基于维度分解的多核并行网包分类算法
2020-04-02唐志斌曾学文
唐志斌,曾学文,陈 晓
(1.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190; 2.中国科学院大学,北京 100049)
0 引 言
网包分类技术是指对接收到的数据流中的网包与分类器中的规则集进行匹配,并根据所匹配的规则对应的动作类型对网包进行相应操作处理[1]。分类器是一系列规则或者策略的集合,每一条分类规则都指定一个类别或者是一条特定的流,将收到的网包头部中特定的字段与规则集中对应的字段相比较匹配,可以判断该包符合哪些规则,进而判断其所属的类别或网络流[2]。许多网络服务都需要包分类功能,比如路由、防火墙、网络计费、服务质量(QOS)保证、虚拟专网(VPN)等[3-4]。随着网络技术的飞速发展,网络流量和带宽都在不断增长,对网络设备的处理能力提出了越来越高的要求[5]。作为网络中最基本、应用最广泛的功能之一,包分类性能逐渐成为各类网络应用的瓶颈,亟待提高。
许多包分类算法基于数学建模分析,在分析和仿真层面往往能取得较低的时间或者空间复杂度,但是因为纯数学层面的分析往往添加特殊条件来简化问题,而这些条件在现实使用中往往无法得到满足,因此难以在实际应用中使用。还有一些算法使用硬件来加速包分类,往往能达到极高的性能,比如现场可编程门阵列(FPGA)[6]、专用集成电路(ASIC)、三态内容寻址存储器(TCAM),然而专用硬件往往价格昂贵,开发周期长,而且往往存储空间比较宝贵,不适于较大的规则集,极大地限制了硬件算法的适用性[7]。
按照文献[8]的描述,包分类算法可以分为如下4种类型:穷举搜索法、决策树法、元组空间法和维度分解法。穷举法思路最简单,通常由硬件实现,比如TCAM[9-10],速度快,但是成本高,不适合广泛应用;基于决策树的算法通常根据规则的特性构建一系列决策树,通过从根节点到叶子节点的逐级访问实现包的分类,比如Grid-of-Tries[11]、HyperSplit[7]算法,该类算法往往针对特定类型的规则集效果较好,并不广泛适用各类规则集,且对规则维数扩展性差;基于元组空间的算法按照规则前缀长度对规则的每一维进行分组,并以前缀作为哈希关键字进行哈希查找,多个维度的分组组合在一起就形成了元组空间,代表为TSS(Tuple Space Search)[12],该算法空间占用小,但是哈希函数的使用使其性能不稳定;基于维度分解的方法以一定的字节数或者比特数为单位,将每一条规则分解为多个维度,每个维度先单独进行查找,然后经过合并得到最终查找结果。