上述实验可知,本文所提方法不仅可以大幅度降低训练耗时,同时也能保证较高的准确率。改进的VGG16网络通过卷积层参数调整及全连接层节点数递减的方式,使其更加适应于标准正视人脸,对于不同证件审核应用场景有较好的适用性。同在Triplet Loss监督训练下,准确率和召回率较原网络模型(原始VGG16)分别提高了3.68个百分点和3.79个百分点。
不同证件审核场景下的数据集具有类内样本数目不足的特点,导致组成三元组所需的正样本数目较少,三元组采样的不合理性对于最终模型的准确率有较大影响。通过在自建数据集和CAS-PEAL-R1数据集下训练模型可知,基于中心损失的联合监督在证件审核场景下表现优于Triplet Loss。同时对比原始方法可以得出,本文所提方法在准确率和召回率上分别有6.29个百分点和7个百分点的提高。在本文实际应用场景中,为确保全部排查出错误人脸,基于最高准确率对应的阈值进行调优,当阈值为0.52、准确率为92%的情况下,可以将错误人脸对全部筛选出来,对于高校教务审核减少了约95%的冗余工作,满足了不同证件照审核工作的实际应用的要求。
4 结束语