基于维度分解的代表性算法有BV(Bit Vector)[13]、ABV(Aggregated Bit Vector)[14]、RFC(Recursive Flow Classification)[15]、HSM(Hierarchical Space Mapping)[16]、PCIU(Packet Classification Algorithm with an Incremental Update Capability)[17]等,其中PCIU算法可以适用于各种类型的规则集,对规则集的维度没有限制,而且具有动态增量更新的特性,分类速度也比较快。此外,还有结合几种类型特点的算法,比如HiCuts[18]、HeyperCuts[19],通过几何分割,把规则集映射为多维空间,再使用决策树分割规则集,在叶子节点通过线性搜索完成包的分类。
软件包分类算法大多为串行的、面向单核的,其性能依赖于处理器的单核性能。而根据目前的处理器发展,单核集成度已经接近极限,性能提升越来越难,摩尔定律正在走向终结,处理器的发展方向转向多核化,虽然单核主频较低,但通过增加处理器核心数量可以提升整体处理器的性能。串行的算法并不能很好适应多核处理器,常常无法充分利用处理器资源,限制了其性能。因此,如果能结合多核处理器的特性,将包分类算法进行并行化的调整和优化,可以提升分类性能。
目前已经有一些对包分类的并行化研究,比如文献[20-21]提出的基于FPGA、多核处理器和GPU的并行包分类系统、文献[22]提出的STORM并行分类方案,以及文献[23]提出的基于GPU和CUDA的并行报文分类方法。但是这些都是包级别的并行方案,因为每个包的处理时间不一定相同,在分类过程中会导致包输入与输出顺序不一致。考虑到维度分解法的特性,每个维度的单独查找可以指定某个核,或者多个核并行处理,多个维度查找结果的合并也可以由多核完成,实现包内级别的并行。因此,本文基于维度分解的思想,提出一种包内并行分类算法IPPC(Intra-Packet Parallelism Classification),实现包内级别的并行,将每个包的分类过程用多个核心并行执行,实现数据包分类的并行加速,同时能保持包的输出顺序与输入顺序一致,避免通常多核并行处理数据包时容易出现的乱序问题。
1 方案分析与选择
1.1 串行方案分析
以BV、PCIU算法为代表的基于维度分解的包分类算法,在将整个规则的多元组划分成更小的多个维度之后,匹配工作可以在每个维度上单独进行,再将每个维度的匹配结果合并在一起,以得到最终的整体匹配结果。每个维度的匹配结果都产生一个位向量(BV),需要将各个维度的BV全部合并,得到最终的BV以得出匹配结果。在整个包的匹配过程中,各维度的匹配结果合并的过程所耗费的时间远远多于每个维度上的匹配时间,因此主要关注的是合并过程。如果这一过程是串行的,假设2个BV合并一次的时间为t,一条规则经过维度分解产生K个维度,那么K个维度的合并时间为(K-1)t。
1.2 包级并行方案分析
如果采用数据包级别的并行,多个核心使用完全RTC(Run to Completion)的并行结构[24],即每个核心执行一个独立的包分类算法,输入的数据包被分配到不同的核心去进行匹配,每个核心独立完成包分类匹配的所有操作,因此每个包K个维度的BV合并过程是在同一个核心上串行执行的。由于多个核心可以同时并行执行多个包的分类匹配,相比于单核系统,包级别的并行处理可以明显提高系统整体的吞吐。但是,值得注意的是,每个包的BV合并时间仍为(K-1)t,单个包的整体匹配时延也没有缩短。而且,由于每个包在各自的核心上的处理时间不一定是相同的,导致多个包同时经过多个核心处理之后,输出的顺序与输入的顺序可能会不同,即无法保证输出与输入包的顺序一致。对于属于同一条流的数据包,如果经过分类之后顺序发生了改变,会导致这一条流出现意外的乱序事件,增加后续操作的重排序开销,甚至造成意外的程序故障。
1.3 包内并行方案分析
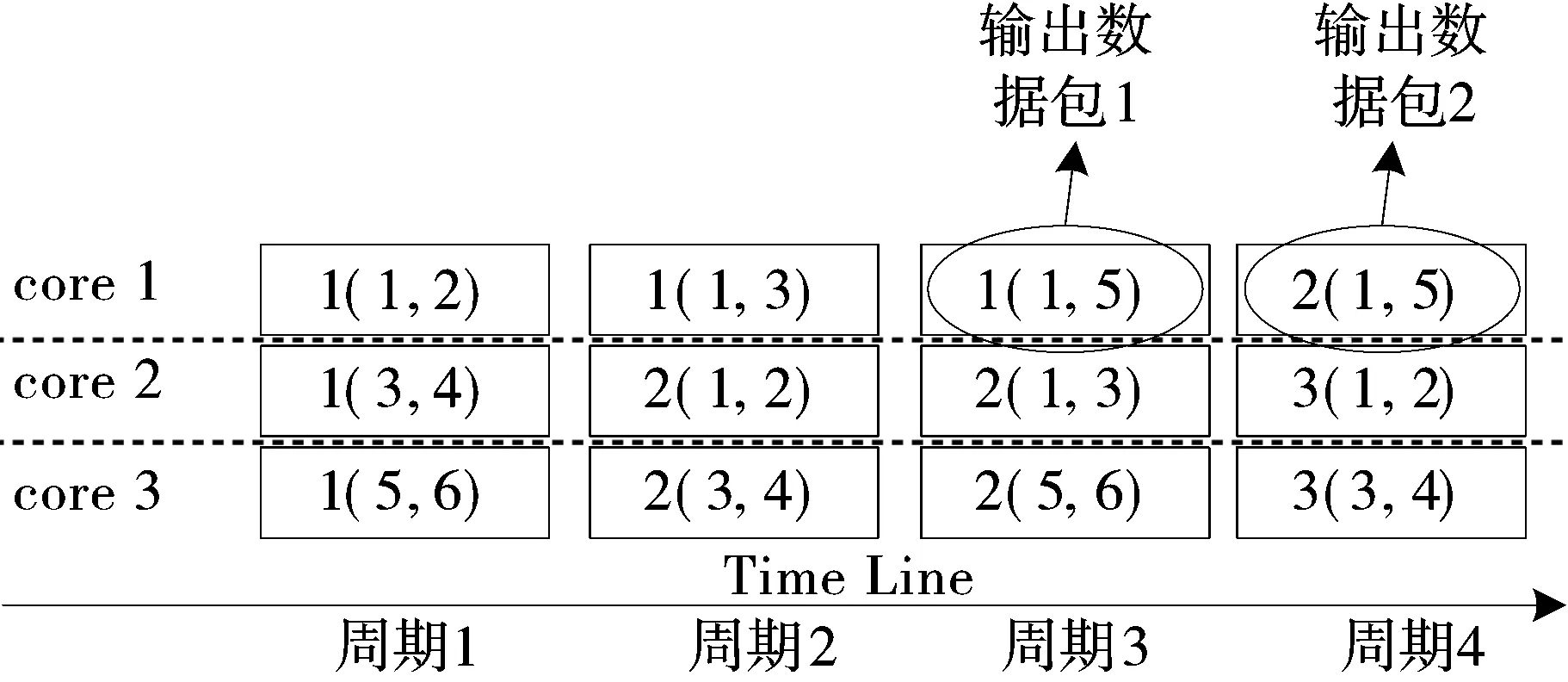
除了包级别的并行,还可以采用包内并行处理,即同一个包的分类匹配过程由多个核心来同时执行。经过维度分解之后的各个维度一共产生K个BV,K个BV合并的过程由多个核心同时进行,在一个合并周期t内可以完成多次相互独立的合并,如图1所示。经过简单的分析可知,当处理器核心数目大于等于K/2时,合并过程的时间可以缩短到「log(K)⎤个周期,即「log(K)⎤t,大幅缩短单个包的匹配时延。以五元组的规则集为例,其5个字段共13 Byte,以1 Byte为一个维度,可分解产生13个维度,即K为13,如果用串行方式合并,需要12个计算周期才能完成13个位向量的合并,而如果使用6个核心去并行执行13个位向量的合并,只需要4个计算周期即可完成。另外,尽管匹配是多核并行处理的,但由于是在包内级别的并行,先输入的包总是被先处理完,因此整个系统仍然是按照包输入的顺序在逐包匹配,输出结果是保序的。

图1 多核并行合并BV过程
1.4 并行方案选择
基于以上分析,本文的算法设计运用维度分解及BV的思想,并采用包内级别的并行方案,在提高系统吞吐的同时,实现保序的并行分类,并减少单个包的分类时延。
2 算法设计
2.1 预处理过程
本文结合BV与PCIU算法的思想对规则集进行构建预处理。预处理步骤如下:
1)将各种形式的规则集,比如表1中前缀匹配形式转换为由最小值和最大值组合成的范围表示形式,如表2所示。
2)将规则集分解成1 Byte大小的子块,每个子块为一个维度,在该维度上每条规则的取值有其上限和下限值,如表3所示。每个维度的取值范围为0~255,即每个维度的搜索空间大小为28,因此为每个维度分配一个大小为28的查找表来列举该维度的所有取值。
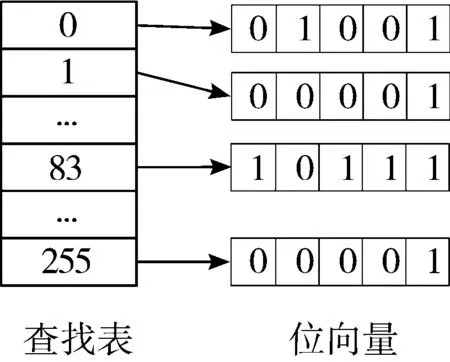
图2 维度1对应的查找表和位向量
3)每个维度查找表中的每一个取值,都与该维度下的所有规则比对,检查是否满足规则,并分配一个BV,记录每个取值所满足的规则。位向量BV是一串比特串,长度为规则数N,比特串中的每一个比特位表示对应的规则的编号ID,如果满足规则该位置为1,不满足则置为0。如图2所示为表1规则的第1个维度对应的查找表和BV,取值83落在第0、1、2、4条规则的范围之内,即该值满足第0、1、2、4条规则,则其对应的位向量为BV=10111b(N为5)。位向量生成的伪代码如算法1所示。
算法1预处理及位向量生成伪代码。
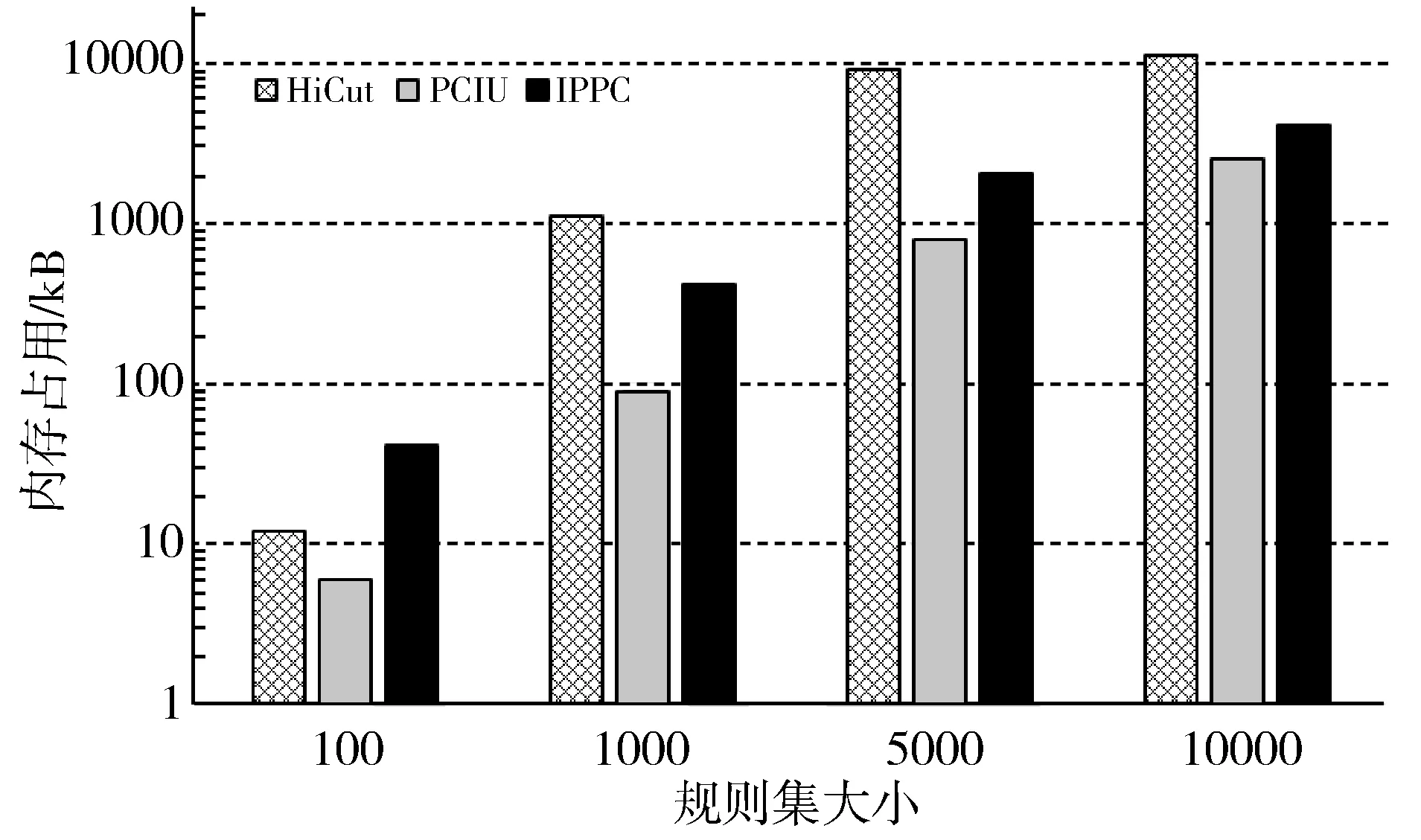
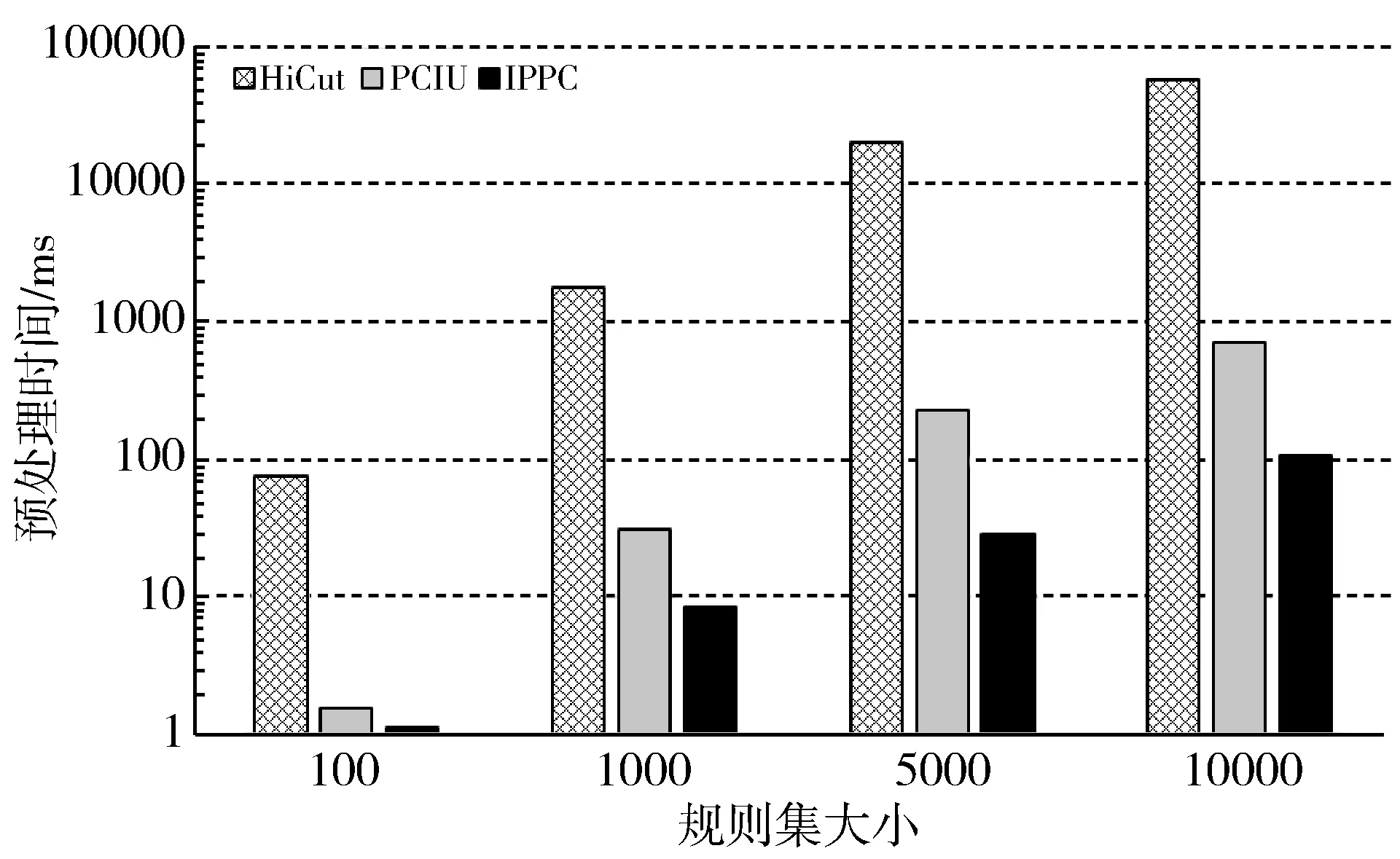
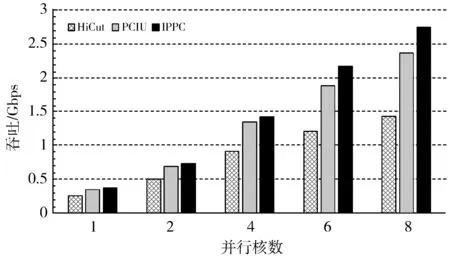
1:for m=0, m 2:for i=0, i<256, i++// 查找表的取值范围为0~255 3:VecPos=1; 4:BV=0; 5:for id=0, id 6:if i≥Rule[id].low and i≤Rule[id].high then 7:BV=BV|VecPos//按位或,将BV对应位置1 8:end if 9:VecPos=left_shift(VecPos); //左移一位 10:end for 11:Chunk[m][i]=BV; //Chunk[m]为第m个维度, //Chunk[m][i]为该维度对应查找表的第i个取值 12:end for 13:end for; 表1 规则集示例 规则源IP(32bits)目的IP(32bits)源端口(16bits)目的端口(16bits)协议号(8bits)00.0.0.0/00.0.0.0/00~6553521~210/ff10.83.1.0/240.0.4.6/320~6553520~3017/ff20.83.4.0/220.0.0.0/00~6553521~210/030.0.9.0/240.0.0.0/00~655350~655356/ff40.83.0.77/320.0.4.6/320~655350~6553517/ff 表2 以范围形式表示的规则集 规则源IP(32bits)目的IP(32bits)源端口(16bits)目的端口(16bits)协议号(8bits)00.0.0.0~255.255.255.2550.0.0.0~255.255.255.2550~6553521~210~010.83.1.0~0.83.1.2550.0.4.6~0.0.4.60~6553520~3017~1720.83.4.0~0.83.7.2550.0.0.0~255.255.255.2550~6553521~210~25530.0.9.0~0.0.9.2550.0.0.0~255.255.255.2550~655350~655356~640.83.0.77~0.83.0.770.0.4.6~0.0.4.60~655350~6553517~17 表3 维度分解后的规则集 规则源IP(32bits)目的IP(32bits)源端口(16bits)目的端口(16bits)协议号(8bits)维度0维度1维度2维度3维度4维度5维度6维度7维度8维度9维度10维度11维度1200~2550~2550~2550~2550~2550~2550~2550~2550~2550~2550~021~210~010~083~831~10~2550~00~04~46~60~2550~2550~020~3017~1720~083~834~70~2550~2550~2550~2550~2550~2550~2550~021~210~25530~00~09~90~2550~2550~2550~2550~2550~2550~2550~2550~2556~640~083~830~077~770~2550~2550~2550~2550~2550~2550~2550~25517~17 本文预处理算法与PCIU算法的不同之处在于,本文为查找表的每个取值都分配一个位向量BV,而PCIU算法针对规则分解之后各个维度上可能存在的冗余,采用了分组的方式,将冗余规则合并,满足同样规则的取值被分为同一组,每个组分配一个位向量BV,这样可以减少总的BV数量,进而减少内存开销。然而,当规则集规模增大,规则更为复杂的时候,冗余度会下降,存在的分组数会增多,最差的情况是每个取值所满足的规则组合都不同,即退化到分组数与查找表大小相同的水平,因此,分组操作在实际使用中能带来的内存节约水平有限。然而分组的操作反而会增加预处理的复杂度,因为在确定分组时,需要将一个BV与所有已经存在的分组对应的BV比较是否一致,进而确定该BV属于已存在的某个分组还是一个新分组,而BV比较的时间复杂度是O(N),即规则集越大,计算开销越大。在规则集更新时,PCIU算法需要对所有分组进行重新构建,相当于重建整个规则集,时间开销巨大,而提升规则集更新速度在SDN等场景下是至关重要的[25]。本文的算法在更新规则集时,只需要更新每个BV的对应位,而不用重新构建。因此综合看来,在规则集较大的情形下,分组所带来的内存节约的好处可能无法掩盖其处理开销增大的代价。本文的预处理方式需要比PCIU更多的内存空间,但与PCIU处于同一数量级,而且消除了分组的时间开销,大大提高了预处理和增量更新的速度。 到达分类器的数据包,先将包头中用于分类的字段切分成与预处理阶段相对应的1 Byte大小的子块。用该数据包头每个子块的取值,分别在预处理阶段构建好的查找表中找到对应的位向量BV,K个维度共得到K个BV。然后,将这所有维度得到的BV执行按位相与操作,得到一个最终的BV,在这最终的BV中,置1的位表示这个包最终所满足的规则。如果在最终BV中有不止一个置1的位,则表明满足多条规则,考虑到规则集通常是按照优先级先后的顺序排列的,因此选择第一个置1位作为最终的结果输出。 在进行包内级别的并行方案的设计时,如果按照图1的并行流程,首先为每2个BV分配一个核心进行第一个周期的计算,计算结果保存在其中一个BV中,然后对上一个周期计算生成的新BV重复这一合并过程,直到最终只剩一个BV,即为最终的匹配结果。从这样的并行合并过程可以看出,随着每个计算周期的逐步进行,同一个包所需要的核心数在减少,上一个周期用到的核在下一个周期会出现空闲,比如图1中,在第二和第三个计算周期只有Core1在工作,Core2和Core3处于空闲状态。核心空闲是对计算资源的浪费,这是并行算法设计中不应该出现的。因此,为了提高核心的利用率,在一个包处理过程中空闲的核心应该被用于处理下一个包,避免核心空闲。 本文的算法通过多核心并行抢占BV的方式来实现这一目标。每个包经过K个维度的匹配得到K个待合并BV,所有待合并处理的包按照到达的顺序排列,形成一个先进先出队列。所有核心同时不断地尝试从队列的第一个包中获取2个相邻的BV进行合并,并将这2个BV标记为已抢占,避免被其他核心获取。合并完成之后,被抢占的2个BV中,一个用于存入合并结果,成为新的BV,并解除该BV的抢占状态,另一个BV则清空,且保持抢占状态,然后重复此过程。如果队列头部的包内无法获得2个未被抢占的BV,表明该包的所有BV都已经被抢占且正在合并中,则进入下一个包尝试获取BV。当一个包仅剩唯一一个BV,其余BV全为空时,该包匹配完成,从最终的BV中获得最终的分类结果。并行合并过程伪代码如算法2所示。 算法2并行合并过程伪代码(所有核心同时运行相同代码)。 1: while(true) do 2: P=P0; //获取第一个数据包 3: while P !=NULL do 4: for i=0, i 5: if BV[i].occupied==false then //未被抢占 6: BV1=BV[i]; break; 7: end if 8: end for 9: for j=i+1, j 10: if BV[j].occupied==false then 11: BV2=BV[j]; break; 12: end if 13: end for; 14: if BV1!=NULL and BV2!=NULL then 15: BV1.occupied=true; BV2.occupied=true; 16: BV[i]=BV1& BV2; BV[j]=NULL;//按位与 17: BV[i].occupied=false; 18: if BV[i] is the final BV in P then // BV[i]是最终的合并结果 19: rule[P]=get_rule(BV[i]); P->OUT; //根据BV[i]获得数据包P的最终匹配规则并输出 20: P0=next(P0); 21: end if 22: break; 23: else 24: P=next(P); 25: continue: 26: end if 27: end while 28: end while 以3个核且维度为6的情况为例,图3和图4分别从每个核心的角度和每个包的角度描述了并行合并的过程。图3描述了每个核心的抢占BV的过程,其中1(1,2)表示第1个包的第1个和第2个BV;图4描述的为相应的每个包的BV合并过程。 图3 每个核心的处理流程 图4 每个包的BV合并过程 通常,包内并行方式往往涉及多个核心对同一个包共享资源的竞争和互斥访问,导致额外的加解锁以及等待开销,但是结合代码和图例分析可知,本文描述的包内级别并行算法,并不涉及资源的共享访问,而是将BV视为任务,由核心进行主动抢占,如果处理核心发现一个BV已被抢占,它不会等待这个BV释放,而是继续去抢占下一个BV,没有空闲等待,因此不会增加核心间的竞争开销。 实验部分在Cavium OCTEON CN6645多核网络处理器平台上开展,对本文描述的包内并行分类方法进行实现,并将其性能与同平台下包级并行RTC实现方案的HiCut和PCIU算法进行对比。该平台具有10个工作频率1100 MHz 的MIPS架构通用处理核心,每个核心具有37 kB的L1 I-Cache, 32 kB L1 D-Cache,以及2 MB共享L2 cache和8 GB DDR3 SDRAM内存,2个10 Gbps网络接口。每个核心可以运行Linux操作系统或简单执行(Simple Execution, SE)高效环境2种模式之一,其中一个核心运行Linux模式,用来对平台进行管理和控制,其余核心均运行SE模式来实现分类算法,以提高数据包处理的能力。 实验所用规则集和数据包流来自ClassBench[26]公开数据集,并由相应的程序生成,所有规则集均使用五元组,其中32位的源和目的IP地址为前缀匹配形式,这里使用了100~10000大小的访问控制列表(Access Control List, ACL)规则集。使用ClassBench生成的数据包流只包含包头信息,在实际吞吐测试中,使用IXIA XT80流量测试设备生成64 Byte~1500 Byte大小的包组成的数据流,包头对应的字段替换成ClassBench生成的包头信息。 3.2.1 内存占用 不同大小的规则集在构建过程中,3种算法所占用的内存情况如图5所示。从结果图中可以看出,内存占用最小的是PCIU算法,然而随着规则集的增大,本文提出的包内并行分类算法占用内存与PCIU逐渐接近,这是因为本文的算法在预处理过程中并未对规则集的冗余进行压缩,所以理论上内存占用比PCIU算法多,但是当规则集增大时,PCIU的利用冗余进行压缩的效果变差,导致其内存占用情况逐渐接近本文的算法。而本文的算法在处理10000大小规则集时内存占用仅约为4.2 MB,当今大多数的网包处理设备都容易满足。 图5 内存占用对比 3.2.2 预处理时间 图6所示为3种算法在构建不同大小规则集的预处理过程所用时间。从结果可以看出,本文算法的预处理时间最少,而且当规则集较大时,本文算法的预处理时间比PCIU缩短得更多,在10000规则集下,本文算法的预处理时间仅为PCIU的15%左右。这也印证了,本文算法通过牺牲一定的内存空间,换来了预处理速度的大幅提升,预处理性能达到每秒92700条规则。 图6 预处理时间 3.2.3 吞吐性能 在测试吞吐性能时将IXIA XT80流量生成设备与多核处理器平台的一个10 Gbps接口直连。首先将数据包大小设置为64 Byte,测试将不同的核心数用于并行合并过程时系统的性能。多核处理器的10个核心中,有一个用来运行Linux系统,还有一个用于查找位向量,用于位向量并行合并过程的核心数为1~8个。实验结果如图7所示。可以看出,包内并行算法的吞吐最大,且随着核数的增多,相对于RTC并行的HiCut和PCIU算法吞吐的差值也更大,说明包内并行算法的多核扩展性更好。对RTC并行的HiCut和PCIU算法进行测试时,由于数据包在多个核心之间的分配不均衡,当流量较大时,出现了部分核心任务堆积而其他核空闲的情况,这是RTC并行的PCIU算法性能不如包内并行算法的主要原因。 将并行阶段的核数固定为8,即使用全部可用核心,用不同大小的包来测试系统的吞吐性能,其结果如图8所示。从结果可知,当数据包大小达到256 Byte时,包内并行算法实现了10 Gbps的线速处理,而RTC并行的HiCut和PCIU分别只能达到线速的50%和80%,当数据包大小为512 Byte时才能实现线速。并行算法的最大吞吐性能为5.37 Mpps(每秒5.37兆个包)。 图7 不同并行核数下的吞吐性能 图8 8个核下不同包大小的吞吐 本文提出了一种多核并行的数据包分类算法,采用包内级别的并行方案,将一个包的分类过程用多个核来并行执行,在并行的同时能保持数据包输出的顺序与输入顺序一致,而不需要重新排序。实验结果表明,包内级别并行算法比包级并行RTC实现的其他算法在预处理速度和吞吐性能上都有所提升,可以达到每秒92700条规则的预处理性能以及5.37 Mpps的吞吐性能,当数据包大于或等于256 Byte时可以实现10 Gbps的线速处理。相较而言,内存空间占用的增加并不显著,不会造成内存爆炸,适用于多数网络处理平台。保序的特点也使得该算法在需要保序的系统中更加适用。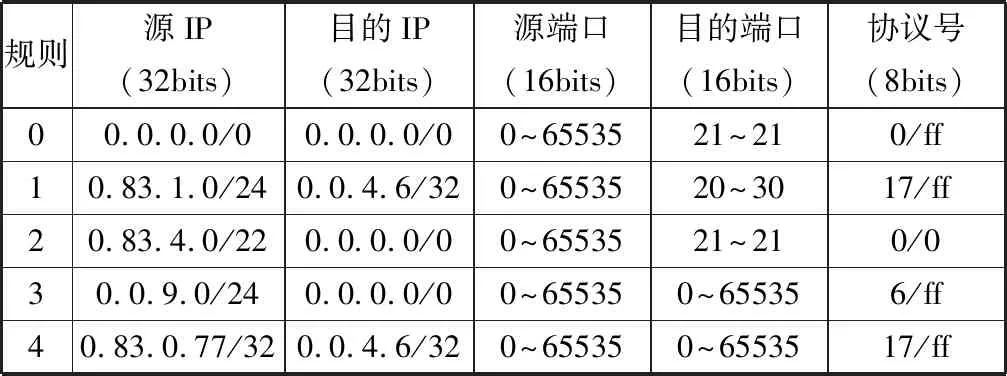


2.2 分类过程
2.3 分类过程多核并行化
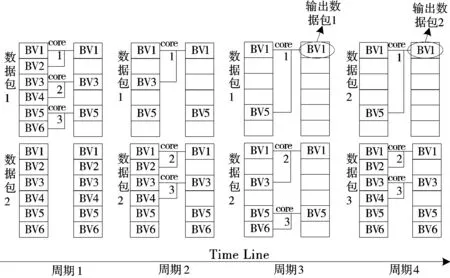
3 实验对比分析
3.1 测试环境和数据集
3.2 测试结果

4 结束语
